마켓컬리와 머신러닝!
컬리에서는 고객님들의 후기 이미지의 분류 자동화를 위해 미약하지만, 머신러닝을 사용하고 있습니다. 관련 기사
당시 파이썬과 머신러닝에 대한 지식이 전무한 상태로 모델을 개발했고 지금도 마찬가지 벌써 1년이 넘게 해당 모델은 잘 사용하고 있습니다.
도입 당시 10%에 육박했던 스크린샷 후기 이미지의 비율이 현재는 1% 대로 감소하였습니다.
하지만 1년이 넘게 추가 훈련 없이 모델이 운영되다 보니 오분류나 정확도 개선의 요구사항은 꾸준히 있었고, 모델의 개선을 위해 준비하던 중 훈련 이미지 만들기에 대해서 있었던 이야기를 공유하고자 합니다.
아래에 나오는 파이썬 예제코드는 파이썬을 모르는 잡ㅏ 개발자가 마구잡이로 적은 것이기 때문에 코드의 품질보다는 가볍게 봐주셨으면 좋겠습니다. 😎
므씬러닝의 시작은 생각보다 멋있지 않다
후기 이미지 분류기를 만들겠다고 생각하고 나서 처음으로 만난 어려움은 바로 훈련데이터 만들기였다.
파이썬은 어떻게든 되겠지 라고 생각했고, 예제 코드도 있었으며 예제코드를 살펴보고 할 만하다고 생각해서 시작했지만
이건 정말 답이 안 나오는 문제였다.😭
이미지 준비하기
일단 훈련을 할 이미지를 준비해야 한다.
이 부분은 생각보다 쉽게 해결 할 수 있었는데 컬리에서 사용하는 후기 이미지는 모두 s3에 저장되기 때문이다
일자별로 분류되어있으며 매일 약 6~8,000개의 이미지가 업로드된다.
2020년 1월 기준으로 대략 600만 개의 이미지가 있을 것으로 예상됨.
s3에 있는걸 이제 알았으니 이미지를 로컬에 받는 건 aws-cli를 사용하면 매우 쉽게 수행할 수 있다.
aws s3 cp s3://bucket/path/to/review/20190303 .이렇게 하면 해당 일자의 이미지를 모두 받을 수 있다.
이미지 검증하기
대략 3일 치의 이미지를 받아서 1만 개가 조금 넘는 이미지를 확인해 보면 몇 가지 문제점들을 확인 할 수 있다.
파일이 많아서 맥북 파인더가 느려지는 거 말고
보통 장바구니 단위의 구매가 발생하다 보니, 상품별로 같은 후기 이미지가 중복 등록되는 경우가 많다.
또, 업로드 하다가 실패한 경우 잘못된 이미지도 존재한다.
특히 이미지 자체가 잘못된 경우에 한참 훈련 도중에 몇 시간 동안 진행되던 훈련이 오류로 종료되기도 하였다. 😭😭😭
이 문제는 이렇게 해결했다.
중복 이미지 삭제
중복 이미지 삭제는 이미지 파일의 해시값을 구한 후 동일한 해시값이 존재하면 중복파일로 가정하고 삭제하도록 했다.
import os
from hashlib import sha1 as hash
from IPython.display import clear_output
hashes = {}
for dirpath, dirnames, filenames in os.walk("download"):
for filename in filenames:
filepath = os.path.join(dirpath, filename)
hashobj = hash()
with open(filepath, "rb") as file:
hashobj.update(file.read())
file_id = hashobj.digest()
duplicate = hashes.get(file_id, None)
if duplicate:
clear_output(wait=True)
print(f"Duplicate found: {filepath}")
os.remove(filepath)
else:
hashes[file_id] = filepath
print("DONE!")잘못된 이미지 삭제
잘못된 이미지는 좀 더 단순하게 해결했는데 그냥 Image 객체로 파일을 읽고 오류가 나면 잘못된 거로 판단했다.
import sys
import os
from PIL import Image
for path in paths:
for dirpath, dirnames, filenames in os.walk(path):
for filename in filenames:
full_path = os.path.join(dirpath, filename)
print(full_path)
Image.open(full_path).load()
print("OK")이제 이미지가 준비되었으니 훈련용 데이터를 만들어야 한다. 🤢
훈련데이터 만들기
mark1 - 드래그앤드롭
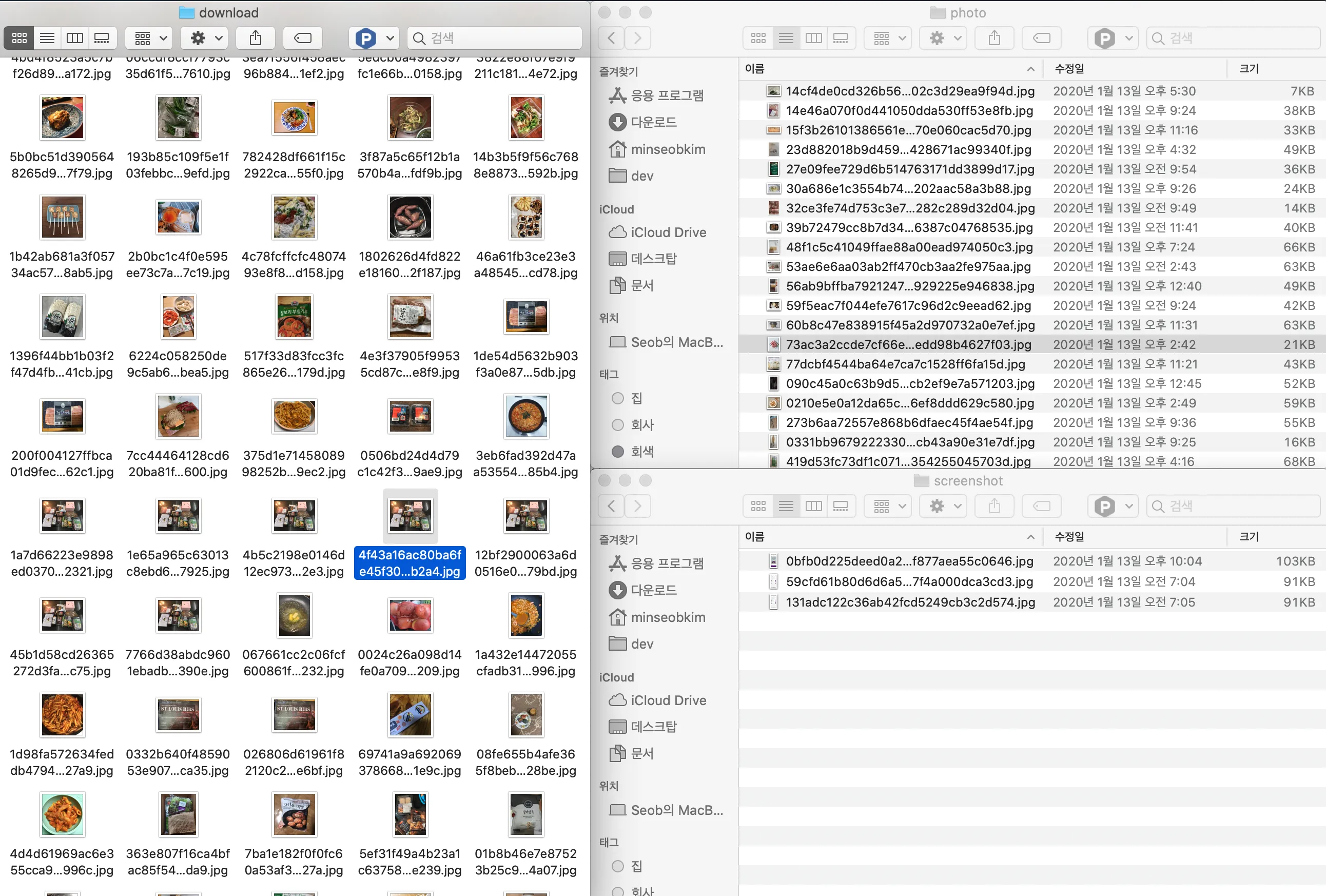
첫 번째 방법이자 현재 서비스하는 모델의 훈련 데이터를 만든 버전으로
위처럼 창을 배치하고 파일을 선택해서 드래그 앤 드롭으로 데이터를 분류하였다. 인간지능
이 방법은 준비해야 하는 훈련 이미지의 형태 때문에 가능하였는데.
필요한 분류의 체계가 스크린샷이거나 사진인 2종류였기 때문에 파인더의 미리 보기만으로도 분간이 가능했고
여러 개의 사진 중에 스크린샷이 가끔 섞여 있는 정도라서 여러 개를 선택해서 옮기기 적합했기 때문이다.
아이러니하게도 이 방법이 가장 효율이 높았다. (1만 장 조금 넘는 데이터를 분류하는데 한 시간 조금 넘게 걸린 듯하다)
그렇지만 잘못 분류할 가능성이 가장 크기도 하였다.
mark2 - 분류기

두 번째 버전은 사진을 화면에 하나씩 띄우고 커맨드를 입력받아 파일을 분류하는 방식이다. 인간지능v2
파일을 하나씩 보고 분류하기 때문에 정확도는 높지만, 속도가 어쩔 수 없이 느리다
빨리하면 초당 2개씩 분류할 수 있는데 1만 개를 분류하려면 한 시간 반 정도 소요된다. (생각보다 괜찮네??)
import os
from PIL import Image
from IPython.display import display
from IPython.display import clear_output
os.makedirs("data/training/photo", exist_ok=True)
os.makedirs("data/training/screenshot", exist_ok=True)
for dirpath, dirnames, filenames in os.walk("download"):
total = len(filenames)
for i, filename in enumerate(filenames):
filepath = os.path.join(dirpath, filename)
try:
img = Image.open(filepath)
img = img.convert(mode='RGB').resize((448, 448))
print(filepath)
display(img)
img.close()
result = input(f"({i + 1}/{total}) 0:exit 1:photo 2:screenshot")
if result is '0':
clear_output(wait=True)
break
elif result is '1':
os.rename(filepath, "data/training/photo/" + filename)
elif result is '2':
os.rename(filepath, "data/training/screenshot/" + filename)
clear_output(wait=True)
except Exception as e:
# 잘못된 이미지파일
os.remove(filepath)
print("DONE")반 인간지능
이 방법은 처음부터 사용할 수 없고 일단 분류 할 수 있는 모델이 있어야 한다.
첫 번째 모델이 배포되고 난 이후에 두 번째 모델훈련을 고민하면서 고안했던 방법인데
첫 번째 모델을 이용하여 이미지를 선 분류 하고 작업자는 데이터를 확인만 하는 방법으로
이미지가 어느 정도 분류가 되어있어서 생각 없이(?) 빠르게 작업을 진행 할 수 있다.
대신 이미지를 기계가 분류해야 하므로 로컬에서 작업하면 맥북이 매우 힘들어하고 사양에 따라서 시간이 오래 걸릴 수 있다. (필자의 맥북 기준 장당 200ms 정도 소요 끽해봐야 인간지능보다 2.5배)
그리고 오늘
새로운 모델을 훈련하기 위해 최근 10만 장의 이미지를 로컬에 받아서 준비하였다.
이미지가 10만 장 정도 되니 파인더로 폴더에 접근하면 파인더가 멈춰버린다. mark1 사용불가
그러던 중 Ground Truth를 발견하고 알아보았다.


내가 필요한 그것
이 서비스를 사용하면 이미지 분류를 자동화하거나 외부 인력 또는 지정된 인력을 이용하여 수작업으로 데이터를 분류 할 수 있다.
이미지 분류를 자동화하는 것은 AWS의 내부 분류 알고리즘을 사용하기 때문에 유효할 것이라고는 생각되지 않는다.
(기능 자체도 메인이 아닌 옵션으로 제공하고 있음)
대신 인력을 지정하여 분류작업을 수행할 수 있는 것은 기존에 했던 분류 방법이 여러 명이 수행할 수 없다는 단점을 해결 할 수 있다.
작업 생성하기
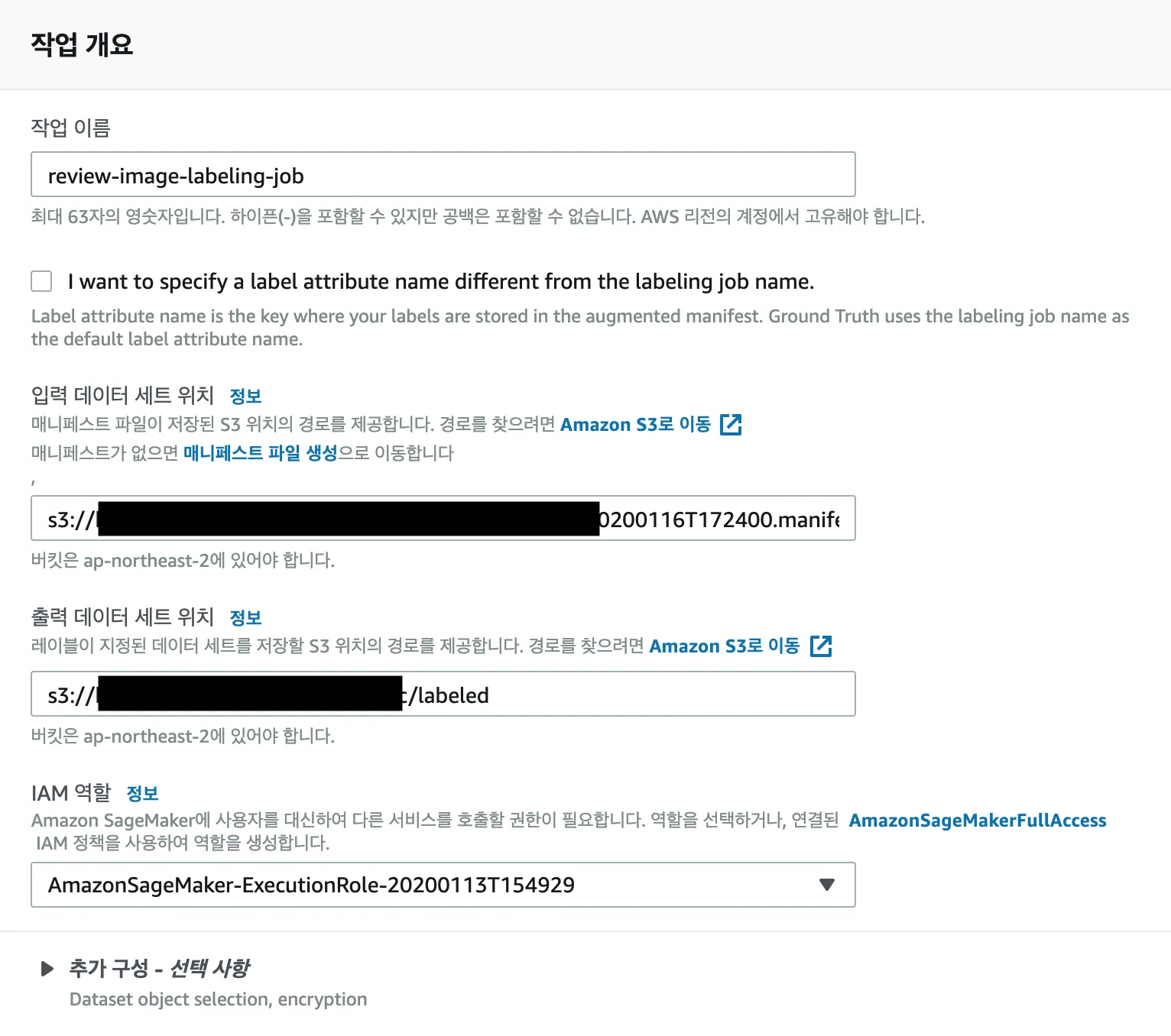
일단 분류할 파일이 모두 s3에 올라가 있어야 하고, 메니페스트 파일이 있어야 하는데
매니페스트 파일 생성을 통해 간단하게 생성 할 수 있다.
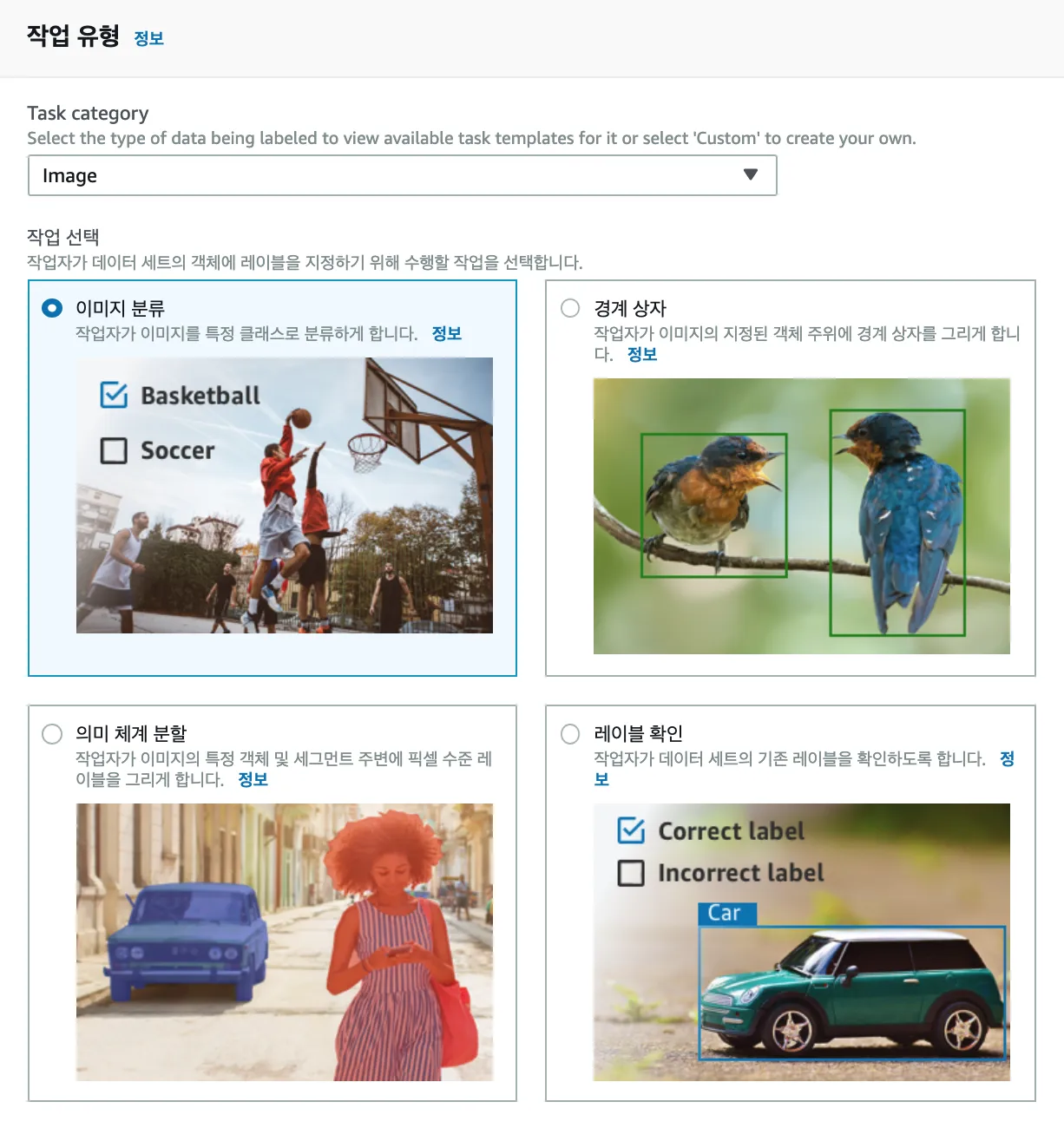
작업유형은 크게 이미지와 텍스트, 사용자 지정으로 나뉘고, 분류별 상세 작업을 선택 할 수 있다.
우리가 필요한 것은 이미지 분류이니 이미지 분류 작업을 기준으로 알아보았다.
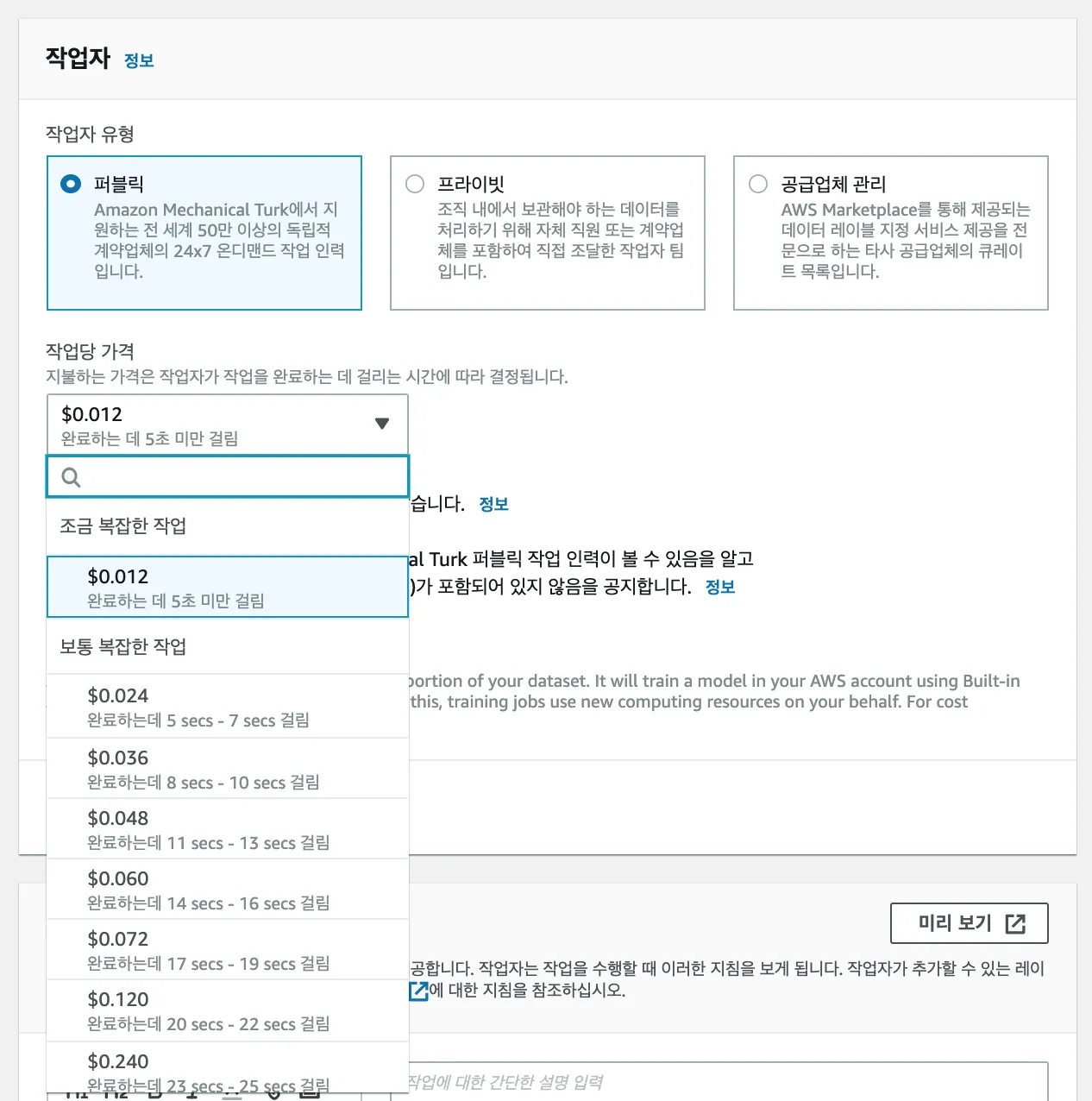
이미지 분류작업을 누구에게 지정할 것인지에 대한 선택지가 있는데
크게 AWS 외주, 프라이빗, 다른 업체 외주가 있다.
재미있는 것은 AWS 외주를 사용하면 분류 난이도에 따라 가격이 다르게 책정이 되어있고
난이도의 기준이 분류 시간인 것이다.
1,200로 한화로 하면 약 139만 원이다.
넉넉잡아 2초에 1장을 분류한다고 가정하면 한사람이 6시간 정도 작업하면 1만 장의 작업을 할 수 있는데
시급 만 원으로 계산하여 국내에서 작업한다면 60만 원이면 가능하다.
고오오오급 인력 AWS

프라이빗을 선택하면 이메일을 기준으로 사용자를 초대할 수 있는 기능을 제공한다. 내가 원하는 그것!
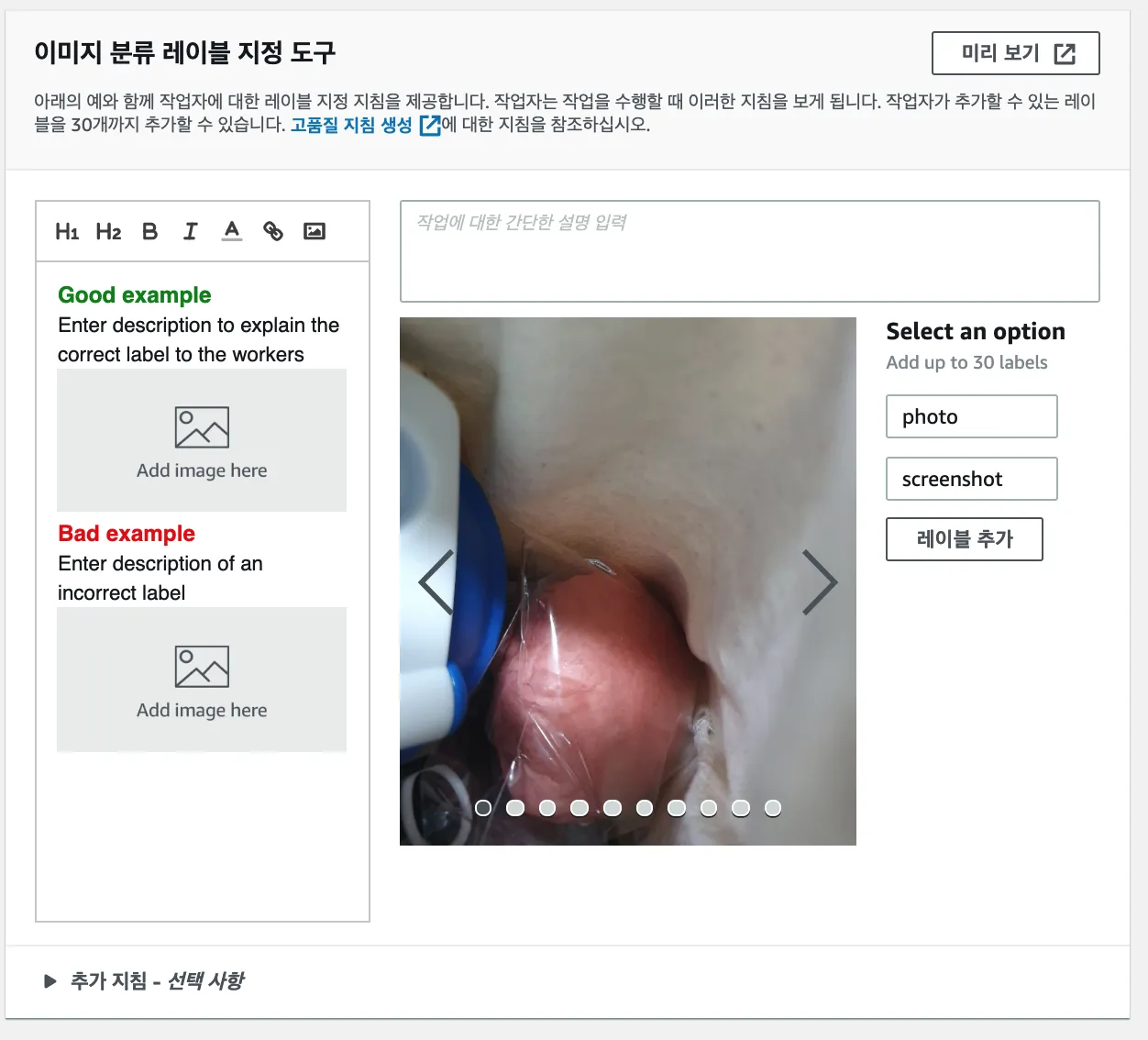
그리고 실제 작업자가 볼 화면을 설정 할 수 있다.
분류의 예나 작업 사항, 라벨을 지정하고 미리 볼 수 있다.
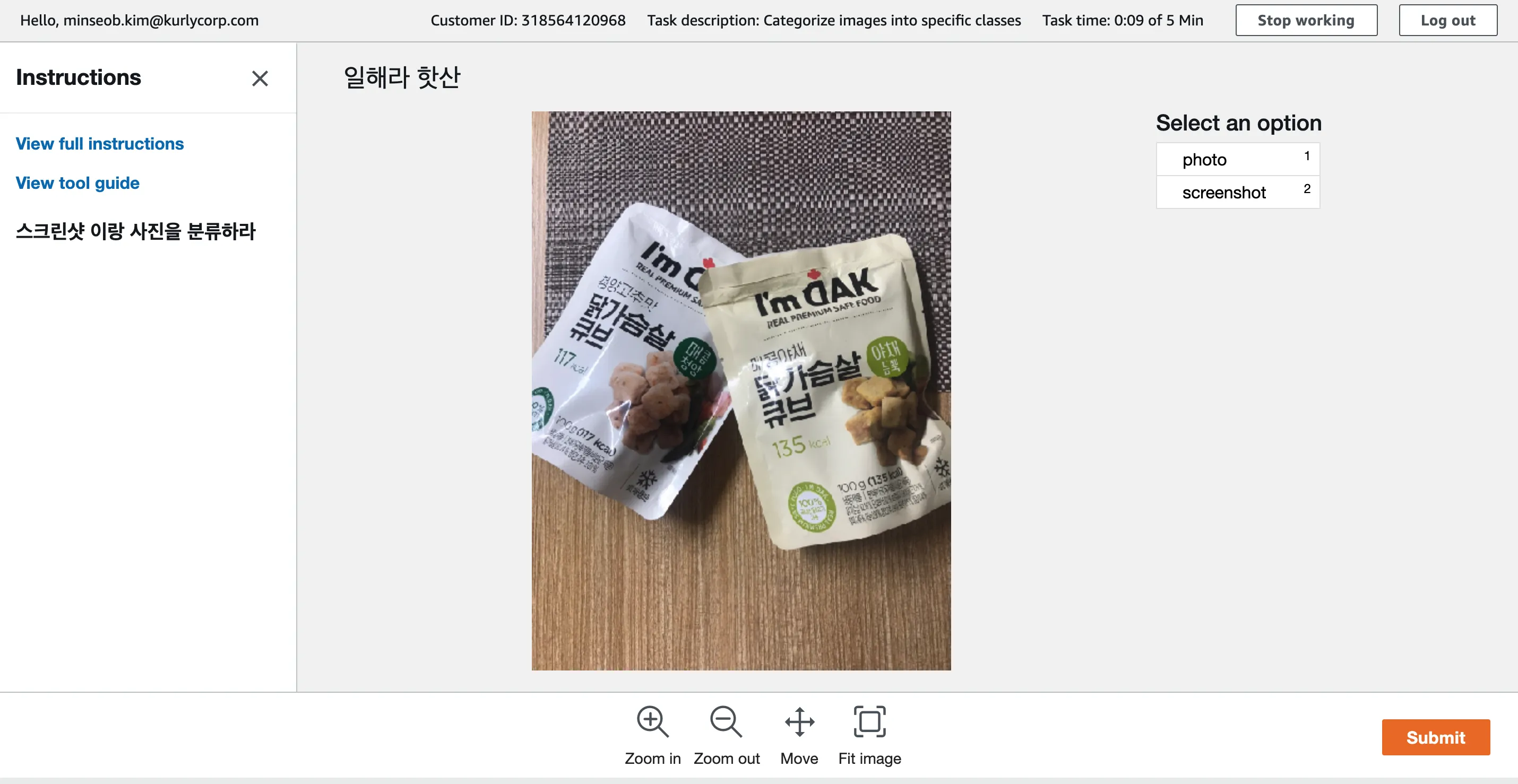
위 과정을 거치면 작업자에게 초대 이메일이 전송되고 이메일에 있는 링크를 통해 로그인하면 아래와 같은 화면을 볼 수 있다.
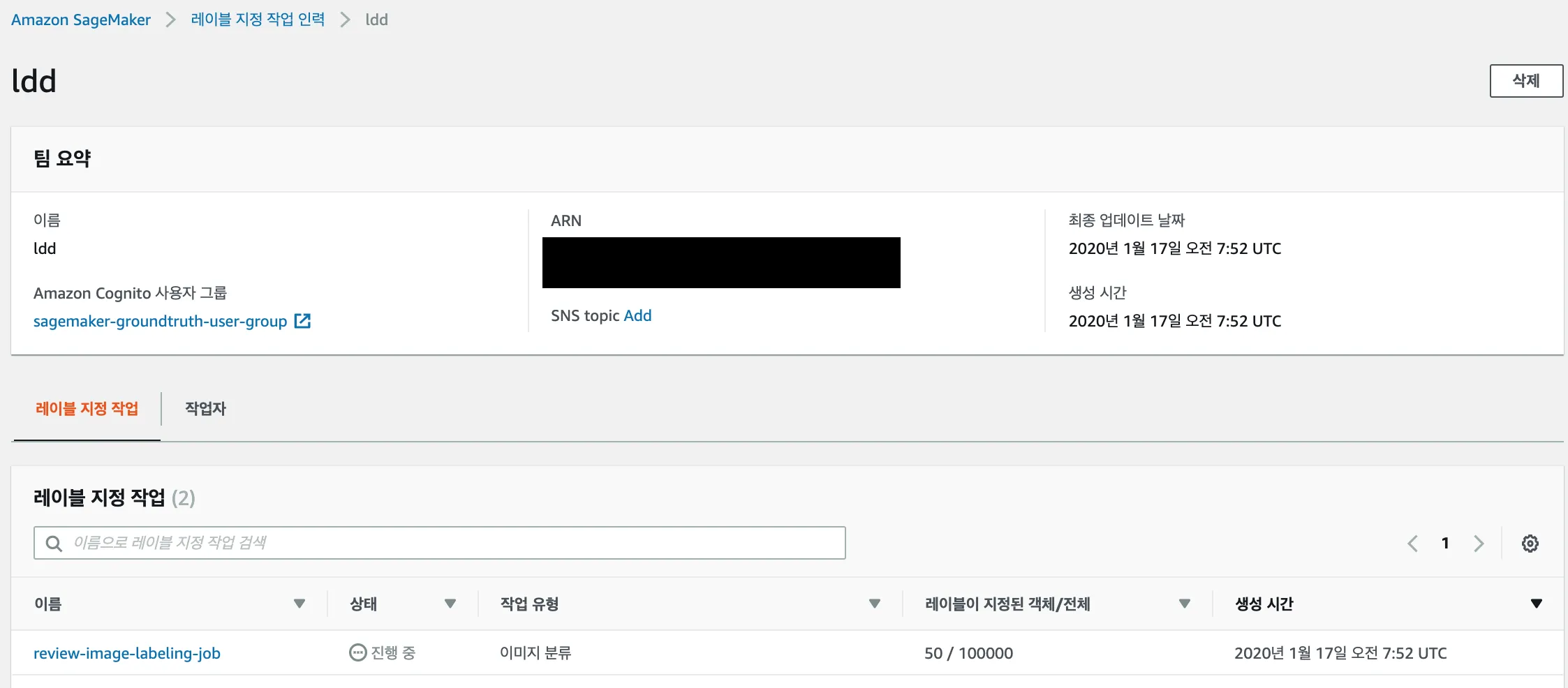
그리고 작업자가 작업을 진행하면 관리화면에서 진행 상황을 볼 수 있다.
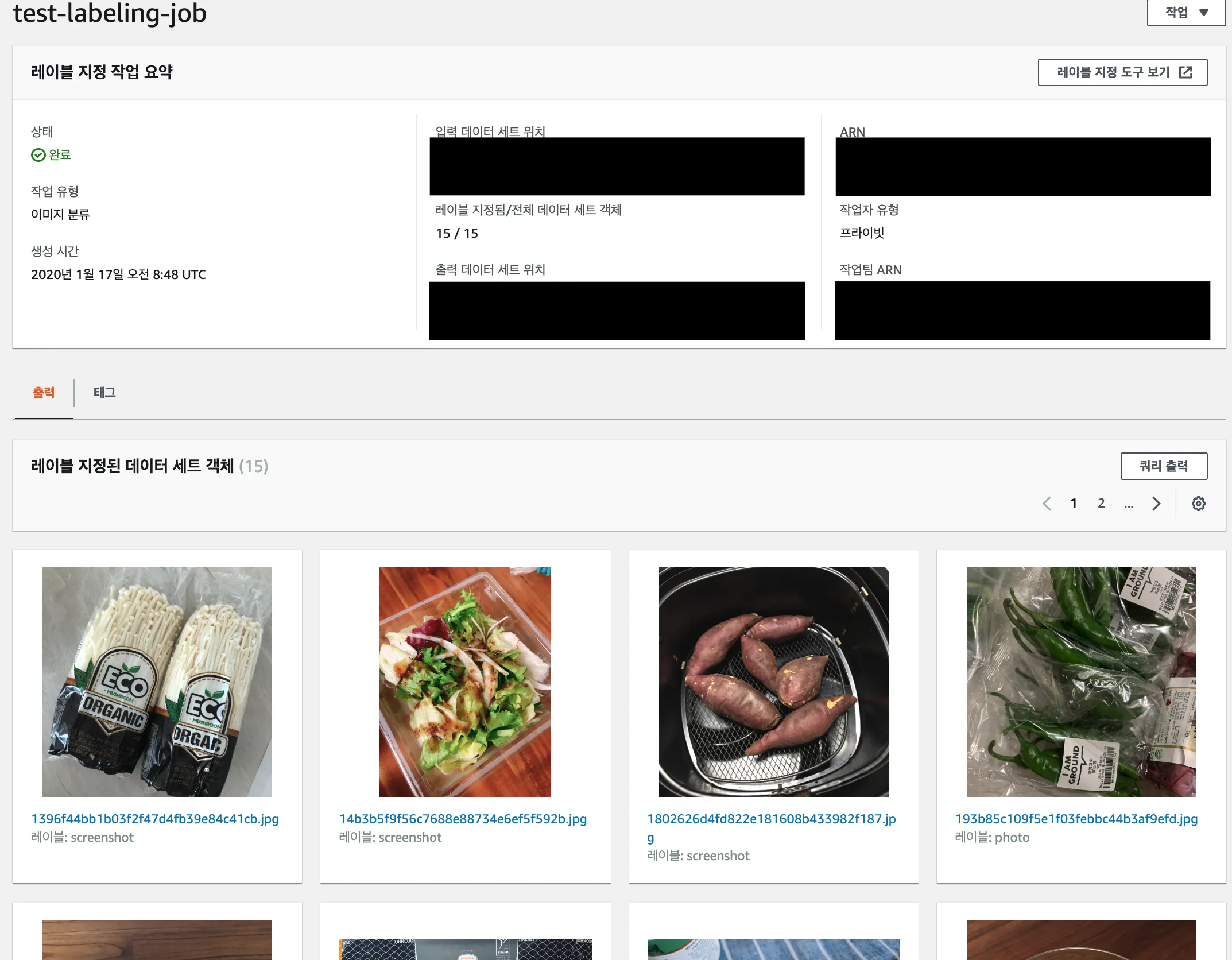
작업이 완료되면 쿼리출력을 통해 분류 결과를 json 형태로 받아볼 수 있다.
이 json에는 이미지의 경로 등의 정보와 분류 결과가 있는데 이 정보를 이용하여 훈련 이미지를 준비 할 수 있다.
이후 Chain을 통해 결과를 다시 분류하거나, 작업을 종료 할 수 있다.
결론
AWS Sagemaker Ground Truth는 훈련 데이터를 다수의 작업자가 편리하게 분류 할 수 있게 만들어 주는 좋은 방법이라고 생각됩니다.
하지만 레이블 지정 객체 수별 요금체계를 가지고 있기 때문에 내부의 작업자가 작업하더라도 위 10만 개의 분류 작업에는 $4,000의 요금이 부과됩니다. 😱😱😱😱
훈련에는 필수적으로 많은 데이터가 필요한데 다소 높은 요금 때문에 실제로 도입하기에는 무리가 있어 보여 아쉬웠습니다.
아 그래서 저 10만 장 분류는 어떻게 해야 할까요?
이 고민은 아직도 진행 중입니다. 좋은 방법을 찾아내면 다음에 또 볼 수 있겠네요. 🙏