1부에서는 BigQuery 도입 배경과 그 주안점에 대해서 소개했습니다. 2부(이번 글)에서는 신규 데이터 파이프라인과 BigQuery 도입 결과 및 효과를 소개하겠습니다.
신규 데이터 파이프라인 아키텍처
신규 데이터 파이프라인 아키텍처는 크게 2가지로 분류할 수 있습니다.
RDBMS(Oracle, Aurora DB) 데이터 연동을 위한 정형 데이터 파이프라인 아키텍처와 DocumentDB 데이터 연동을 위한 비정형 데이터 파이프라인 아키텍처입니다.
비정형 데이터는 정형 데이터와 달리 스키마가 고정적이지 않기 때문에, 파이프라인에서 데이터 변환이 필요합니다.
정형 데이터 파이프라인 아키텍처

Kafka Topic의 CDC 로그는 일자 기준으로 파티션 된 BigQuery의 CDC 로그 테이블에 BigQuery Streaming API를 통해 저장됩니다. CDC 로그 테이블은 연동하는 DB 테이블의 변경된 레코드(Record)의 데이터, 변경된 레코드의 DML(Data Manipulation Language) operation과 CDC 로그 발생 일시(timestamp)를 저장하는 테이블입니다.
CDC 로그 테이블은 GCP Cloud Composer(Airflow)의 BigQuery Job Operator가 실행하는 Merge Procedure을 통해 주기적으로 Final 테이블에 데이터를 넣어줍니다. Final Table은 원본 DB 테이블과 동일한 상태인 BigQuery 테이블입니다. Merge Procedure는 Merge 문으로 작성했습니다. Merge Procedure는 Final 테이블의 데이터와 CDC 로그 테이블의 데이터를 비교해서 원본 DB 테이블과 동일한 상태의 테이블을 만듭니다. Merge Procedure는 Primary Key, 생성일자, DML operation, CDC 발생 일시(timestamp) 4가지 칼럼이 필요하며, 컬리의 모든 RDBMS 테이블에는 Primary Key와 생성일자가 포함되어 있습니다. CDC 로그 테이블은 Merge Procedure에 필요한 4가지 칼럼을 항상 포함하고 있습니다.
CDC 로그 테이블은 GCP Cloud Composer(Airflow)의 BigQuery Job Operator가 실행하는 Merge Procedure을 통해 주기적으로 Final 테이블에 데이터를 넣습니다. Merge Procedure가 실행되면, Final 테이블은 원본 DB 테이블과 동일한 상태가 됩니다.
비정형 데이터 파이프라인 아키텍처

Kafka Topic의 CDC 로그는 JSON Format Processing을 진행합니다.
아래 테이블은 JSON Format Processing을 진행한 테이블입니다.
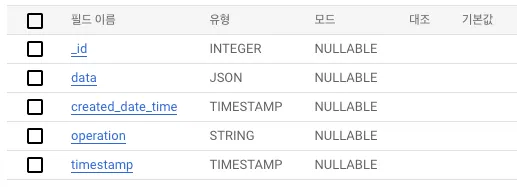
JSON Format Processing을 진행하면 Merge Procedure에 필요한 칼럼들이 CDC 로그 테이블에 BigQuery Streaming API를 통해 중복 저장합니다.
원본 Document는 CDC 로그 테이블에서 data라는 JSON 타입 칼럼에 넣어서 추가되는 칼럼이 누락되지 않도록 구축헀습니다.
JSON Format Processing을 진행하면 추가되는 칼럼에 대해서 일일이 대응을 하지 않습니다.
BigQuery는 JSON 타입을 지원합니다.
JSON 타입을 이용하여 JSON Format Processing을 단순하게 구현할 수 있습니다.
CDC 로그 테이블은 GCP Cloud Composer(Airflow)의 BigQuery Job Operator가 실행하는 Merge Procedure을 통해 주기적으로 Final 테이블에 데이터를 넣습니다. Merge Procedure가 실행되면, Final 테이블은 원본 DB Collection과 동일한 상태가 됩니다.
BigQuery 도입 결과 및 효과
데이터 레이크하우스 구축
BigQuery는 기존 Data Warehouse와 달리 스토리지 비용이 상당히 저렴하며 확장성이 굉장히 뛰어납니다. 운영 DB 테이블 연동 이외에도 운영 DB 테이블의 이력(CDC 로그), 데이터 마트를 주기적으로 삭제하지 않고 보관할 수 있습니다.
장기간 보관이 필요한 운영 서비스 및 운영 어플리케이션 로그와 데이터의 양이 많아 저장할 수 없던 로그도 BigQuery에 보관할 수 있습니다. BigQuery는 JSON 타입을 지원하기에 다양한 로그를 손쉽게 보관할 수 있습니다.
데이터 파이프라인 개선
기존 Data Warehouse는 스크립트를 통하여 Data Warehouse 테이블과 AWS S3에 있는 CDC 로그 데이터를 비교하여 UPSERT(Update + Insert) 방식으로 데이터를 적재했습니다. 해당 스크립트의 동작 방식은 임시 테이블 생성, 과거 데이터 삭제, 신규 데이터 삽입, 임시 테이블 삭제 4단계를 거쳐서 적재해서 속도가 느렸습니다.
또한 UPSERT 방식은 Delete 작업이 반영되지 않아 원본 테이블과 정합성이 맞지 않는 경우가 발생했습니다.
BigQuery는 Merge 문을 사용하여 Insert, Update, Delete를 스크립트를 사용할 필요 없이 빠른 속도로 데이터를 적재했으며, 데이터 연동 지연 시간이 대폭 감소했습니다.
쿼리 응답 시간 감소
BigQuery에서 데이터 파이프라인을 위한 프로젝트와 데이터 조회를 위한 프로젝트를 분리하여 구축했습니다.
데이터 파이프라인과 데이터 조회가 한정된 자원이 아닌 할당된 자원을 사용해서 쿼리 응답 시간이 대폭 감소했습니다.
또한 테이블 조회 시 파티션을 꼭 사용하도록 옵션을 설정하여 스캔 용량을 줄여 쿼리 응답 시간을 개선했습니다.
체감속도가 얼마나 빨라졌는지, CTO 형규님의 반응은 아래와 같았습니다.

비용 감소
기존 Data Warehouse는 서버 규모에 따라 정해진 금액만큼 비용을 지불했습니다. BigQuery는 스캔 비용에 따라 비용을 지불하거나 슬롯을 예약 구매하여 정해진 비용을 낼 수 있습니다.
비용 절감을 위해서 스캔 용량이 크고, 사용자가 많은 프로젝트와 데이터 파이프라인을 위한 프로젝트에는 슬롯을 예약했습니다. 스캔 용량이 크지 많은 프로젝트는 슬롯 제약은 두지 않되 하루 데이터 스캔 용량을 제한했습니다. 그 결과 비용이 기존보다 많이 감소했습니다.
BigQuery 이관 및 도입 후기
BigQuery 도입부터 이관과 완료까지 6개월 동안 기존 데이터 파이프라인 운영과 함께 이관 작업을 진행했습니다. 신규 데이터 파이프라인 설계 및 구축을 위해 기존 데이터 파이프라인 변경도 진행을 해서 꽤 오랜 시간 소요됐습니다. 초기 POC부터 신규 데이터 파이프라인 설계 및 구축, 데이터 이관까지 정말 많은 고민을 했습니다. 데이터플랫폼팀과 데이터 엔지니어분들의 도움으로 이번 BigQuery 도입을 완료할 수 있었습니다.
e-Commerce 최초로 BigQuery를 도입해서 앞으로 컬리가 데이터를 가지고 할 일이 더 많아질 것 같습니다. 앞으로 컬리 데이터플랫폼팀에 많은 응원과 관심 부탁드립니다! 감사합니다.
Reference
BigQuery 문서 * 본 게시물에 사용된 이미지들의 저작권은 컬리에 있습니다. 사용 시 출처를 꼭 명시해주세요.