컬리가 상품을 고객에게 빠르게 전달하는 똑똑한 방법
최적화 기법을 활용한 배송 효율화 사례 소개
안녕하세요. 컬리 데이터서비스개발팀 구병주입니다.
컬리는 매일 다양하고 많은 상품들을 전국 각지에 배송하고 있습니다. 배송 차량이 상품을 싣고 고객 분들께 향하는 과정을 어떻게 하면 더 효율적으로 해낼 수 있을지 컬리는 항상 고민하고 있는데요. 이번 글에서는 최적화 기법을 활용하여 배송 효율화를 해내고 있는 모습을 일부 소개해 드리고자 합니다.
컬리 배송이 이루어지는 과정
컬리의 배송은 크게 두 단계로 이루어집니다. 김포, 평택 등지에 위치한 대형 물류센터를 CC(Cluster Center)라고 합니다. 이 곳에서 분류 및 포장 작업을 마친 상품을 대형 배송 차량을 이용하여 일차적으로 각지에 위치한 TC(Transfer Center)로 전달합니다.
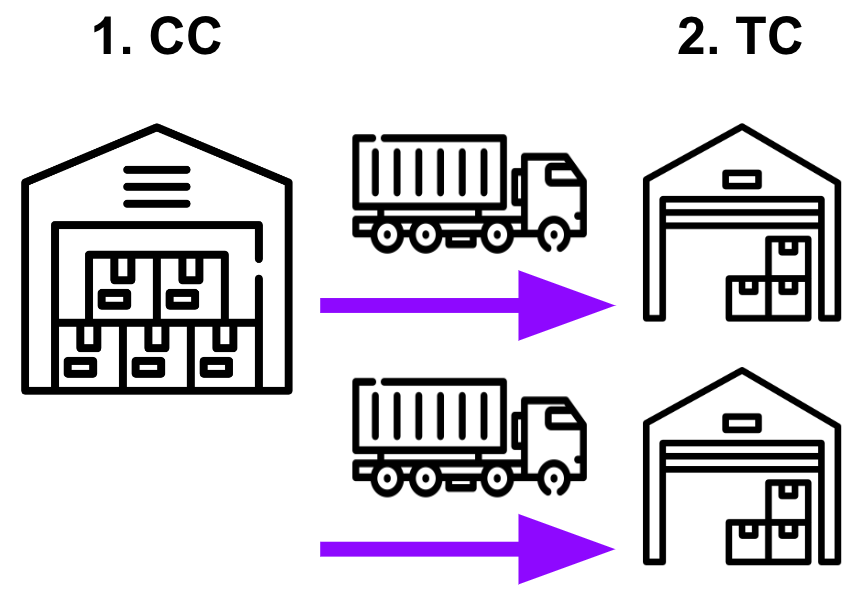
다음으로, TC에 도착한 상품은 최종적으로 각지의 고객 분들께 소형 배송 차량을 이용해 전달합니다. 최종 배송지는 일정 범위의 배송지들을 포함하는 ‘권역’이라는 단위로 묶여있습니다. 접수된 주문은 권역별로 미리 할당된 TC를 통해 배송됩니다.
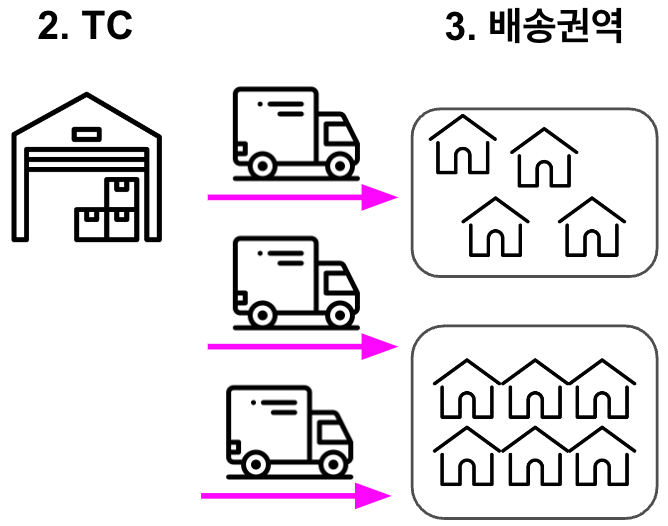
컬리는 전국 각지에 여러 CC와 TC를 운영 중이고 수백 개의 권역으로 분류된 배송지들을 다루는 복잡한 시스템입니다. 따라서 각 권역에 상품을 배송할 CC와 TC를 어떻게 선택하느냐에 따라 배송 및 물류 센터의 효율성이 좌우됩니다.
풀고자 한 문제
배송의 첫 번째 단계에서 CC는 가까운 TC에 물량을 공급하도록 고정되어 있습니다. 하지만 두 번째 단계에서 각 TC가 어떤 권역에 배송을 할지는 상대적으로 유동적으로 이루어집니다. 이에 따라 저희는 TC-권역 할당을 재조정하는 최적화 프로젝트를 진행하였습니다.
먼저 이해를 돕기 위해 최적화 전/후 간단한 예시를 그림으로 보겠습니다. 4개의 TC(큰 표시) 각각에 할당된 권역들(같은 색깔 표시)입니다. (무작위로 생성한 예시 지도이며, 실제 운영과는 무관합니다)
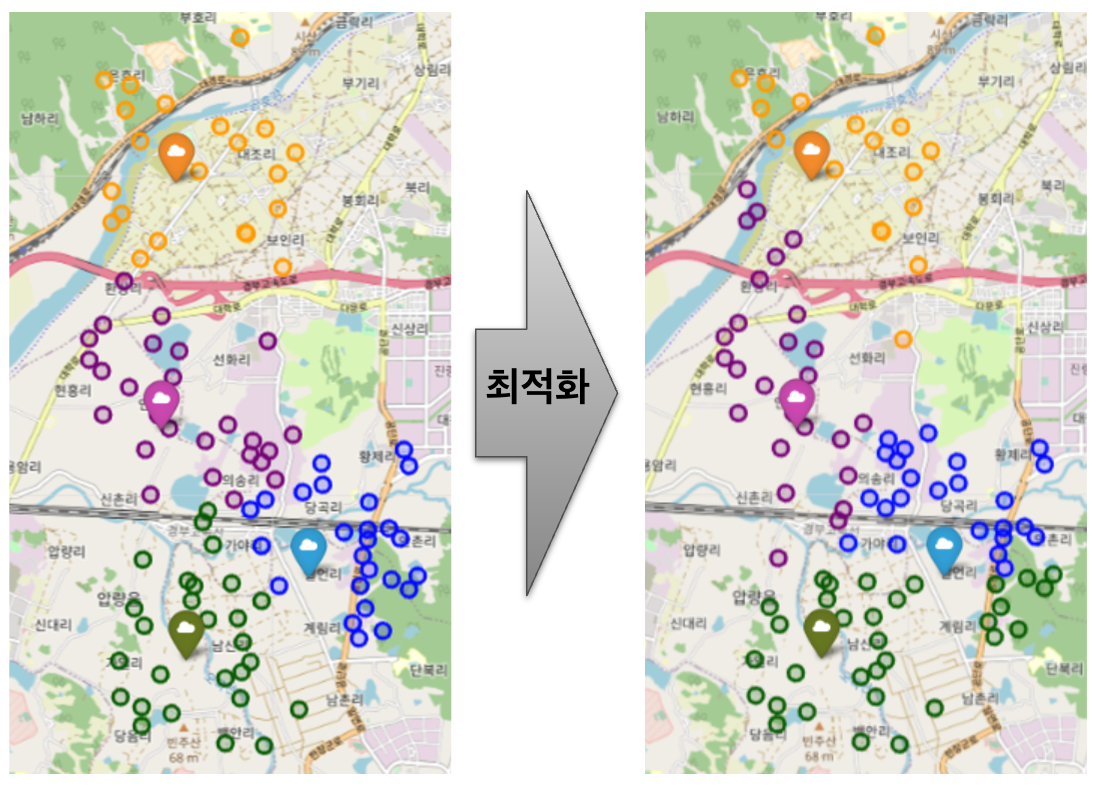
기존 권역 할당은 주로 행정 구역 및 직선 거리에 기반한 구획 분할 방식을 사용했습니다. 저희는 그림과 같이 각 TC에 할당된 권역들을 재배치하여 아래의 두 가지를 달성하고자 했습니다.
- 배송 소요시간 감소
- 실제 배송차량의 이동 소요시간이 꼭 직선거리에 비례하지는 않기에, 사람이 구획을 나눈 기존의 방식은 효율적인 이동을 보장하지 못합니다. 저희는 할당 권역 재배치를 통해 배송차량의 이동 소요시간을 전반적으로 감소시키고자 했습니다.
- TC간 물량 불균형 해소
- 기존의 운영 방식에서 각 TC는 수용력에 비해 너무 많거나 적은 물량을 소화하고는 했습니다. 저희는 TC별 물량수용력을 고려한 최적 배치를 통해 불균형을 해소하여, 물량 적체나 잉여 자원 발생을 방지하고자 했습니다.
어떻게 풀 것인가
문제 정의
저희는 이 문제를 조합 최적화 문제로 바라보았습니다.
TC에 권역들을 할당시키는 방법의 수는 아주 많습니다. TC가 10개이고 권역이 100개라고 가정하면 \(10^{100}\) 가지의 경우의 수가 있는데, 이는 우주의 모든 원자 수\((10^{82})\)보다 많고, 전부 나열하여 확인하려면 슈퍼 컴퓨터를 100억 년간 실행해도 모자랍니다. 이렇게 가능한 조합의 경우가 많은 상황에서 최적 조합을 빠르게 찾아내는 방법을 연구하는 분야가 바로 조합 최적화입니다.
이 문제에 조합 최적화 기법을 적용하기 위해서는 아래와 같이 문제를 구체적으로 정의할 필요가 있습니다.
컬리의 목표
- 상품을 고객들에게 최대한 빠르고 신선하게 전달하는 것
- ⇒ CC에서 주문이 출발하는 시점부터 배송지에 도착하는 시점까지 걸리는 시간을 모든 주문에 대해 계산하고, 이 시간의 총합을 최소화하고자 했습니다.
제약사항
- 각 TC는 소화할 수 있는 물량의 상한선이 정해져있습니다.
- 각 권역은 정해진 주문 물량을 하나의 TC로부터 배송받습니다.
결정해야 하는 것
- 모든 (TC-권역) 쌍에 대한 할당 여부
이렇게 최적화 문제는 목표(목적함수)와 제약사항(제약식), 그리고 결정할 사항(결정변수) 세 가지로 요약할 수 있습니다. 그리고 이를 풀기 편하도록 수식으로 표현한 것을 수리 모형이라고 합니다. 아래는 이 문제를 수리 모형으로 요약한 모습입니다. 수식이 낯설 수도 있지만, 위에서 요약한 바랑 똑같은 내용을 다르게 표현한 것에 지나지 않습니다.
파라미터
- \(I \quad\)(TC 집합)
- \(J \quad\)(권역 집합)
- \(t_{ij} \quad \forall i \in I, j \in J \quad\)(CC→TC \(i\)→권역 \(j\) 소요시간의 물량 가중합)
- \(d_{j} \quad \forall j \in J \quad\)(권역 \(j\)의 물량)
- \(c_i \quad \forall i \in I \quad\)(TC \(i\)의 소화 가능 물량)
목적함수
- \(\text{minimize } \sum_{i\in N} \sum_{j\in M} t_{ij} y_{ij}\quad\)((CC→TC→권역) 소요시간 총합 최소화)
제약사항
- \(\sum_{j \in J} d_{j}y_{ij} \leq c_{i} \quad \forall i \in I\quad\)(TC별 소화 가능 물량 제한)
- \(\sum_{i \in I} y_{ij} = 1, \quad \forall j \in J\quad\)(각 권역은 1개 TC에 할당)
결정변수
- \(y_{ij} \in \{0,1\} \quad \forall i \in I, j \in J\quad\)(TC \(i\)에 권역 \(j\) 할당 여부)
이 문제는 Generalized Assignment Problem (GAP)이라는 잘 알려진 최적화 문제의 special case입니다.
최적화 도구 선정
이와 같은 최적화 문제를 해결할 수 있는 방법은 다양합니다. 문제가 어렵거나 실시간으로 빠른 답안을 내놓는 것이 중요하다면 유전 알고리즘이나 tabu search 등 휴리스틱을 이용할 수도 있고, 시간이 조금 걸리더라도 해의 품질이 중요하다면 최적해를 보장하는 접근법을 사용할 수도 있습니다. 어떤 방식을 택할지 결정할 때에는 문제의 목적이나 복잡성, 범위 및 데이터 크기, 주어진 시간 제한 등을 잘 고려해야 합니다.
저희는 결론적으로 OR-Tools의 최적화 solver를 이용하기로 하였는데, 그렇게 결정한 근거는 다음과 같습니다.
- TC-권역 할당 문제는 실시간으로 해결해야 하는 문제가 아니며 도출된 계획의 품질이 중요합니다.
- 따라서 알고리즘에게 24시간 이상의 제한 시간을 주고 최적 답안을 찾을 때까지 기다려줄 수 있습니다.
- GAP는 NP-hard 문제임이 알려져 있지만(참고 문헌), 최적화 solver들은 저희에게 주어진 문제에 대해 수시간 안에 최적해를 도출한다는 직관이 있었습니다.
- OR-Tools는 그중에서도 사용이 용이한 오픈소스이기에 부담이 없습니다.
구글이 개발한 OR-Tools는 최적화 문제를 풀기 위한 여러 solver를 지원하는데, 그중 CP-SAT과 SCIP를 이용했습니다.
Solver를 이용하기 위해서는 위 수리 모형을 그대로 형식에 맞춰서 작성해 주기만 하면 됩니다. OR-Tools의 CP-SAT solver를 예로 들면, 위 수리 모형의 구현은 아래와 같이 직관적으로 이루어집니다.
#결정변수 정의: y_ij = TC i에 권역 j 할당 여부
y = {(i, j): model.NewIntVar(0, 1, f"y[{i}][{j}]") for i in range(len(TCS)) for j in range(len(NODES))}
#목적함수 정의: (CC→TC→권역) 소요시간 총합 최소화
objective = sum(y[i, j] * DISTANCES[i][j] for i in range(len(TCS)) for j in range(len(NODES)))
#제약식 정의
#TC별 소화 가능 물량 제한
for i in range(len(TCS)):
model.Add(sum(y[i, j] * DEMANDS[j] for j in range(len(NODES))) <= CAPACITIES[i])
# 각 권역은 1개 TC에 할당
for j in range(len(NODES)):
model.Add(sum(y[i, j] for i in range(len(TCS))) == 1)
이처럼 수리 모형을 이용해 문제를 정의해서 solver에 입력하면, 답을 내놓기 위한 조합 최적화 알고리즘이 solver 내부에서 자동으로 실행됩니다.
CP-SAT solver는 Constraint Programming과 Boolean Satisfiability Problem 패러다임 하에서 Constraint Propagation, Backtracking 등으로 작동합니다. SCIP solver는 선형완화, Branch-and-Bound 등 기법 기반의 정수 최적화(Integer Programming)를 사용합니다. Constraint Programming과 Integer Programming 두 분야는 내용과 역사가 방대하고 어렵지만 흥미로우니, 관심이 있으신 분들은 따로 더 찾아보시길 추천드립니다.
두 solver 모두 저희가 풀고자 하는 조합 최적화 문제에 적용 가능하지만, 문제의 구조나 데이터의 특징 등 복잡한 인과관계에 따라 특정 solver가 더 빠르게 최적해를 내놓을 수 있습니다. 저희는 안정적인 결과를 얻기 위해 둘을 병렬 실행하였습니다.
권역 재분할 문제
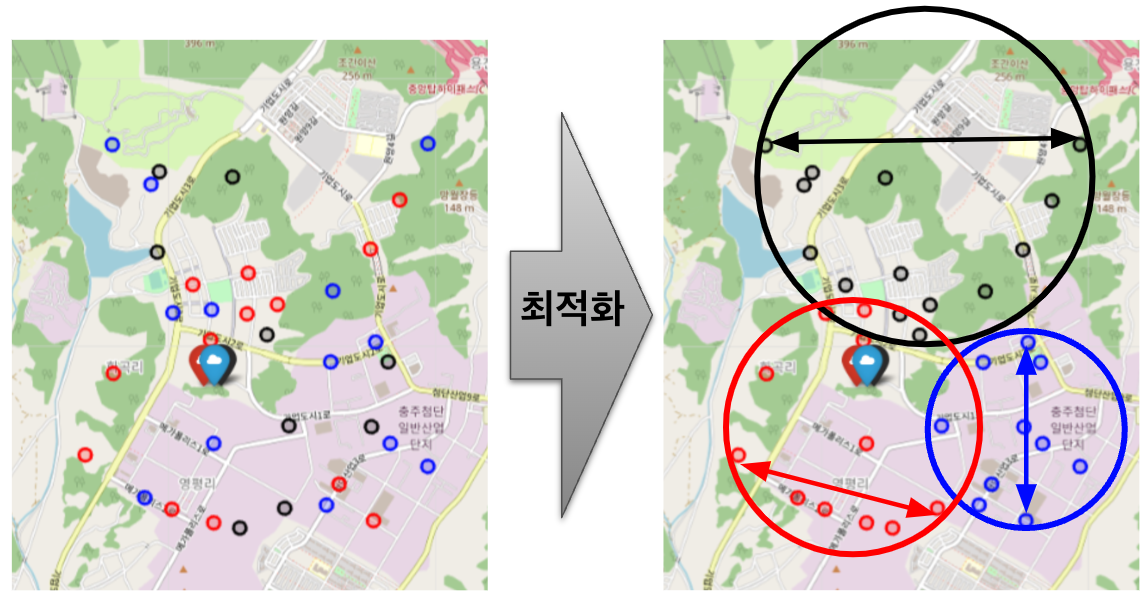
위 TC-권역 할당에는 비슷한 위치에 여러 TC가 존재하는 경우가 있다는 문제가 있습니다. 예를 들어 아래와 같이 할당된 권역들이 이리저리 섞이는 현상이 발생합니다.
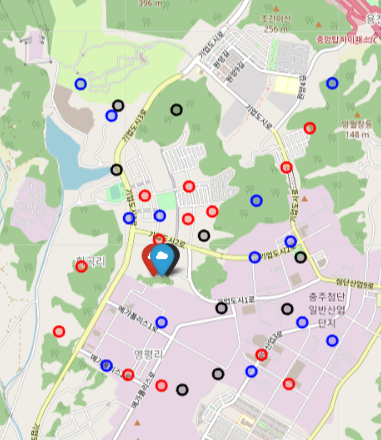
이는 비슷한 위치의 TC로부터 권역까지의 이동 소요시간은 거의 차이가 없기 때문입니다. 하지만 현실에는 사용할 수 없는 결과입니다. 일단 관리 측면에서 용이하지 않아 혼란이 발생할 가능성이 높습니다. 또한 실제 계획 실행 시에 배송기사의 권역 간 이동이 필요할 경우 비효율이 발생할 가능성이 큽니다. 배송기사 배정은 매일 변동성이 있기에 지금 단계에서 완벽히 고려하긴 힘들지만, 각 TC의 담당 권역들이 최대한 한 데 모여있는 것이 추후 실행에 더 유리합니다.
따라서 저희는 각 TC가 담당하는 권역이 서로 모여 있도록 하고 싶었습니다. 이 또한 조합 최적화 방법론으로 해결 가능합니다. 이를 위해 다음과 같은 최적화 문제를 추가로 정의했습니다.
목표
- 서로 가까이 위치한 n개 TC에 대해, 각 TC에 할당된 권역들끼리 서로 모여있도록 하는 것
- ⇒ 각 TC별로 할당된 권역들 사이 이동거리 중 최댓값을 구하고, 이 값의 총합을 최소화하고자 했습니다.
제약사항
- 각 TC는 소화할 수 있는 물량의 상한선이 정해져있습니다.
- 각 권역은 정해진 주문 물량을 하나의 TC로부터 배송받습니다.
이를 그림으로 나타내면 아래와 같습니다. 물량 제약을 만족하면서, 각 TC에 할당된 권역들 간 거리 중 최댓값(화살표로 표시)의 총합을 최소화하는 방식을 찾고자 했습니다.
위 문제상황을 수리 모형으로 나타내면 아래와 같습니다.
파라미터
- \(I\quad\)(TC 집합)
- \(J\quad\)(권역 집합)
- \(t_{jk} \quad \forall j, k \in J, \quad j<k\quad\)(CC→TC \(i\)→권역 \(j\) 이동거리)
- \(d_{j} \quad \forall j \in J\quad\)(권역 \(j\)의 물량)
- \(c_i \quad \forall i \in I\quad\)(TC \(i\)의 소화 가능 물량)
목적함수
- \(\text{minimize } \sum_{i\in N} w_i\quad\)(각 TC에 할당된 권역간 이동거리의 최대값 총합 최소화)
제약사항
- \(\sum_{j \in J} d_{j}y_{ij} \leq c_{i} \quad \forall i \in I\quad\)(TC별 소화 가능 물량 제한)
- \(\sum_{i \in I} y_{ij} = 1, \quad \forall j \in J\quad\)(각 권역은 1개 TC에 할당)
- \(z_{ijk} \geq y_{ij} + y_{ik} - 1 \quad \forall i \in I, \quad \forall j, k \in J, \quad j < k\quad\)(TC별 권역 동시 선택 여부 계산)
- \(z_{ijk} \leq y_{ij} \quad \forall i \in I, \quad \forall j, k \in J, \quad j < k\quad\)(TC별 권역 동시 선택 여부 계산)
- \(z_{ijk} \leq y_{ik} \quad \forall i \in I, \quad \forall j, k \in J, \quad j < k\quad\)(TC별 권역 동시 선택 여부 계산)
- \(w_i ≥ t_{jk}z_{ijk} \quad \forall i \in I, \quad \forall j, k \in J, \quad j < k\quad\) (각 TC에 할당된 권역간 이동거리 계산)
결정변수
- \(y_{ij} \in \{0,1\} \quad \forall i \in I, j \in J\quad\)(TC \(i\)에 권역 \(j\) 할당 여부)
- \(z_{ijk}\in \{0,1\} \quad \forall i \in I, \quad \forall j, k \in J, \quad j < k\quad\)(TC \(i\)에 권역 \(j\)와 \(k\)의 동시 할당 여부)
- \(w_{i}\geq 0 \quad \forall i \in I\quad\)(TC \(i\)에 할당된 권역간 이동거리 중 최대값)
권역 재분할 문제는 앞선 TC-권역 할당 문제보다 구조가 복잡하며 GAP와 같이 잘 알려진 최적화 문제로 정의할 수 없습니다. 하지만 수리 모형만 잘 정의한다면 최적화 solver를 적용하는 데에는 큰 문제가 없습니다. 따라서 마찬가지로 OR-Tools의 CP-SAT과 SCIP solver를 이용해 풀 수 있습니다.
이런 접근은 마치 k means clustering 과 비슷한데, 실제로 알고리즘의 목표도 비슷하지만 각 TC의 물량 수용력과 각 권역의 주문 물량을 맞추어야 한다는 점이 큰 차이이고, 이러한 제약 조건까지 반영하기 위하여 최적화 기법을 적용하게 되었습니다.
입력 데이터
한편, 수리 모형화 및 solver 구동 못지않게 중요하고 어려운 것이, 입력 데이터를 구성하고 반영하는 방식입니다. 모형을 아무리 잘 만들어도 garbage in, garbage out입니다.
최적화에 필요한 입력 데이터를 살펴보면 아래와 같습니다.
- 권역의 주문 물량
- TC의 물량 수용력
- 이동 소요시간
1. 권역별 주문 물량
- \(d_{j} \quad \forall j \in J\quad\)(권역 \(j\)의 물량)
주문 물량 자체는 객관적인 데이터입니다. 컬리는 BigQuery에 준실시간으로 주문 데이터를 저장하고 있으며, 원하는 기간 원하는 지역의 주문량을 통계적으로 유의미하게 가늠할 수 있습니다.
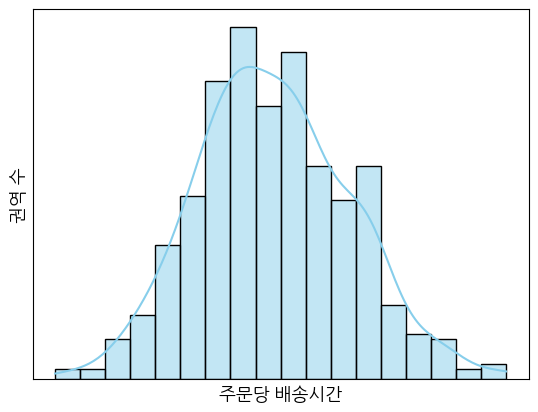
하지만 여기서 주의할 사항은 주문 권역별로 배송 난이도 및 소요시간이 다르다는 점입니다. 이는 주문 밀집도나 교통 상황, 주차장 상황 등 요인의 영향을 받습니다. 예를 들면 강남에서 1시간에 60건을 배송할 수 있는 배송기사가 남양주에서는 1시간에 최대 30건만 배송 가능할 수 있습니다. 이 경우 남양주의 주문 1건은 강남의 주문 2건과 동일하게 취급하여야 합니다.
위와 같은 이유로 인해 수리 모형 속 권역별 주문 물량 \(d\) 는 배송지별 난이도를 반영한 값(물량*난이도)이 되어야 합니다. 여기서 난이도는 과거 권역별 주문당 배송시간 데이터를 구한 후, 현장 의견을 수렴하여 적당히 scaling한 값을 사용합니다. 권역별 주문당 배송시간은 아래 그림과 같이 얼추 정규 분포의 모습을 보였습니다. (가상의 데이터로 수행한 결과입니다)
2. TC의 물량 수용력
- \(c_i \quad \forall i \in I\quad\)(TC \(i\)의 소화 가능 물량)
TC의 물량 수용력은 물리적인 차량 수용 공간에 기반하여 정해지지만, 역시 현실성을 갖춘 값으로 설정하기 위하여 과거 배송 데이터 및 TC 관계자의 피드백 반영 등 과정이 필요했습니다.
3. TC-권역 이동 소요시간
- \(t_{ij} \quad \forall i \in I, j \in J\quad\)(CC→TC \(i\)→권역 \(j\) 소요시간의 물량 가중합)
각 TC에서 배송 차량들은 보통 하루에 3회에 나누어 출차합니다. 출차 시각에 따라서 소요시간에 차이가 크기 때문에, TC별 출차 시각 이력 데이터를 통해 각 출차 회차 별 예상 소요시간을 각각 계산하고, 목적지 권역의 각 회차별 물량으로 가중합을 계산했습니다.
이외에도 현실 반영을 위한 여러 추가 입력 사항이 있습니다. 예를 들면, 배송기사들의 여건을 고려해 TC에서 권역까지 40분 이상이 소요되지 않도록 제한할 수 있습니다. 특정 권역은 그곳에 익숙한 특정 배송기사가 배송하고자 할 수도 있습니다. 이러한 사항들을 입력받아 데이터 전처리 혹은 수리 모형 제약식 형태로 추가 구현했습니다.
최적화 실행 및 결과
최적화 모듈을 이용해 두 버전의 대안을 도출했습니다. 아래는 기존 방식과 대안을 평가한 결과의 일부입니다.
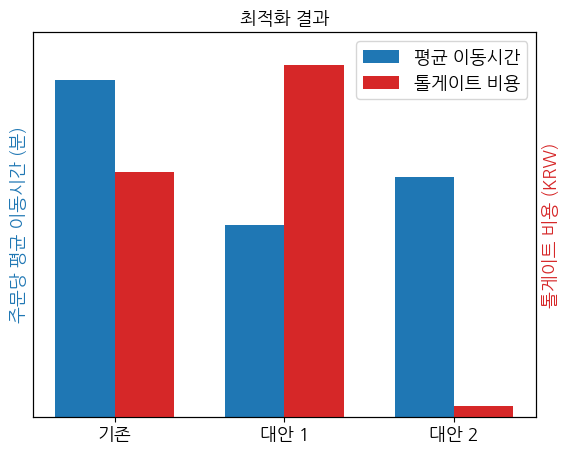
대안1은 최적경로 우선, 대안2는 무료도로 우선 길찾기를 사용했습니다. 대안 1은 기존 방식에 비해서 톨게이트 비용을 더 소모했지만, 이론적으로 배송 소요시간을 약 5% 절약할 수 있었습니다. 대안 2는 배송 소요시간 측면에서는 약간 타협했지만, 톨게이트 비용까지 최소한으로 사용하며 기존 방식보다 좋은 결과를 보여줬습니다.
다만 이러한 결과를 현실 세계에 적용하는 것은 또 다른 문제입니다. 현실 세계를 수리 모형에 완벽하게 담기는 어려우므로, 최적화 모형 실행과 피드백 및 경험 반영이 상호 보완적으로 이루어져야 합니다. 즉, 코드 실행 결과를 그대로 사용하기보다는, 모형이 반영하지 못한 부분에 대한 수기 재조정이나 입력 데이터 수정 및 실행을 반복적으로 거쳐야 실제로 적용할 수 있습니다.
해당 최적화 프로젝트는 일회성으로 그치지 않고 재사용 할 수 있도록 도구화하였습니다. 이를 통해 물류 운영 부서에서 입력 데이터 업데이트, 최적화 범위 설정, 실행 및 결과 분석을 쉽게 반복할 수 있도록 하였습니다. 나아가서는 TC-권역 할당 재조정뿐만 아니라, 새로운 TC 후보지 계약이나 권역 자체의 재조정 등 광범위한 의사 결정에도 활용할 수 있도록 했습니다. 현재는 지금까지의 최적화 결과를 반영한 권역 재배치 프로젝트가 진행 중입니다.
지금까지 컬리가 최적화 기법을 활용하여 배송 효율화를 해내고 있는 모습을 일부 소개해 드렸습니다. 다음에 다른 좋은 주제로 다시 찾아뵙도록 하겠습니다. 감사합니다.