 © 2024. Kurly. All rights reserved.
© 2024. Kurly. All rights reserved.
소개
안녕하세요, 컬리 데이터서비스개발팀에서 일하고 있는 Data Engineer 김영준, Product Manager 송재현입니다. BigQuery 환경에서 다양한 데이터 분석 업무를 진행하는 컬리에서, 최근 구글의 LLM 모델 Gemini Pro를 BigQuery console 화면에서 호출하여 사용할 수 있다는 소식을 들었습니다. PM과 엔지니어도 모델 구현에 대해 고민하는 시간을 줄일 수 있게 되어, 비용 효율적으로 다양한 분석 결과를 직접 도출할 수 있다는 기대를 갖게 되었습니다. 이번 글에서는 컬리 리뷰 데이터로 진행한 Gemini 분석 활용 예시를 공유합니다.
쉽고 간단한 Gemini 호출 Query 사용법
Gemini를 BigQuery에서 사용하기 위한 사전 준비
Gemini 모델은 GCP의 Vertex AI에서 제공됩니다. 따라서 BigQuery에서 Gemini 모델을 사용하려면 Vertex AI로 요청을 보낼 수 있도록 아래의 두 가지 설정이 필요합니다.
- Vertex AI에 접근하기 위한 연결 (Connection) 생성
- BigQuery 데이터셋에 사용할 Gemini 모델 (Model) 추가
Gemini를 사용해보려면 아래의 링크를 따라서 설정합니다.
BigQuery에서 Gemini에게 인사하기
BigQuery에서 Gemini를 사용하는 것은 SQL을 사용해 본 경험이 있으신 분들이라면 BigQuery에서 Gemini를 사용하는 것은 쉬운 일입니다. BigQuery ML을 사용하기 위해 간단한 설정을 마치고 나면 바로 사용이 가능합니다. 아래 보시는 것과 같이 짧은 SQL문으로 사용이 가능합니다.
SELECT
ml_generate_text_llm_result AS result
FROM
ML.GENERATE_TEXT(
MODEL `llm_model.gemini_pro`, -- 사용할 모델
(SELECT "안녕" AS prompt), -- 프롬프트
STRUCT (TRUE AS flatten_json_output) -- 파라미터
)사용할 Gemini 모델과 서브 쿼리에 선언된 프롬프트를 ML.GENERATE_TEXT 함수에 사용해서 호출하는 형태입니다. 추가로 Gemini 모델에서 사용할 파라미터를 STRUCT 자료형에 작성하여 호출도 가능합니다.
그리고 쿼리를 실행한다면 아래와 같이 결과를 얻을 수 있습니다. LLM 모델인 Gemini로 생성하는 문장은 고정되지 않기 때문에 값은 조금씩 달라질 수 있습니다.
| result |
|---|
| 안녕하세요! 👋 무엇을 도와드릴까요? 😊 |
리뷰 데이터로 Gemini 사용해보기
BigQuery에 저장되어 있는 많은 데이터를 사용하는 예시로 제품명 (product)과 리뷰 (review)라는 컬럼으로 구성된 product_review 테이블의 데이터를 사용하여 Gemini에게 다양한 작업을 시켜보겠습니다.
| product (STRING) | review (STRING) |
|---|---|
| 닭가슴살 도시락 | 전자레인지에 편하게 데워 먹을 수 있어서 너무 편해요! |
| 닭가슴살 도시락 | 남편이 퍽퍽살 싫어하는데 이건 맛있다고 좋아했어요. |
| 닭가슴살 도시락 | 믿고 구매하는 제품이에요 재구매입니다 |
| 수분 크림 | 촉촉해요 만족스럽습니다 |
| 수분 크림 | 선물용으로 샀어요 |
| … | … |
리뷰를 요약하기
BigQuery의 데이터를 사용하여 요청을 보내려면 프롬프트를 선언하는 서브 쿼리에 Gemini에게 시킬 요청과 BigQuery 테이블의 데이터를 문자열로 합쳐서 프롬프트를 만들어주면 됩니다.
SELECT
product, review,
ml_generate_text_llm_result AS result,
FROM
ML.GENERATE_TEXT(
MODEL `bqml_tutorial.gemini_pro`,
(
SELECT
CONCAT("이 리뷰를 한 단어로 요약해줘: ", review) AS prompt,
FROM
`sample_project.sample_data.product_review`
),
STRUCT(
TRUE AS flatten_json_output
)
)위 쿼리를 실행하면 아래와 같이 한 단어로 요약된 결과를 확인할 수 있습니다. 다만 LLM 출력값 형식에는 예측 불가한 변동성이 있다 보니 종종 한 단어로 끝나지 않고 설명을 붙이는 경우도 있는데 이런 경우 프롬프트에 설명을 달지 말라고 요청을 포함하면 도움이 됩니다.
| product (STRING) | review (STRING) | result |
|---|---|---|
| A 닭가슴살 도시락 | 전자레인지에 편하게 데워 먹을 수 있어서 너무 편해요! | 편리함 |
| A 닭가슴살 도시락 | 남편이 퍽퍽살 싫어하는데 이건 맛있다고 좋아했어요. | 맛있다 |
| A 닭가슴살 도시락 | 저렴한데 믿고 구매하는 제품이에요 재구매입니다 | 재구매 |
| B 수분 크림 | 촉촉해요 만족스럽습니다 | 촉촉하다 |
| B 수분 크림 | 선물용으로 샀어요 빨리와서 좋네요 | 선물 |
| B 수분 크림 | 이 제품은 제가 즐겨쓰는 크림인데요 오랫동안 수분이 유지되어서 건조한 겨울에도 피부를 촉촉하게 유지할 수 있어요. 피부가 건성인 분들은 여름에도 좋을것 같아요. | 촉촉하게 |
| … | … | … |
이 쿼리에서 프롬프트를 조금만 수정하면 다양한 작업을 시킬 수 있습니다. 각 리뷰의 키워드를 찾거나 감성 분석을 수행할 수 있습니다.
제품별로 리뷰를 바탕으로 홍보 문구 작성하기
홍보 문구를 작성하는 것도 Gemini를 사용하면 손쉽게 수행할 수 있습니다. 이를 위해, 간단하게 각 제품에 대한 리뷰를 하나의 문자열로 결합하고, Gemini에게 이를 바탕으로 홍보 문구를 작성하도록 요청합니다.
SELECT
product,
ml_generate_text_llm_result AS result,
FROM
ML.GENERATE_TEXT(
MODEL `bqml_tutorial.gemini_pro`,
(
SELECT
product,
CONCAT(STRING_AGG(review, ','), "\n 이 리뷰들을 바탕으로 제품의 홍보 문구를 작성해줘.") AS prompt,
FROM
`sample_project.sample_data.product_review`
GROUP BY 1
),
STRUCT(
TRUE AS flatten_json_output
)
)아래는 쿼리를 실행한 후의 예시 결과입니다. 각 제품에 대해 Gemini 모델이 생성한 홍보 문구를 확인할 수 있습니다.
| product (STRING) | result |
|---|---|
| A 닭가슴살 도시락 | ## 맛있고 저렴한 가격에 구매할 수 있는 좋은 제품! 이 제품은 맛있고 저렴한 가격에 구매할 수 있어서 많은 사람들에게 사랑받고 있습니다. - 맛있음: 너무 부드러워서 퍽퍽살을 싫어하는 사람도 맛있게 먹습니다. - 편리한 조리: 전자레인지에 편하게 데워 먹을 수 있어서 편리합니다. - 만족도 높음: 많은 사람들이 만족하는 제품입니다. 지금 바로 구매해서 맛있고 저렴한 제품을 경험해 보세요! |
| B 수분 크림 | ## B 수분 크림 제품: 촉촉함의 정석 B 수분 크림 제품은 촉촉함을 추구하는 모든 이들에게 완벽한 선택입니다. 리뷰어들은 B 수분 크림 제품을 사용한 후 피부가 촉촉하고 수분이 잘 유지된다고 극찬했습니다. |
| … | … |
다양한 활용 방법
그 밖에도 Gemini를 사용하여 별도로 모델을 구축할 필요 없이 키워드 추출, 카테고리 분류, 감성 분석 등 활용이 가능합니다. 더 나아가 빅쿼리 내에서 예약쿼리 혹은 프로시저를 활용하면 수작업을 간단하게 자동화할 수도 있습니다.
리뷰의 주요 키워드 찾기
CONCAT(review, "\n 이 리뷰에서 드러나는 리뷰의 주요 키워드를 추출해서 키워드만 ,로 구분하여 나열해 줘") AS prompt,
| product | review | result |
|---|---|---|
| A 닭가슴살 도시락 | 저렴한데 믿고 구매하는 제품이에요 재구매입니다 | 저렴,믿음,재구매 |
| B 수분 크림 | 이 제품은 제가 즐겨쓰는 크림인데요 오랫동안 수분이 유지되어서 건조한 겨울에도 피부를 촉촉하게 유지할 수 있어요. 피부가 건성인 분들은 여름에도 좋을것 같아요. | 수분,건조,건성 |
리뷰의 주요 카테고리 분류하기
CONCAT(review, "\n 이 리뷰에서 드러나는 리뷰의 주요 키워드를 다음 목록에서 하나만 골라서 출력해줘 [배송, 포장, 가격, 품질, 신선도]") AS prompt,
| product | review | result |
|---|---|---|
| A 닭가슴살 도시락 | 전자레인지에 편하게 데워 먹을 수 있어서 너무 편해요! | 품질 |
| B 수분 크림 | 선물용으로 샀어요 빨리와서 좋네요 | 배송 |
리뷰에서 드러나는 고객의 감정을 분석하기
CONCAT(review, "\n 이 리뷰에서 드러나는 제품에 대한 고객의 감정을 0 ~ 10 사이 정수로 숫자만 출력해 줘. 0에 가까울수록 부정, 10에 가까울수록 긍정으로 표시해줘.") AS prompt,
| product | review | result |
|---|---|---|
| A 닭가슴살 도시락 | 남편이 퍽퍽살 싫어하는데 이건 맛있다고 좋아했어요. | 10 |
| B 수분 크림 | 너무 맘에 드는데 가격이 세일 안하면 부담스러울거 같아요 | 6 |
직접 사용하며 얻은 팁
응답 형식을 JSON으로 지정하여 결과에 대한 정합성 높이기
때때로 LLM을 사용하다 보면 사용자 요청에 명시되지 않았거나 제공된 정보와 일치하지 않는 내용을 생성하는 일종의 할루시네이션 (hallucination) 을 경험하곤 합니다. 위의 예시에서는 잘 생성된 예시만을 보여 드렸지만 실제로는 아래와 같이 다양한 이유로 결과 값을 사용하기가 쉽지 않았습니다.
예를 들어 위의 다양한 활용 방법 중 리뷰에서 드러나는 고객의 감정을 분석하기에서 할루시네이션이 발생한다면 아래와 같이 발생할 수 있습니다.
| product | review | result | 사용하기 힘든 이유 |
|---|---|---|---|
| A 닭가슴살 도시락 | 남편이 퍽퍽살 싫어하는데 이건 맛있다고 좋아했어요. | 긍정적인 리뷰입니다. | 숫자 값을 요구하였지만 문자열로 답변을 생성 |
| B 수분 크림 | 너무 맘에 드는데 가격이 세일 안하면 부담스러울거 같아요 | -5 | 제시한 값의 범위를 벗어남 |
| B 수분 크림 | 선물용으로 샀어요 빨리와서 좋네요 | 이 리뷰에서 드러나는 제품에 대한 고객의 감정은 10입니다. 이 제품을 구매한 고객은 선물용으로 구매를 하였으며 배송이 빠른 점을 좋게 보고 있습니다. 그리고 … | 요청하지 않은 추가 설명이 붙음 |
이런 경우에 생성된 결과 값에 정합성 검사를 하여 신뢰성을 확보할 수 있습니다. 그리고 이럴 때 응답 형식을 지정해 주는 것이 효과적이었습니다. 가장 많이 활용하고 있는 방식은 JSON 형식으로 응답 값을 요청하는 것입니다. JSON 형식으로 응답을 요청하면 BigQuery에서 JSON을 다루는 쿼리를 통해 정합성 검사를 쉽게 할 수 있고, 한 번에 생성하는 결과 값이 여러 개일 때 요청을 나누어서 처리하지 않아도 되는 장점이 있습니다.
CONCAT(review, "\n 이 리뷰에서 말하는 이야기의 분류에 일치하는 카테고리에 대해 분류해서 주어진 json 형식에 맞게 출력해줘. 배송과 관련되어 있으면 delivery, 맛이나 신선도와 관련되어 있으면 quality, 가격과 관련되어 있으면 price 필드에 값을 True로 표시해줘. 네가 출력해야 하는 응답 형식은 다음과 같고 json 외에 아무것도 출력하지마. {'delivery': False, 'quality': False, 'price': False}") AS prompt,
위와 같은 프롬프트로 요청을 보낸다면 아래와 같이 사용하기 편하게 생성된 값을 얻을 수 있습니다. 정규표현식과 JSON 쿼리로 정합성 검사를 하고 원하는 결과가 아니라면 다시 생성하도록 로직을 구성하여 신뢰성을 확보하고 각 JSON의 필드들을 각각 칼럼으로 나누어 저장할 수 있습니다.
| product | review | result |
|---|---|---|
| A 닭가슴살 도시락 | 남편이 퍽퍽살 싫어하는데 이건 맛있다고 좋아했어요. | {‘delivery’: False, ‘quality’: True, ‘price’: False} |
| A 닭가슴살 도시락 | 저렴한데 믿고 구매하는 제품이에요 재구매입니다 | {‘delivery’: False, ‘quality’: True, ‘price’: True} |
대량의 데이터를 처리하는 방법
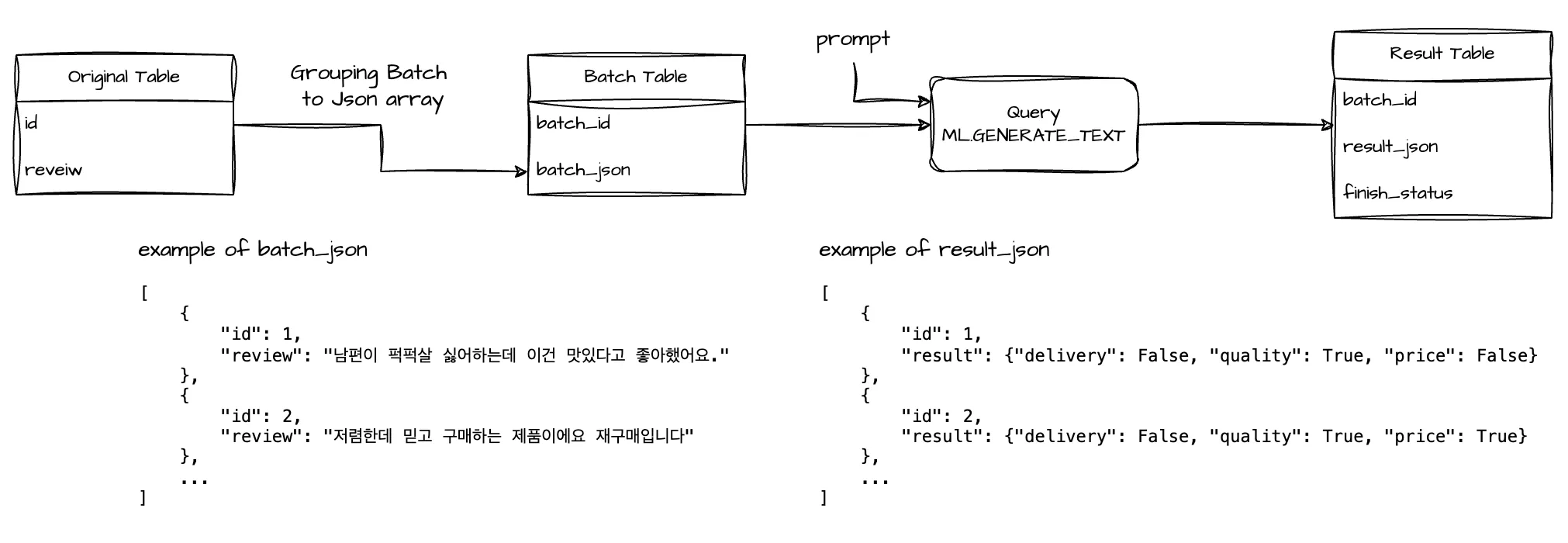
Gemini에 처리를 요청할 데이터가 수만 건이 넘어간다면 요청하게 되는 프롬프트의 수가 많아져서 처리 시간이 자연스레 증가할 수밖에 없고 요청 제한에 걸릴 수 있습니다. 이런 상황에서 동시에 더 많은 데이터를 처리하는 방법으로 하나의 프롬프트에 여러 데이터를 묶어서 처리하는 배치 기법을 사용할 수 있습니다.
 © 2024. Kurly. All rights reserved.
© 2024. Kurly. All rights reserved.
위 사진은 응답 형식을 JSON으로 지정하여 결과에 대한 정합성 높이기의 예시에서 배치 기법을 적용한 플로우입니다. 원본 테이블에서 데이터를 묶어서 만드는 중간 테이블과 Gemini에서 생성한 결과 테이블도 살펴본다면 아래와 같습니다.
배치 테이블
| batch_id | batch_json |
|---|---|
| 1 | [{“id”: 1,“review”: “남편이 퍽퍽살 싫어하는데 이건 맛있다고 좋아했어요.”}, {“id”: 2,“review”: “저렴한데 믿고 구매하는 제품이에요 재구매입니다”}, … ] |
| 2 | [{“id”: 101,“review”: “전자레인지에 편하게 데워 먹을 수 있어서 너무 편해요!”}, {“id”: 102,“review”: “맛있네요! 역시 컬리라 배송도 빨랐어요!”}, … ] |
결과 테이블
| batch_id | result_json |
|---|---|
| 1 | [{“id”: 1,“result”: ”{‘delivery’: False, ‘quality’: True, ‘price’: False}”}, {“id”: 2,“result”:“{delivery’: False, ‘quality’: True, ‘price’: True}”}, … ] |
| 2 | [{“id”: 101,“result”: ”{‘delivery’: False, ‘quality’: True, ‘price’: False}”}, {“id”: 102,“result”:“{delivery’: True, ‘quality’: True, ‘price’: False}”}, … ] |
이렇게 리뷰를 100개씩 묶어서 JSON으로 만들고 배치 테이블을 만든 다음 이 테이블의 데이터를 Gemini가 처리하게 한다면 더 많은 데이터의 동시 처리가 가능합니다. 이런 데이터의 묶음을 만드는 전처리와 묶음을 풀어주는 후처리가 필요하기 때문에 처리 시간은 데이터의 수가 증가할 수록 효율적입니다.
RAI(Responsible AI) 기능으로 응답 결과 해석하기
만약 ML.GENERATE_TEXT 함수의 실행 결과에 대해 더 자세한 내용을 확인하고 싶다면 ml_generate_text_rai_result 값을 통해 확인이 가능합니다. 여기서는 책임감 있는 AI를 위해 요청한 프롬프트에서 안전 속성에 위배되는 항목을 확인할 수 있습니다.
책임감 있는 AI와 안전 속성에 대해 자세히 알고 싶으시다면 아래 글을 읽어보시면 좋습니다.
더 자세한 실행 결과를 확인하기 위해서는 STRUCT에 정의한 파라미터 중 flatten_json_output 값을 False로 바꿔서 확인이 가능합니다. 이 상태에서는 결과값이 ml_generate_text_result 라는 컬럼으로 생성되며 생성된 문장과 더불어 종료 상태, 안전 속성 상태, 토큰 수를 json 형태로 확인할 수 있습니다.
그 중 종료 상태를 나타내는 finish_status 값을 확인하면 어떻게 Gemini의 실행이 종료되었는지 확인이 가능합니다.
자주 볼 수 있는 finish_status
- 1 : 생성 완료로 종료
- 2 : max_output_token에 도달하여 종료
- 3 : 안전 속성에 의한 종료
마치며
Gemini를 사용하면서 직접 딥러닝 모델을 구축한 경험이 없는 저희도 원하는 분석 결과를 도출할 수 있음을 확인한 좋은 경험이었습니다. 프롬프트를 수정하면서 다양한 결과를 얻을 수 있고, 결과를 개선해나가는 과정이 LLM 모델을 단순히 적용하는 시도보다는 그 이상의 협업 과정이라고 느꼈습니다.
이번 글에서는 소개하지 못했지만, Gemini가 많은 양의 텍스트 데이터도 빠르고 효율적으로 처리할 수 있어, 저희가 수행한 Gemini 리뷰 데이터 분석 결과부터 시작하여 실제 서비스에 적용해나가고 있습니다. 리뷰 뿐만 아니라 컬리의 다양한 데이터를 활용해 업무에서 활용성을 늘려나가고 더 많은 인사이트를 제공하는 데에도 큰 도움이 될 것이라고 기대합니다. 읽어주셔서 감사합니다.