들어가며
안녕하세요. 컬리 핀테크개발팀 이경훈입니다.
2024년 컬리에 합류하여 지류 상품권 프로젝트, AML 프로젝트를 거치며 여러 종류의 배치 애플리케이션을 개발했습니다.
spring-batch를 이용해 배치 애플리케이션을 개발한 경험은 처음이라 시행착오를 겪으며 재미있게 만들었습니다.
이번 글에서는 그 과정에서 MySqlPagingQueryProvider로 인해 겪었던 두 가지 이슈와 주의 사항을 공유하고자 합니다.
참고로 상품권 서비스와 AML 서비스의 환경 구성은 다음과 같습니다. (세부 버전은 미기재)
- Framework :
spring-batch- DBMS :
MySQL- Language :
kotlin
이 글은 spring-batch 5.2.0 버전을 기준으로 작성되었습니다.
spring-batch 의 기본 구조와 Chunk 단위 처리
spring-batch 의 기본 구조
본격적으로 제가 마주했던 이슈를 살펴보기 전에 spring-batch의 기본 구조를 알 수 있는 문서를 공유하니, 필요하면 살펴보시면 되겠습니다.
간략히 설명해 드리자면, spring-batch의 Job은 1개 이상의 Step으로 구성됩니다.
그리고 하나의 Step은 Reader(필수), Processor(선택), Writer(필수)로 구성됩니다.
이렇게 구성된 Job은 Job Launcher에 의해 실행되며, 그 과정에서 메타데이터들은 Job Repository에 저장됩니다.
Chunk 단위 처리
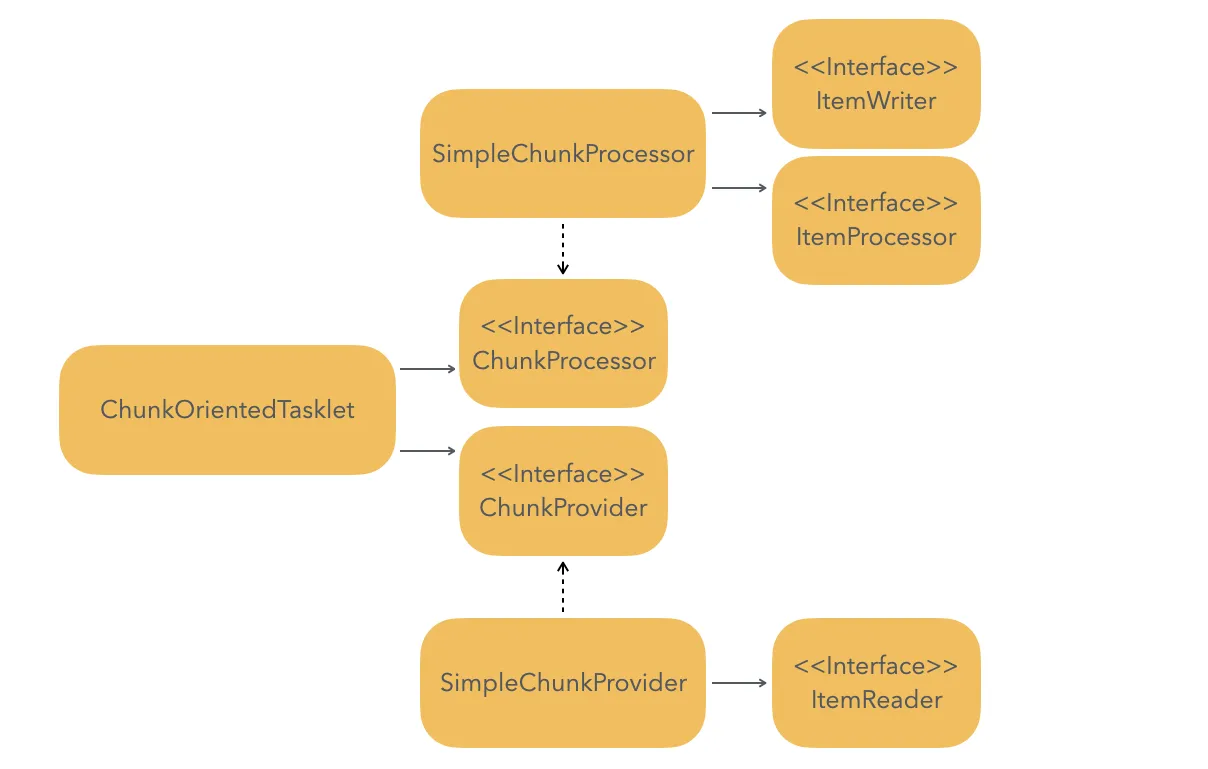
spring-batch에서는 Chunk 단위로 배치 작업을 처리할 때 ChukOrientedTasklet을 사용합니다.
별다른 설정 없이 Chunk 단위 Step을 만들면 다음과 같이 동작합니다.
- ChunkProvider의 구현체인 SimpleChunkProvider를 통해 Chunk를 제공(ItemReader)받습니다.
- ChunkProcessor의 구현체인 SimpleChunkProcessor를 통해 Chunk를 처리(ItemProcessor)하고, 저장(ItemWriter)합니다.
내부적으로 ChunkOrientedTasklet 을 더 이상 Chunk가 없을 때까지 반복 실행합니다.
© 2024.Kurly.All right reserved
JdbcPagingItemReader, PagingQueryProvider, 성공적
먼저 Chunk를 읽어오는 ItemReader Interface의 구현체인 JdbcPagingItemReader에 대해 알아보겠습니다.
public class JdbcPagingItemReader<T> extends AbstractPagingItemReader<T> implements InitializingBean {
// 생략 ..
private DataSource dataSource;
private PagingQueryProvider queryProvider;
private Map<String, Object> parameterValues;
private RowMapper<T> rowMapper;
private String firstPageSql;
private String remainingPagesSql;
private Map<String, Object> startAfterValues;
// 생략 ..
@Override
public void afterPropertiesSet() throws Exception {
// 생략 ..
this.firstPageSql = queryProvider.generateFirstPageQuery(getPageSize());
this.remainingPagesSql = queryProvider.generateRemainingPagesQuery(getPageSize());
}
// 생략 ..
}JdbcPagingItemReader 일부 발췌
위 코드는 spring-batch 프로젝트에서 JdbcPagingItemReader의 주요 필드를 발췌해 온 것이며, 각 필드의 용도는 다음과 같습니다.
- dataSource : DB connection을 얻는 역할을 수행합니다.
- queryProvider : 데이터를 조회할 Query를 제공합니다.
- parameterValues : Query에 바인딩할 파라미터 값입니다.
- rowMapper : 조회해 온 ResultSet을 객체로 매핑하는 역할을 수행합니다.
- firstPageSql : 첫 번째 페이지 조회 Query입니다.
- remainingPagesSql : 두 번째 페이지 이후 조회 Query입니다.
- startAfterValues : 다음 페이지 조회 시, 이전 페이지의 마지막 Row의 sort key 값들을 저장합니다.
여기서 주의 깊게 살펴봐야 할 점은 firstPageSql과 remainingPagesSql이 분리되어 있으며,
Bean으로 등록될 때 PagingQueryProvider로부터 제공받아 초기화된다는 것입니다.
이제 PagingQueryProvider를 살펴보겠습니다.
JdbcPagingItemReader는 여러 DBMS의 종류에 의존하지 않도록 하기 위해 PagingQueryProvider를 사용합니다.
protected PagingQueryProvider determineQueryProvider(DataSource dataSource) {
try {
DatabaseType databaseType = DatabaseType.fromMetaData(dataSource);
AbstractSqlPagingQueryProvider provider = switch (databaseType) {
case DERBY -> new DerbyPagingQueryProvider();
case DB2, DB2VSE, DB2ZOS, DB2AS400 -> new Db2PagingQueryProvider();
case H2 -> new H2PagingQueryProvider();
case HANA -> new HanaPagingQueryProvider();
case HSQL -> new HsqlPagingQueryProvider();
case SQLSERVER -> new SqlServerPagingQueryProvider();
case MYSQL -> new MySqlPagingQueryProvider();
case MARIADB -> new MariaDBPagingQueryProvider();
case ORACLE -> new OraclePagingQueryProvider();
case POSTGRES -> new PostgresPagingQueryProvider();
case SYBASE -> new SybasePagingQueryProvider();
case SQLITE -> new SqlitePagingQueryProvider();
};
provider.setSelectClause(this.selectClause);
provider.setFromClause(this.fromClause);
provider.setWhereClause(this.whereClause);
provider.setGroupClause(this.groupClause);
provider.setSortKeys(this.sortKeys);
return provider;
}
catch (MetaDataAccessException e) {
throw new IllegalArgumentException("Unable to determine PagingQueryProvider type", e);
}
}JdbcPagingItemReaderBuilder 의 일부 발췌
위와 같이 JdbcPagingItemReader를 만들 때, dataSource로 DBMS를 구분해 DBMS에 맞는 PagingQueryProvider 구현체를 생성합니다.이렇게 PagingQueryProvider를 사용함으로써 JdbcPagingItemReader는 DBMS에 대한 정보를 알 필요가 없게 됩니다.
자, 이제 본격적으로 제가 겪었던 이슈들을 살펴보겠습니다..!
첫 번째 이슈 : MySqlPagingQueryProvider의 Pagination 전략
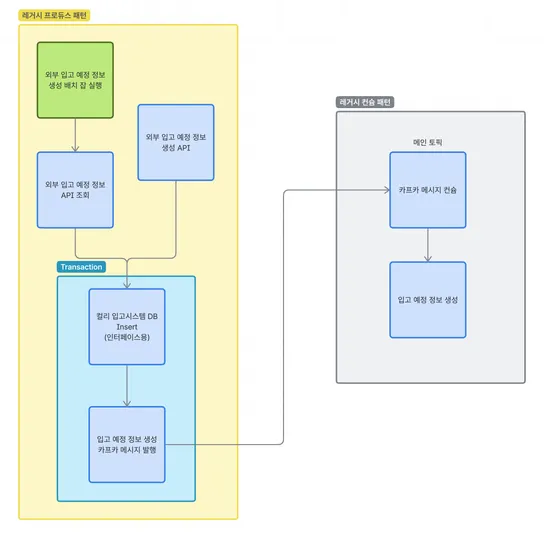
첫 번째 주제는 상품권 서비스에 Transactional Outbox Pattern을 적용하는 과정에서 마주한 MySqlPagingQueryProvider의 Pagination 전략입니다.
지류 상품권 프로젝트에서 상품권의 상태가 변경될 때 이벤트를 발행하여 Back Office로 변경된 상태를 전달해야 했습니다.
지류 상품권은 인쇄소에서 인쇄된다는 특성 때문에 한 번에 대량의 상품권이 인쇄 및 등록되어야 하는데,
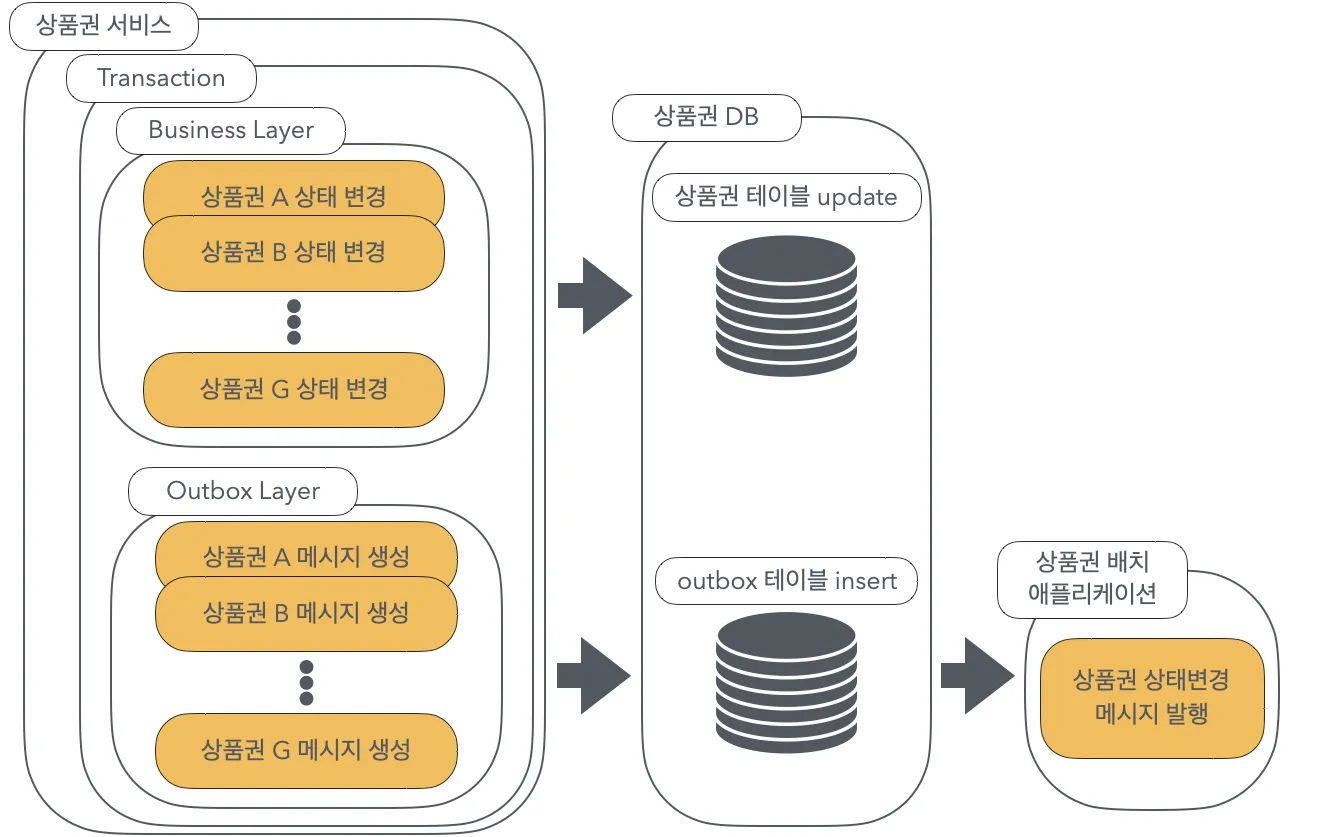
다수의 메시지를 한 번에 발행할 때 상품권 서비스 DB와 BackOffice의 DB간 정합성을 보장하기 위해 Transactional Outbox Pattern을 다음과 같이 적용했습니다.
© 2024.Kurly.All right reserved
Backoffice를 위한 기능이었고, 실시간성이 중요하지 않았기 때문에 CDC를 알아보는 대신 배치에서 Polling 하는 방식을 선택했습니다.
이때, Outbox 테이블의 대략적인 ERD는 다음과 같습니다. (실제 테이블과 유사하지만 다르게 살짝 수정했습니다.)

© 2024.Kurly.All right reserved
상품권의 상태 변경 메시지를 보내는 배치여서 발행 순서가 중요했습니다.
가령, 상품권 A가 발행 -> 사용 순으로 상태가 변경되었는데, 사용 -> 발행 순으로 메시지가 발행되면 이상하겠죠?
왜 일부만 발행될까?
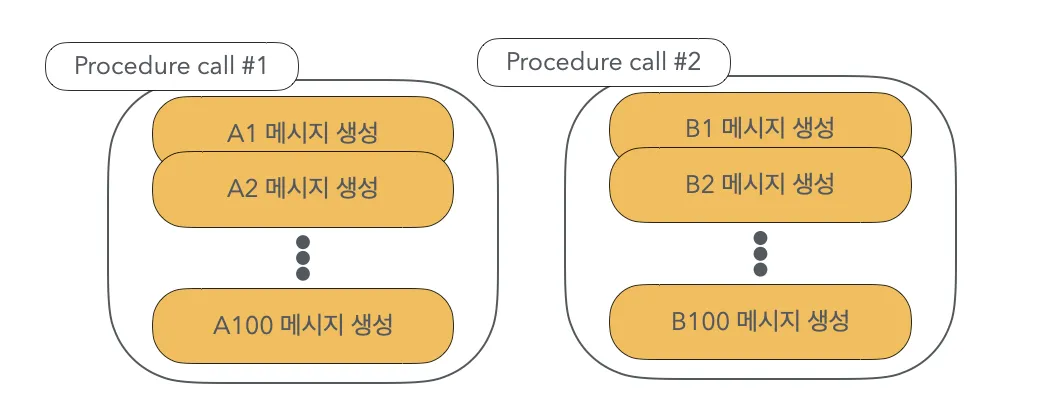
배치를 테스트하기 위한 용도로 outbox 테이블에 created_at 컬럼을 now()로 해서 100개씩 Insert 하는 Stored Procedure를 만들었습니다.
그리고 이 Procedure를 시간차를 두고 여러 번 호출해서 테스트 데이터를 만들고 배치를 실행했습니다.
그런데 희한하게도 한 번 호출했을 때 생성된 100개의 데이터 중 앞의 Chunk 크기만큼만 발행되고 나머지는 발행되지 않는 현상이 발생했습니다.
가령, Chunk 크기가 10이고 다음 그림과 같이 2번 Procedure를 실행해 A1~A100, B1~B100 데이터를 생성했을 때,
A1~A10, B1~B10까지만 발행되고 나머지는 발행되지 않았습니다.
© 2024.Kurly.All right reserved
그리고 이 이슈의 원인은 MySqlPagingQueryProvider의 Pagination 전략에 있었습니다.
초기 버전의 PagingQueryProvider와 문제점
처음 만들었던 PagingQueryProvider 는 다음과 같습니다.
fun outboxSendReadQueryProvider(
id: Long?,
): PagingQueryProvider {
val provider = SqlPagingQueryProviderFactoryBean()
provider.setDataSource(dataSource)
provider.setSelectClause("""
SELECT
t1.id, t1.message_payload,
t1.message_topic, t1.message_status,
t1.try_count, t1.created_at, t1.updated_at
""".trimIndent())
provider.setFromClause("""
FROM outbox t1
""".trimIndent())
provider.setWhereClause("""
WHERE 1=1
""".trimIndent() +
(id?.let { "AND t1.id = :id " }
?: """ AND t1.message_status in (:status)
AND t1.try_count < :tryCount
AND t1.created_at BETWEEN :startDateTime AND :endDateTime""".trimMargin())
)
provider.setSortKeys(mapOf("t1.created_at" to Order.ASCENDING))
return provider.`object`
}이렇게 하면 Chunk 크기만큼 씩 offset, limit을 변경해 가며 쿼리를 구성할 것으로 예상했지만, 실제로 실행된 쿼리는 다음처럼 전혀 달랐습니다.
-- first page query
SELECT
t1.id, t1.message_payload,
t1.message_topic, t1.message_status,
t1.try_count, t1.created_at, t1.updated_at
FROM outbox t1
WHERE 1=1
AND t1.message_status in (:status)
AND t1.try_count < :tryCount
AND t1.created_at BETWEEN :startDateTime AND :endDateTime
ORDER BY t1.created_at ASC LIMIT 100
-- remaining page query
SELECT
t1.id, t1.message_payload,
t1.message_topic, t1.message_status,
t1.try_count, t1.created_at, t1.updated_at
FROM
outbox t1
WHERE (1=1
AND t1.message_status in (:status)
AND t1.try_count < :tryCount
AND t1.created_at BETWEEN :startDateTime AND :endDateTime
AND ((t1.created_at > :_t1.created_at))
ORDER BY t1.created_at ASC LIMIT 100왜 이런 결과가 나온 걸까요??
원인은 MySqlPagingQueryProvider에 있었습니다.
public class MySqlPagingQueryProvider extends AbstractSqlPagingQueryProvider {
// 생략 ..
@Override
public String generateRemainingPagesQuery(int pageSize) {
if (StringUtils.hasText(getGroupClause())) {
return SqlPagingQueryUtils.generateLimitGroupedSqlQuery(this, buildLimitClause(pageSize));
}
else {
return SqlPagingQueryUtils.generateLimitSqlQuery(this, true, buildLimitClause(pageSize));
}
}
private String buildLimitClause(int pageSize) {
return new StringBuilder().append("LIMIT ").append(pageSize).toString();
}
}이렇게 MySqlPagingQueryProvider는 Remaining Query를 만들 때 LIMIT만을 사용하게 되어 있었습니다.
저는 Group Clause를 설정하지 않았기 때문에 SqlPagingQueryUtils.generateLimitSqlQuery 메서드를 따라 들어갔습니다.
private static void buildWhereClause(AbstractSqlPagingQueryProvider provider, boolean remainingPageQuery,
StringBuilder sql) {
if (remainingPageQuery) {
sql.append(" WHERE ");
if (provider.getWhereClause() != null) {
sql.append("(");
sql.append(provider.getWhereClause());
sql.append(") AND ");
}
buildSortConditions(provider, sql);
}
else {
sql.append(provider.getWhereClause() == null ? "" : " WHERE " + provider.getWhereClause());
}
}그 결과 위와 같이 WHERE 절에 뭔가 수상한 동작을 하는 부분을 발견했습니다. buildSortConditions 메서드 에서는 QueryProvider의 sortKey를 기준으로 새로운 조건을 추가하고 있었습니다.
즉, MySqlPagingQueryProvider는 Pagination을 위해 이전 Chunk의 마지막 SortKey를 기억하고 있다가, 그 SortKey보다 큰 값을 가진 Row를 다음 Chunk로 가져오는 방식으로 동작합니다.
이 마지막 SortKey는 JdbcPagingItemReader의 내부 클래스인 PagingRowMapper에서 startAfterValues에 저장하게 되어있습니다.
private class PagingRowMapper implements RowMapper<T> {
@Override
public T mapRow(ResultSet rs, int rowNum) throws SQLException {
startAfterValues = new LinkedHashMap<>();
for (Map.Entry<String, Order> sortKey : queryProvider.getSortKeys().entrySet()) {
startAfterValues.put(sortKey.getKey(), rs.getObject(sortKey.getKey()));
}
return rowMapper.mapRow(rs, rowNum);
}
}이슈의 원인과 개선된 버전의 PagingQueryProvider
위에서 예로 들었던 Chunk 크기 10의 상황에서 created_at을 sortKey로 사용하고 테스트데이터를 일괄로 생성했을 때 발생한 이슈의 원인은 다음과 같았습니다.
- 첫 번째 쿼리 수행 (A1~A10) 조회 후 A10의 created_at 값을 startAfterValues에 저장
- 두 번째 퀴리 수행 시 Pagination을 위해
created_at > A10.created_at조건을 추가- 이때, A1~A100까지는 created_at이 동일하기 때문에 다음 조건에서 필터링되고, 그 대신 B1~B10을 조회
- B1~B10까지 조회 후 B10의 created_at 값을 startAfterValues에 저장 …
outbox 테이블의 id 컬럼이 MySQL의 auto_increment로 생성된 컬럼이었기 때문에,
sort key를 id로 변경하니 순서도 보장되고 문제도 해결되었습니다.
fun outboxSendReadQueryProvider(
id: Long?,
): PagingQueryProvider {
val provider = SqlPagingQueryProviderFactoryBean()
provider.setDataSource(dataSource)
provider.setSelectClause("""
SELECT
t1.id, t1.message_payload,
t1.message_topic, t1.message_status,
t1.try_count, t1.created_at, t1.updated_at
""".trimIndent())
provider.setFromClause("""
FROM outbox t1
""".trimIndent())
provider.setWhereClause("""
WHERE 1=1
""".trimIndent() +
(id?.let { "AND t1.id = :id " }
?: """ AND t1.message_status in (:status)
AND t1.try_count < :tryCount
AND t1.created_at BETWEEN :startDateTime AND :endDateTime""".trimMargin())
)
provider.setSortKeys(mapOf("t1.id" to Order.ASCENDING))
return provider.`object`
}두 번째 이슈 : MySqlPagingQueryProvider의 Pagination 전략 (With group clause, table alias)
두 번째 이슈는 AML(Anti Money Laundering) 프로젝트에서 컬리의 모든 거래내역 데이터를 솔루션에 전달하기 위한 배치를 개발하다가 마주했습니다.
좀 더 간략히 설명해 드려 보자면 table alias가 포함된 sort key + group clause 조합에서 발생한 문제였습니다.
AML 시스템에서 거래내역 데이터가 생성되는 흐름을 간략히 설명해 드리자면 다음과 같습니다.
- 결제 서비스는 결제 메시지를 발행합니다.
- AML 서비스는 이 메시지를 Consume하여 결제이력 테이블에 적재합니다.
- AML 배치에서는 이 결제이력 데이터를 읽어 가공한 뒤 솔루션에 전달하기 전 임시 테이블에 적재합니다.
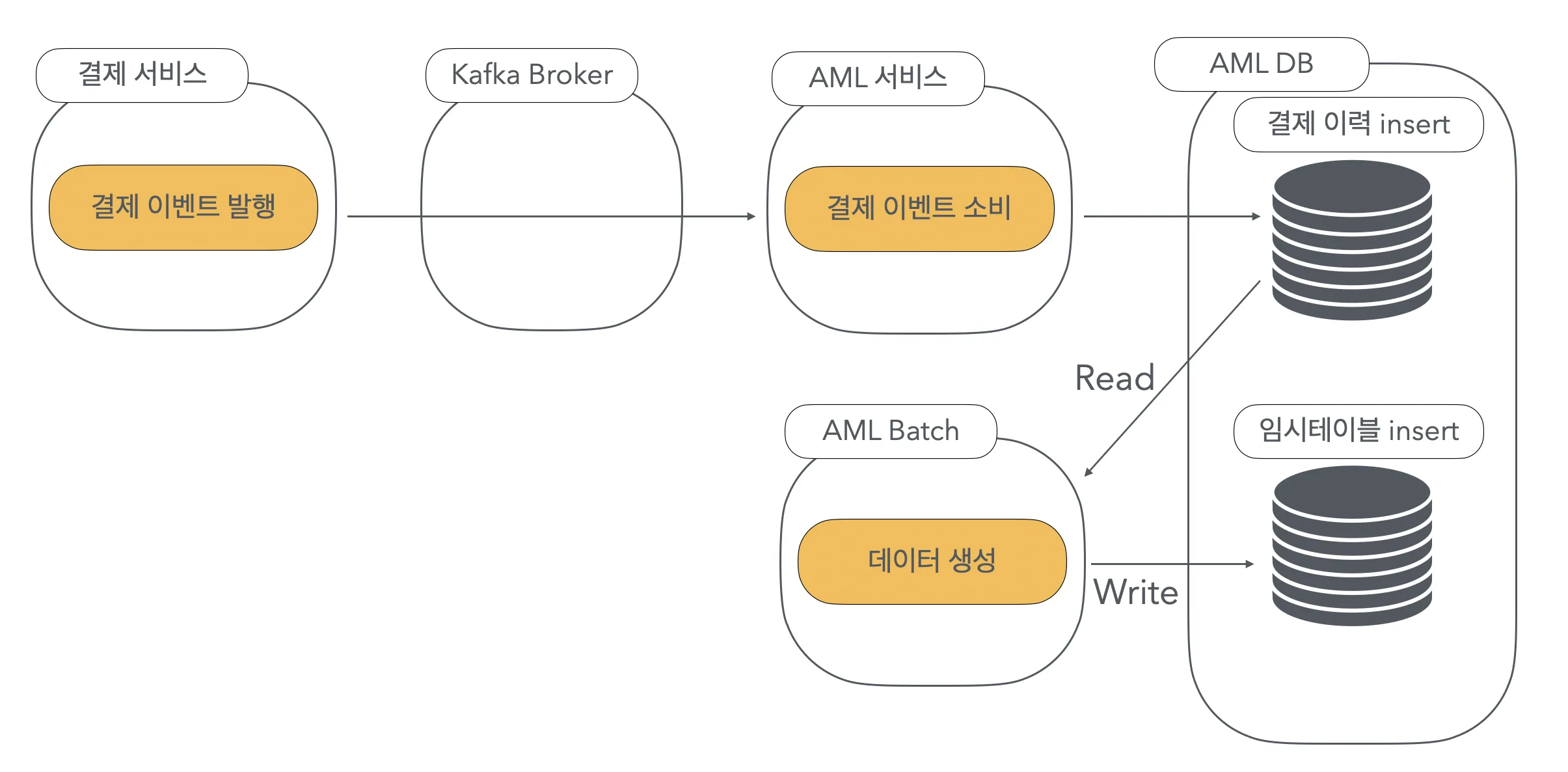
© 2024.Kurly.All right reserved
하나의 파트너 ID(컬리에 입점한 파트너)에 대한 결제이력/취소이력과 금액 조회해야 했는데, 부분취소 때문에 같은 주문 번호로 취소 데이터가 여러 건 존재할 수 있었습니다.
그래서 파트너 ID별로 그날의 전체 취소 금액을 얻기 위해 group by를 사용했습니다.
왜 첫 페이지에서만 동작하지?
첫 번째 페이지에서는 정상적으로 데이터가 조회되었지만,
두 번째 페이지부터는 데이터가 조회되지 않고 SQLSyntaxErrorException이 발생했습니다.
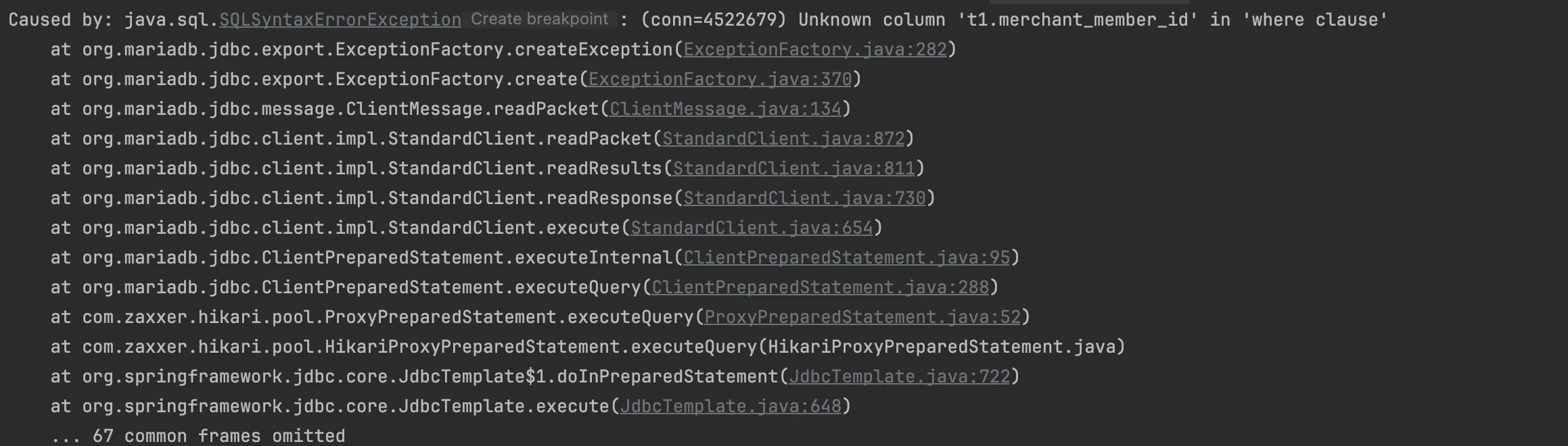
© 2024.Kurly.All right reserved
예외 메시지를 보면 where 조건 내에 t1.merchant_member_id를 찾지 못했음을 알 수 있습니다.
이제 왜 이런 문제가 발생했는지 살펴보겠습니다.
초기 버전의 PagingQueryProvider와 문제점
처음 만들었던 PagingQueryProvider 는 다음과 같습니다.
여기서 주목해야 할 점은 group clause가 포함되어 있고, sort key에 table alias로 t1 이 붙어있다는 점입니다.
private fun paymentReadQueryProvider(dataSource: DataSource): PagingQueryProvider {
val provider = SqlPagingQueryProviderFactoryBean()
provider.setDataSource(dataSource)
provider.setSelectClause(
"""
SELECT
// 생략..
SUM(t1.cancel_amount) AS cancel_amount,
// 생략..
""".trimIndent(),
)
provider.setFromClause(
"""
FROM payment_history t1
""".trimIndent(),
)
provider.setWhereClause(
"""
WHERE t1.payment_day = :paymentDate
""".trimIndent(),
)
provider.setGroupClause(
"""
GROUP BY
t1.payment_day,
t1.merchant_member_id,
t1.order_no
""".trimIndent(),
)
provider.setSortKeys(mapOf("t1.merchant_member_id" to Order.ASCENDING))
return provider.`object`
}이렇게 만들어진 MySqlPagingQueryProvider는 이렇게 생긴 Remaining Query를 만들어냅니다.
SELECT *
FROM (SELECT
-- 생략..
SUM(t1.cancel_amount) AS cancel_amount,
-- 생략..
FROM payment_history t1
WHERE 1 = 1
AND t1.payment_day = :paymentDate
GROUP BY t1.payment_day,
t1.merchant_member_id,
t1.order_no) AS MAIN_QRY
WHERE ((t1.merchant_member_id > :_t1.merchant_member_id))
ORDER BY t1.merchant_member_id ASC
LIMIT 10000;앞서 살펴본 MySqlPagingQueryProvider의 Pagination 전략대로 WHERE 조건에 sort key로 추가한 t1.merchant_member_id 기준으로 조건문이 생기는걸 볼 수 있는데요.
그 바로 앞부분에 정체불명의 MAIN_QRY가 붙습니다.
MAIN_QRY로 한번 감싸기 때문에 t1이라는 table alias를 찾지 못했던 것이었습니다.
자, 다시 한번 MySqlPagingQueryProvider의 generateRemainingPagesQuery 메서드를 보겠습니다.
@Override
public String generateRemainingPagesQuery(int pageSize) {
if (StringUtils.hasText(getGroupClause())) {
return SqlPagingQueryUtils.generateLimitGroupedSqlQuery(this, buildLimitClause(pageSize));
}
else {
return SqlPagingQueryUtils.generateLimitSqlQuery(this, true, buildLimitClause(pageSize));
}
}이번엔 group clause가 포함되어 있으니 generateLimitGroupedSqlQuery 메서드로 가보겠습니다.
public static String generateLimitGroupedSqlQuery(AbstractSqlPagingQueryProvider provider, String limitClause) {
StringBuilder sql = new StringBuilder();
sql.append("SELECT * ");
sql.append(" FROM (");
sql.append("SELECT ").append(provider.getSelectClause());
sql.append(" FROM ").append(provider.getFromClause());
sql.append(provider.getWhereClause() == null ? "" : " WHERE " + provider.getWhereClause());
buildGroupByClause(provider, sql);
sql.append(") AS MAIN_QRY ");
sql.append("WHERE ");
buildSortConditions(provider, sql);
sql.append(" ORDER BY ").append(buildSortClause(provider));
sql.append(" ").append(limitClause);
return sql.toString();
}generateLimitGroupedSqlQuery 메서드를 보면 알 수 있듯이, MySqlPagingQueryProvider는 group clause가 포함된 경우 MAIN_QRY라는 이름의 Inline View를 생성합니다
그리고 그 뒤에 pagination을 위한 sort key 조건을 추가합니다.
이슈의 원인과 개선된 버전의 PagingQueryProvider
위에서 설명해 드린 것처럼 group clause가 포함된 경우 아래 순서로 Remaining Query가 생성됩니다.
where clause와group clause로MAIN_QRY inline view생성- pagination을 위한 조건문 추가
- order by 추가
MySqlPagingQueryProvider를 만들 때 sort key를 세팅하면 부모 클래스인 AbstractSqlPagingQueryProvider의 Map 타입 필드 (필드명: sortKeys)에 저장되는데요.
이 sortKeys 필드의 key를 기반으로 2, 3번 과정을 수행하기 때문에 sort key에 넣은 t1이라는 alias가 이런 문제를 일으켰습니다.
따라서 sort key에 table alias를 넣지 않고 column name만 넣어주면 문제가 해결됩니다.
private fun paymentReadQueryProvider(dataSource: DataSource): PagingQueryProvider {
val provider = SqlPagingQueryProviderFactoryBean()
provider.setDataSource(dataSource)
provider.setSelectClause(
"""
SELECT
// 생략..
SUM(t1.cancel_amount) AS cancel_amount,
// 생략..
""".trimIndent(),
)
provider.setFromClause(
"""
FROM payment_history t1
""".trimIndent(),
)
provider.setWhereClause(
"""
WHERE t1.payment_day = :paymentDate
""".trimIndent(),
)
provider.setGroupClause(
"""
GROUP BY
t1.payment_day,
t1.merchant_member_id,
t1.order_no
""".trimIndent(),
)
provider.setSortKeys(mapOf("merchant_member_id" to Order.ASCENDING))
return provider.`object`
}요약
MySqlPagingQueryProvider는 Where 조건으로 page를 나눈다!
JdbcPagingItemReader 와 MySqlPagingQueryProvider를 사용하면 sort key를 where 절에 추가하는 방식으로 Paging 합니다.
따라서, sort key를 결정할 때 이 점을 꼭 염두에 두어야 합니다.
참고로 JdbcPagingItemReader의 공식 문서에도 데이터 유실을 막기 위해서 Sort Key는 Unique 제약조건이 걸린 컬럼을 사용해야 한다고 적혀 있었습니다.

MySqlPagingQueryProvider는 grouping 할 때 inline view를 만든다!
MySqlPagingQueryProvider는 group by 절이 포함되어 있을 때, MAIN_QRY라는 이름의 Inline View를 생성합니다.
따라서 group clause가 포함된 경우 sort key에 table alias를 넣지 않도록 주의해야 합니다.
마치며
컬리에서 처음으로 spring-batch 애플리케이션을 개발했기 때문에 기대 반 설렘 반으로 개발했습니다.
초반에는 부끄럽게도 다른 개발자가 만들어둔 소스를 분석하여 따라서 개발했는데요. 그래서 이런 이슈들을 맞닥뜨렸습니다.
역시 맹목적으로 따라 하는 것보다는 스스로 찾아보며 이해하는 게 중요하다는 것을 몸소 느꼈습니다. 🥲
또, spring-batch의 내부 동작을 이해하고 제가 만든 애플리케이션의 이슈를 해결하다 보니 성취감도 있었습니다.
개발자로 일하다 보면 여러 가지 프레임워크를 다루게 될 텐데요. 프레임워크의 동작 방식을 직접 살펴보는 게 생각보다 재밌었습니다.
끝으로 바쁘신 와중에 틈내서 검수해 주신 박병찬님, 박주용님, 최지원님께 감사의 말씀을 전하며 글을 마치겠습니다.