도입 계기
여러분! 적치 작업을 멈춰주세요!!!📢📢
때는 2022년 7월, 제가 컬리의 입고프로덕트개발팀에 처음 합류한 어느 날이었습니다. 얼마 전까진 이방인이었다가 이제 막 컬리의 일원이 되어 낯선 환경에 한창 어리둥절하고 있을 때, 슬랙 한 켠에서 알림이 계속해서 울립니다.
“📢 여러분! 적치 작업을 멈춰주세요! 재고 DB 작업 중입니다! 📢 ”
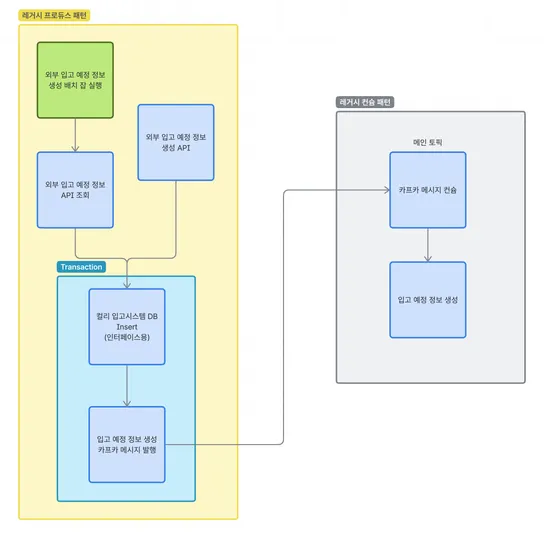
잠깐 컬리의 입고 시스템 구조에 대해 짧은 설명이 필요하겠네요. 컬리의 입고 DB 와 재고 DB 는 물리적으로 분리되어 있습니다.
입고 프로세스를 간단하게만 설명하자면 물건(상품)이 센터에 도착하게 되면, 물건의 수량이 정확한지 확인하는 “검수” 작업과, 물건의 품질이 적합한지 확인하는 “검품” 작업을 거친 후, 물건을 실제 창고 내 특정 위치에 가져다 놓는 “적치” 작업이 완료된 후에 비로소 재고가 생성이 됩니다.
이를 시스템 단위로 다시 나눠서 설명드리면, “검수/검품”은 RMS Server 를 통해 입고 DB 에만 데이터를 적재하고, “적치”할 땐 RMS Server 를 통하는 것은 동일하나, 입고 DB 뿐 아니라 WMS Server 의 API 를 함께 호출하여 재고 DB 에 데이터를 생성하는 것으로 완료가 됩니다.
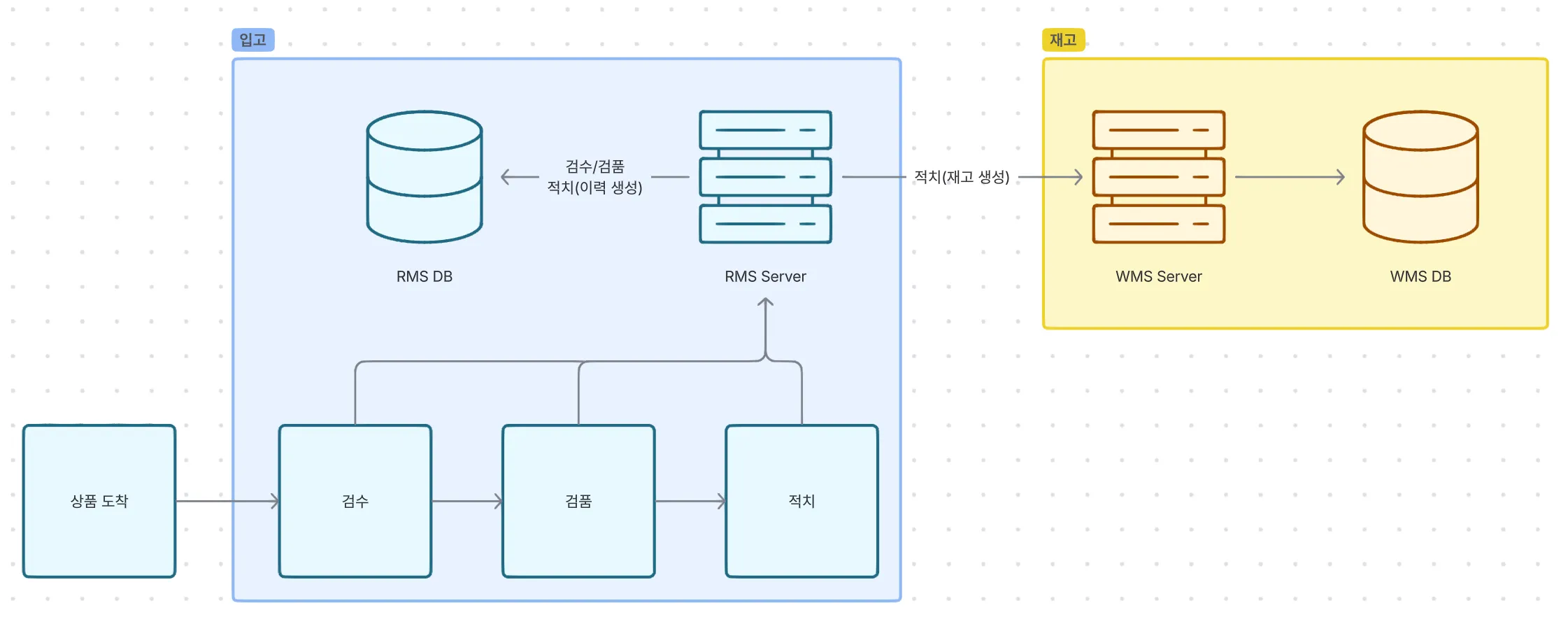
이날은 이 중 재고 DB(WMS DB) 에서 점검 작업이 진행되었던 겁니다. 사전에 여러 번 안내 공지는 되었지만 해당 사실을 전파 받지 못한 몇몇 센터 작업자분들은 이 사실을 모른 채 적치 작업을 진행합니다. 이어 데이터독에는 하나둘 에러 로그가 쌓이고 모니터링 시스템을 통해 저희에게 알림이 오고 있었습니다.
더구나 이 WMS Server 를 호출하여 재고 DB 에 데이터를 쌓는 부분은 비동기 통신으로 이루어져 있었는데, 보상 트랜잭션은 따로 구성해놓지 않았습니다. 다시 말해 이 부분에서 에러가 난다는 것은, 즉 우리 개발팀이 수기로 재고를 조정 처리 해줘야 하는 데이터가 하나둘 쌓이고 있다는 말과 같은 말이었습니다.
 상황이 발생하고서 가장 먼저 떠오른 건 nginx 라우팅 설정을 통해 적치 API 호출을 차단시키는 방안이었습니다. 하지만 개발팀에겐 실행중인 인스턴스의 nginx 설정 파일을 변경할 권한도, nginx 를 재시작할 권한도 없었습니다. 인프라 팀에 협조 요청을 구하면 가능한 일이긴 하겠지만, 이미 상황은 벌어진 상태고, DB 점검 시간은 그렇게 길지 않아, 협조를 구해 nginx 라우팅 설정을 변경하고 재시작 하면 이미 상황은 종료되어 있을 것으로 계산이 되었습니다.
상황이 발생하고서 가장 먼저 떠오른 건 nginx 라우팅 설정을 통해 적치 API 호출을 차단시키는 방안이었습니다. 하지만 개발팀에겐 실행중인 인스턴스의 nginx 설정 파일을 변경할 권한도, nginx 를 재시작할 권한도 없었습니다. 인프라 팀에 협조 요청을 구하면 가능한 일이긴 하겠지만, 이미 상황은 벌어진 상태고, DB 점검 시간은 그렇게 길지 않아, 협조를 구해 nginx 라우팅 설정을 변경하고 재시작 하면 이미 상황은 종료되어 있을 것으로 계산이 되었습니다.
그래서 우리는 그저 목놓아 외칠 수 밖에 없었습니다.
“여러분! 적치를 멈춰주세요!!! 적치 전 검수/검품 업무까지만 진행해 주세요!!”
그러면서 한편으론, 이 상황이 끝난 후 보정 처리를 해야 할 데이터를 일일이 취합하고 있을 뿐이었습니다. ‘오늘 점심은 다 먹었다…’ 쓰린 눈물을 삼키면서요.

아 배고파…
공지 전파로는 한계가 있다. 시스템에서 접근을 막아보자.
해당 DB 작업은 서비스 운영 중 드물게 발생하는 일이었고, 당시의 입고프로덕트개발팀은 빌딩된 지 그렇게 오래되지 않아 아직 체계가 완전히 확립되거나, 운영도구 등이 충분히 준비되지 못했던 때였습니다.
그리고 사전에 미리 협조요청만 구하면, 센터의 물류 작업자 분들도 온전히 따라 주시겠거니 하는 안이한 생각도 있었죠.
우리는 그렇게 깨달았습니다. 공지와 협조요청으로는 언제든 음영 구역이 생길 수 있고, 그 잘못은 우리의 작은 목소리에 귀기울여주지 않은 그 분들에게 있는 것이 아니라, 당연히 시스템에서 제대로 차단하지 못하는 우리에게 있음을요.
AccessBlock, 그 시작과 진화의 여정
첫 번째 AccessBlock
간단한 시작
선술했듯, 개발팀에겐 nginx 접근 권한이 없습니다. 그래서 웹서버 라우팅 처리로 서비스 점검을 걸지는 못하고, 애플리케이션 레벨에서 차단해야 했습니다. 이 시스템을 AccessBlock 으로 명명하고, 이제부터 성장시켜 나갈 겁니다.
우선 간단하고 명료하게 접근했습니다. 차단할 화면 목록을 미리 등록해놓고 그룹으로 묶어서, 유사시에 그룹 단위로 차단할 수 있게끔요. MySQL 에 두 개의 테이블을 추가합니다.
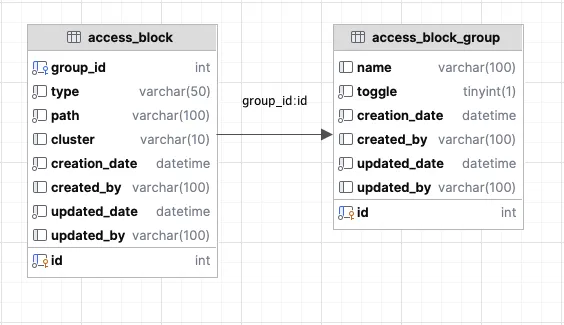
access_block 테이블에는 path 정보(예: /user/list)들을, access_block_group 은 access_block 들을 하나의 그룹으로 묶어줄 그룹 정보를 생성합니다. 그리고 해당 그룹의 toggle 이 true 라면, 그룹에 묶여있는 access_block 의 path 들은 모두 차단되는 방식입니다. 이러면 우리는, access_block 및 access_block_group 데이터의 등록/수정/삭제, 그리고 toggle 을 on/off 시킬 수 있는 API 만 있으면 됩니다.
동작 방식도 심플합니다. 프론트의 각 페이지가 라우팅될 때 마다, RestAPI 로 만들어둔 차단 여부 조회 API 를 호출합니다. API 는 현재 요청된 페이지의 url 과 access_block 의 path 를 비교해 일치하면 true 를 반환합니다. 그리고 프론트에서 이 true 응답을 받으면, 점검 안내 페이지로 강제 리다이렉트 시킵니다.
화면 단위의 차단 외에도, API 단위의 차단도 생각해 둬서 type 컬럼을 두었지만, 이 버전에선 구현하지 않았습니다.
매 페이지 라우팅 시마다 네트워크 비용이 한 단계 추가되긴 했지만, 이 정도로는 전체 프로덕트 성능에 끼치는 영향은 극히 미미합니다. 오히려 덕분에 좋아진 점도 있습니다.
기존에는 페이지 라우팅만으로는 서버 통신이 없기 때문에, 토큰이 만료되어도 클라이언트에서 이를 캐치할 수가 없으므로 이 페이지 저 페이지 이동이 가능했는데, 이제는 차단 여부 조회 API 가 매 페이지마다 호출되니 토큰 만료도 알 수 있게 돼서 즉시 로그아웃 처리를 할 수 있으니 “오히려 좋아” 입니다.
 운영을 하다보니 특정 클러스터만 차단을 해야 하는 일이 갑자기 생겼습니다. 워낙 급한 일정이라 깊이 고민할 수 있는 시간은 없었습니다. 깊이 고민한다 한들, 설계를 바꿀 수 있는 물리적인 시간도 없었습니다. 우선 직면한 요구사항을 구현하기 위해 급한대로 access_block 테이블에 cluster 라는 컬럼을 하나 추가하고, 코드를 살짝 고칩니다. “나중에 설계를 다시 고민해봐야지.” 라고 다짐합니다. 기술 부채가 하나 더 쌓였습니다.
운영을 하다보니 특정 클러스터만 차단을 해야 하는 일이 갑자기 생겼습니다. 워낙 급한 일정이라 깊이 고민할 수 있는 시간은 없었습니다. 깊이 고민한다 한들, 설계를 바꿀 수 있는 물리적인 시간도 없었습니다. 우선 직면한 요구사항을 구현하기 위해 급한대로 access_block 테이블에 cluster 라는 컬럼을 하나 추가하고, 코드를 살짝 고칩니다. “나중에 설계를 다시 고민해봐야지.” 라고 다짐합니다. 기술 부채가 하나 더 쌓였습니다.
아뿔싸…
아뿔싸, RMS DB 도 점검이 걸릴 수 있다는걸 간과했습니다.
사실 RMS DB 가 점검이라면, 로그인을 비롯해 아무것도 할 수 없기 때문에 서비스 전체를 차단해야 하므로 서비스 자체를 다운시켜두는 것과 다를 바가 없긴 합니다. 그래도 기왕이면, 서비스를 다운시키지 말고 점검 페이지를 보여주고 싶었습니다. 다들 그러시지 않나요? 날 것 그대로의 에러 페이지는 약간 뭐랄까.. 엔지니어의 수치 같은 느낌..? 아니라면 저만 그런 걸로 하겠습니다…


웹서버 기본 에러 페이지는 엔지니어의 수치다.
그리고 DB 점검도 여러 종류라, DB 접속이 완전히 차단되는 경우엔 서비스 자체를 내려도 무방하겠지만, 특정 테이블만 작업이 있어 락이 걸린다든지, 어떠한 작업으로 인해 성능이 현저히 다운돼서 단순 조회성 쿼리는 괜찮은데 트랜잭션이 추가로 생기면 곤란해진다든지, AccessBlock 차단 여부를 조회하는 쿼리마저 응답이 느려지게 돼 정상 동작을 담보할 수 없다든지 하는 경우도 생길 수 있습니다.
이런 경우들을 대비해, 결국 AccessBlock 과 AccessBlockGroup 데이터를 RDBMS 에서 분리해서 관리해야 할 필요성을 더 느끼게 됩니다.
두 번째 AccessBlock
캐싱을 해보자
위에서 설계한 AccessBlock 과 AccessBlockGroup 데이터를 그대로 Redis 에 주기적으로 캐싱하는 방식을 사용합니다. 단, AccessBlockGroup 의 toggle 컬럼은 이제 사용하지 않습니다. AccessBlock 및 AccessBlockGroup 데이터는 AccessBlock 시스템을 위한 메타데이터로써의 역할만 수행하고, toggle 에 해당하는 데이터 구조체는 Redis 에서 따로 관리합니다.
 위와 같이 3개의 Redis 데이터로 구성했습니다.
위와 같이 3개의 Redis 데이터로 구성했습니다.
ACCESSBLOCK 및 ACCESS_BLOCK_GROUP 을 사용해 path 들을 그룹으로 묶는 역할은 기존과 동일하나, toggle-on 을 시키면 기존처럼 ACCESS_BLOCK_GROUP 의 데이터를 수정하는게 아니라, BLOCKED…IDLIST 에 ACCESS_BLOCK_GROUP 의 ID 값을 하나 추가합니다. 이 BLOCKED…ID_LIST 값이 등록되어 있으면 toggle 이 on 되어 있다고 갈음하는 방식입니다.
캐싱 정책은 스케줄링 배치를 활용하여 주기적으로 할까 고민했다가, 우선은 최소한의 공수로 하나의 인스턴스 안에서만 해결하고 싶어서 아래와 같은 정책을 세웠습니다.
- AccessBlockGroup 데이터를 등록/수정/삭제할 때 즉시 캐싱
- AccessBlock 데이터를 등록/수정/삭제할 때 즉시 캐싱
차단 여부 조회 API가 100번째 호출될 때마다 한 번 캐싱
RDBMS 의 테이블을 직접 조회하던 차단 여부 조회 API 는 이제 저 BLOCKED_…ID_LIST 값을 읽어서, 여기에 데이터가 하나도 없으면 바로 false 를 반환하고, 여기에 데이터가 있으면 해당 값으로 그룹이 묶인 ACCESS_BLOCK 을 찾아, 대상 path 와 현재 url 정보를 대사하여 응답합니다.
자, 이제 우리는 RMS DB 가 전체 다운이 되더라도, 일부만 작업이 생기더라도, 어느 상황에든 자유롭게 toggle 을 on/off 시킬수도 있고, 차단 여부 조회도 RDBMS 와 상관 없이 마음껏 할 수 있게 되었습니다. 데이터를 조회해오는 곳이 RDBMS 가 아니라 Redis 로 바뀌니, 응답 속도 또한 크게 향상된 것은 덤으로요.
AccessBlock, AccessBlockGroup 데이터만 미리 잘 생성해 둔다면 말이죠.
그런데 말입니다

네, 방금 제가 했던 말에 함정이 있습니다.
“AccessBlock, AccessBlockGroup 데이터만 미리 잘 생성해 둔다면 말이죠.” …
네, 이 방식은 결국, AccessBlock, AccessBlockGroup 데이터(이제부턴 이 둘을 묶어서 ‘메타데이터’라 칭하겠습니다.)를 RDBMS 에서 Redis 로 복제해올 뿐, 이 데이터에 대한 등록/수정/삭제는 여전히 RDBMS 를 통해 하고 있습니다.
이 말인 즉, 이미 RDBMS 가 다운 되어버린 상태에선 새로운 메타데이터의 등록이 불가능하다는 뜻이 됩니다. 물론 사전에 시나리오를 잘 수립하고, 계획한 대로만 일이 흘러간다면 아무 문제가 없겠지만, 세상은 언제나 제 생각보다 더 멋진 곳입니다.

남겨진 숙제
결국, 메타데이터의 관리 마저도 RDBMS 와의 의존성을 완전히 제거해야 한다는 결론에 도달합니다. 그러면서도 DB Tool 처럼 테이블 내용이 표 형태로 직관적으로 눈에 보이고, 수정도 할 수 있는 UI 가 제공되면 좋겠습니다. 직접 UI 를 개발해도 되겠지만, 기존의 시스템 안에 넣자니 DB 가 다운되면 로그인이 안되고, 새로운 인스턴스를 띄우자니 고작 이 기능 하나를 구현하기 위해 너무 오버스펙으로 가는 것 같습니다.
그래서 어떤 결론을 냈는지는, 다음 편에서 이어서 이야기하도록 하겠습니다. 아, 혹시라도 너무 큰 기대는 말아주세요. 별 대단한 건 나오지 않으니까요.