개요
- 퍼플 박스 배송 완료 사진의 수기 검수 비용을 93% 절감
- 퍼플 박스와 종이봉투 배송 유형 추적 자동화
- 데이터 엔진을 활용해 적은 라벨링 비용으로 객체 탐지 학습 데이터 확보
- 라벨 개선 및 재학습 주기를 통해 목표 모델 성능 달성
- [Update] 비닐 상태 배송 탐지 기능 추가 이후 수기 검수 필요 건 99.8% 감소, 도입 이후 비닐 상태 배송 건 수 25% 감소로 서비스 품질 개선에 기여
프로젝트의 필요성
안녕하세요. 컬리 데이터서비스개발팀의 ML Engineer 윤준호입니다. 컬리에서 상품을 주문하실 때 퍼플 박스를 사용해 본 경험이 있으신가요? 퍼플 박스를 선택하면, 배송 기사님이 고객님의 문 앞에 놓인 퍼플 박스 안에 상품을 넣어 안전하게 배송해 드립니다.
하지만 간혹 퍼플 박스 배송을 요청했음에도 박스를 내놓지 않으신 고객님들이 계십니다. 이런 경우, 기사님은 상품의 신선도를 유지하기 위해 종이봉투에 담아 배송을 진행합니다.
컬리에서는 이처럼 배송 과정에서 발생하는 다양한 상황을 배송 완료 사진을 통해 검수하고 있습니다. 특히, 퍼플 박스나 종이봉투를 사용하지 않고 상품이 그대로 배송된 경우, 신선도 저하의 위험이 크기 때문에 빠른 확인과 조치가 매우 중요합니다.
이러한 검수 과정을 효율적으로 자동화하고, 배송 품질을 높이기 위해 본 프로젝트가 필요하게 되었습니다.
목적: AI 기반 배송 완료 사진 검수
본 프로젝트의 목적은 촬영된 배송 완료 사진에서 퍼플 박스와 종이봉투를 탐지해 배송 현황 파악을 자동화하고, 두 객체가 모두 없어 신선도 저하가 의심되는 경우만 사람에게 확인하도록 하여 수기 검수 비용을 줄이는 것이 목적입니다.
[Update] 최종적으로는 두 객체가 모두 없고, 비닐 상태 배송이 탐지된 경우를 운영자가 확인하도록해여 수기 검수 비용을 줄이도록 했습니다.
방법 (Data-Centric Approach)
배송 완료 사진 객체 탐지 모델을 학습하기 위해, “Data-centric AI” 철학을 따라 데이터 품질과 라벨링 전략에 초점을 맞추었습니다.
목표로 하는 성능을 달성하기 위해 얼마나 많은 학습 데이터가 필요할지 모릅니다. 따라서, 목표 성능에 달성할 때까지 점진적으로 학습 데이터를 늘려가며, 라벨링 비용을 최소화하기 위해 아래와 같은 데이터 엔진을 사용했습니다.
데이터 엔진
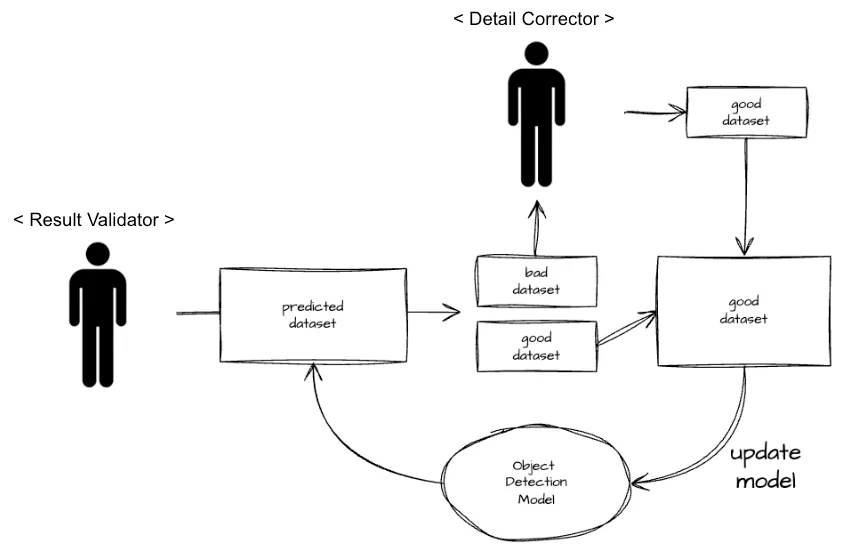
모든 사진에 대해 객체 탐지용 주석(클래스 정보, 바운딩 박스)을 직접 라벨링 하는 것은 비용이 크기때문에, 모델의 추론 결과가 잘못되었다고 판단된 주석만 수정하도록 했습니다. 데이터 품질을 개선하고 모델의 성능을 향상시키기 위해 아래의 단계를 반복합니다(새로운 문제를 풀고, 오답 노트를 작성하는 사람의 학창 시절 학습 과정과 유사해 보이기도 합니다).
step 1. 라벨이 없는 데이터에 대한 추론
라벨이 없는(unlabeled) 이미지들을 추론하여 class 정보와 bounding box 정보를 포함하는 가짜 라벨(pseudo label)을 생성합니다. 재학습 주기마다 1일 동안 수집된 배송 완료 사진들을 추론하였습니다.
step 2. 라벨링 품질 개선
라벨링 품질 개선 과정에는 사람이 개입합니다. 두 종류의 라벨러가 이 과정에 참여합니다.
-
결과 검증자(Result Validator): Step 1에서 추론한 가짜 라벨의 시각화 결과를 확인하여, 바운딩 박스가 올바르게 표시되었는지에 대해 긍정/부정 이진 분류를 수행합니다.
-
세부 수정자(Detail Corrector): 결과 검증자가 부정으로 분류한 가짜 라벨을 확인하여, 세부 어노테이션(bounding box)을 직접 수정합니다.
step 3. 재학습을 통한 모델 개선
마지막으로, 모델 재학습 단계입니다. step 1, 2를 거쳐 개선된 데이터를 학습 데이터 세트에 추가하여 모델을 재학습합니다.
© 2025. Kurly. All right reserved.
모델
객체 탐지 모델은 YOLOv11을 사용했으며, Ultralytics를 활용하면 간단한 코드로 전처리, 데이터 증강 등이 포함된 학습을 쉽게 할 수 있습니다.
결과
퍼플 박스 탐지
퍼플 박스 탐지 모델의 경우, 리뷰 도메인에서 사용되고 있던 모델을 초기 모델로 사용하였습니다.
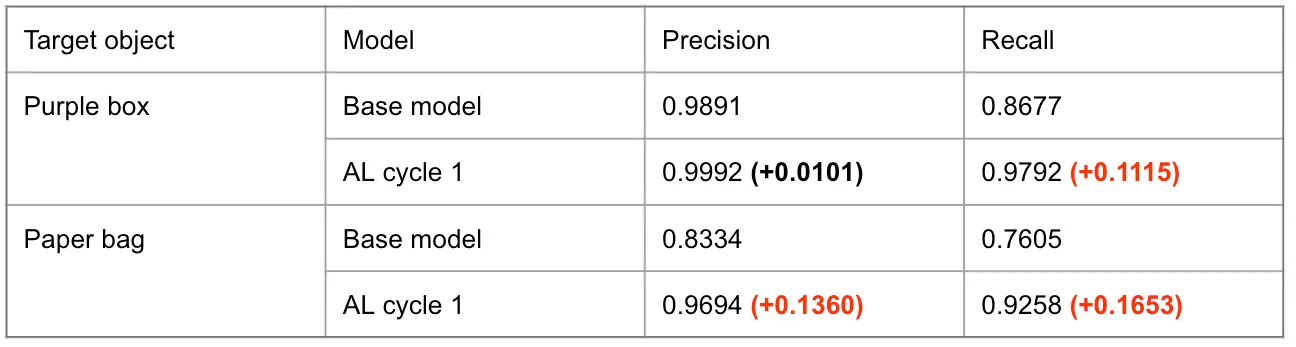
리뷰 모델을 처음 사용했을 때는 precision 0.9891, recall 0.8677의 성능을 보였습니다.
배송 완료 도메인에 fine-tuning 겸 라벨링 개선 주기를 1회 거친 후에는 precision 0.9992, recall 0.9792로 성능이 향상되었습니다.
이 과정에서 학습 데이터의 가짜 라벨 중 주석(bounding box)을 직접 수정한 경우는 7%에 불과했습니다.
종이봉투 탐지
종이봉투 탐지 모델은 초기 모델이 없었기 때문에, 275장에 대한 주석을 직접 라벨링 한 뒤 모델을 학습하여 초기 모델을 마련했습니다.
초기 모델의 성능은 precision 0.8334, recall 0.7605였습니다.
라벨링 개선 주기를 1회 거친 후에는 precision 0.9694, recall 0.9258로 성능이 향상되었습니다.
이 과정에서 학습 데이터의 가짜 라벨 중 주석을 직접 수정한 경우는 6%에 불과했습니다.
논의
AI 모델 vs 인간
배송 기사분들은 배송 완료 후 퍼플 박스 배치 여부를 앱에 기록하고 계시는데, 퍼플 박스 탐지 모델의 결과는 배송 기사님의 기록과 91.3% 일치했습니다.
나머지 8.7%의 의견이 갈린 배송 완료 사진에 대해 수기 검수한 결과, 7.3%는 모델이 맞았고, 1.4%는 인간이 맞았습니다.
따라서, AI 모델이 인간보다 높은 퍼플 박스 탐지 성능을 보였습니다.
라벨링 품질 개선 비용
결과적으로 낮은 라벨링 비용으로 만족할 만한 성능을 달성했습니다. 초기 모델의 성능이 일정 수준 이상이었던 덕분에 라벨링 품질 개선 과정에서 바운딩 박스를 직접 수정하는 비율이 퍼플 박스와 종이봉투 모두 10% 미만이었습니다.
본 프로젝트에서는 라벨링 결과를 주고받는 과정이 매뉴얼하게 이루어졌다는 점이 아쉬운 부분입니다. 초기 모델의 성능이 낮거나 탐지가 어려운 객체여서 더 많은 라벨링 개선 주기가 필요할 경우, 전 주기를 MLOps 관점에서 설계한다면 더 효율적인 작업이 가능할 것입니다.
마지막으로, 라벨링 비용을 더 줄이기해, step 2 이전에 예측 결과의 objectness score(객체로 확신하는 정도)가 높은 경우를 먼저 필터링하는 방법을 고려해 볼 수 있습니다. 사람이 전부 개입할 수 없을 정도로 작업량이 많을 경우 필요성이 더 클 것입니다. 하지만, 높은 objectness score로 잘못 탐지한 경우는 여전히 라벨링 품질이 개선되지 않을 위험이 있습니다.
퍼플 박스 탐지 모델의 recall 증가
퍼플 박스 탐지 모델의 재학습 이후 recall이 급증한 원인은 도메인 적응 때문으로 보입니다. 리뷰 이미지의 퍼플 박스는 가려져 있지 않은 경우가 대부분인데, 배송 완료 사진에서는 가려져 있는 퍼플 박스가 자주 등장합니다.
| 도메인 적응 전: 가려진 퍼플 박스 탐지 불가 | 도메인 적응 후: 가려진 퍼플 박스 탐지 성공 |
|---|---|
 |  |
운영 성과
퍼플 박스와 종이봉투 배송 건을 검수 대상에서 제외한 결과, 93%의 수기 검수 비용이 감소했습니다. 추가적인 객체 탐지를 통해 남은 7%를 더 줄일 수 있다면, 향후 작업으로 시도해 보면 좋을 것 같습니다.
[Update] 퍼플 박스와 종이봉투 배송 건을 제외한 나머지 7% 중 비닐 상태로 배송 된 경우를 탐지하여 검수한 결과, 수기 검수가 필요한 건이 99.8% 감소했습니다. 퍼플 박스, 종이봉투, 비닐 상태 배송 탐지를 운영에 적용한 후 비닐 상태 배송이 25% 감소하여 서비스 품질 개선에도 기여했습니다.
이 글을 마치며
레이블링 작업에 도움을 주신 컬리넥스트마일 관계자분들께 감사드립니다.