고객에게 뚜렷한 경험을: 컬리의 후기 이미지 처리 기술
안녕하세요. 데이터서비스개발팀 소속 Data Scientist 안은정입니다.
여러분들은 컬리에서 상품을 구매할 때 어떤 부분을 고려하시나요?
저는 상품을 구입하기 전에 구매 후기를 꼭 확인하는데요. 그렇게 후기를 보고 구매를 한 상품들은 잘 샀다는 느낌을 받은 적이 많습니다. 컬리 고객들의 솔직한 후기 덕분에 컬리만의 상품이 실제로도 괜찮은지 실제 사진들을 보며 상품에 대한 판단 할 수 있었고, 그게 컬리에서의 좋은 구매 경험으로 이어지지 않았을까 싶습니다. 하지만, 너무 흐리거나 어두워서 별로 도움 되지 않는 후기 이미지도 종종 보일 때가 있는데요.
데이터서비스개발팀에서는 선명하고 도움되는 이미지를 선정하는 다양한 기술을 적용해 고객 분들의 구매 의사 결정에 도움 드리는 것을 목표로 하고 있습니다.
이번 포스팅에서는 후기 이미지 처리 개선을 위해 어떤 시행착오를 거쳤으며, 어떤 결과와 개선 효과가 기대되는지 공유 드리겠습니다.
현행 리뷰 이미지 처리 과정
컬리는 고객에게 양질의 리뷰를 제공하기 위해 아래와 같은 세 가지 이미지 처리를 수행합니다.

여기서 현재 흐린 이미지 탐지 과정의 경우 입력 이미지를 다양한 주파수를 갖는 주기함수들의 합으로 분해하여 흐린 정도를 탐지하는 푸리에 변환(Fourier transform) 기반의 알고리즘이 뱉어낸 결과를 다시 한번 사람이 검토하고 있습니다. 하지만, 해당 알고리즘만 적용할 경우 탐지되는 이미지의 양이 너무 많으며, 탐지 결과가 일정하지 않은 상황이 생깁니다.
그래서 이번에는 기존 알고리즘에 흐린 이미지를 탐지하는 다른 종류의 알고리즘을 덧대어서 전반적인 탐지 정확도 (현재 precision 기준. 즉, 탐지한 이미지 중 진짜 흐린 이미지는 몇 %인지)와 이미지 검토 업무 효율성 모두 높이는 것을 목표로 프로젝트를 진행하였습니다.
리뷰 이미지 개선 과정
첫 번째 삽질 - 기존 후기 이미지 그대로 사용하기
컬리에는 하루에 평균 몇 건 정도 후기가 올라올까요?! 조회해 본 결과 평균적으로 3만 건 이상의 후기가 등록이 됩니다. 이렇게 등록된 후기는 위에 언급한 알고리즘을 통과하며 처리가 되는데요. 기존 이미지 처리 결과를 바탕으로 저의 첫 번째 삽질이 시작되었습니다.
먼저 기존 이미지 처리 결과 흐리다고 판단된 이미지와 뚜렷하다고 판단된 이미지의 픽셀 값의 분포를 비교해 보았습니다. 아무래도 흐린 이미지의 경우 뚜렷한 이미지에 비해 픽셀 값의 분포가 치우쳐 있을 것이라 가정하고 진행했던 삽질이었습니다. 아래의 그래프는 흐린 이미지 집단을 집단 1로, 뚜렷한 이미지 집단을 집단 2로 하여 각 픽셀 값의 평균, 표준편차 및 변동계수 분포를 확인한 결과입니다.
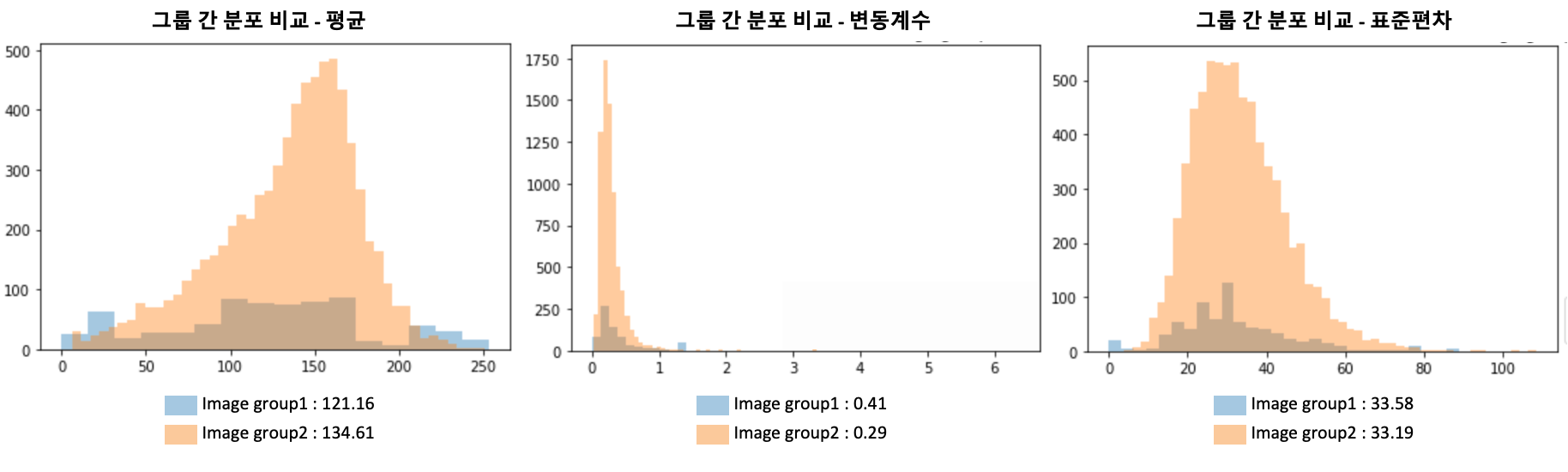
사실 두 집단 간 분포 차이가 날 것이라 가정하고 진행한 분석이었는데 그래프 분포 상으로 두 집단 간 차이 검정 결과로도 유의한 결과가 보이지 않아 원인을 살펴보았습니다.
그래서 원인은?
→ 이미지 처리 과정 중 역변환을 하며 뚜렷하다고 판단된 실제 이미지와 뚜렷하지 않다고 판단된 실제 이미지의 차이가 크지 않기 때문이었습니다.
두 번째 삽질 - 무작정 딥러닝 모델 활용
사실 저는 데이터 사이언스의 꽃은 딥러닝이라고 생각하는 편인데요. 특히 이미지 데이터나 음성 데이터 등의 비정형 데이터에서 그 꽃이 더욱 활짝 핀다고 생각했던 터라 프로젝트 진행 시 기대감에 부풀어 있었습니다. 하지만 그땐 몰랐습니다. 이게 두 번째 삽질의 시발점인지…
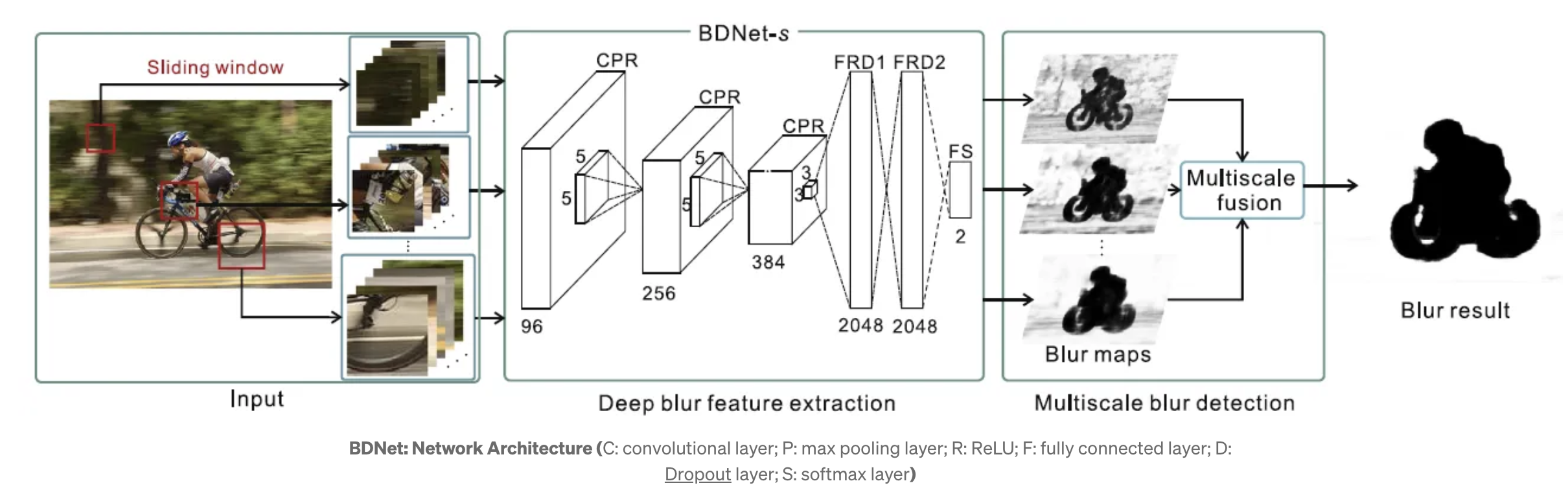
이때까지만 해도 CNN 기반의 모델 구조를 활용하면 모델이 흐린 이미지와 뚜렷한 이미지의 특성을 잘 잡아내어 분류를 잘 해주리라 막연히 믿었습니다. 그래서 찾아낸 모델이 AlexNet 과 유사한 구조를 가지고 있는 BDNet(Blur Detection Network)이라는 CNN 모델이었습니다.
-
BDNet 구조
© 2024.Kurly.All rights reserved.
PyTorch를 이용하여 BDNet 구조의 네트워크를 형성하여 기존 후기 이미지로 학습을 시켜본 결과, 기존 보다 흐린 이미지를 확실하게 잡아내긴 하지만, 여전히 precision은 0.6 정도로 낮은 수치에 머물러 있었습니다.
그래서 원인은?
→ 근본적으로 후기 데이터의 두 이미지 집단 간 특성의 차이가 미미하므로 아무리 CNN 모델이라도 특성을 정확하게 잡아내기 힘들기 때문입니다. 너무 모델에만 기대려고 한 탓도 있었죠.
추가 개선 Point!!
→ 비록 두 번의 삽질로 끝났지만 원인 파악을 함으로써 흐린 이미지와 뚜렷한 이미지의 기준 정립이라는 개선 포인트를 찾아 운영에 반영하면 좋을 것 같다는 생각으로 마무리하였습니다.
세번째 삽질 - 학습이미지 인위적으로 만들기
위의 두 번의 삽질로 학습 이미지에 변화를 줄 필요성을 느꼈고, 동료들의 아이디어를 받아 뚜렷한 이미지와 흐린 이미지의 특성을 확실하게 하기 위해 일부러 뚜렷한 이미지를 가져와서 여러 가지 형태로 블러 처리를 한 후 라벨링 작업을 실시하였습니다.
필터 사이즈가 커질수록 블러 정도가 심해지고 \(5 \ast 5\) 사이즈의 필터부터 최대 \(99 \ast 99\) 사이즈의 필터까지 다양하게 적용하여 학습 데이터로 사용하였습니다.

그래서 성능개선이 되었나?
→ 결론부터 말하자면 드라마틱한 성능의 개선은 없었습니다. 오히려 batch 별 과적합 현상이 나타나면서 validation precision이 0.9 정도로 높게 나왔으나, test precision은 0.7로 뚝 떨어지는 현상이 있었습니다. activation function을 바꿔보고, optimizer의 learning rate를 조정해 봐도 전반적인 성능은 0.75 정도에 머물렀습니다.
시행착오 결과? → Simple is the best!
여러 번의 시행착오를 겪으며, 새로운 관점으로 문제를 해결해야 할 필요성을 느꼈습니다. 그래서 이미지 데이터의 특성을 이용하기로 하였습니다.
-
이미지 데이터 구조

© 2024.Kurly.All rights reserved. 우리가 자주 접하는 컬러 이미지를 데이터화하였을 때 실제 데이터의 구조는 \(M \ast N \ast 3\) 행렬로 이루어져 있습니다. 이것을 흔히 RGB(Red, Green, Blue) 형태의 이미지라고 합니다. 각 색깔에 해당하는 \(M \ast N\) 행렬이 3개로 이루어진 형태라고 생각할 수 있습니다. 그리고 우리가 보는 다양한 색깔들은 RGB의 적절한 조합으로 나타나는 거죠.
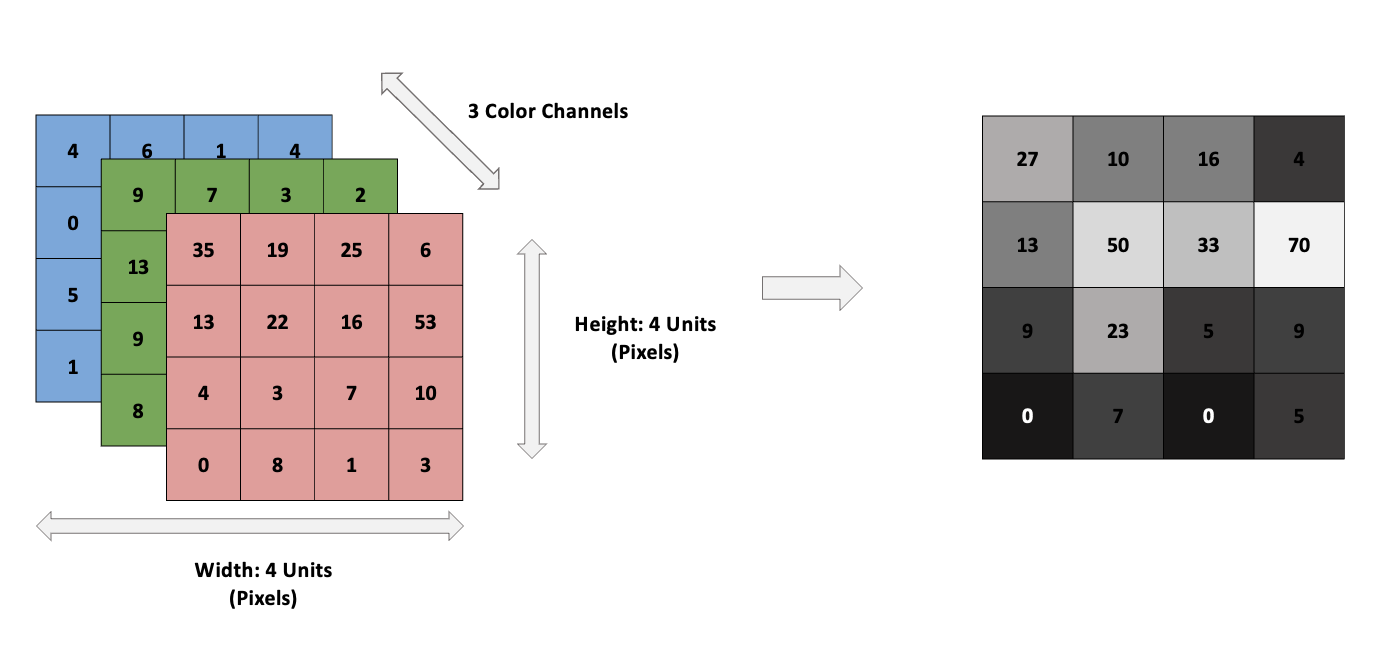
© 2024.Kurly.All rights reserved. 또한 우리가 알고 있는 흑백 이미지는 3차원으로 구성된 RGB 데이터를 1차원으로 축소하여 흰색과 검은색의 조합으로 나타낸 이미지입니다.
각 행렬을 구성하는 픽셀 값은 0~255 사이의 숫자로, 0에 가까울수록 진해지며 255에 가까운 숫자일수록 밝아지는 특성을 가지고 있습니다.
모델이 왜 흐린 이미지와 뚜렷한 이미지를 제대로 구별하지 못하는 걸까? 이 둘의 가장 뚜렷한 차이점은 뭘까?
여기서 제가 생각했던 정답은 경계선 이였습니다. 흐린 이미지일수록 경계선이 뚜렷하지 않고, 픽셀 값의 차이가 없다는 것이죠. 하지만 CNN 모델의 경우 filter를 활용하여 지엽적인 특성을 추출해 내기 때문에 이런 차이점을 제대로 구분하지 못한 게 아닐까 하는 결론을 내렸습니다.
제가 생각했던 결론이 맞는지 한번 찾아보았는데요.
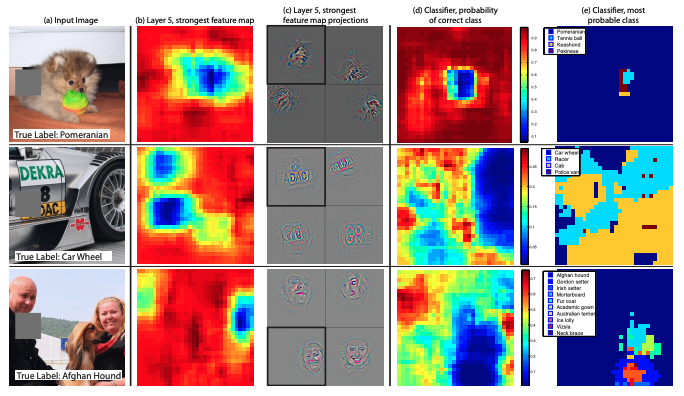 출처논문 : Visualizing and Understanding Convolutional Networks
출처논문 : Visualizing and Understanding Convolutional Networks
© 2024.Kurly.All rights reserved. → 위 그림은 모델이 이미지를 분류하는 데 큰 영향을 미치는 부분을 관찰하여 시각화 한 결과라고 합니다(Occlusion Experiment 방법). 마지막 (e) Classifier, most probable class 그래프를 보았을 때, 포메라니안의 경우 포메라니안 얼굴 부분을 제외하고 전 부분이 분류에 영향을 준다고 보입니다. CNN의 경우 각 convolution layer에 다양한 필터를 적용하여 하나의 이미지에 대한 여러 가지 지엽적인 특징을 추출하는 과정을 거쳐 이미지를 분류하게 됩니다. 그런데 흐린 이미지 탐지의 경우 지엽적인 특징이 아닌 이미지 전반에 대한 흐림의 정도를 판단해야 하며, 뚜렷한 이미지라도 여러 레이어를 거치며 마지막 레이어에서는 흐린 이미지와 구분되는 큰 특징이 없을 수도 있겠다는 생각이 들었습니다.
 출처 논문: Research on Video Quality Diagnosis System Based on Convolutional Neural Network
출처 논문: Research on Video Quality Diagnosis System Based on Convolutional Neural Network
© 2024.Kurly.All rights reserved. → 위 자료를 보면 마지막 레이어에서는 원본 이미지의 일부만 확대해서 내보내는 걸 볼 수 있습니다. 그 이유는 convolution layer의 경우 원본 이미지에 여러 가지 필터를 씌워 다음 레이어로 전달하고, pooling layer는 이미지의 일부 특징만을 추출하기 때문입니다. 이 과정은 이미지의 정보손실로 이어지며, 흐린 이미지와 뚜렷한 이미지를 구분하기 어렵게 만듭니다. 다시 말해, 모델을 활용할 경우 레이어가 깊어질수록 흐린 이미지와 뚜렷한 이미지의 차이가 미미할 수 있으며 이미지가 엄청 뚜렷하거나 흐려서 제대로 구분이 되지 않을 정도인 경우에만 제대로 된 분류가 가능할 것입니다. 따라서, 흐린 이미지를 탐지하는 경우 모델보다는 오히려 룰 기반 알고리즘이 성능이 높을 수도 있다는 결론을 내렸습니다.
이미지 변환 및 실험
위의 과정을 거쳐서 내린 결론으로 두 가지를 가정해 봤습니다.
- 흐린 이미지는 특정 픽셀 값이 주변의 픽셀 값과 차이가 적을 것이다.
- 라플라시안 필터를 적용했을 때 윤곽선이 뚜렷하지 않을 것이다 → 1번 가정과 같은 맥락으로 주변의 픽셀 값과 비슷한 숫자를 가지고 있을 것이다.
이미지 변환
위의 가정들을 확인하기 위해 컬러 이미지를 흑백 이미지로, 흑백 이미지에서 다시 윤곽선만 추출하는 과정을 거친 결과 이미지입니다. 저는 라플라시안 필터를 활용하여 윤곽선을 검출하는 방법에서 흐린 이미지를 분류할 수 있는 아이디어를 얻었습니다.

육안으로 확인했을 때 뚜렷한 이미지에서는 이미지 내 윤곽선이 잘 도출되는 반면, 흐린 이미지는 거의 모든 영역이 검은색이 보입니다.
그럼 픽셀 값은 어떨까요? 뚜렷한 이미지는 0~255사이의 값들이 고루 분포됐고 흐린 이미지에서는 0에 가까운 숫자들이 이미지 행렬을 구성하리라 예상됩니다. 따라서, 뚜렷한 이미지는 픽셀 값의 표준편차가 흐린 이미지에 비해 클 것이고 흐린 이미지는 상대적으로 표준편차가 작을 것입니다.
라플라시안 필터로 윤곽선 검출 원리

라플라시안 연산자는 경도(Gradient)의 발산(Divergence)이라고 합니다. 여기서 Gradient 연산자(\(\nabla f\))는 벡터 함수로 정의하는 벡터장 내의 한 점에서 벡터 함수의 값이 가장 급격히 변하는 주변의 위치와 크기를 알려주는 연산자이며, Divergence 연산자(\(\nabla\cdot f\))는 단위 단면적으로부터 퍼져 나가는 정도를 알려줍니다. 따라서, Divergence 가 0이라면 퍼져 나가는 정도와 유입되는 정도가 동일하므로 벡터의 흐름이 균일한 상태를 의미합니다.
즉, 라플라시안 연산자는 벡터장 내에 벡터의 흐름이 균일하지 못한 정도를 나타낸다고 합니다. 이걸 이미지에 적용해 본다면, 윤곽선이 뚜렷한 부분은 픽셀 값이 급격하게 변하므로 라플라시안 연산의 결과 값이 큽니다.
실험
위의 가정과 이론을 활용하여 인위적으로 만들어낸 학습 데이터에 적용을 해보았습니다. 라플라시안 필터를 흐린 이미지 그룹과 뚜렷한 이미지 그룹에 적용한 후 픽셀값의 평균 및 표준편차의 분포를 비교한 그래프를 그려보았습니다.
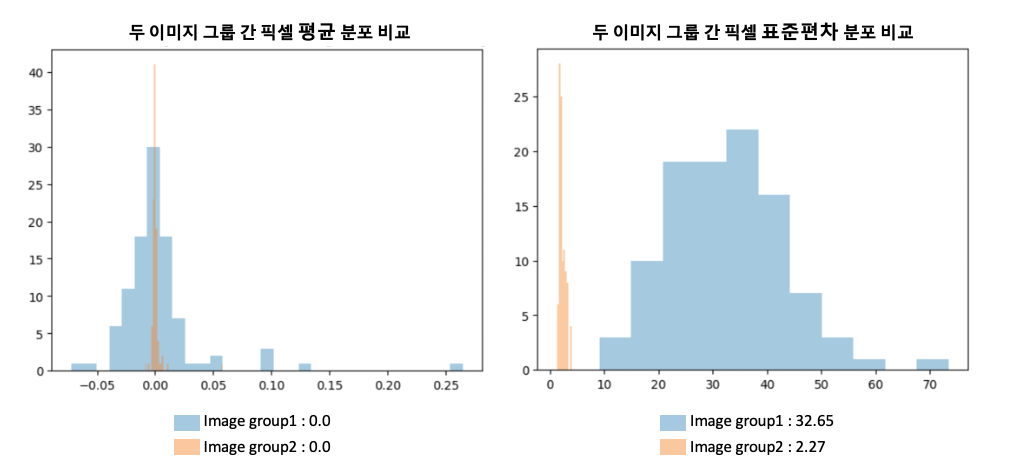
평균의 경우 라플라시안 변환을 하게 되면 기본적으로 검은색 바탕에 윤곽선만 흰색으로 표시가 되므로 group1 (흐린 이미지)과 group2 (뚜렷한 이미지) 간에 유의미한 차이는 없었습니다.
하지만 흐린 이미지는 윤곽선이 뚜렷하지 않아 거의 대부분의 픽셀 값이 0에 가까우므로 표준 편차의 값이 비교적 작으며, 두 번째 그래프에서도 그룹 간 차이가 확연히 보였습니다.
그렇다면, 실제 후기 데이터에 적용했을 땐 어떤 결과가 나왔을까요?
흐린 이미지를 판단하는 기준 (threshold) 값으로 표준편차 = 4를 적용하여 실험을 진행하였고, 해상도는 낮아도 상품 구분은 가능한 (즉, 검출 대상이 아닌) 이미지들도 같이 검출이 되었습니다. 뚜렷한 이미지를 흐린 이미지로 판단하는 경우가 반대의 경우보다 리스크가 크기 때문에, threshold를 좀 더 보수적으로 하향 조정하여 precision을 높일 필요가 있었습니다.
-
잘못 검출된 뚜렷한 이미지 예 (False Positive)
 해당 이미지의 표준편차 값 : 3.543
해당 이미지의 표준편차 값 : 3.543
© 2024.Kurly.All rights reserved.
위의 이미지는 어떤 상품인지는 알아볼 수 있으나, 해상도가 비교적 낮아 흐리다고 분류되었습니다. 위 이미지의 표준편차를 보니 3.5 정도의 값을 가지고 있습니다. 그 외에도, 잘못 검출된 이미지들의 표준편차를 보면 대부분 3.5~6 선에 분포되어 있었습니다. 따라서 표준편차의 threshold 값을 3.5로 하향 조정하여 다시 실험을 해보았습니다. 그 결과, 검출된 이미지의 약 90%(precision)가 실제로 흐린 이미지였습니다.
-
정상 검출된 흐린 이미지 예 (True Positive)

© 2024.Kurly.All rights reserved.
마치며
평소에 이미지 데이터 처리에 관심이 많았던 터라 이번 프로젝트를 재밌게 진행할 수 있었습니다. 또한 이미지 분류는 딥러닝이 답이다 라는 저의 고정관념도 깨부술 수 있었던 의미 있는 프로젝트였습니다. 하지만 다음번에 또 다른 이미지 프로젝트를 맡게 된다면 다시 한번 CNN을 도전해 보고 싶다는 욕심도 생겼습니다.
그리고 현재는 전반적인 결과 개선이 된 것처럼 보이지만 아직 10% 이미지의 경우 여전히 해결하지 못한 숙제로 남아있습니다. 조금 더 깊은 연구를 통해 나머지 이미지에 대한 결과 개선도 시도해 볼 것이라 다짐하며 이번 포스팅은 마무리하도록 하겠습니다.
긴 글 읽어주셔서 감사합니다 😄
Reference
- BDNet
- Laplacian-filter
- CNN filter & deconvolution