안녕하세요, 커머스 프로덕트 주문플랫폼개발 팀 소속 박재현입니다.
작년부터 Gen AI 기술이 주목을 받으며, 2024년에는 실제 운영 환경에서 LLM 서비스를 구성하려는 시도들이 많아졌습니다. 이런 시도들의 일환으로 컬리 커머스 프로덕트 팀에서도 다양한 실험을 진행했습니다. 그 중 한 가지가 이번 글에서 소개 드릴 리뷰 요약 서비스입니다.
리뷰 요약 서비스는 이미 많은 시도가 있었던 기능이지만, 이번 글에서는 컬리에서 어떻게 LLM의 활용 범위를 넓혔는지, 또한 LLM 서비스를 설계 및 구현하며 어떤 고민을 했는지 공유하고자 합니다. 또한 Gen AI 기술과 LLM 활용 방법을 접하고 다양한 시도를 해보면서 얻은, 고객들에게 새로운 가치를 전달할 수 있는 서비스를 만들어갈 수 있을지 고민했던 경험들도 이번 글을 통해 나누려 합니다.
이번 시도에 대한 상세한 경험은 2가지 파트로 나누어져있으며, 각 파트 별로 정리된 내용은 다음과 같습니다.
📌 1. Prompt Engineering을 활용한 비정형 데이터 검수 실험
첫 번째로 소개 드릴 내용은 단순히 여러 개의 리뷰를 요약하는 정도의 prompt 작성 대신, 유용한 정보의 리뷰 선별 실험에 대한 내용을 정리해 보았습니다.
📌 2. 리뷰 요약 서비스 설계 및 구축 공유
두 번째 파트에선 prompt 당 task를 최소화하는 전략부터, LLM 응답에 의존도를 낮출 수
있는 사람의 개입 전략까지 해당 서비스의 PoC를 진행하며 고민했던 내용들을 소개 드릴 예정입니다.
PoC의 시작점
컬리엔 고객 분들께서 작성해주신 소중한 리뷰가 있습니다. 리뷰엔 단순히 고객들의 선호도 뿐만 아니라, 어떤 맛인지, 어떻게 소비하고 있는 지 등 소비자의 주관이 많이 담긴 넓은 범위의 정보를 상품 상세 정보만큼 혹은 그보다 더 많이 가지고 있어요.
단적인 예로, 식료품의 경우 소비자들의 캠핑, 집들이와 같이 제품을 구매하기 좋은 이벤트부터, 본인들만의 레시피까지 리뷰라는 콘텐츠 안에 녹입니다. 이런 리뷰 속에 흩어진 많은 정보를 요약해서 한눈에 볼 수 있다면, 유저들이 상품을 구매하는 데 도움이 될 수 있지 않을까 하는 생각으로 ‘상품 속성 정보를 풍부하게 내포하는’ 리뷰 요약 LLM 서비스를 기획했습니다.
기존에도 유저들에게 다양한 정보를 전달하기 위해 베스트 리뷰 라는 콘텐츠를 내부적인 검수, 선정 과정을 통해 제공하고 있어요. 그만큼 베스트 리뷰 는 질적, 양적으로 많은 정보를 내포하고 있는 리뷰입니다.
© 2024. Kurly. All rights reserved.
저의 첫 번째 시도인 베스트 리뷰 요약은 이렇게 검증된 리뷰들을 간략히 요약해서 제공하는 것을 목표로 진행하게 되었습니다.
베스트 리뷰 요약 결과 및 한계점
말씀드린 것과 같이 베스트 리뷰는 내부 검수 및 선별을 통해 퀄리티가 보장되어 있는 만큼, 다양한 정보들을 내포하고 있습니다.
아래 결과는 베스트 리뷰를 상품별로 요약한 내용입니다.

© 2024. Kurly. All rights reserved.
첫 번째 시도만에 이 정도 퀄리티의 요약을 받을 수 있다니 완전 럭키비키잖아? 는 일어날 리가 없죠…
항상 처음 시도는 아쉬운 부분이 있을 수 밖에 없는 것처럼 실제 운영 콘텐츠로서 전달되기엔 아래와 같은 한계점들이 존재했습니다.
베스트 리뷰 요약의 한계점
- 베스트 리뷰가 존재하는 상품들이 한정적이다.
- 베스트 리뷰가 1개만 존재할 경우 요약 콘텐츠는 필요하지 않다.
- 선정된 베스트 리뷰가 없는 경우 리뷰의 시의성이 보장되지 않는다.
베스트 리뷰 요약 서비스는 선정된 베스트 리뷰가 없는 상품엔 제공되지 않았습니다. 그 결과, 스테디 셀러 상품들을 제외한 다수의 상품에 대해 리뷰 요약 콘텐츠를 제공할 수 없었습니다. 이는 범용적으로 활용할 수 없다는 한계를 낳았습니다.

© 2024. Kurly. All rights reserved.
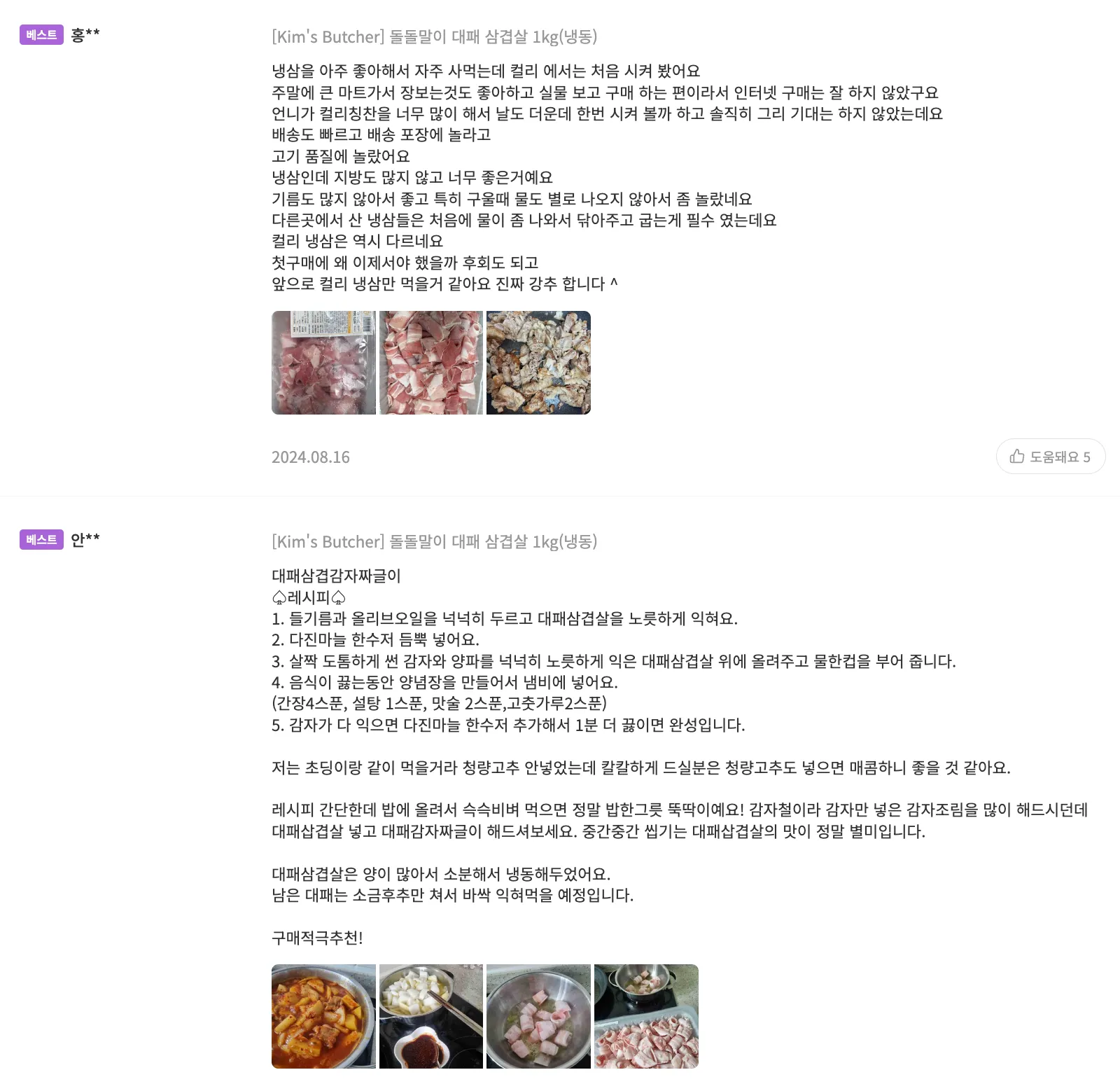
베스트 리뷰가 1개만 존재하는 경우도 장애물이 되었습니다. 1개의 베스트 리뷰를 요약하면 동일한 내용의 콘텐츠가 생성되었고, 불필요한 요약 작업을 수행하게 됩니다. 위에서 첨부한 왼쪽 이미지는 “[모로칸오일] 헤어 트리트먼트” 상품의 베스트 리뷰인데요, 유사한 내용을 동일한 색상으로 표시해 보았습니다. 이 때, 베스트 리뷰와 요약 정보는 순서나 사용한 단어만 다를 뿐 동일한 내용을 보여줍니다.
베스트 리뷰는 1주일에 1회씩 일부 상품에 한해 업데이트됩니다. 그렇기 때문에 선정되지 않은 상품의 베스트 리뷰 요약은 시기에 맞춰 업데이트되지 못합니다. 신선 식품, 제철 식품의 리뷰는 상품의 시기에 따른 퀄리티를 포함하고 있기 때문에, 상품 구매 결정에 큰 요소가 됩니다. 위의 “[모로칸오일] 헤어 트리트먼트 상품”의 리뷰는 이미지에서 확인할 수 있듯 2023년에 선정되었습니다. 시기에 맞는 고객들의 목소리를 확인하기 위해선 조금 더 넓은 범위의 리뷰를 요약해야 했습니다.
정리하자면, 베스트 리뷰를 활용한 요약 서비스는 2가지 한계를 노출했습니다.
범용성 : 리뷰 요약 정보를 제공하는 대상 상품이 제한적
시의성 : 최신 정보를 반영하는 것의 어려움
리뷰 요약 서비스만을 위한 리뷰 선별 작업
이렇게 저의 첫 번째 시도는 1. 리뷰 요약 대상 확장, 2. 리뷰 요약 대상 중 유용한 정보를 가지고 있는 리뷰를 선별 이라는 숙제를 남겼습니다.
그럼 요약을 위해 선별된 리뷰들이 충족해야 하는 조건에는 무엇이 있을까요?
요약 대상 리뷰들의 선별 조건
- 최신성 : 현재를 기준으로 특정 기간 내 작성된 리뷰들
- 관련성 : 대상 상품이 아닌 다른 상품의 정보 내포 여부
- 부정 후기 여부 : 부정적인 정보를 내포하고 있는 리뷰 여부
- 정보 제공도 : 상품 속성 정보를 가지지 않은 단순 긍, 부정의 리뷰 (예: 맛있어요!, 좋아요!) 여부
최신성을 만족하는 리뷰는 조회 기간을 한정 짓는 것만으로 필터링을 할 수 있지만, 그 외 조건들을 선별하려면 단순한 서비스 로직 구현만으로는 불가합니다. 리뷰 콘텐츠가 비정형 데이터인만큼 각 문장의 문맥 파악, 긍부정 스코어링 등을 판단할 수 있는 ML 모델을 구축하고 분석/검수를 거치는 과정이 지금까지는 필요했습니다.
여기서 주목했던건 LLM의 강점인데요. LLM의 강점은 아래와 같이 표현되곤 합니다.
- 텍스트 생성 : 다양한 주제와 스타일로 자연스러운 텍스트를 생성할 수 있는 능력.
- 컨텍스트 요약 : 긴 텍스트나 복잡한 정보를 핵심 요점으로 간결하게 요약하는 능력.
- 문맥 파악 : 주어진 텍스트의 맥락과 의도를 정확히 이해하고 해석하는 능력.
- 추론 (Inference, Reasoning) : 주어진 정보를 바탕으로 논리적 결론을 도출하거나 새로운 아이디어를 제시하는 능력.
그 외 다양한 생성 작업 (코드 작성과 같은)
이 중 컨텍스트 요약, 문맥 파악, 추론에 집중하고, LLM을 리뷰 선별자로서 역할을 부여하기 위해 몇 가지 실험을 하게 되었습니다.
실험 1. 각 조건에 대해 필터링을 성공적으로 수행하는가?
첫 번째 실험으로 LLM에게 위 리뷰 선별 조건들을 직접 판단하고 조건을 모두 충족하면 true, 아니라면 false로 응답하도록 prompt를 작성했습니다.
그 결과, 명확하게 판별할 수 있는 리뷰에 대해서 필터링에 성공한 것을 아래와 같이 확인할 수 있었어요.
| product (STRING) | review (STRING) | result (Boolean) |
|---|---|---|
| [더마펌] 수딩 리페어 마스크 R4 (5매) | 재구매템! 최애 마스크팩 되었어요 써봤던 마스크팩 중에 제일 괜찮아요 투명시트인데 밀착력도 좋고 순해요 에센스 많이 들어서 있어서 좋네요 촉촉함이 정말 좋아요 더 많이 팔았음 더 좋겠네요~~ | true |
| [모로칸오일] 헤어 트리트먼트 100ml | 가볍게 발라지고 묵직하지 않아조아요 모르간오일 쓰다가 다른거 못써요^^ | true |
| [삼삼물산X이태리식탁] 크림 관자 그라탕 | 관자가 쫄깃하니 맛있어요 양은 간단히 먹기 좋은양 | true |
| [연안식당] 부추 꼬막 비빔장 | 혼자 간단하게 한끼 먹고 싶을 때 딱이에요ㅎㅎㅎㅎ 전부 다 넣으면 짜서 양념장은 조금 넣어보고 조절하시는 거 추천드려요 | true |
| [더마펌] 수딩 리페어 마스크 R4 (5매) | 항상 쓰던 제품이예요! 특별한날에는 언제나 잊지않고 써서 이번에 컬리에서도 판매중이길래 쟁여두려고 구매했어요! | false |
| [모로칸오일] 헤어 트리트먼트 100ml | 배송도 하루만에 받았어요 세일할적에 잘 구매했어요 | false |
| [연안식당] 부추 꼬막 비빔장 | 생각보다 양이 엄청 작아요…괜히산듯.. | false |
| [연안식당] 부추 꼬막 비빔장 | 맛있을것 같아요 잘먹을게요 | false |
하지만, 저는 LLM의 필터링 결과만을 받았을 때 그 결과를 신뢰할 수 있을까? 라는 의문점을 가지게 되었고, 자연스럽게 아래 질문을 하게 되었습니다.
LLM의 판단 근거가 정확하고 충분히 논리적인가?
LLM의 판단 근거를 가시적으로 확인할 수 있는가?
만약 질문들을 답변할 수 있다면 결론의 정확성 향상, 결론 도출의 투명성을 얻어낼 수 있다고 생각했고, 이를 해결하기 위해 두 번째 실험을 진행하게 되었습니다.
실험 2. 필터링 결과를 신뢰할 수 있는가? (w. Reasoning)
실험 1을 바탕으로 제시한 질문들을 답변하기 위해 리뷰를 검수 하며 ‘LLM의 해당 결론을 내린 이유’에 대해서 알고 싶었었는데요. 저는 이 과정을 Reasoning 단계라 지칭하고, LLM이 직접 판단하고 그 근거를 응답값에 함께 전달하도록 prompt를 작성했습니다.
| product (STRING) | review (STRING) | result (Boolean) | reason (STRING) |
|---|---|---|---|
| [더마펌] 수딩 리페어 마스크 R4 (5매) | 재구매템! 최애 마스크팩 되었어요 써봤던 마스크팩 중에 제일 괜찮아요 투명시트인데 밀착력도 좋고 순해요 에센스 많이 들어서 있어서 좋네요 촉촉함이 정말 좋아요 더 많이 팔았음 더 좋겠네요~~ | true | 리뷰는 [더마펌] 수딩 리페어 마스크 R4 (5매)에 대한 것이며, 부정적인 내용을 포함하지 않고, 상품 속성에 대한 충분한 정보를 제공하고 있습니다. 예를 들어, 밀착력, 순함, 에센스 양, 촉촉함 등에 대해 언급하고 있습니다. |
| [모로칸오일] 헤어 트리트먼트 100ml | 가볍게 발라지고 묵직하지 않아조아요 모르간오일 쓰다가 다른거 못써요^^ | true | 제공된 리뷰는 [모로칸오일] 헤어 트리트먼트 100ml에 대한 것으로, 부정적인 내용이 포함되어 있지 않으며, 상품의 속성에 대한 구체적인 내용(가볍게 발라지고 묵직하지 않다는 점)을 포함하고 있습니다. |
| [삼삼물산X이태리식탁] 크림 관자 그라탕 | 관자가 쫄깃하니 맛있어요 양은 간단히 먹기 좋은양 | true | 리뷰는 [삼삼물산X이태리식탁] 크림 관자 그라탕에 대한 것이며, 부정적인 내용을 포함하지 않고, 관자의 식감과 양에 대한 구체적인 정보를 제공하고 있습니다. |
| [연안식당] 부추 꼬막 비빔장 | 혼자 간단하게 한끼 먹고 싶을 때 딱이에요ㅎㅎㅎㅎ 전부 다 넣으면 짜서 양념장은 조금 넣어보고 조절하시는 거 추천드려요 | true | 리뷰는 [연안식당] 부추 꼬막 비빔장에 대한 것이며, 부정적인 내용을 포함하지 않고, 상품 속성에 대한 구체적인 내용을 포함하고 있습니다. 예를 들어, ‘전부 다 넣으면 짜서 양념장은 조금 넣어보고 조절하시는 거 추천드려요’라는 부분이 상품 사용 방법에 대한 유용한 정보를 제공하고 있습니다. |
| [더마펌] 수딩 리페어 마스크 R4 (5매) | 항상 쓰던 제품이예요! 특별한날에는 언제나 잊지않고 써서 이번에 컬리에서도 판매중이길래 쟁여두려고 구매했어요! | false | 리뷰는 [더마펌] 수딩 리페어 마스크 R4 (5매)에 대한 것으로 보이지만, 상품 속성에 대한 구체적인 내용이 부족합니다. 단순히 제품을 항상 사용하고 특별한 날에 사용한다고 언급했을 뿐, 제품의 구체적인 속성이나 효과에 대한 정보는 포함되어 있지 않습니다. |
| [모로칸오일] 헤어 트리트먼트 100ml | 배송도 하루만에 받았어요 세일할적에 잘 구매했어요 | false | 제공된 리뷰는 [모로칸오일] 헤어 트리트먼트 100ml에 대한 내용이 아니라 배송과 세일에 대한 언급만 포함되어 있어, 제품에 대한 구체적인 정보나 속성이 부족합니다. |
| [연안식당] 부추 꼬막 비빔장 | 생각보다 양이 엄청 작아요…괜히산듯.. | false | 리뷰는 [연안식당] 부추 꼬막 비빔장에 대한 것이지만, 부정적인 내용을 포함하고 있으며, 상품 속성에 대한 충분한 정보를 제공하지 않습니다. |
| [연안식당] 부추 꼬막 비빔장 | 맛있을것 같아요 잘먹을게요 | false | 리뷰는 [연안식당] 부추 꼬막 비빔장에 대한 것으로 보이지만, 리뷰 내용이 단순한 긍정적 표현(맛있을것 같아요 잘먹을게요)만 포함하고 있어 상품 속성에 대한 충분한 정보를 제공하지 않습니다. |
이러한 추론 과정을 명시적 LLM에게 짚고 넘어가도록 하는 기법은 아래의 2가지 장점을 가질 수 있습니다.
장점1. 정확성 향상
첫 번째는 LLM이 조금 더 정확한 결과를 낼 수 있도록 하는 장점이 있습니다.
Reasoning은 LLM에게 아래 3가지를 제공함으로써 응답의 정확도를 향상하게 됩니다.
-
재검토 과정 : LLM은 결론의 근거를 찾고 제시하는 과정에서 자신의 결론을 재검토를 하게 됩니다.
-
논리적 일관성 확보 : 근거와 결론 사이의 논리성을 확인하며 근거와 결론 사이의 일관성을 제공합니다. 이에 따라, 결론의 정확도는 올리면서 합리적인 근거를 제공 받을 수 있습니다.
-
오류 감지 및 수정 기회 확보 : 근거를 찾지 못하거나 근거가 결론과 모순될 경우, LLM은 자신의 오류를 감지하고 수정할 기회를 갖습니다.
이렇듯, 단순하게 결론에 대한 근거를 제시하여 응답하는 prompt 작성만으로 LLM의 응답값의 정확성을 더 높일 수 있습니다.
장점2. 투명성 향상 두 번째는 모델 및 결론 도출 과정의 투명성을 보장할 수 있습니다.
요즘 대부분의 사람들이 hallucination이라는 단어를 아는 만큼, LLM의 신뢰도는 항상 의문점을 가지게 합니다. 더군다나, 현재까지도 자동화하기 힘들었던 검수 과정에서의 역할을 LLM이 완벽하게 해낼 수 있다는 것은 어불성설일 수 있다고 생각합니다. 모델의 발전은 지속적으로 이뤄지지만 정확도에 대한 의문점은 항상 있는 만큼, 단순히 LLM 모델의 업데이트를 기다리는 것도 무의미할 수 있습니다.
이런 상황에서 LLM의 결론 도출 과정을 모니터링 하는 것이 신뢰성 있는 LLM Application을 만드는 전략이 될 수 있습니다.
이렇게 LLM의 판단 근거를 응답으로 받아 운영자가 모니터링 하면 잘못된 결론에 대한 케이스를 선별할 수 있게 됩니다. 이 후, 발생 케이스 원인 파악 후 prompt를 수정, 혹은 결론 도출 방식을 변경하여 더 신뢰성 있는 서비스를 만들기 위한 지속적인 개선이 가능해집니다.
리뷰가 거치는 검수 조건들의 단계 (w. CoT)
다양한 실험들을 통해 작성된 prompt의 예시는 아래와 같습니다. 리뷰 조건을 명시한 검증 단계를 눈여겨 봐주세요.
너는 텍스트 리뷰를 읽고 작성자의 의도를 파악 해내는 리뷰 분석가야.
사용자들의 작성한 리뷰를 바탕으로 긍/부정을 명확히 평가해내고 무의미한 리뷰와 상세한 정보를 가지고 있는 리뷰를 판별할 수 있어.
함께 전달된 상품의 리뷰인지 아닌지도 너는 알 수 있어.
{product_name}의 리뷰가 제공 될 거고 각 리뷰를 아래 단계 순서대로 검증해줘.
검증 단계:
1. 제공된 리뷰가 {product_name} 외 다른 제품에 대한 리뷰가 포함되지 않은 리뷰인가?
2. 제공된 리뷰가 부정적인 내용을 포함하지 않은 리뷰인가?
3. 단순한 긍,부정 (맛있다, 좋다 등) 외에 제공된 리뷰가 상품 속성에 대한 내용을 충분히 포함하고 있는 리뷰인가?
리뷰:
{review}
만약 모든 검증 단계를 통과하면 "true"를 반환하고, 그렇지 않으면 "false"를 반환해줘.
제공된 응답 포맷에 맞춰서 결과를 반환해줘.
"result": "true" or "false",
"reason": "" // 종합적으로 result에 대한 사유를 설명각 리뷰가 검증을 통과할 수 있을지 없을지 단계를 나눠 확인하고, 그 결과와 근거를 함께 응답하도록 prompt를 작성했습니다.
이렇게 작성된 prompt는 ‘상품 정보를 많이 내포하고 있는지 검수’라는 크고 모호한 task를 세부적인 단계를 나눈 CoT 기법을 활용하여 검증의 정확성을 높일 수 있습니다.
그렇다면 CoT란 무엇일까요?
CoT (Chain of Thought)
CoT란, Prompt Engineering에 가장 많이 언급되는 기법 중 하나로 LLM이 복잡한 조건에 대한 결과를 정확하게 낼 수 있도록 문제를 해결하는 과정을 일련의 세분화된 단계로 명시하는 방법입니다.
실제로 CoT는 LLM의 활용도를 높여주는 기법의 시작점이라고 할 수 있습니다. 단순히 LLM이 채팅봇 혹은 요약 서비스가 아닌 문제 해결 및 판단을 스스로 할 수 있는 개체로서 역할을 하기 위해 CoT를 활용한 문제 해결은 많은 가능성을 열어준다고 볼 수 있죠.
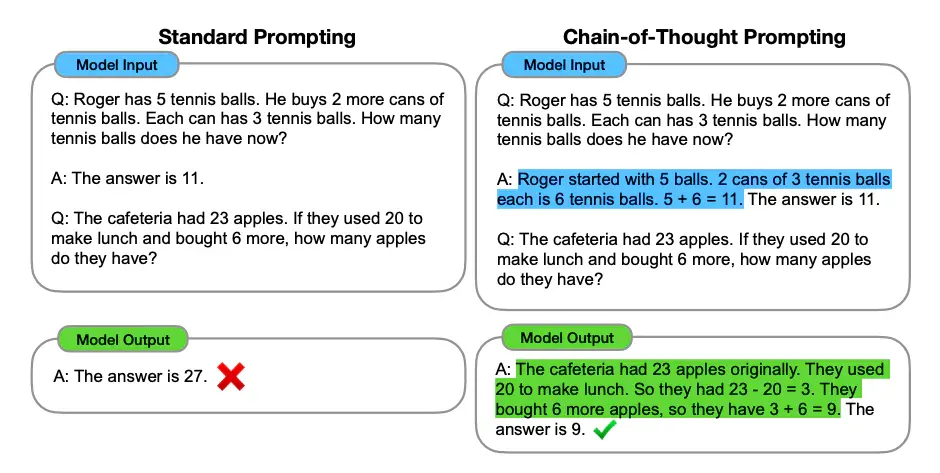
CoT를 설명할 때 가장 자주 등장하는 예시 prompt입니다. Input의 A를 보면 단계적 답변을 예시로 전달하며 본 질문을 단계적으로 풀어나가는 걸 확인할 수 있습니다. 그 결과, 모델이 단계를 거쳐 응답하며 조금 더 정확한 결론에 도달하는 것을 확인할 수 있습니다.
위 이미지와 같이 응답의 예시를 함께 전달하는 방식을 Few-Shot CoT라고도 부릅니다. 반대로, 예시 전달 없이 LLM에게 ‘think step by step’(단계적으로 생각해봐)하도록 유도하는 방식도 있는데요. 이런 방식은 Zero-Shot CoT라고 부르고 있습니다.

이렇듯 CoT Prompting은 LLM으로 하여금 문제를 세부 단계로 나눠서 해결하도록 유도할 수 있습니다. 이를 통해, LLM은 단계적인 추론과 함께 더 정확한 결론에 도달할 수 있습니다.
결과물
Prompt 내 검증 단계를 위와 같이 명시적으로 작성한 후 Reasoning 했을 때, 아래와 같이 나오게 됩니다.

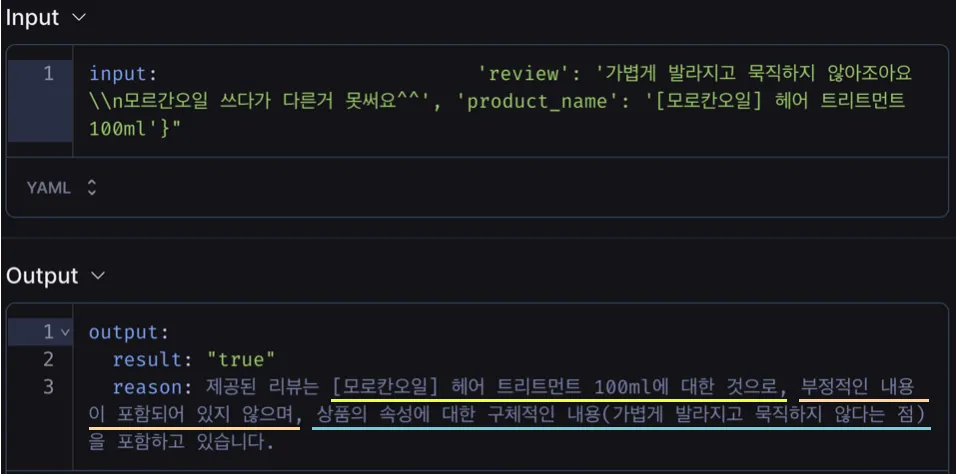
 각 검증 단계에 대한 LLM의 평가 및 근거를 위 이미지에서 동일한 색상으로 밑줄 쳐 표현했습니다.
이를 통해 LLM이 결론을 내기 위해 검증 단계를 순차적으로 거치는 것을 확인할 수 있습니다.
각 검증 단계에 대한 LLM의 평가 및 근거를 위 이미지에서 동일한 색상으로 밑줄 쳐 표현했습니다.
이를 통해 LLM이 결론을 내기 위해 검증 단계를 순차적으로 거치는 것을 확인할 수 있습니다.
결론적으로, 검증 단계를 명시적으로 세분화하여 prompt에 작성하고 LLM이 Reasoning 단계를 거치도록 하면서 성공적인 리뷰 검수를 할 수 있었습니다.
1부를 마치며
이번 글에서는 LLM을 활용한 비정형 데이터 검수 실험에 대해 살펴보았고, 이를 통해 몇 가지 중요한 점을 확인할 수 있었습니다.
첫째, LLM은 기존에 많은 데이터 사이언스 리소스가 필요했던 비정형 텍스트 분석 작업을 훨씬 더 쉽고 효율적으로 수행할 수 있게 해줍니다. 머신러닝이나 딥러닝 모델을 구축하고 튜닝하는 복잡한 과정 없이도, LLM을 통해 텍스트 데이터에서 의미 있는 인사이트를 추출할 수 있게 되었습니다.
둘째, Prompt Engineering의 강력함을 재확인할 수 있었습니다. 적절한 prompt 설계만으로도 LLM의 다양한 기능을 활성화하고 원하는 결과를 얻을 수 있습니다. 이는 LLM 활용에 있어 Prompt Engineering이 얼마나 중요한 역할을 하는지 보여줍니다.
마지막으로, Reasoning 기법의 중요성이 두드러졌습니다. LLM에게 추론 과정을 명시적으로 요구함으로써 결과의 정확성을 높이고, 동시에 결론 도출 과정의 투명성을 확보할 수 있었습니다. 이는 LLM 기반 시스템의 신뢰성과 해석 가능성을 크게 향상시키는 핵심 요소입니다.
이러한 발견들은 LLM을 활용한 비정형 데이터 분석의 가능성을 넓히고, 더 효과적이고 신뢰할 수 있는 AI 시스템 구축의 토대가 될 것 같습니다. 앞으로 LLM 기술이 더욱 발전하면서, 이러한 접근 방식이 다양한 분야에서 어떻게 적용되고 확장될 지 기대됩니다.
2부에서는 LLM을 활용한 리뷰 요약 서비스를 설계하면서 직면한 문제들과 고민들에 대해서 정리해보려 합니다. 긴 글 읽어주셔서 감사합니다!