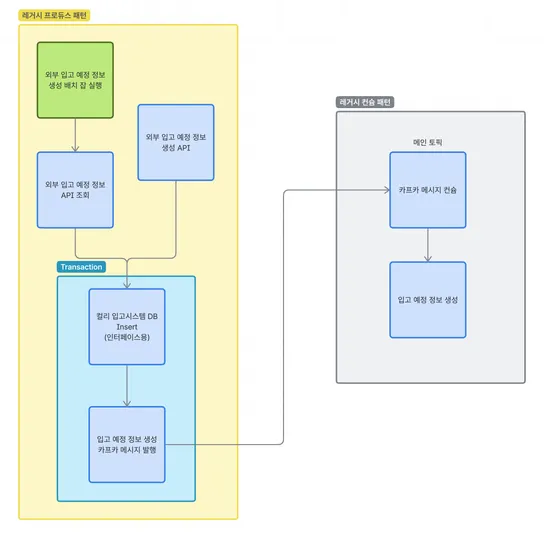
개요
지난 편에는 저희가 이 AccessBlock 을 도입하게 된 계기와 사용하는 도중 어떤 니즈가 있었고 어떤 아쉬움으로 인해 계속해서 점진적으로 시스템을 어떻게 바꿔왔는지를 말씀드렸습니다. 이어서 이번 리뉴얼은, 도출한 내용들을 최종 정리하여 완전체로 거듭나기 위해 공을 좀 들여 보겠습니다.
그동안 나왔던 모든 것들을 종합하여 내용을 다시 한번 정리해 봅시다.
-
사실, 들어온 요청을 페이지나 API 의 path 기준으로 판단하여 점검 페이지로 리다이렉트 시키거나, 특정 HttpStatus 로 응답을 주는 것은 nginx 와 같은 웹서버에서 처리하면 굉장히 간편하고 강력하게 처리할 수 있습니다.
-
그러나, 우리는 nginx 가 앞단에서 모든 요청을 받아서 라우팅 처리하는 리버스 프록시 방식이 아니고, 별도의 게이트웨이도 존재하지 않으며, CORS 방식이라 프론트와 서버가 각각의 nginx 를 가지고 있고, 무엇보다 nginx 설정은 인프라팀의 관리 하에 도커에서 베이스 이미지와 함께 생성되고 있으므로, nginx 설정을 통해 접근을 차단하는 방식은 우리의 인프라 상황에 적합한 방식은 아닙니다.
-
추가로, 우리는 서버 엔지니어가 아니거나, nginx 설정 파일의 문법을 모르는 사람도 직관적으로 접근 차단을 설정하고, 활성화할 수 있길 원했습니다. 기획자나, QA 엔지니어, 혹은 개발팀이 아닌 시스템 운영 담당자 등등..
-
그리고 또, 가끔은 특정 클러스터/센터에 소속된 사용자만 접근을 차단시키거나, 특정 권한을 가진 사람만 접근을 허용하는 등의 기능도 필요합니다. 가령, 김포 클러스터의 DB 가 작업 중이어서 김포 클러스터 소속 사용자들은 모두 접근이 차단되어야 하는데, 그럼에도 슈퍼마스터 권한은 점검을 위해 페이지를 열 수 있어야 한다든지 하는 상황이요.
-
그리고 이 모든 기능은 업무 시스템에서 사용하는 RDBMS 에 아무런 종속성이 없어야 합니다.
구현
MySQL 의 그늘에서 벗어나기
이번 리뉴얼의 MVP 는 단연 “탈 RDBMS” 입니다. 그러면서도 DB Tool 처럼 테이블 내용이 표 형태로 직관적으로 눈에 보이면서 수정도 간편하게 할 수 있길 원했습니다. 서버 엔지니어가 아니라도 자유자재로 다룰 수 있게끔요. 지난 시간에 말씀드렸다시피, UI 를 직접 만들자니 기존 시스템 안에 넣기도 애매하고, 이 기능 하나만을 위한 신규 인스턴스를 띄우기도 애매했습니다.
주위를 둘러보니, 눈에 띄는 강력한 소프트웨어가 하나 있습니다.
표 형태로 데이터를 직관적으로 관리하기 적합하고, 현대의 회사원이라면 누구나 다뤄봤을 정도로 접근성이 좋은, 바로 “엑셀”입니다. 이 엑셀을 웹 기반으로 만든 구글 스프레드시트로 데이터를 관리하고, 이 데이터를 구글 클라우드의 BigQuery 에 연동시킨다면, 업무 시스템에서 사용하는 RDBMS 에는 종속성을 전혀 가지지 않게 됩니다.
하지만 문제가 하나 있습니다. BigQuery 는 원래 IO 가 빈번한 업무 시스템의 메인 DB 로써의 역할보다는, 그 이름대로 방대한 데이터를 저장해놓고 통계나 분석 쿼리를 질의하는데 특화된 DB 입니다. 아주 작은 테이블에 아주 간단한 쿼리를 질의해도 수백 ms 는 기본으로 소요됩니다. 우리는 단지 업무용 시스템에서 사용하는 RDBMS 와 관계가 없는, 써드파티 데이터베이스 저장소가 필요했고, 구글 스프레드 시트와의 연계가 용이하기에 BigQuery 를 선택했으나, 매 페이지 라우팅이 동작할 때마다, API 가 호출될 때마다 차단 여부를 알기 위해 BigQuery 에 직접 질의하는 단계가 들어간다면 네트워크가 상당 시간 지연될 것입니다. 이는 프로덕트의 심각한 성능 저하를 야기할 수 있습니다.
따라서, 이 BigQuery 데이터를 최종적으로 Redis 에 캐싱해 두고, 질의는 Redis 를 통해 하는 전략은 이전 버전의 AccessBlock 과 동일하게 유지하도록 합니다. 단, 기존처럼 “N 번 호출마다 한 번씩 동기화” 와 같은 호출 횟수 기반의 동기화 방식은 트래픽의 증감에 따라 동기화 주기 예측이 어려워지므로, 이번에는 스케줄링 배치도 개발하여 정확히 3분마다 한 번씩 동기화가 되도록 합니다.
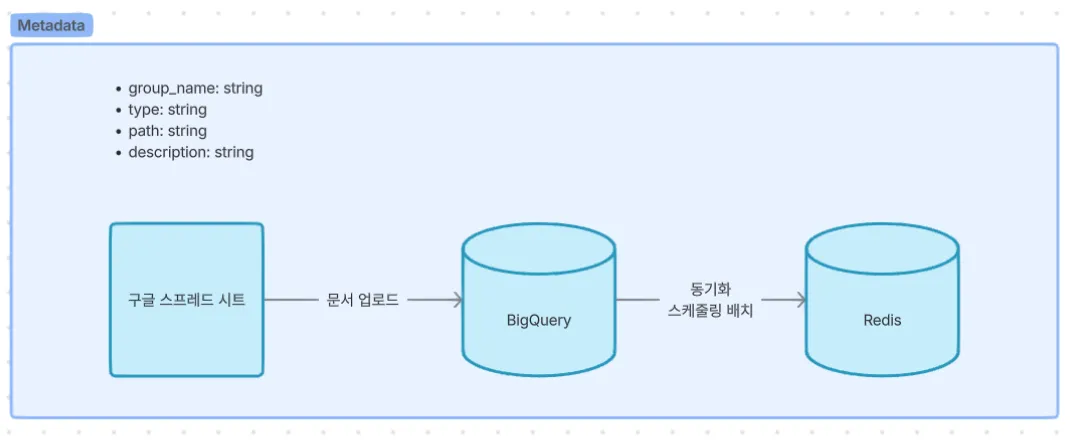
이전 버전에서 임시로 메타데이터에 추가했던 cluster 컬럼은 이 버전에서 다시 삭제됩니다. 메타데이터는 “어떤 path 를 차단시킬 것인가” 에 대한 정보만 가지도록 하고, cluster 는 “어떤 클러스터에 소속된 사용자를 대상으로 차단을 실행할 것인가” 라는, 차단을 실행하는 시점의 관심사로 분리하도록 합니다.
이제 메타데이터는 순수하게 path 정보와 이 여러 path 정보를 하나의 group 으로 묶기 위한 정보만 존재합니다.
메타데이터와 실행데이터의 분리
차단할 대상 path 정보들의 명세를 가지고 있는 “메타데이터”는 위에서 정리가 끝났습니다. 이제는 “언제, 누구를 대상으로, 어떤 path 들을 차단할 것인가” 하는 정보를 관리해야 하는데, 이를 “실행데이터” 라 칭하겠습니다.
toggle on/off 에 대한 판단을 Redis 에 데이터가 있는지 여부로 갈음하는 컨셉은 그대로 유지합니다. 다만, 이전엔 단순히 group_id 값만 가지고 있었던 데에 반해, 이번에는 “누구를 대상으로 실행 시킬 것인지” 에 대한 데이터까지 함께 관리합니다. 선술했듯, 메타데이터에 있던 cluster 필드를 실행데이터로 옮겨왔습니다. 추가로 좀 더 세부적인 설정을 위해 cluster 하위의 warehouse 단위로까지 대상 범위를 지정할 수 있게 하고, 특정 권한을 가진 사용자는 차단 대상에서 제외되도록 만들기 위해 excludeRoles 라는 필드까지 추가합니다.
이 데이터는 사용자의 입력 즉시 바로 기민하게 반응해야 합니다. 그리고 특정 데이터 셋을 항상 저장해두고 관리해야 하는 데이터가 아니라, 유사시에 insert 하고, 상황이 종료되면 바로 삭제하면 되는 휘발성이 강한 데이터입니다. 따라서 메타데이터처럼 구글시트로 관리하고, 빅쿼리에 연동하고, Redis 에 캐싱하는 등 여러 절차를 거치는게 아니라, Swagger 나 Postman 등의 툴을 사용해 API 를 직접 호출하여 Redis 에 입력/삭제 되게끔 합니다.
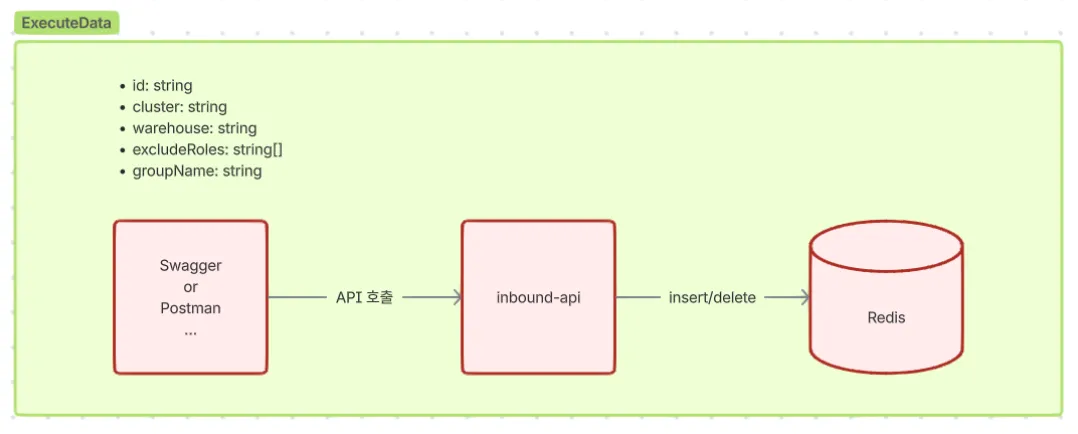
실행데이터의 데이터셋을 구성하는 각 필드의 설명은 아래와 같습니다.
- id: 등록 시 자동 채번되는 문자열로, 삭제 시 활용됩니다.
- cluster / warehouse: 빈 값 혹은 null 로 등록하면, 전체를 대상으로 차단을 실행합니다.
- 예) 사용자가 cluster=평택클러스터, warehouse=평택냉장 에 소속되어 있을 때,
- 차단되는 경우
- cluster=null, warehouse=null
- cluster=평택클러스터, warehouse=null
- cluster=null, warehouse=평택냉장
- cluster=평택클러스터, warehouse=평택냉장
- 차단되지 않는 경우
- cluster=김포클러스터, warehouse=null
- cluster=김포클러스터, warehouse=평택냉장
- cluster=null, warehouse=김포냉장
- cluster=평택클러스터, warehouse=김포냉장
- 차단되는 경우
- 예) 사용자가 cluster=평택클러스터, warehouse=평택냉장 에 소속되어 있을 때,
- excludeRoles: 권한 코드를 배열로 가지며, 사용자가 이 권한 중 하나 이상을 가지고 있다면, 해당 사용자는 차단 대상에서 제외됩니다. 빈 배열을 등록하게 되면 전체 권한을 대상으로 차단을 실행합니다.
- groupName: 차단할 메타데이터의 그룹 이름
서버 로직 구현
AccessBlock 의 동작에 대해 사용자 입장에서의 플로우는 아래와 같습니다.
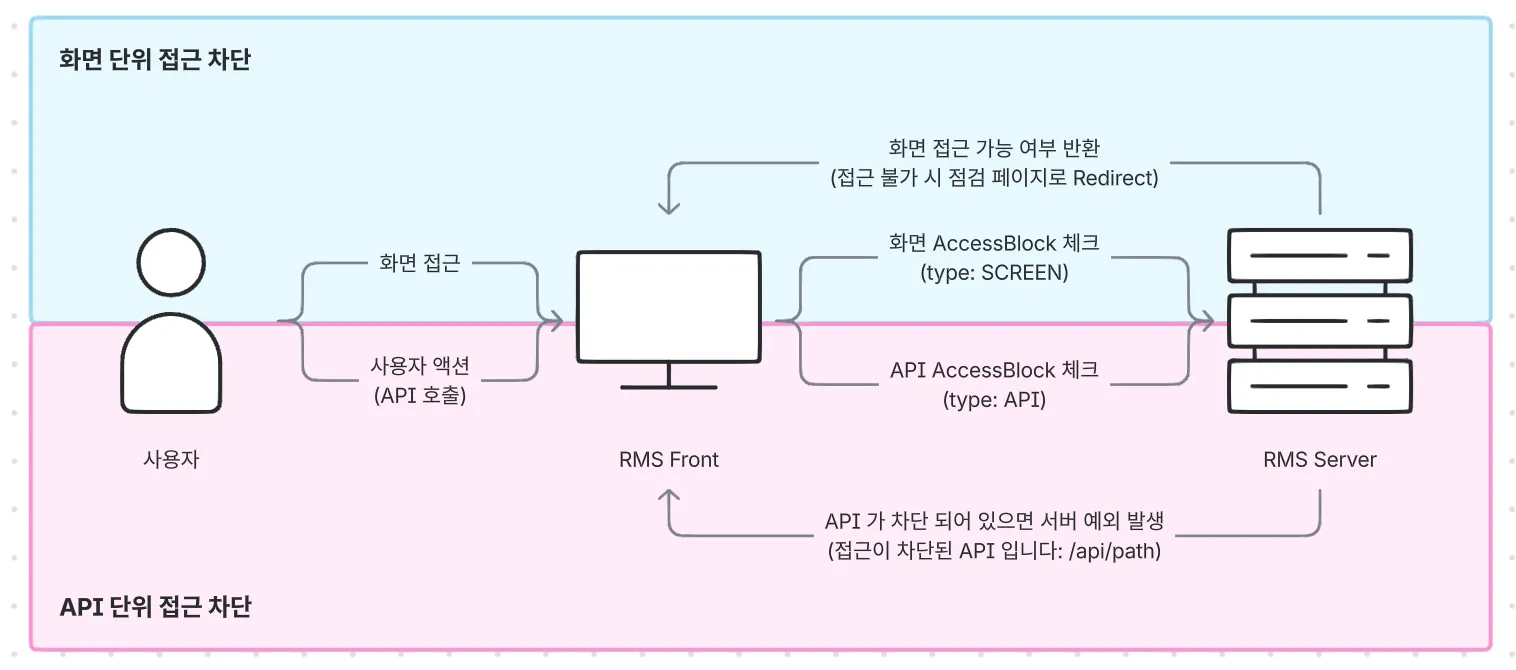
이 부분의 컨셉은 기존과 달라질 것은 없습니다. 다만 데이터의 구조가 바뀌면서 체크해야 하는 로직이 변경이 됐을 뿐이죠. 그리고 이번엔 화면에 대한 차단뿐만 아니라 API 호출에 대한 차단도 같이 구현하기로 합니다.
화면 접근제어 처리
저희 프로덕트의 프론트는 Vue.js 로 구성되어 있습니다. VueRouter 의 beforeEach 메서드를 통해, 매번 라우팅이 수행되기 전, to.path 값이 차단되어 있는지, Store 에 정의되어 있는 AccessBlock 차단여부 조회 API 를 호출합니다. 페이지가 차단되어 있으면 라우팅이 수행되면 안되기에, async 로 동작할 수 있게 해줍니다. 그리고 그 응답이 true 일 경우, 사용자가 이동하길 원했던 페이지가 아니라 /unavailable 경로로 강제로 리다이렉트 시킵니다.
이 /unavailable 페이지를 비롯해 몇몇 페이지는 접근 차단에서 예외 적용을 받아야 할 수 있습니다. 이 경로들은 차단 여부를 확인하지 않도록 적절히 처리해 줍니다.
router.beforeEach(async (to, from, next) => {
// AccessBlock 체크 제외할 페이지
const excludedPaths = [
'/login',
'/logout',
'/unavailable',
'/block',
];
if (!excludedPaths.some((excludedPath) => to.path.startsWith(excludedPath))) {
await store.dispatch('AccessBlock/checkBlocked', to.path);
if (store.state.AccessBlock.isBlocked) {
return next('/unavailable');
}
}
// something else ...
}API 접근제어 처리
API 호출에 대한 접근제어는 Spring AOP 를 활용해 RestController 로 들어오는 모든 요청을 인터셉트하여 선처리 합니다. 만약 대상이 차단되어 있으면 별도로 약속된 Exception 을 발생시키고, 그렇지 않다면 원래의 JoinPoint 의 수행을 이어갑니다. 마찬가지로, 차단이 되면 안되는 API 도 있으니 @ExcludeAccessBlock 라는 어노테이션도 같이 생성하여, 해당 어노테이션이 선언되어 있는 클래스와 메서드는 Aspect 가 수행되지 않도록 합니다.
@Target({ ElementType.TYPE, ElementType.METHOD })
@Retention(RetentionPolicy.RUNTIME)
public @interface ExcludeAccessBlock {}@Aspect
@Component
public class AccessBlockAop {
private final AccessBlockUseCase accessBlockUseCase;
public AccessBlockAop(AccessBlockUseCase accessBlockUseCase) {
this.accessBlockUseCase = accessBlockUseCase;
}
@Pointcut("@within(org.springframework.web.bind.annotation.RestController) && within(com.kurly.inbound..*)")
private void controllerPointcut() {}
@Pointcut("!@annotation(com.kurly.inbound.aop.annotation.ExcludeAccessBlock) && !@within(com.kurly.inbound.aop.annotation.ExcludeAccessBlock)")
public void notExcludeAccessBlockAnnotated() {}
@Around("controllerPointcut() && notExcludeAccessBlockAnnotated()")
public Object check(ProceedingJoinPoint joinPoint) throws Throwable {
HttpServletRequest request = ((ServletRequestAttributes) Objects.requireNonNull(RequestContextHolder.getRequestAttributes())).getRequest();
String currentPath = request.getRequestURI();
String userCluster = SecurityUtils.getUserCluster();
String userWarehouse = SecurityUtils.getUserWarehouse();
List<String> userRoles = SecurityUtils.getUserRoles();
UserCredential userCredential = UserCredential.of(userCluster, userWarehouse, userRoles);
AccessBlockInquiry inquiry = AccessBlockInquiry.of(AccessBlockType.API, currentPath, userCredential);
boolean isBlocked = accessBlockUseCase.isBlocked(inquiry);
if (isBlocked) {
throw new InboundServiceException(AccessBlockExceptionType.BLOCKED_API, currentPath);
}
return joinPoint.proceed();
}
}차단 여부를 판단하는 로직은 별도의 도메인으로 분리하여, 각 시나리오별로 꼼꼼하게 테스트 코드도 작성해 줍니다.

사용 방법
이젠 사용자 입장에서 어떤 식으로 메타데이터 및 실행데이터를 관리하고, 정상적으로 차단이 됐을 때 어떤 결과물을 낼 수 있는지 확인해 봅니다.
구글시트로 메타데이터 관리하기
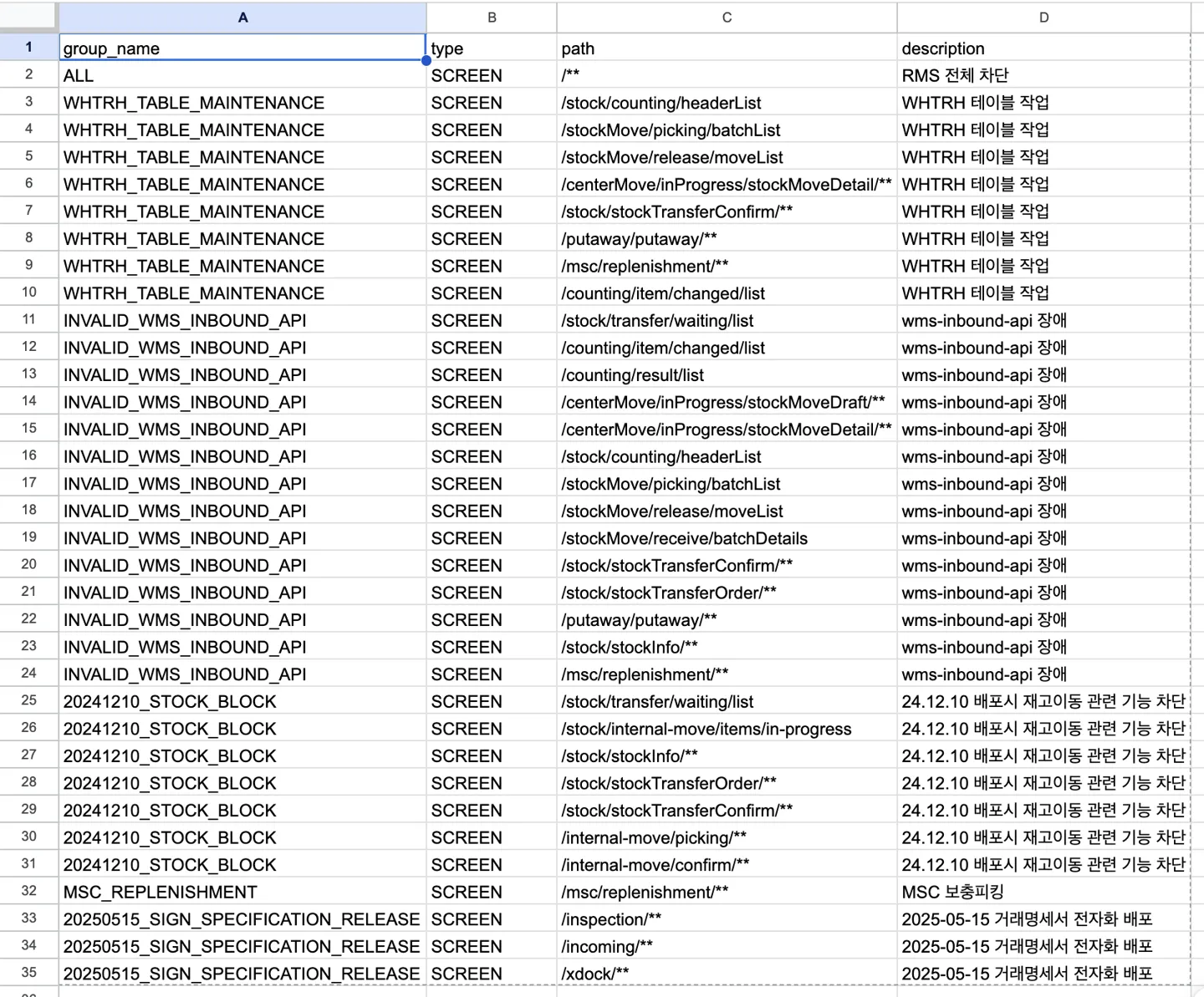
누구에게나 친숙한 스프레드 시트 그 자체입니다. 이 스프레드 시트를 구글 드라이브에 업로드 해놓고, 빅쿼리에서 시트 링크를 통해 데이터를 읽어올 수 있습니다. 저희는 회사 내부 정책으로 인해 시트 링크 방식은 사용할 수 없고, 대신 데이터 팀에서 별도의 확장 프로그램을 통해 빅쿼리에 직접 업로드할 수 있도록 환경을 제공해주고 있습니다.
구글 스프레드 시트를 빅쿼리와 연동하는 방법은 구글링을 통해 쉽게 찾아볼 수 있으니, 여기서 자세한 설명은 생략합니다.

3분 단위로 스케줄링 되어 있는 배치 잡을 통해, Redis 에 동기화까지 완료된 모습입니다. 동기화 시 모든 데이터를 삭제하고 다시 저장하므로, 데이터 타입은 List 형태로 저장합니다.
스웨거로 실행데이터 관리하기
실행데이터는 별도의 관리 툴이나 구글시트 연계 같은 장치를 만들어두지 않았기에, 스웨거나 포스트맨을 이용해 직접 API를 호출하는 방식을 사용합니다. 저는 스웨거를 통해 호출하도록 하겠습니다.
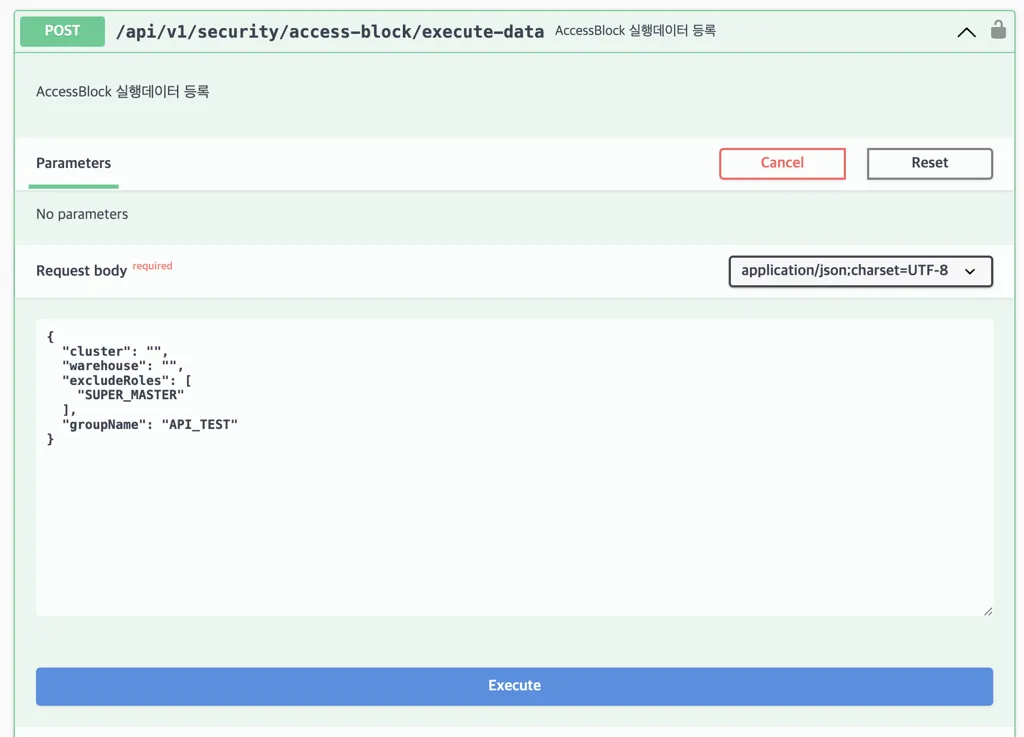
위 데이터는 API_TEST 라는 그룹에 해당하는 path 들을 차단시킬건데, 클러스터와 센터는 전체 대상으로, 단 SUPER_MASTER 권한을 보유한 사용자는 제외한다는 뜻입니다.
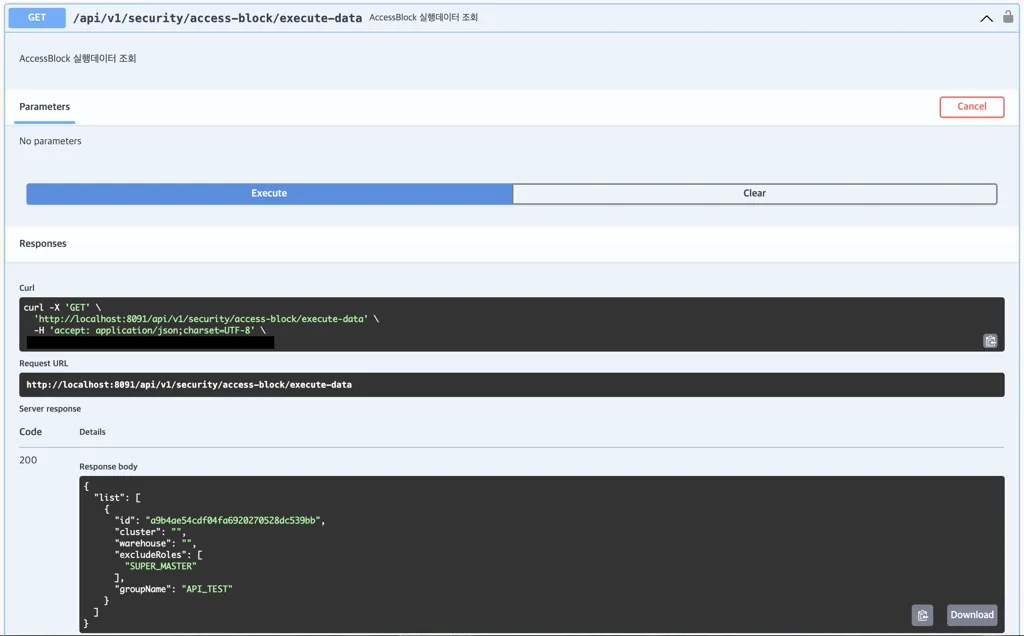
실행데이터를 등록하면 UUID 를 활용한 랜덤 문자열로 id 를 하나 채번합니다. 추후 등록된 실행데이터를 삭제할 땐 이 값을 통해 삭제할 수 있습니다. 등록 즉시 차단이 실행, 삭제 즉시 차단이 해제되는 구조입니다.

등록된 실행데이터를 Redis 에서 조회해 보았습니다. 앞서 메타데이터는 중간에 하나의 데이터만 삭제하는 경우가 없이 전체 삭제 후 전체 저장하게 되므로 List 타입으로 저장했지만, 실행데이터는 데이터가 빈번하게 추가/삭제 되는 구조이니 Key 로 제어하기 용이하게끔 Hash 타입으로 저장합니다.
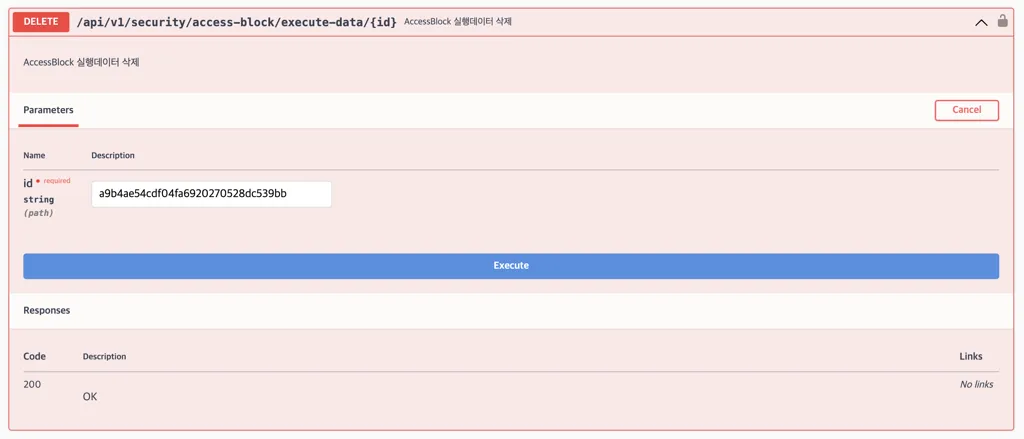
실행데이터를 삭제할때도 역시 스웨거를 이용할 수 있습니다. 실행데이터를 등록한 후 조회할 때 확인했던 id 값을 넣어서 삭제 처리하면, 즉시 차단이 해제되게 됩니다.
결과
정상적으로 차단이 실행되면, 웹과 PDA 에서 각각 아래와 같이 처리됨을 볼 수 있습니다.
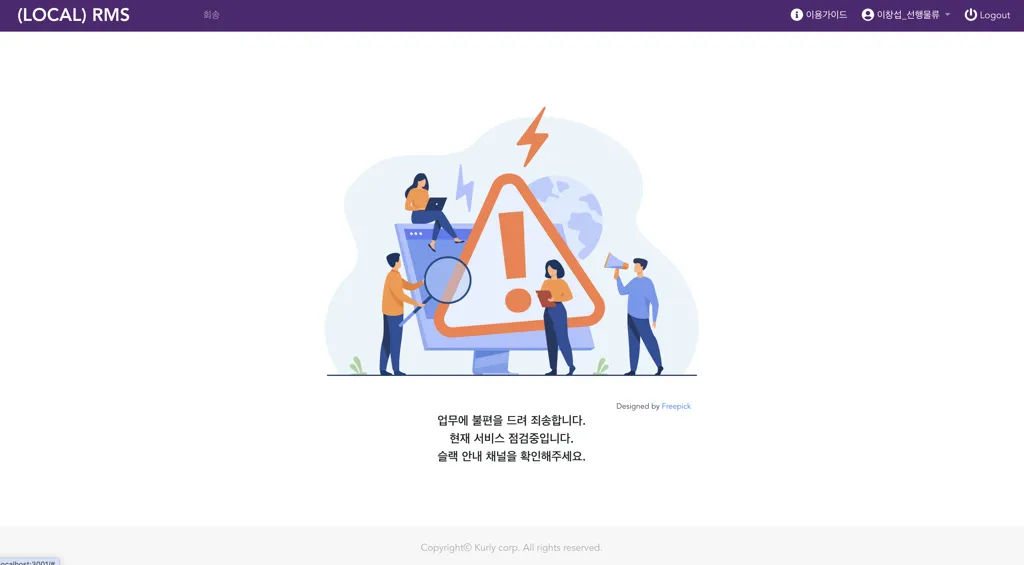
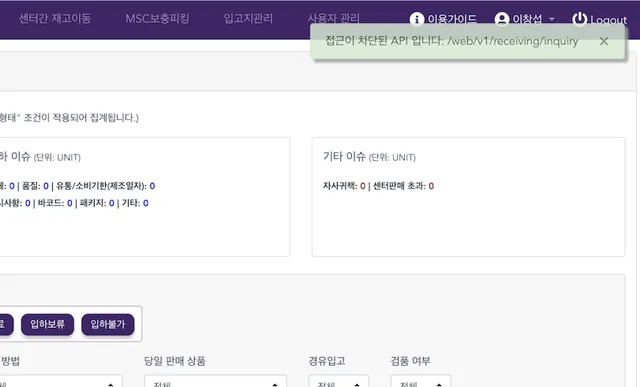
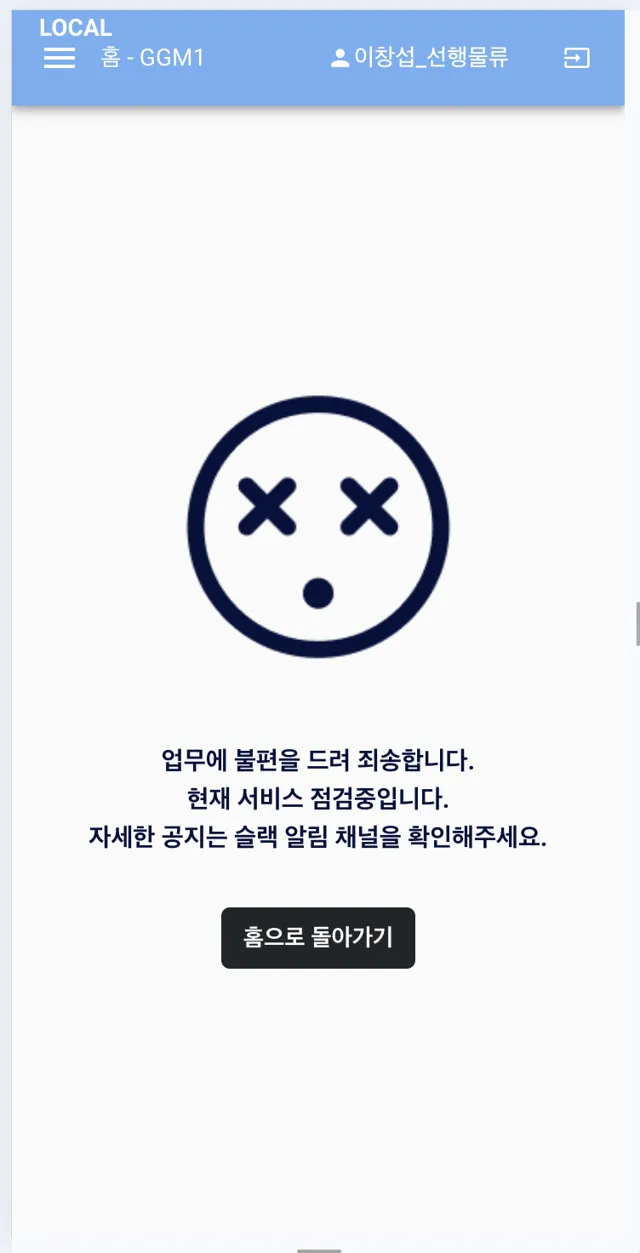
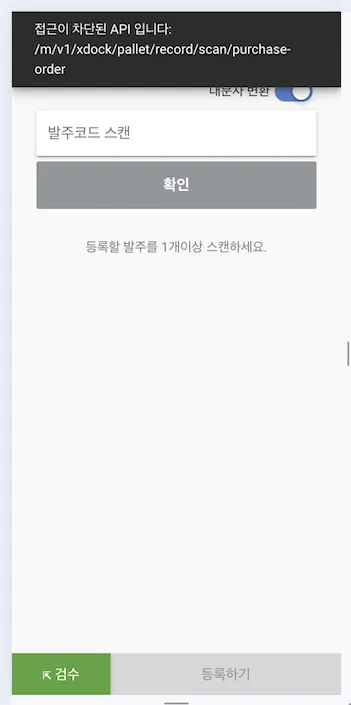
마치며
네, 여기까지입니다. 참으로 별 것도 아닌 기능 같으면서도, 또 어떻게보면 참 중요한 기능 중 하나입니다. 물론 이보다 훨씬 멋지게 제대로 만든 솔루션을 도입해서 활용중인 회사와 팀이 분명 더 많겠지요. 그럼에도 불구하고, 과거의 저희와 비슷한 고민을 하였거나, 주어진 환경의 제약을 아이디어로 극복해야 하는 개발자가 단 한 분이라도 계시다면, 그리고 그 분이 이 글을 보고 아주 사소한 힌트 하나라도 얻으셨다면, 저는 더할나위 없이 기쁘겠습니다. 구현된 코드를 모두 공개하기엔 양이 너무 방대하여 가독성을 해칠까 차마 지면에 다 실을 수 없었던 점 양해 부탁 드립니다. 궁금한 점이 있으시다면 따로 댓글 등으로 문의 주시면 성심껏 답변 드리겠습니다.
이상 AccessBlock 이 겪은 지금까지의 여정을 함께해 주셔서 감사합니다. 그럼, 또 뵙겠습니다!