안녕하십니까 컬리 데이터서비스개발팀 데이터 엔지니어 김영준입니다. 컬리에서는 수많은 데이터 파이프라인과 MLOps, BI (Business Intelligence) 등 다양한 분야에서 워크플로 관리 플랫폼인 Airflow를 사용하고 있습니다. 최근 그중 데이터 파이프라인에 사용하던 Airflow를 관리형 서비스에서 Kubernetes (이하 K8S) 환경으로 이관을 진행하고 안정적인 운영을 위한 여러 작업을 진행하였습니다. 이 글에서는 그 과정에서 겪은 다양한 경험들을 공유해 보고자 합니다.
관리형 서비스에서 K8S로
![]() © 2024. Kurly. All rights reserved.
© 2024. Kurly. All rights reserved.
Airflow의 운영 환경을 전환하게된 배경
컬리의 데이터 플랫폼은 K8S 환경과 여러 관리형 서비스들을 사용하여 구축되어 있으며 지속해서 기술 성숙도를 높이기 위해 노력하고 있습니다. 그런 노력중 하나로 오픈소스 기반의 관리형 서비스를 직접 관리하는 K8S 환경으로 전환하기 위해 도전하고 있으며 이번엔 데이터 파이프라인에 사용중인 Airflow의 운영 환경을 전환 하였습니다. 이를 통해 성능 및 비용 최적화를 달성하고 있으며 직접 부딪히며 기술의 수준을 끌어올리고 있기도 합니다.
데이터 파이프라인에 사용중인 Airflow의 초기 구축은 AWS의 Managed Workflows for Apache Airflow 또는 GCP의 Composer 등과 같은 CSP (Cloud Service Provider)의 SaaS (Software as a Service)를 이용하여 손쉽고 빠르게 구축하였습니다. 시간이 지나고 기술 성숙도를 높여 K8S 클러스터 환경으로 전환하는 것에 도전하였습니다.
컬리가 데이터 파이프라인의 Airflow를 어떻게 구성하였는지 궁금하시다면 아래 글을 참고해 주세요
- 데이터 파이프라인 : 컬리의 BigQuery 도입기 2부
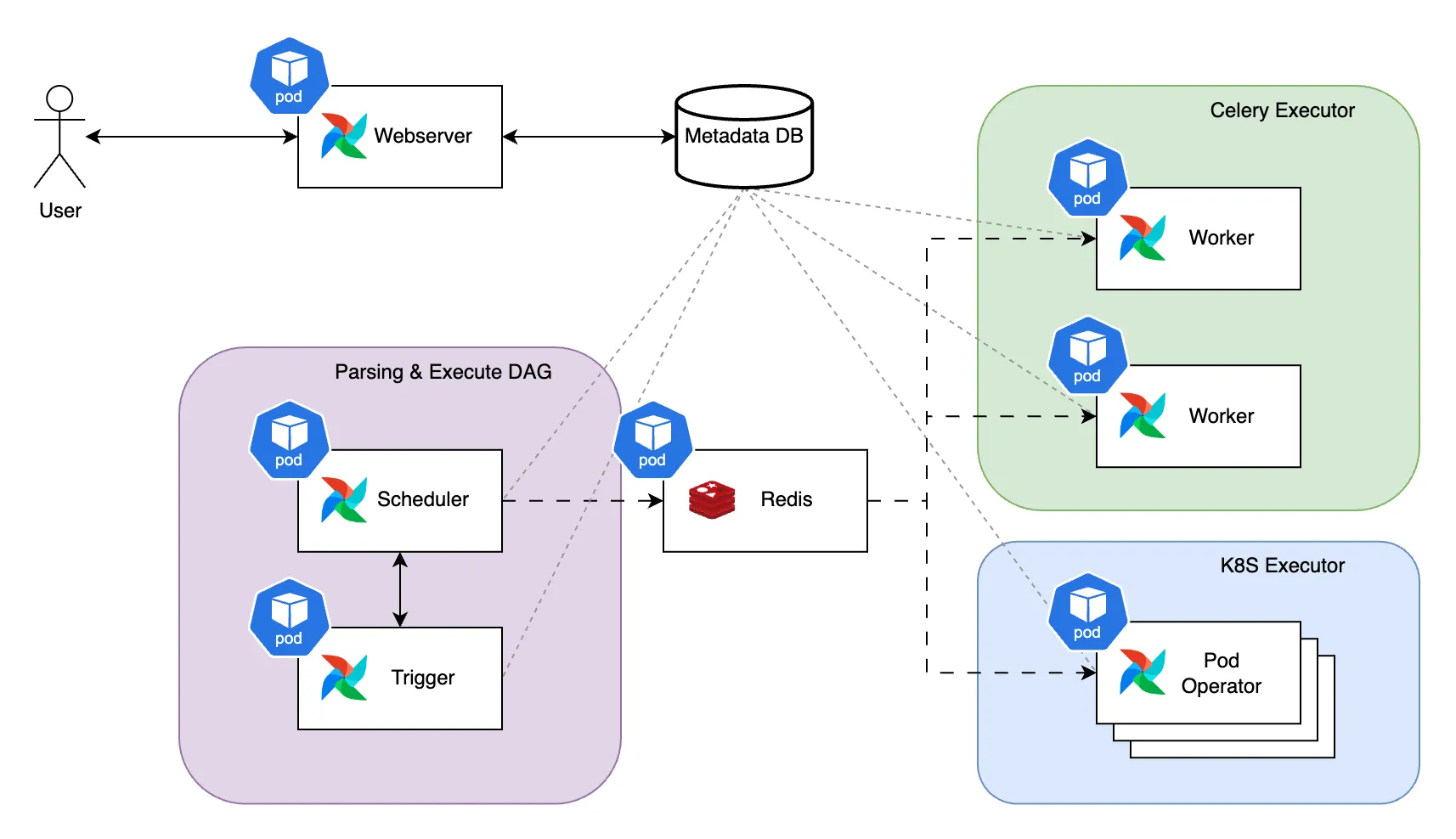
K8S위의 Airflow
 © 2024. Kurly. All rights reserved.
© 2024. Kurly. All rights reserved.
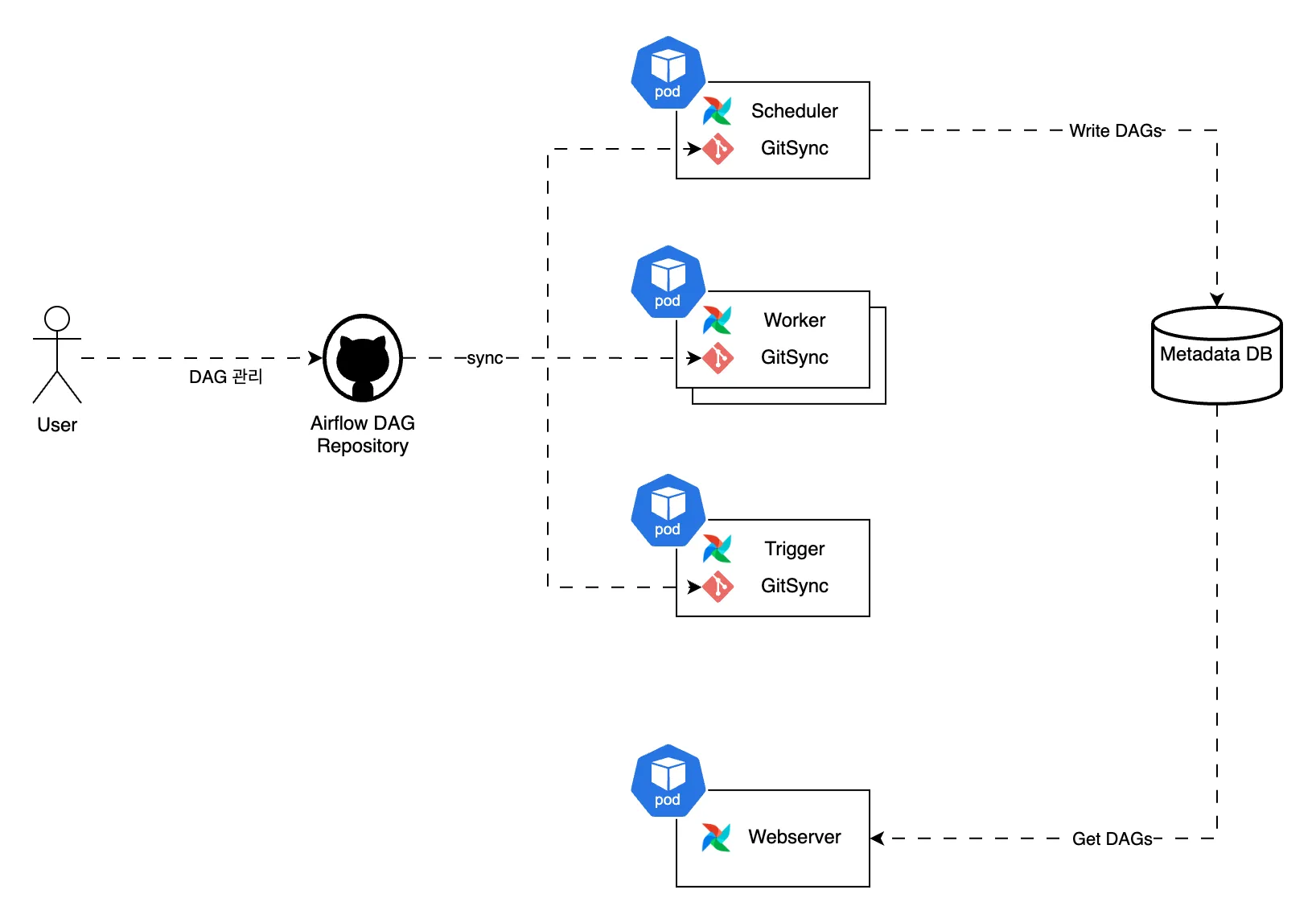
Helm을 통해 K8S 환경에 배포한 Airflow는 위 다이어그램의 형태로 구성되어 있습니다. 각각의 컴포넌트는 Metadata DB와 정보를 주고받으며 상태를 동기화하고 사용자는 웹서버를 통해 Airflow의 상태를 확인할 수 있습니다. Airflow의 작업은 스케줄러(Scheduler)와 트리거(Trigger)에 의해 레디스 큐에 발행되며, Pod나 셀러리 워커(Worker)에 순차적으로 할당되어 실행됩니다.
운영 이슈와의 조우
CPU 과부하 문제 해결하기
Airflow GitSync는 DAG를 로컬 디렉토리가 아닌 Github Repository와 같은 git 저장소에서 관리하는 기술입니다. 여러 사람이 git을 통해 DAG 파일을 추가하거나 수정하는 등 관리하기에 편리하여 사용하고 있습니다.
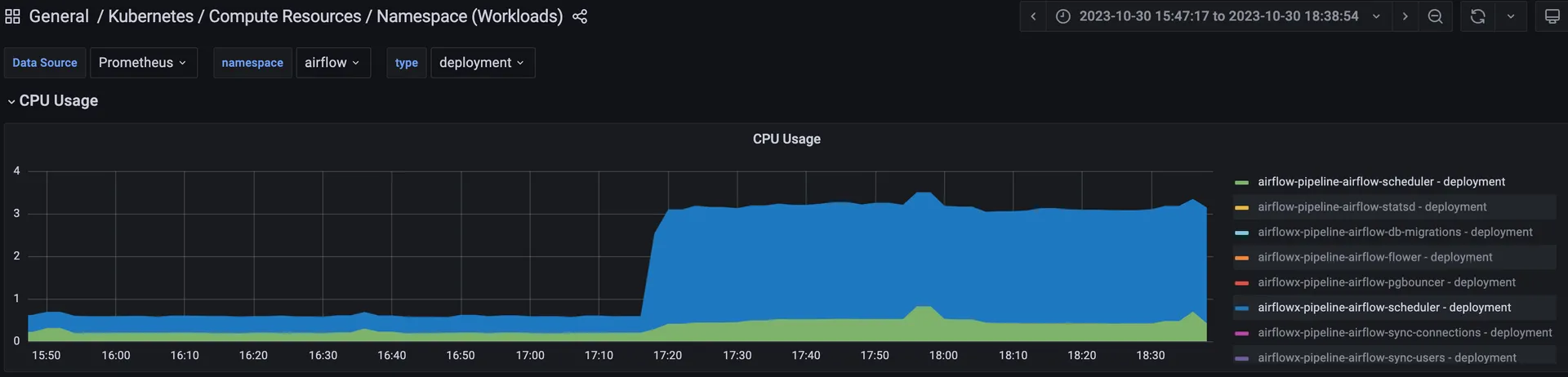
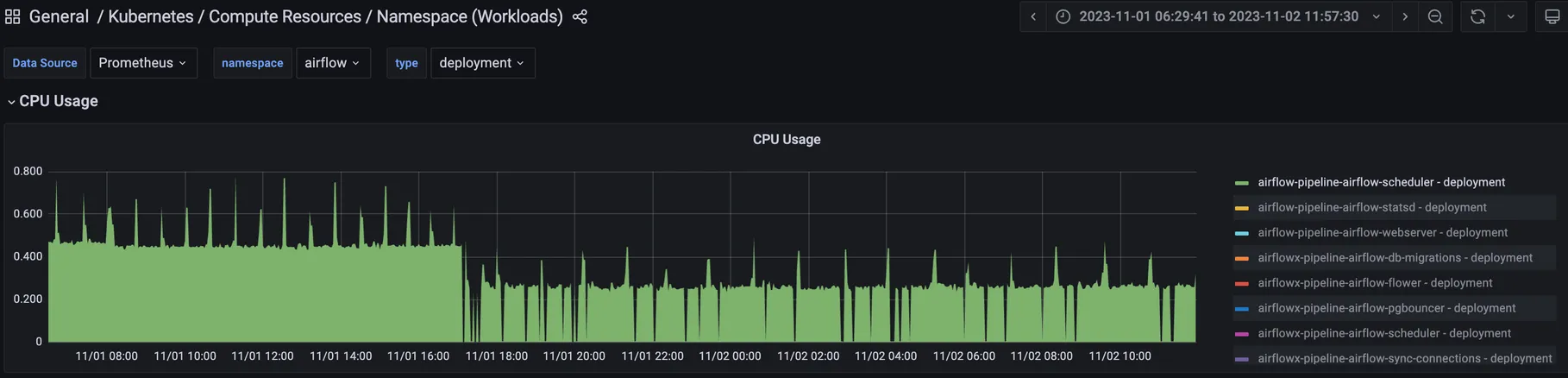
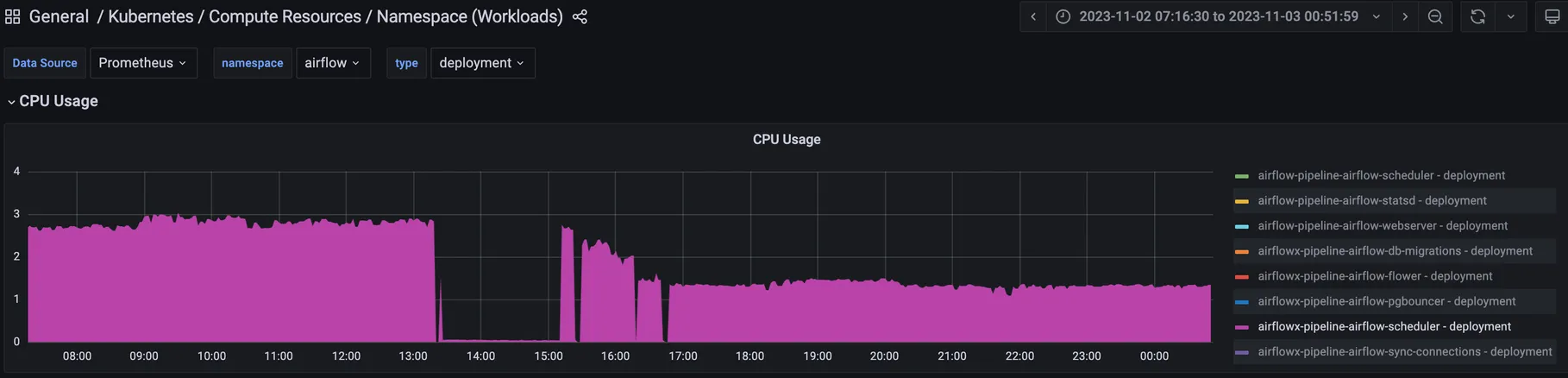
이관해 올 DAG들을 추가해주자 Airflow 스케줄러 (Scheduler)의 CPU 사용량이 급등하는 현상을 대시보드를 통해 확인했었습니다. 특히 저 당시에는 새로 배포한 Airflow 뿐만 아니라 개발용으로 배포되어 있던 Airflow도 같은 Git 레포지토리를 GitSync 해주고 있었기 때문에 배포되어 있던 두 가지 Airflow가 동시에 DAG 추가의 영향을 받았습니다.
 © 2024. Kurly. All rights reserved.
© 2024. Kurly. All rights reserved.
새로 배포한 Airflow는 스케줄러의 CPU 사용량이 0.25 core에서 0.45 core로 80% 증가, 개발용 Airflow는 스케줄러의 CPU 사용량이 0.4 core에서 2.7 core로 675% 증가했었습니다.
스케줄러는 DAG의 실행을 관리하는 역할을 수행하기 위해 지속해서 DAG 파일을 구문분석하고 작업을 적재적소에 할당합니다. DAG가 추가되면서 스케줄러의 CPU 사용량이 증가한 상황이므로 CPU의 파일 I/O를 줄이면 좋겠다는 조언을 받아서 Airflow의 작동에는 큰 영향을 주지 않을 적절한 파라미터를 찾게 되었습니다. 스케줄러가 DAG에 대한 업데이트를 위해 구문분석하는 시간 주기인 min_file_process_interval 값이었습니다. min_file_process_interval 값은 증가시키면 새로운 DAG 변경 사항의 반영이 느려지지만 파일 I/O의 빈도가 줄기 때문에 CPU 사용량이 줄어들기를 기대했습니다. 마침 DAG의 변경이 많지 않고 조금 늦게 반영이 되어도 문제가 없어서 이 값을 상향 조정시켜 주었습니다.
 © 2024. Kurly. All rights reserved.
© 2024. Kurly. All rights reserved.
 © 2024. Kurly. All rights reserved.
© 2024. Kurly. All rights reserved.
다행히 CPU 사용량은 효과적으로 감소하였습니다. “장애는 발생하지 않았으니 상관없다.” 라 생각할 수 있지만, 충분히 해결 가능한 문제였기 때문에 바로 대응을 했던 이슈였습니다.
 © 2024. Kurly. All rights reserved.
© 2024. Kurly. All rights reserved.
나중에 알게 된 사실이지만 GitSync는 다른 컴포넌트들에서도 동작하는데 스케줄러에서 크게 영향을 받은 이유는 위 그림 처럼 Airflow 2.0 버전부터 GitSync한 DAG 파일을 직렬화하여 Metadata를 관리하는 DB에 저장하는 작업도 수행하기 때문이었습니다.
Airflow 워커의 OOM 문제 해결하기
Airflow의 워커는 스케줄러와 트리거가 DAG의 태스크를 차례대로 수행하는 핵심적인 역할을 합니다. DAG의 작업을 수행하기 위해 Celery를 사용하는 워커는 태스크가 할당되면 이를 처리하기 위해 필요한 자원을 요청합니다. 그런데 이 워커들이 자원을 많이 사용하다 보니 파드나 노드가 비정상적으로 종료되어 장애가 발생하는 이슈가 있었습니다.
원인은 메모리 부족(OOM: Out of Memory)으로 워커에서 태스크를 수행하기 위해 자원을 요청하는 과정에서 자원이 충분하지 않거나 자원 경합이 발생하면 OOM 문제가 발생하여 파드나 노드가 비정상적으로 종료되는 문제였습니다. OOM 문제가 발생하면 애플리케이션이 중단될 수 있기 때문에 워크플로우 전체가 지연되거나 실패하게 됩니다. OOM 이벤트가 반복적으로 발생하면 시스템의 안정성과 성능에 심각한 영향을 미치며, 다른 파드나 서비스에도 연쇄적인 문제를 일으킬 수 있는 큰 문제입니다. 이 문제를 해결하기 위해 K8S와 Airflow에 관해 많은 연구와 시행착오를 겪었습니다.
OOM 문제는 다양한 원인으로 발생할 수 있으므로 간단한 문제가 아니라고 생각합니다. 특히 여러 계층으로 애플리케이션을 관리하는 K8S 환경에서 Airflow를 운영하고 있었기 때문에 확인해야 할 부분이 많았습니다.
Airflow가 동작하고 있는 K8S 환경은 효율적인 자원 활용을 위해 노드 내에서 한 파드가 자원을 상한선보다 적게 사용 중이라면 다른 파드가 이 파드의 자원을 사용할 수 있는 오버 커밋을 지원하고 있습니다. 하지만 이에 따라 한정된 자원을 더 할당받기 위해 요청을 하다가 자원 경합이 발생할 수 있습니다. 자원 경합이 발생하면 스로틀링을 할 수 있는 CPU와 다르게 메모리는 압축 불가능한 자원 (Incompressible Resource)이어서 시스템 장애로 이어지게 됩니다.
이런 이유로 순간적으로 큰 장애가 발생하는 것을 막기 위해 여러 계층에서 OOM이 발생하게 되어있습니다. 다음은 K8S에서 발생할 수 있는 OOM 목록입니다.
| OOM 이벤트 | Container level OOM | Kubelet level OOM | OS level OOM |
|---|---|---|---|
| 동작 시기 | 컨테이너에 설정된 제한 (limit) 보다 메모리를 많이 사용하려고 할 때 | 상한선 (Hard Eviction Threshold) 에 적용된 값보다 가용 리소스가 적은 경우 kubelet이 OOM을 감지 | kubelet이 OOM 상태를 감지하지 못한 채로 메모리 사용량이 급격하게 솟구친 경우. 리눅스에서의 OOM을 감지 |
| 목적 | 컨테이너가 정해진 자원만 사용하게 하기 위해 | 자원 경합으로 다른 파드에 영향을 주지 않기 위해 | 노드 자체가 완전히 죽는 상황을 방지하기 위해 |
| OOM 해결 방식 | 컨테이너를 종료 시킨다. | 1. MemoryPressure 상태 값을 true로 설정한다. 2. 파드들의 우선 순위에 따라 노드에서 축출 (Pod Eviction) 시킨다. 3. 축출된 파드는 프로세스가 모두 종료되며 다른 노드에 (MemoryPressure 상태가 false인 노드) 재할당 된다. | OS가 메모리 사용량이 높은 (OOM score가 높은) 특정 프로세스를 종료시킨다. 파드 안의 모든 컨테이너가 종료되지 않는다. |
표의 내용과 같이 K8S Pod 내부에서 동작하고 있는 Container 레벨, 여러 Pod 들의 자원을 관리하는 Kubelet 레벨, 리눅스에서 자원을 관리하는 OS 레벨의 3가지 단계에서 OOM이 발생 가능하며 각각의 단계에서 OOM이 발생하기 전에 순간적으로 제어 가능한 메모리 자원보다 많이 요구하여 단계별 시스템이 동작을 못하면 더 높은 단계의 시스템이 동작하여 OOM을 발생시키는 식입니다. 그리고 순간적으로 파드가 할당된 노드의 OS마저도 제어하지 못하는 수준으로 순간적인 메모리 사용량이 많으면 노드가 죽어서 함께 배치된 다른 파드에 영향을 주게 될 수 있습니다. 이 현상을 방지하기 위해 각 단계의 OOM은 공통으로 임계치보다 메모리 사용량이 증가하면 메모리를 과도하게 많이 사용한 대상부터 종료시키는 방법으로 동작합니다.
앞서 언급한 파드가 비정상적으로 종료되는 현상은 파드의 순간적으로 메모리 사용량이 증가하여 K8S에 설정된 상한선 (Hard Eviction Threshold)보다 가용 자원이 적어졌기 때문에 kubelet이 메모리를 많이 사용한 파드를 다른 노드로 보낸 조치이고, 노드가 비정상적으로 종료되는 현상은 순간적인 메모리 사용량을 OS도 감당하지 못하여 노드가 죽어서 장애가 발생했기 때문이었습니다. 이런 현상을 막기 위해 자원 경합이 일어나지 않을 만큼 자원을 더 늘리는 방법도 있지만, K8S에서 설정 가능한 자원 제한 정책이 해결에 도움이 되리라 생각했습니다.
# 자원 제한 정책의 예시
airflow:
worker:
resources:
limits:
cpu: 1000m
memory: 4Gi
requests:
cpu: 500m
memory: 2Gi자원 제한 정책으로 파드의 CPU와 메모리 자원에 request (요청) 및 limit (제한)을 설정할 수 있습니다. request가 설정되어 있으면 파드가 할당될 노드를 찾을 때 요청량만큼 자원이 충분한 노드를 찾을 수 있고 limit이 설정되면 CPU는 최대 사용량이 설정된 limit 까지만 사용되도록 제한되지만 메모리는 사용량이 limit이 있더라도 제한되지 않아서 limit을 넘겼을 때 Container 단계의 OOM이 발생합니다.
Container 단계의 OOM이 동작하면 더 큰 장애가 되기 전 조기에 대응될 수 있습니다. 그래서 메모리와 CPU 사용 경향을 모니터링하여 알맞은 request와 limit 설정을 하는 것을 권장하고 있습니다. 따라서 문제가 되었던 메모리에 자원 제한 정책을 적용하여 Airflow의 각 파드들이 할당될 때 평상시 사용하는 자원만큼 보장받을 수 있도록 하고 자원 사용량이 치솟아서 노드에 영향을 줄 만큼의 상황이 되기 전에 다른 노드에 할당되게 한다면 각각의 파드나 노드가 더 안정적으로 자원을 활용할 수 있게 개선될 수 있다고 생각했습니다.
하지만 이렇게 Airflow에 자원 제한 정책을 설정해 주어도 아직 정책이 적용되지 않은 다른 애플리케이션의 파드가 동일한 노드에 할당되는 문제가 발생하는 경우를 발견하였습니다. 그래서 가능한 많은 애플리케이션에 정책을 적용하기 위해 파드나 컨테이너 단위에서 정책을 하나하나 설정하는 방법이 아닌 K8S의 네임스페이스 단위에서 자원 관리에 사용하는 LimitRange와 ResourceQuota라는 정책도 고려해 보았습니다. 하지만, 컴포넌트별로 다른 자원 요구사항을 가지는 경우가 많은 데이터 애플리케이션들에는 적절하지 않다고 생각하였습니다.
좋은 자원 관리 방법을 데이터 엔지니어분들과 논의한 끝에 비교적 일정한 자원 사용량을 가지는 애플리케이션들은 K8S의 Taint와 Tolerations을 통해 애플리케이션마다 할당 가능한 노드를 분리하여 관리할 수 있도록 해주었습니다. 자원을 격리함으로써 Airflow가 자원 할당으로 인한 장애는 거의 발생하지 않게 되었고, 장애가 발생하더라도 더 빠르게 대응할 수 있게 되었습니다.
워커의 사라진 실행 로그 찾기
Could not read served logs: Client error '404 NOT FOUND' for ...
Airflow의 워커는 실행된 모든 태스크의 로그를 기록하고 웹서버의 GUI에서 편리하게 확인할 수 있습니다. 하지만 어느 날 주기적으로 실행되던 DAG가 실행돼야 했을 시각에 실행되지 못하고 다음 주기보다 늦게 실행되는 일이 있었습니다. 이유를 알기 위해 웹서버에서 로그를 보려 하였지만, 1차 실행을 실패한 로그는 찾을 수 없었고 위 로그처럼 404 코드만 확인 되는 처음 보는 이슈가 있었습니다.
작업이 지연된 이유를 찾을 때는 실행 로그만큼 확실한 방법이 없어서 혹여 로그가 존재하는데 웹서버에서 조회를 못 하는 이슈가 아닐지 직접 워커 파드에 접근하여 로그를 찾아보았지만 존재하지 않았습니다. 그래서 로그가 왜 없는지에 대해 고민했습니다. 첫 번째로 워커가 로그를 지웠을 가능성을 생각했지만, 삭제 이력은 찾지 못했습니다. 두 번째로 로그가 생성되지 못했을 가능성을 고려했습니다. 선행 작업이 밀리면 나중에 실행 되어야 할 후행 작업이 모두 밀리는 게 아니라 밀린 만큼 나중에 한꺼번에 실행된다는 점을 고려해 특정 시간대에 작업이 밀려 워커에 로그가 없는 상황을 확인했습니다. 특정 실행에서 로그가 평소와 다르게 남아있는 경우도 발견했습니다.
유심히 확인해보니 로그가 사라진 실행은 worker container에 로그가 조금 다르게 남아 있었습니다. 첫 실행이 삭제된 경우 [scheduled] 상태의 로그가 남아 있었지만 일반적일 때 [queued] 상태의 로그가 남아 있었습니다.
INFO - Running <TaskInstance: weird_task ... [scheduled]> on host ...
INFO - Running <TaskInstance: normal_task ... [queued]> on host ...그리고 실행 로그가 사라진 1차 다음의 2차 실행 로그를 보니 작업을 실행하려 했으나 scheduled 상태여서 실행을 하지 못했다고 알 수 있었습니다.
INFO - Dependencies not met for <TaskInstance: weird_task ... [scheduled]>,
dependency 'Task Instance State' FAILED: Task is in the 'scheduled' state.
INFO - Task is not able to be run이 정보를 바탕으로 어떤 순서대로 작업이 실행되는지 실마리를 찾기 위해 공식 문서를 확인했습니다.
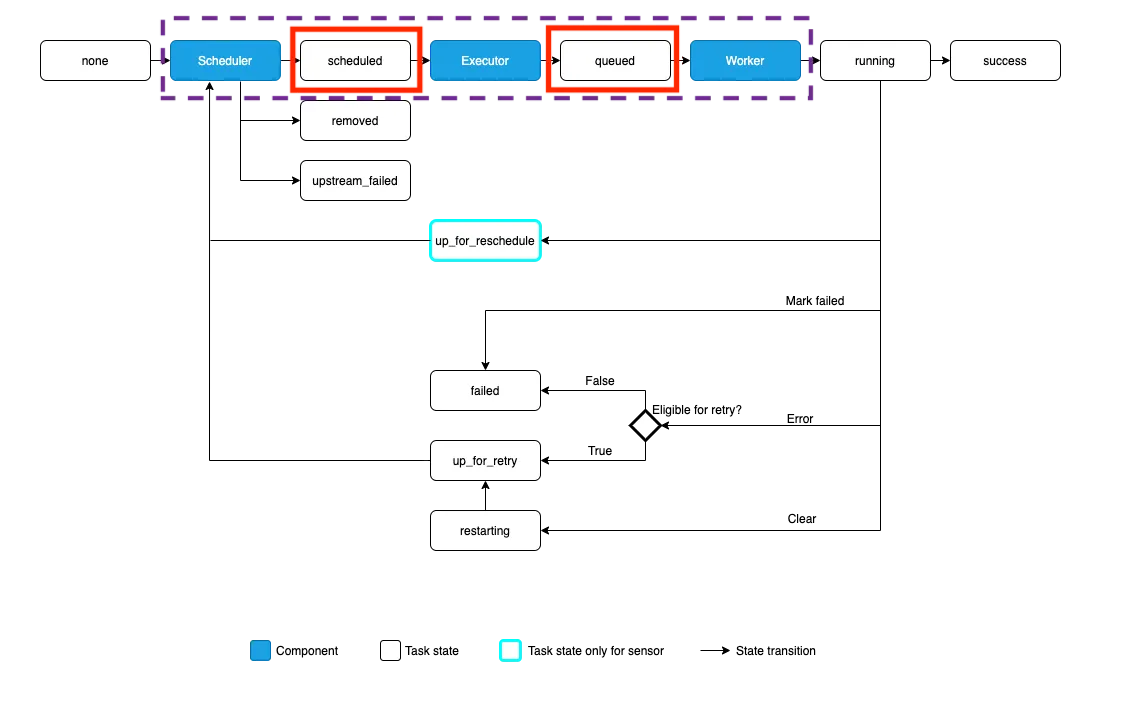
공식 문서에서 Airflow의 작업 실행 프로세스를 위 다이어그램 플로우로 설명하고 있습니다. 스케줄러에서 태스크를 Executor에 넘기기 전에 scheduled 상태가 되고 그다음에 Executor에서 queued 상태가 된다는 사실을 확인할 수 있었습니다. 이 사실을 바탕으로 로그가 사라지는 경우를 태스크가 scheduled 상태에서 워커의 문제로 Executor에 할당되지 못한 상황으로 추측했고, 로그를 남기는 주체인 CeleryExecutor에 태스크가 가기 전에 1차 실행이 끝났다면 로그가 존재하지 않을 수 있다는 가설로 이어지게 되었습니다.
CeleryExecutor 워커에 태스크가 할당되지 못한 이유를 찾기 위해 워커가 장애로 중단된 기록이 있는지 먼저 확인하였습니다. 하지만 중단 의심 시점에 중단 기록보다는 다른 작업의 실행 로그가 있는 상황으로 보아 워커의 중단보다는 다른 작업이 지연되어 오래 대기한 현상으로 판단하게 되었습니다. 그리고 결정적으로 지연이 발생한 시점에 BigQuery에서 문제가 발생하여 태스크의 요청 작업이 비정상적으로 오래 걸렸던 상황을 발견했습니다. 작업이 밀리다 보니 태스크들이 워커에 할당되기 전에 1차 실행이 타임아웃으로 종료되었고 이 현상이 원인으로 2차 실행의 로그부터 기록되었습니다. 특히 최근 연동하는 파이프라인이 많아지며 DAG의 수가 증가하게 되었는데 워커에 동시에 할당 가능한 태스크의 숫자가 상한선에 다가온 게 원인이라는 결론을 내렸습니다.
따라서 워커가 더 많은 양의 태스크를 동시에 처리할 수 있다면 작업이 오래 걸려서 밀리는 현상은 제외하더라도 scheduled 상태에서 오래 머물러서 로그조차 없는 문제는 해결할 수 있다고 결론을 내리게 되었습니다. 이렇게 하기 위해서는 두 가지 방법이 있었는데 워커에 자원을 더 할당시키는 스케일 업을 해주고 워커에서 동시에 처리할 수 있는 작업의 수 worker_concurrency 를 증가 시키는 방법과 워커의 수를 더 늘려서 스케일 아웃을 하는 방법 사이에서 고민했습니다. 이 고민은 생각보다 쉽게 결정이 되었는데 그동안 워커를 한대로 운용하고 있었기 때문에 이참에 두 대로 늘리는 방법을 선택하는 게 조금 더 K8S 환경에 적절한 방법이라 생각이 들어서 워커의 수를 늘리는 스케일 아웃을 하는 방법을 선택하게 되었습니다. 그 이후로는 Airflow에서 작업이 지연되는 현상이 확인되는 일이 확연히 줄어들었습니다.
마무리
운영 환경 전환의 효과
운영 환경 전환을 통해 Airflow와 K8S에 관한 기술 역량이 많이 증가하기도 하였지만 관리형 서비스에서 발생하던 고정 비용은 K8S에서 노드 사용 비용으로 바뀌면서 50% 가량 감소하는 효과도 있었습니다. 직접 문제를 해결하면서 Airflow 인프라 관리에 있어서 로그 수집과 모니터링 고도화 등 안정성을 높이는 작업이 더 필요하다고 느끼게 되었습니다. 따라서 여러 기술을 검토하며 Airflow를 K8S에서 더욱 안정적으로 운영하기 위한 노력을 끊임없이 이어나갈 계획입니다.
소감
Airflow의 운영 환경을 전환하면서 빠른 도입을 위해 관리형 서비스로 시작을 하고, 기술 성숙도를 높여 직접 관리하는 환경으로 전환하는 인프라의 성장 과정을 경험할 수 있었습니다. 개발자들 사이에는 일단 어떤 인프라 도입을 하겠다고 선언을 하고 직접 수 많은 이슈와 함께 동거동락 하는 방식이 선언형 인프라라는 우스갯소리가 있습니다. 직접 경험을 해본 입장으로는 시행착오에서 경험하는 실전 경험들이 더욱 빠른 성장을 위한 원동력이 되었고 가장 중요한 것은 “왜 이렇게 되는 거지?” 와 같은 기술에 대한 호기심이라고 느끼게 되었습니다.
컬리는 빠르게 신기술을 도입하고 고도화하며 기술 수준을 지속적으로 끌어올리고 있습니다. 앞으로도 다양한 기술들의 운영 환경을 전환하여 직접 운영을 해보는 도전을 이어갈 것입니다. 이러한 도전에 함께하고 싶은 분들은 컬리에 오셔서 직접 경험하며 성장할 수 있으니 컬리의 채용에도 많은 관심 부탁드립니다.