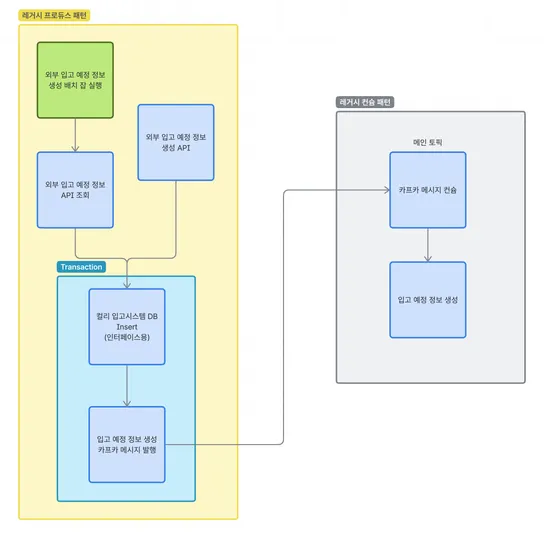
들어가며
안녕하세요, 컬리 SCM 프로덕트 개발팀의 박지환입니다.
이번 글에서는 레거시 기반의 원천 데이터를 어떻게 이벤트 기반 구조로 전환했는지, 그리고 스파이크성 트래픽을 안정적으로 집계하기 위해 Kafka Streams의 윈도우(Window) 를 어떻게 도입했는지에 대해 이야기해보려고 합니다.
Kafka Streams의 기본 개념에 익숙하신 분이라면, 실제 서비스 환경에서 어떤 고민을 했고 어떻게 풀어갔는지 보다 현실적으로 느끼실 수 있을 것입니다.
이번 글에서는 개발 과정에서 마주한 문제와 그 해결 과정을 함께 공유해 드리니, 비슷한 고민을 하고 계신 분들께 작은 도움이 되었으면 합니다.
도입 배경
정산 프로세스를 구축하는 과정에서, 기존처럼 배치 기반으로 정산을 처리할 것인지, 아니면 이벤트 기반으로 Kafka를 활용할 것인지에 대한 내부 검토를 진행했습니다.
배치 방식은 한 번에 많은 데이터를 처리하기에 구현은 단순하지만, 데이터가 누적될 때까지 기다려야 하므로 실시간성 확보가 어렵고, 대용량 처리를 하기 때문에 특정 시간에 시스템 부하가 일어날 수도 있습니다.
그 결과,
- 준실시간 정산 처리 가능성 확보
- Kafka 토픽 발행을 통한 서비스 확장성 향상
이러한 장점을 바탕으로, Kafka 기반의 이벤트 처리 방식을 선택하게 되었습니다.
다만, 컬리는 주문 마감 및 새벽 도착 보장이라는 비즈니스 특성상, 스파이크성 트래픽이 특정 시간대에 몰리는 문제가 존재했습니다.
이러한 데이터를 효율적으로 처리하고,
정산 단위에 맞춰 시간 기반 집계를 안정적으로 수행하기 위해
Kafka Streams의 윈도우(Window) 기능을 도입하게 되었습니다.
요구사항
이번 작업의 주요 요구사항은 아래와 같았습니다:
- 5분 단위로 수집된 원천 데이터(재고 변동 이력)를 Kafka로 발행
- 데이터 생성 시간 기준으로 데이터를 5분마다 수집 후 Kafka Topic 발행
- 스파이크성 데이터는 상품 코드 기준으로 일정 시간 간격(예: 5분)으로 집계
- 스파이크성 데이터는 특정 시점에 몰리기 때문에, 단건 저장하기보단 일정 시간 기준으로 상품 코드별 수량을 집계하여 저장해야 함
- 스파이크성 데이터 외 데이터는 집계 없이 정산 테이블에 즉시 반영
이 중 핵심 포인트는 요구사항 2번 스파이크성 데이터의 집계 방식이었습니다.
스파이크성 데이터는 특정 시간대에 데이터가 집중적으로 몰리는 성격이 있어 건별로 적재하면 DB 부하가 급증할 수 있습니다.
따라서 “상품 코드 + 일정 시간 간격” 기준으로 스파이크성 데이터를 집계하고, 정해진 시점마다 단 한 번만 저장되도록 설계했습니다.
Kafka Streams의 윈도우란?
Kafka Streams는 Kafka 위에서 동작하는 스트리밍 처리 라이브러리로, 시간 단위로 데이터를 묶어 집계하는 데 최적화된 기능을 제공합니다.
예를 들어, 5분 단위로 들어오는 스파이크성 데이터를 상품 코드 기준으로 묶어 합계를 낼 수 있습니다.
Kafka Streams의 윈도우 종류
| 종류 | 설명 |
|---|---|
| 텀블링 윈도우 (Tumbling Window) | 고정된 시간 간격으로 겹치지 않게 데이터를 묶음 (예: 5분 단위) |
| 호핑 윈도우 (Hopping Window) | 일정 간격마다 겹치면서 윈도우를 시작 (예: 5분 윈도우, 1분 간격 시작) |
| 세션 윈도우 (Session Window) | 사용자 활동을 기준으로 윈도우 구성 (비정형 구간) |
| 슬라이딩 윈도우 (Sliding Window) | Kafka 3.0부터 도입, 이벤트 발생 시마다 윈도우 생성 |
우리는 왜 텀블링 윈도우를 선택했는가?
이벤트 데이터 집계는 다음의 조건을 만족해야 했습니다.
- 이벤트가 겹치지 않아야 한다.
- 하나의 이벤트는 정확히 하나의 윈도우 구간에만 속해야 합니다.
- 집계된 데이터는 단 한 번만 발행되어야 한다.
- 중복 저장이나 다중 집계를 방지해야 합니다.
이를 만족하기 위해 고정된 간격으로 겹치지 않게 동작하는 텀블링 윈도우를 선택했습니다.
예시코드
@Autowired
public void shipmentStreams(StreamsBuilder streamsBuilder) {
KStream<String, InventoryTransactionDto> stream = streamsBuilder.stream(
sourceTopic,
Consumed.with(STRING_SERDE, TRANSACTION_DTO_SERDE)
);
stream
.groupByKey(Grouped.with(STRING_SERDE, TRANSACTION_DTO_SERDE))
// 윈도우 시간 5분 / 유예 시간 1분
.windowedBy(TimeWindows.ofSizeAndGrace(Duration.ofMinutes(5), Duration.ofMinutes(1)))
// 수량 집계
.reduce(this::aggregateTransactions)
// 중간집계는 발행하지 않고, 최종결과만 발행
.suppress(Suppressed.untilWindowCloses(Suppressed.BufferConfig.unbounded()))
.toStream()
.map((key, value) -> KeyValue.pair(key.key(), value))
.to(toTopic, Produced.with(STRING_SERDE, TRANSACTION_DTO_SERDE));
}
private InventoryTransactionDto aggregateTransactions(InventoryTransactionDto aggregateDto,
InventoryTransactionDto newDto) {
return InventoryTransactionDto.from(newDto, aggregateDto.quantity() + newDto.quantity());
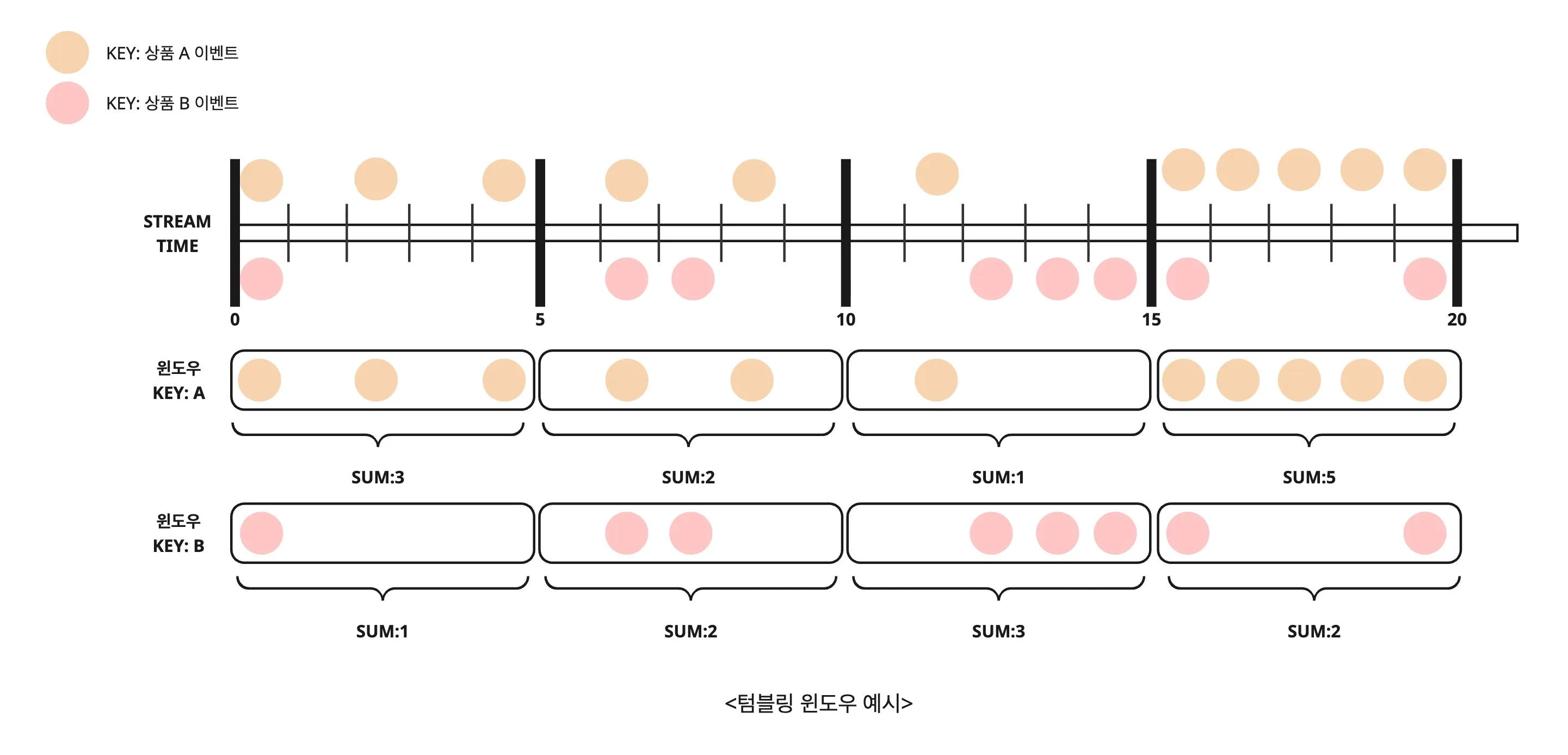
}아래는 Kafka Streams의 텀블링 윈도우를 적용한 데이터 집계 시각화 예시입니다. 상품 코드(Key) 별로 5분 단위의 윈도우를 정의하고, 각 구간 내의 이벤트를 count 하여 집계합니다.
예를 들어, 상품 A는 00~05분 사이에 3건의 이벤트가 있었고, 06~10분 사이에는 2건의 이벤트가 있습니다. 각각의 윈도우는 서로 겹치지 않으며, 집계는 윈도우 종료 시점에 단 한 번만 발행됩니다.
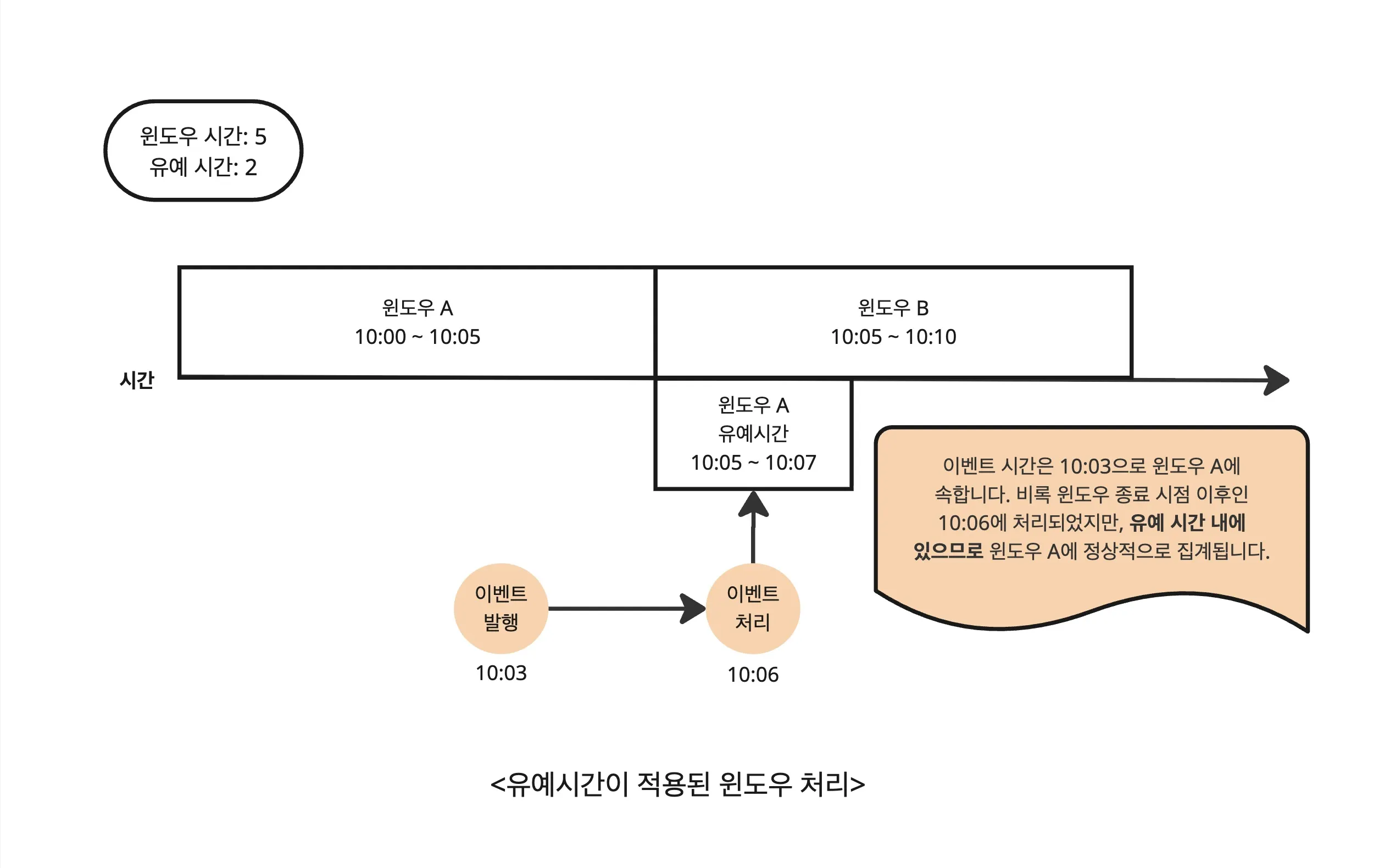
유예 시간이란 무엇인가?
유예 시간(grace period) 은 윈도우가 닫히기 전에 늦게 도착한 이벤트를 얼마나 기다려줄 것인지를 결정하는 기준입니다.
실시간 데이터 처리 환경에서는 네트워크 지연이나 시스템 처리 순서 차이로 인해 이벤트가 늦게 도착할 수 있는데, 유예 시간은 이러한 ‘지각생 이벤트’를 허용해주는 시간 범위를 의미합니다.
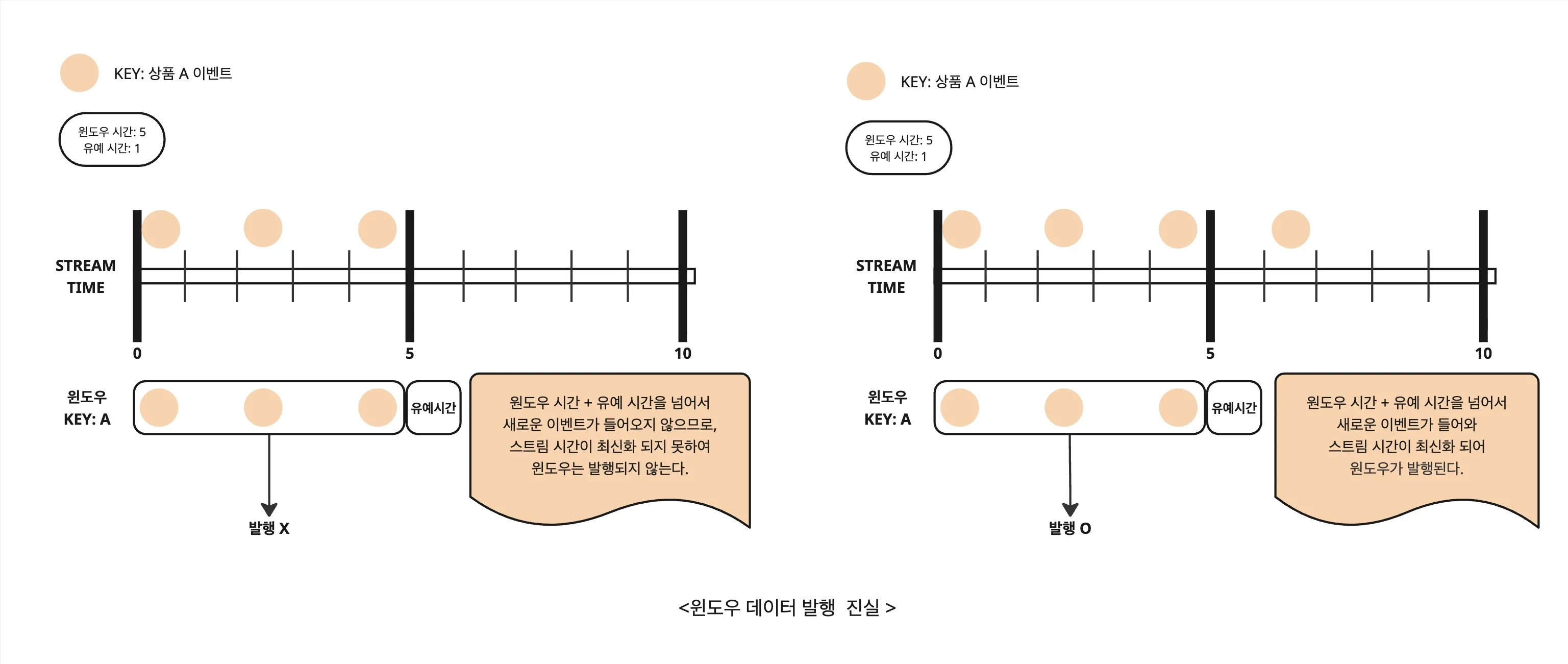
윈도우 발행 시점의 오해와 진실
Kafka Streams에서 윈도우(Window) 기능을 사용할 때 흔히 하는 오해 중 하나는,
“윈도우 시간이 끝나면 곧바로 집계 결과가 발행된다.”
하지만 실제로 윈도우 결과가 발행되는 시점은 단순히 이벤트 시간이 아닌 스트림 시간(Stream Time) 과 깊은 관련이 있습니다.
| 구분 | 의미 |
|---|---|
| 이벤트 시간 | 이벤트 자체가 실제로 발생한 시간 (레코드의 timestamp 기반) - default - 토픽에 발행된 시간 |
| 스트림 시간 | Kafka Streams 내부에서 유지하는 현재까지 처리된 이벤트의 최근 이벤트 시간 - 스트림 시간은 전체 파티션에 걸쳐 들어온 이벤트들 중 가장 최신 이벤트 시간으로 자동 갱신 |
그럼 윈도우는 언제 닫히고, 언제 발행될까?
Kafka Streams에서 윈도우가 닫히고 결과가 발행되는 시점은 단순히 윈도우 시간의 종료 시점이 아닙니다. 아래 조건이 충족되어야만 윈도우 결과가 실제로 발행됩니다.
- 스트림 시간이 윈도우 종료 시점과 그 이후의 유예 시간까지 모두 지나 더 이상 해당 윈도우에 포함될 수 없는 시점에 도달해야 함
즉, 윈도우 시간 동안 들어온 이벤트들만으로는 결과가 절대 발행되지 않습니다. 그 이후의 이벤트가 들어와 스트림 시간을 갱신해줘야 발행이 가능합니다.
시행착오
문제1
데이터 생성 시간과 Kafka 발행 시간의 불일치
현 시스템 한계상 재고 변동 이력을 Kafka로 실시간 스트리밍 전송이 어려운 구조입니다.
이런 제약으로 인해, 데이터를 생성 시간 기준 5분 단위 Batch로 수집한 뒤, Kafka에 5분마다 발행하는 방식을 사용하고 있습니다.
Kafka Streams(윈도우 시간 10분 / 유예 시간 5분)에서는 이 데이터를 기반으로 윈도우 단위 집계를 수행합니다.
그런데 문제는, 정산 비즈니스 특성상 하루 단위 시간 정합성이 매우 중요하다는 점입니다.
예시:
23:59에 생성된 데이터가 실제로는 00:00에 Kafka 발행
Kafka Streams에서는 이 데이터를 다음 날 00:00 ~ 00:05 윈도우에 포함 (00:00 발행 시간 기준으로 이벤트 시간 할당)
결과적으로 잘못된 날의 정산 결과에 포함 → 정산 처리상 이슈 발생
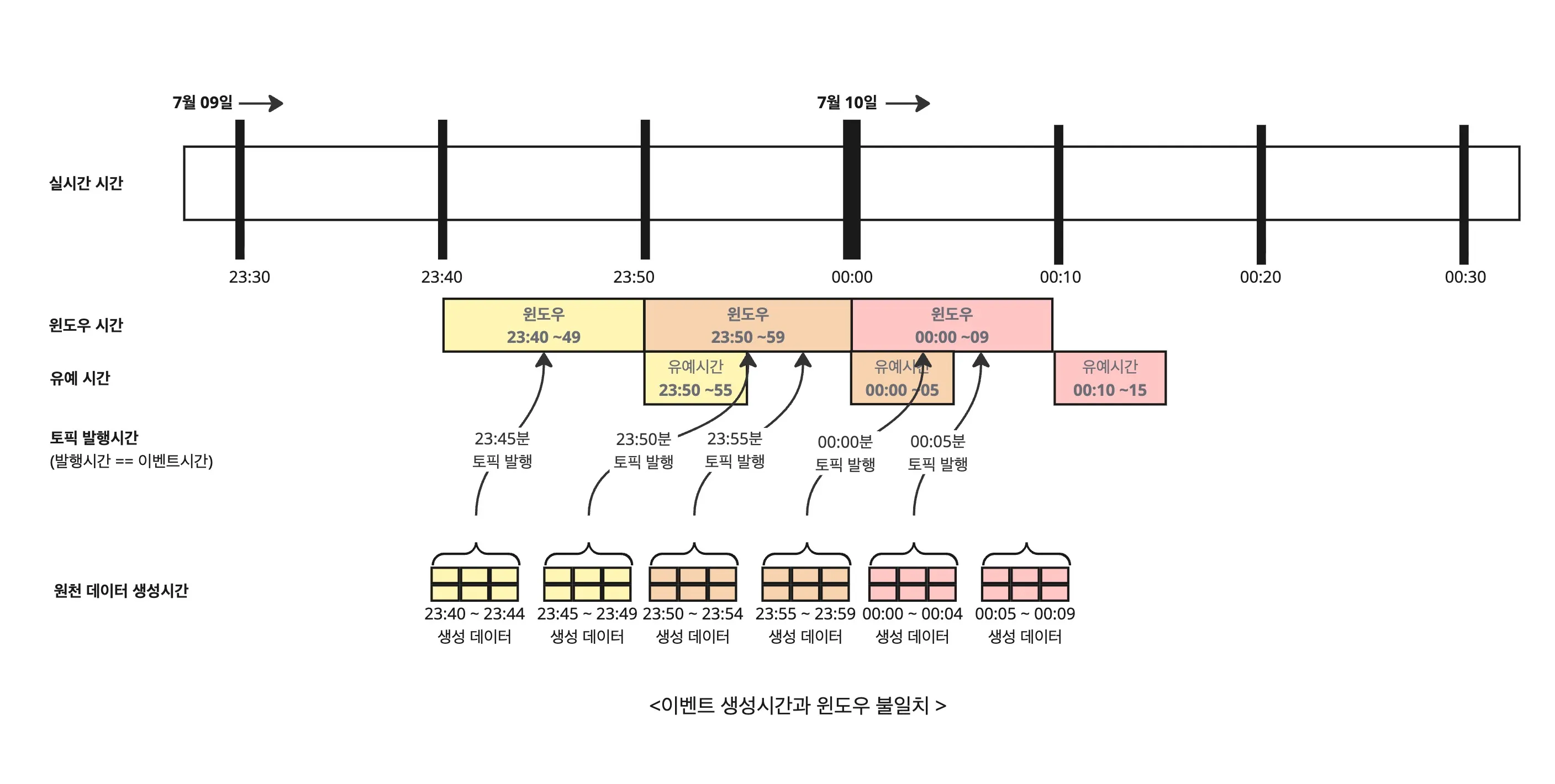
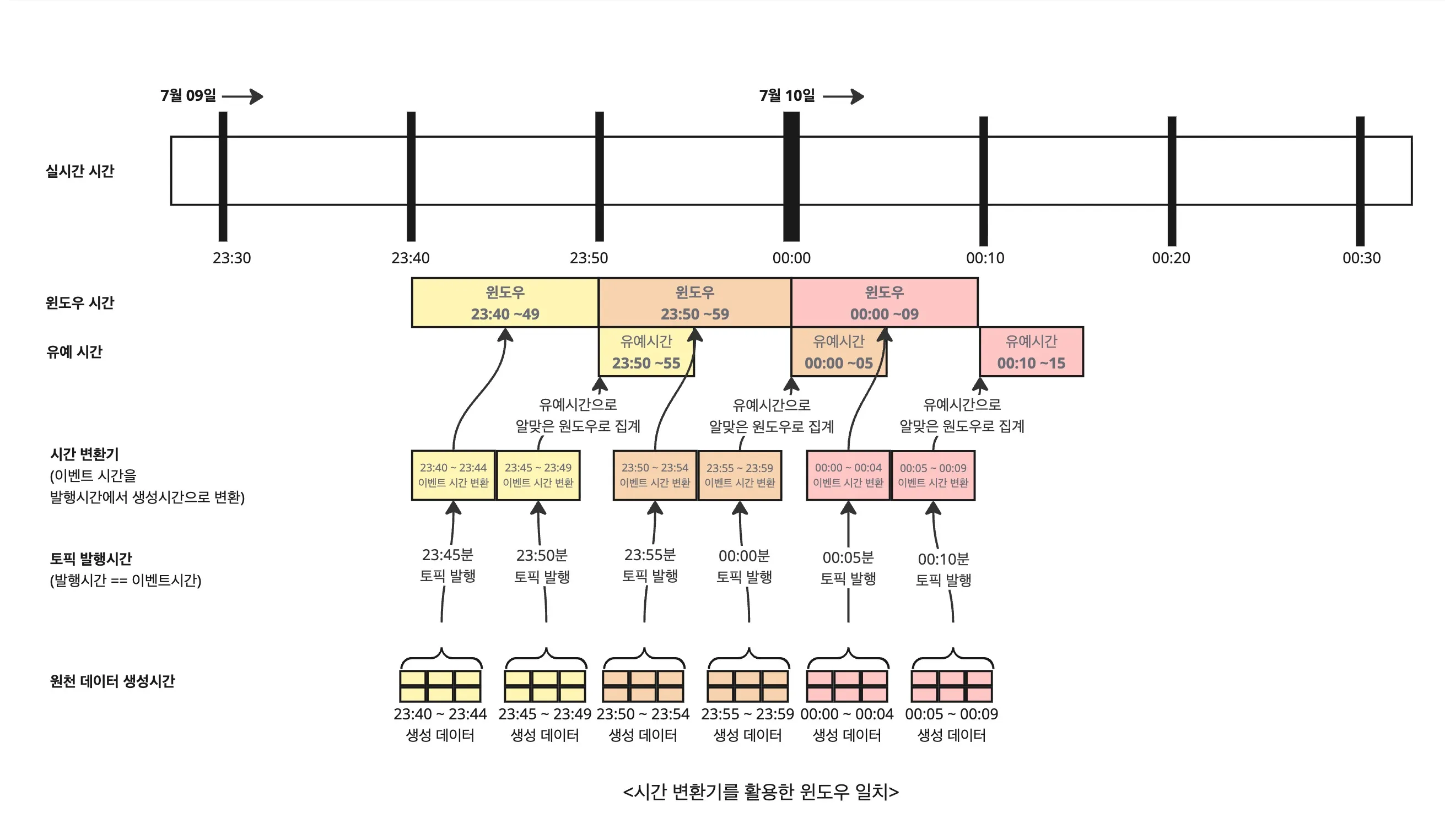
해결: 데이터 생성 시간 기준 이벤트 시간 변환
Kafka Streams는 기본적으로 Kafka 레코드의 발행 시각을 기준으로 윈도우를 할당합니다.
하지만 실제 데이터 생성 시간과 Kafka 발행 시각 사이에 시간 차이가 발생하므로, Kafka Streams가 인지하는 이벤트 시간을 데이터 생성 시간으로 재정의해야 합니다.
이를 위해 Kafka Streams에서는 Timestamp Extractor 기능을 사용합니다.
- TimestampExtractor + Grace Period 사용 시
- 23:59 생성 데이터가 23:50~23:59 윈도우에 정확히 포함
예시 코드
public class EventTimeExtractor implements TimestampExtractor {
@Override
public long extract(ConsumerRecord<Object, Object> record, long partitionTime) {
MyEvent event = (MyEvent) record.value();
return event.getCreatedAt().toInstant().toEpochMilli(); // ← 생성 시간 기준
}
}
문제2
토픽에 새로운 이벤트가 들어오지 않는 시간대에는 윈도우가 어떻게 닫힐까?
위에서 윈도우는 언제 닫히고, 언제 발행될까? 에서 이야기한 것처럼 윈도우 시간 이후 이벤트가 들어와야지 윈도우가 닫힘을 인지하고 발행을 하게 되는데 만약 윈도우 시간 이후 이벤트가 들어오지 않는 경우는 어떻게 해야 할까?
삽질 1: Processor에서 내부 더미 이벤트 발행
“이벤트가 안 오니까 내가 직접 쏴볼까?” Processor 안에서 이렇게 시도해 봤습니다
processorContext.forward(key, new DummyEvent(...));하지만… 아무 일도 일어나지 않았습니다.
왜냐하면 이건 Topology 내부 전파일 뿐, Kafka Streams의 스트림 시간을 진전시키는 이벤트는 아니기 때문입니다.
Kafka Streams는 소스 토픽에서 소비된 레코드의 timestamp로만 스트림 시간을 계산합니다. 즉, 내부에서 forward()를 날려봤자 “시간이 흘렀다” 라는 사실을 인식하지 못합니다.
결론: ❌ 스트림 시간은 멈춰 있고 윈도우도 안 닫힌다.
삽질 2: WindowStore 직접 스캔해서 강제 발행
두 번째 시도는 좀 직접적으로 접근했습니다. “그럼 내가 store에서 직접 꺼내서 쏴버릴게!”
try (KeyValueIterator<Windowed<String>, String> iter = store.all()) {
while (iter.hasNext()) {
KeyValue<Windowed<String>, String> kv = iter.next();
long windowEnd = kv.key.window().end();
// 10초 이상 지난 윈도우는 강제 발행
if (now - windowEnd > 10_000) {
kafkaProducer.publishMessageAsObject(toTopic, "key", "value", context.taskId().partition());
}
}
}결과는? 중복 발행이 발생했습니다.
왜냐하면 Streams 내부에서는 여전히
“이 윈도우는 닫히지 않았다”
라고 알고 있기 때문입니다.
Store에서 강제로 데이터를 꺼내 쏘는 건 “내부 상태를 닫는다” 라는 의미가 아니기 때문에, 다음번에 이벤트가 들어오면 또 같은 윈도우가 다시 발행될 수 있습니다.
결론: ❌ 중복 발행 유발
해결: 외부 더미 이벤트 발행으로 강제 시간 전진
“Kafka Streams의 스트림 시간은 입력 이벤트에 의해서만 움직인다.”
따라서 이벤트가 없을 때는 외부에서 “더미 이벤트”를 주입해서 스트림 시간을 강제로 전진시키면 됩니다.
핵심은 카프카 토픽 레벨에서 dummy 이벤트를 주입하는 것이고, Processor 안에서 파티션 단위로 이를 실행하도록 설계했습니다.
왜 파티션별로 키값을 다르게 해야 할까?
Kafka Streams의 스트림 시간은 파티션별로 독립적으로 관리됩니다.
즉, 모든 더미 이벤트의 키값이 같으면 한 파티션으로 할당 되기 때문에 한 파티션에서만 스트림 시간이 움직이고, 나머지 파티션들은 그대로 멈춰 있게 됩니다.
따라서 파티션별로 분배가 되도록 키를 설정을 하거나 아래처럼 파티션 번호를 직접 지정해서 발행해야 합니다.
이렇게 하면 각 파티션의 스트림 시간이 독립적으로 전진하게 됩니다.
public class WindowClosingProcessor implements Processor<String, InventoryTransactionDto, String, InventoryTransactionDto> {
private ProcessorContext<String, InventoryTransactionDto> context;
private final KafkaProducer<String, InventoryTransactionDto> kafkaProducer;
private final String toTopic;
public WindowClosingProcessor(KafkaProducer<String, InventoryTransactionDto> kafkaProducer, String toTopic) {
this.kafkaProducer = kafkaProducer;
this.toTopic = toTopic;
}
@Override
public void init(ProcessorContext<String, InventoryTransactionDto> context) {
this.context = context;
// 3분마다 트리거 실행 (이벤트가 없어도 실행됨)
this.context.schedule(Duration.ofMinutes(3), PunctuationType.WALL_CLOCK_TIME, timestamp -> {
emitWindowedData();
context.commit();
});
}
private void emitWindowedData() {
// 현재 Task(파티션) 기준으로 더미 이벤트 발행
String topicKey = "dummy-key-" + context.taskId().partition();
kafkaProducer.publishMessageAsObject(
toTopic, // 대상 토픽 이름
topicKey, // 메시지 키
InventoryTransactionDto.emit(), // 발행할 더미 이벤트 데이터
context.taskId().partition() // 발행할 파티션 번호 (직접 지정)
);
}
}시도 및 결과 비교
| 시도 | 결과 | 비고 |
|---|---|---|
| Processor 내부 forward | ❌ 스트림 시간 갱신 안 됨 | 내부 이벤트는 시간 전진 불가 |
| WindowStore 직접 스캔 | ❌ 중복 발행 | 내부 상태 닫힘 인식 X |
| 외부 더미 이벤트 발행 | ✅ 정상 작동 | 스트림 시간 전진 + 윈도우 닫힘 |
후기
Kafka Streams의 윈도우는 동작 원리를 이해하면 단순하지만,
테스트하기가 어렵습니다. 특히 “시간 단위로 집계 결과를 기다려야 하는” 구조이기 때문에,
한 번의 검증에 몇 분씩 소요되는 경우도 많았습니다.
삽질하다 보면 자연스럽게 시야가 점점 좁아지기 마련인데, 이번에도 마찬가지였습니다.
“왜 윈도우가 닫히지 않지?”만 생각하다가
“스트림 시간이 안 흘러서 안 닫히는 거네”라는 단순한 결론을 보지 못했습니다.
그래서 이번 문제를 해결하는 과정에서 팀 스터디와 코드 리뷰가 큰 도움이 되었습니다.
같이 고민하면서 시야를 넓힐 수 있었고, “Kafka Streams는 이벤트 기반으로만 시간이 흐른다” 는 핵심 개념을 다시 한번 깊게 이해할 수 있었습니다.
함께 도와준 팀원들에게 고마움을 전합니다.
또한 정산 로직에 윈도우를 도입하려면 단순히 윈도우 닫힘뿐 아니라 경계 시점(예: 자정 00시) 문제도 중요합니다.
예를 들어,
“00시 이전 윈도우의 데이터가 00시 이후에 들어오면 어떻게 처리할까?”
이처럼 경계 시점에서 발생할 수 있는 다양한 상황에 대한 정책이 명확해야 합니다.
윈도우 단위 정산은 이런 시간 경계 처리, 그리고 문제 발생시 데이터 재계산 로직까지
이벤트 기반으로 처리해야 하므로 설계 단계에서 고려할 것이 훨씬 많습니다.
결국,
윈도우 기반 설계는 단순히 ‘시간을 자르는 일’ 이 아니라
‘시간과 이벤트의 관계를 정의하는 일’ 이라는 점을 이번 개발을 통해서 알게 되었습니다.