안녕하세요. 데이터농장 데이터사이언스 팀에서 근무하고 있는 김왕수입니다.
지난 2022년 11월 8일~9일, AWS 코리아가 역삼 센터필드에서 고객사들을 대상으로 MLOps 분산학습 워크숍을 진행했습니다. 저희 팀에서는 함께 근무하고있는 윤선범님과 제가 참석할 수 있는 기회가 주어져 이틀 동안 워크숍에 참가하였습니다.
워크숍에서는 MLOps에 대한 동향 및 AWS의 클라우드서비스인 SageMaker에 대해 알아보는 시간을 가질 수 있었는데요. 해당 포스트를 통해 워크숍에 방문했던 후기를 블로그에 남겨보고자 합니다.
DAY 1
첫날은 AWS 내의 유명한 강사이신 Emily Webber의 기조연설로 시작했는데요.

이번 AWS에서 고객사들의 현업담당자들을 대상으로 진행한 워크숍 방식의 행사는 Emily Webber가 처음으로 제안해 흥행에 크게 성공하여 전 세계적으로 운영 확장되고 있다고 합니다. 아시아 국가 중에서는 한국이 아마도(?) 첫 시도일 것이라고 하네요.

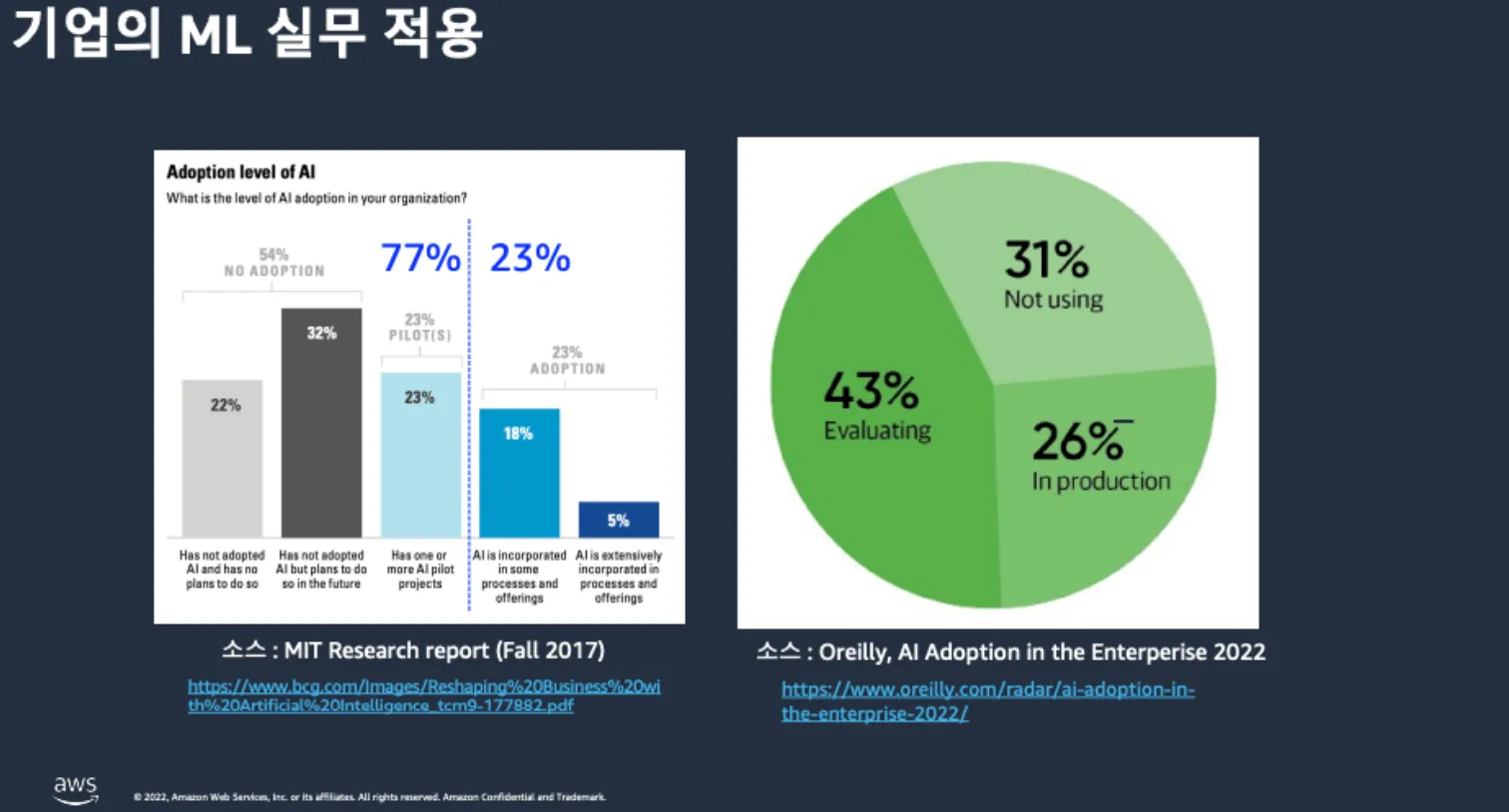
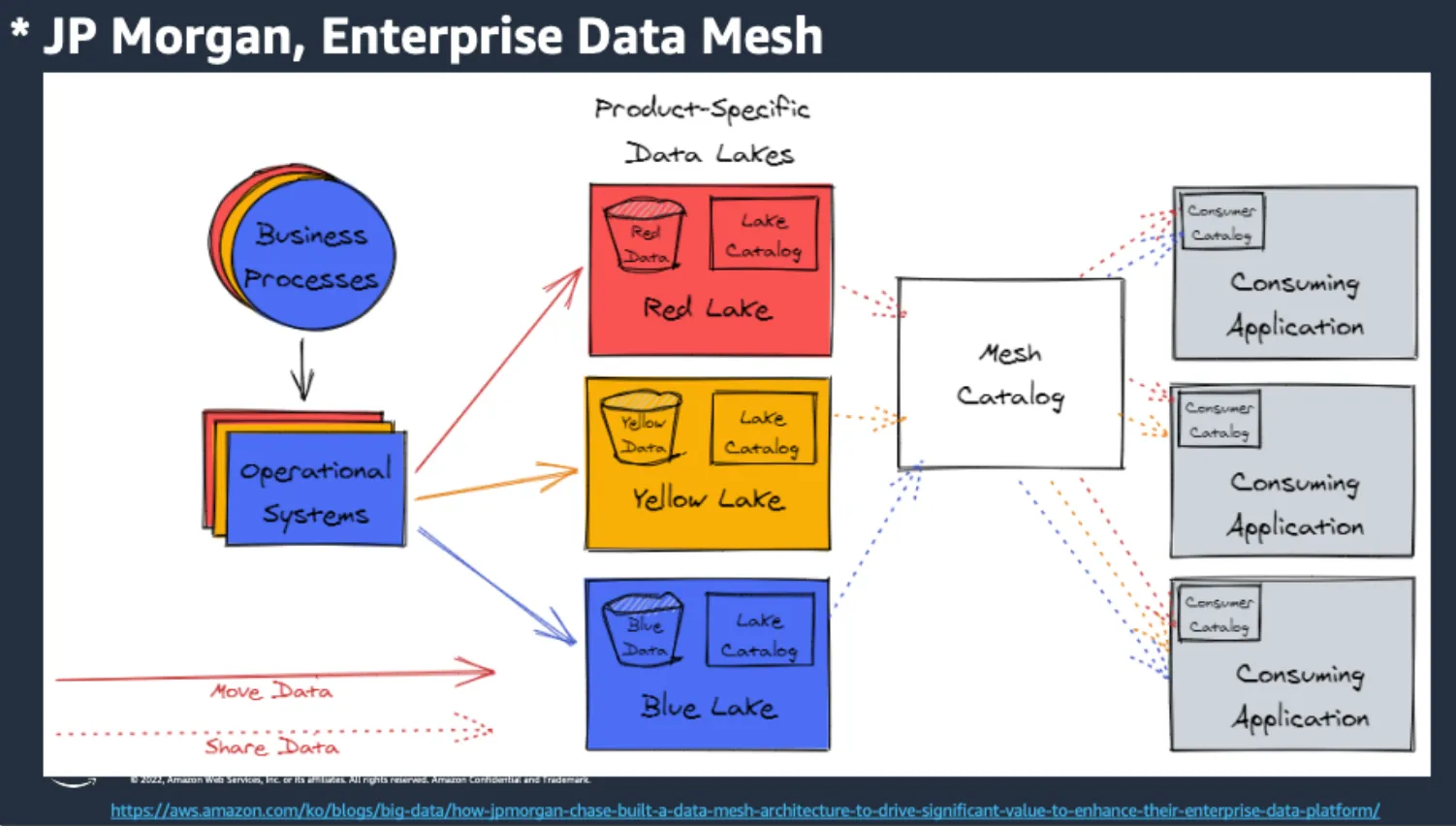
기조연설 다음으로 이어진 오전 세션에서는 MLOps에 대한 기초적인 내용 및 AWS의 해외 고객사들의 MLOps 구축사례를 통해 MLOps 환경을 어떻게 구축하여 사용하고 있는지 동향에 대해 파악할 수 있었습니다. 최근 회사들의 Machine Learning 실무 적용률의 변화라든지, JP Morgan의 Data Mesh 구축, Fidelity의 Feature Store, Vanguard의 ML IDE 환경 생성 자동화 등 여러 가지 흥미로운 사례들을 소개받을 수 있었습니다.
여기서 Data Mesh라는 개념은 처음 듣는 단어라 흥미로웠는데요. Data Lake의 새로운 패러다임이며, 이전의 중앙집중 방식의 Lake를 역할별로 분리 후 Mesh Catalog를 통해 Consumer Application으로 나가는 형태라고 합니다. 해당 방식을 이용하면 시스템 복잡도는 증가하지만, Data Lake에서 발생하는 여러 가지 문제를 해결할 수 있다고 합니다. (이외에 다른 해외 기업에 대한 MLOps 구축사례는 AWS MLOps 및 분산학습 워크숍 페이지에 가시면 확인해보실 수 있습니다!)
이후 오후 세션에서는 SageMaker를 도입한 국내기업의 실무자들이 참여하는 세션이었습니다. 소속된 회사에서 어떻게 SageMaker를 도입하여 사용하고 있는지 소개하는 세션과 직접 SageMaker를 가지고 실습을 진행해보는 세션을 진행했습니다.
국내기업에서는 ‘LG에너지솔루션’과 ‘동화기업’의 실무자분들께서 참석해 주셨는데요. MLOps를 사내에 어떻게 도입하고 있는지, 어떤 프로젝트에서 어떤 기능을 활용하고 있는지와 같은 이야기들을 해주셨습니다. 두 기업 모두 제조업 회사라 공정에 적용한 사례들 중심으로 설명해주셨습니다(자세한 얘기는 해당 기업에 실례가 될 것 같아 생략하겠습니다).
실습세션에서는 SageMaker의 MLOps관련 기능들에 대해 실습해 보는 시간을 가졌습니다. 실습환경에 약간의 사소한(?) 문제가 있었지만 ETL tool, Feature Store, Model Registry, Model Artifact, Deployment, Model Monitoring, Model Orchestration 등 정말 많은 기능들을 SageMaker 하나로 처리할 수 있다는 걸 알 수 있어서 좋았습니다.
DAY 2
둘째 날은 주로 대규모 분산학습 위주로 워크숍이 진행되었는데요. 분산학습에 대한 트렌드, 분산학습 고객 사례, 실습 위주로 세션들이 구성되어 있어 분산학습에 대해 알아보는 시간을 가질 수 있었습니다.
먼저 오전에는 분산학습에 대한 트렌드와 첫날에 키노트를 진행한 Emily Webber님이 소개하는 고객 사례 세션이 진행되었습니다.
분산학습에 대한 트렌드로는 최근 Text-to-Image나 Text-to-Video와 같은 대규모 데이터나 모델을 활용하는 애플리케이션을 등장으로 분산학습의 필요성이 대두되고 있으며, 이러한 시대적인 흐름에 따라 AWS도 SageMaker를 통해 분산 학습 및 추론 기능들을 지원하고 있다는 내용들로 구성되어 있었습니다. Open AI의 ‘Scaling Laws for Neural Language Models’나 AWS 한국팀의 시계열 모델 실험 사례를 통해 데이터, 모델의 파라미터, 컴퓨팅 자원이 커질수록 모델의 성능이 향상됨을 실험적으로 확인할 수 있음을 예로 들며 분산학습의 필요성을 어필한 부분이 인상적이었습니다.
이어서 클러스터 분산 학습을 크게 2가지로 나누어 설명해 주셨는데요. 크게 분산 학습에는 데이터 병렬처리(Data Parallelism)를 통한 방법과 모델 병렬 처리(Model Parallelism)를 위한 방법이 있으며, AWS에서는 분산학습을 위한 병렬처리를 위해 Traininium이라는 칩을 만들어 분산학습에 사용 중이란 것을 알 수 있었습니다. 추가로 Amazon SageMaker Ephemeral Training 클러스터 사용 시 관리형 Spot Instance를 통해 학습비용을 절감하는 방법(모델이 커질수록 추천하지 않음), SageMaker Debugger를 통해 CPU, GPU bottleneck 구간을 확인하거나 학습 데이터 크기에 따라 적절한 데이터 옵션 선택 방법(테라바이트급 데이터에서는 Amazon FSx Luster를 사용) 등 다양한 사용 방법들을 전수(?)해주셨습니다.
오전 세션의 마지막으로는 어제 기조연설을 진행한 Emily Webber의 분산 학습 고객 사례 세션이 있었는데요. Salesforce의 CodeT5, Aurora의 Autonomous Model 등 대규모 분산학습을 사용하여 서비스에 적용 중인 여러 가지 고객사 사례들을 볼 수 있었습니다. 그리고 국내기업으로는 여러 세션에서 연사분들이 LG AI Research의 틸다를 언급하셔서 자연스레 국내기업에서도 대규모 모델을 클라우드 서비스를 통해 학습하는 회사가 있다는 것을 알 수 있었습니다.
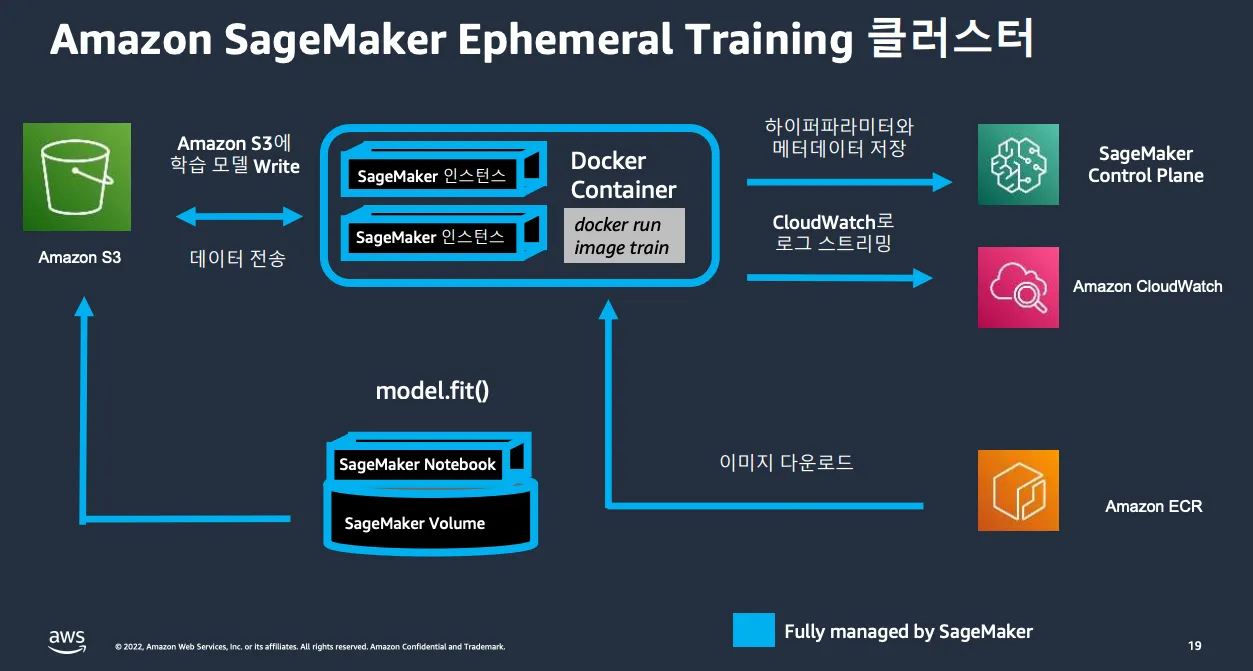
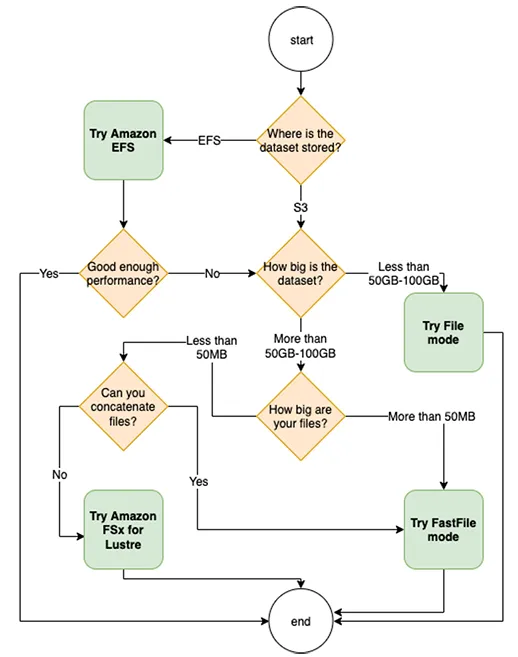
오후 세션은 분산 학습에 대한 실습과 추론을 위해 SageMaker에서 제공하고 있는 서비스 포트폴리오에 대해서 소개하는 시간이었습니다.
실습에서는 SageMaker Studio를 활용해 GPT-2 모델을 학습해 보는 시간을 가졌는데, 연사님들께서 실습용 코드를 미리 준비해주셔서 손쉽게 SageMaker를 경험해 볼 수 있었습니다.
마지막 세션에서는 데이터 사이언티스트 및 엔지니어들이 가진 특정한 스킬 셋을 활용해 배포를 구현할 수 있도록 다양하게 갖추어 놓은 SageMaker의 포트폴리오를 소개하며, SageMaker 내에서 추론을 위해 지원하는 여러 가지 방법들 또한 소개받을 수 있는 시간이었습니다.
추론 기능을 구현하기 위해 사용하는 도구들이 데이터 과학자 및 엔지니어의 스킬 셋에 따라 상이할 수 있는데, SageMaker는 이를 잘 지원할 수 있도록 여러 가지 포트폴리오를 구성해놓았음을 알 수 있었습니다.

후기
네트워킹
Data drift를 확인하고 재학습 시기를 결정하는 부분을 자동화하는 것에 관심이 있었는데 첫날 소개된 SageMaker의 MLOps 기능 중 Data Clarify와 Model Monitor에서 해법을 찾을 수 있을 것 같다는 기대를 했었습니다. 마침 연사분들 중에 저희팀 윤선범님의 지인이신 AWS의 김대근 님이 있으셔서 네트워킹할 기회가 있었는데 여러 가지 자료들을 소개해주셨습니다.
Data drift란, 모델 배포 후 입력되는 데이터의 통계적 분포가 학습에 사용된 데이터의 분포와 달라지는 현상을 말합니다. Data drift가 발생하면 예측을 위해 입력되는 데이터의 분포가 달라져 모델의 예측 성능이 저하될 수 있기 때문에, 모니터링과 재학습을 통해 모델 성능을 유지해 주어야 합니다.
Youtube: Amazon SageMaker 모델 모니터로 자연어 처리 모델의 데이터 드리프트 감지하기
AWS web page: (클릭)
맛있는 도시락
무료 행사였는데 식사를 정말 잘 준비해주셔서 맛있게 잘 먹었습니다~^^ 도시락 퀄리티가 정말 좋았어요! 마지막 날에는 저녁도 준비해 주셨었는데 아쉽게도 다른 일정이 있어 참석하지 못했습니다.