BULK 처리 개선해보기
안녕하세요, 컬리 파트너서비스개발팀에서 백엔드 개발을 하고 있는 유형환입니다.
업무 중에 경험했던 BULK 처리 개선에 관해 공유해 보려 합니다.
BULK처리는 일반적으로 Spring Batch와 많이 엮이지만 API, Consumer 등 여러 애플리케이션에서도 문제는 동일하기 때문에
애플리케이션과 <-> DB와의 관계에 집중해서 글을 작성했습니다!
아래 레파지토리에 실제로 테스트한 예제 코드도 있으니 참고해 주세요!
예제 링크 👉👉 https://github.com/thefarmersfront/bulk-performance-tuning/
| ✅ |
성능 테스트에 태훈님의 TestContainers로 유저시나리오와 비슷한 통합테스트 만들어 보기 글을 참고해서 테스트 환경을 구축했는데 덕분에 테스트 코드만으로도 순조로운 성능 테스트가 가능했습니다. 👍👍 TestContainers 알아보기 👇 https://helloworld.kurly.com/blog/delivery-testContainer-apply/ |
BULK 처리.. 어느 곳에나 있지만… 😂
어느 도메인에나, 어느 시스템에나 있지만…
백엔드 개발자들이 항상 부담스러워하는…😂 기능이 몇 가지 있는데
그중 하나는 BULK 처리 (일괄 처리, 엑셀 처리, 통계 데이터 생성 등)일 것입니다.
일반적으로 BULK 처리가 부담스러운 이유는 많은 데이터를 처리하기 위해 급격히 시스템 리소스 사용량이 증가하기 때문입니다.
장애는.. 지속적으로 100이라는 자원을 사용할때보다는..
계속 10 자원을 사용하다가 → 1분 동안 급격하게 50을 사용하는 경우에 자주 발생하더라고요..
이런 BULK 처리를 개선할 수 있는 방법은 여러 가지가 있고 상황에 맞는 방법을 선택하면 됩니다.
- 실시간성이 중요하지 않다면 → 모아두었다가 이용률이 적은 시간에 처리
- 애플리케이션 자체의 성능 튜닝
- 아키텍처 개선
- 등등…
성능 튜닝 한다면?
보통 성능 튜닝을 진행한다고 하면 우선 크게 3가지 포인트로 추상화해서 바라볼 수 있습니다.
- Read (읽기)
- Process (처리, 가공)
- Write (쓰기)
튜닝을 진행하기 전 위 3가지 중 어느 부분이 원인이 되는지 판단하고 → 어느 부분을 튜닝할지 정하는 것이 첫 번째 단계라고 할 수 있습니다.
👉이번 글에서는 BULK 처리 성능개선 중 Write에 집중해서 몇 가지 개선 경험들을 서술하려 합니다.👈
| 📌 |
근데.. 저 3가지.. Read,Process, Write 뭔가 익숙한 구조인데요…? 🤔 네, Spring Batch에서 많이 언급되는 구조입니다. Spring Batch에서는 위 3가지에 항목에 대한 편의성을 제공하는 여러 가지 추상화된 기능들을 제공합니다. 그렇기 때문에 Spring Batch에서 위 용어들을 많이 언급할 뿐… 생각해 보면 우리의 애플리케이션 API, BATCH, CONSUMER 등은 모두 일반적으로 위 3가지 흐름대로 동작하고 있고 위 3가지를 잘하기 위해 여러 기술들을 선택하고 있습니다. |
Write 개선 1
JPA(ORM)에 대해 생각해보기
결론부터 서술하자면 사실 JPA는 BULK 처리에 적합한 도구는 아닙니다.
원론적인 이유를 생각해 보면 JPA는 ORM이고 → ORM은 대량 처리에 적합한 도구는 아니기 때문입니다.
JPA는 편의성을 위한 테크닉
ORM (Object–relational mapping)
Object–relational mapping (ORM, O/RM, and O/R mapping tool) in computer science is a programming technique for converting data between a relational database and the heap of an object-oriented programming language.
출처: Wikipedia
Wikipedia의 ORM 설명도 RDB ↔ 객체지향 언어 간의 변환 테크닉이라고 설명하고 있습니다.
이외에 ORM의 많은 장점들을 나열하고 있지만 대용량 데이터 처리나 성능에 관해서는 언급하고 있지 않습니다.
그런데도 ORM이 많은 개발자들이 사용하는 도구가 된 이유는 그만큼 개발 편의성에는 많은 도움이 되기 때문입니다.
Database I/O
10만건의 row를 insert해야 하는 상황이라면
기본적으로 Database와 애플리케이션 간에 발생하는 I/O를 줄이는 방향으로 쿼리를 실행해야 합니다.
- (X) 10만개의 insert 쿼리보다는
- (O) BULK 형태 N번의 insert 쿼리가 성능상 많은 이점을 가질 수 있습니다.
JPA의 saveAll()…?
JPA의 saveAll()은 메소드명만 보면 BULK 형태로 동작할것 같이 생겼습니다. 😌 아래 처럼요.
INSERT INTO … VALUES (…), (…), (…), ...하지만 실행해보면.. 결과적으로는 건건이 write 쿼리가 발생하는 기능입니다.
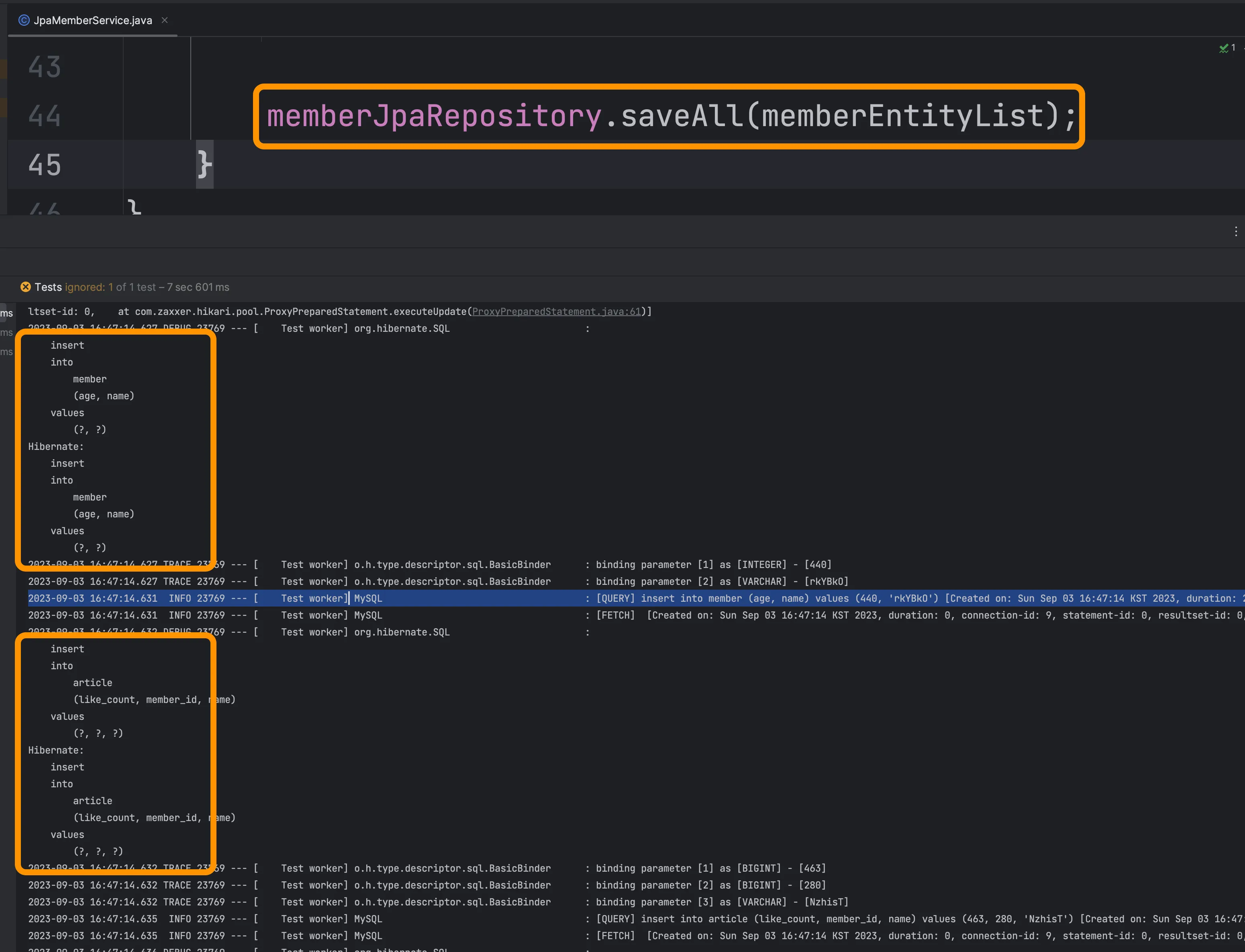
saveAll() 쿼리 로그
간단하게 이유를 살펴보면
- INSERT 완료 후 Entity 객체에 ID가 맵핑되어야 하지만
- BULK 형태의 INSERT 쿼리는 모든 Entity의 ID를 알 수 없습니다.
- INSERT된 Entity의 ID를 알기 위해서는 row별로 INSERT쿼리가 실행될 수밖에 없습니다.
(기본키 전략(
@GeneratedValue)에 따라 구체적인 이유는 상이하지만BULK INSERT가 실행될 수 없다는 점은 모두 동일합니다.)
JPA말고 다른 도구 → JDBC의 batchUpdate
이런 상황에서 BULK 처리의 성능을 높이기 위해서 JDBC의 batchUpdate를 이용해 INSERT INTO … VALUES (…), (…), (…), ... 형태의 쿼리가 실행되도록 개선할 수 있습니다.
public void createMember(List<CreateMemberCommand> commands) {
var sql = "INSERT INTO member(name, age) VALUES (?, ?)";
jdbcTemplate.batchUpdate(
sql,
new BatchPreparedStatementSetter() {
@Override
public void setValues(
PreparedStatement ps,
int i
) throws SQLException {
CreateMemberCommand command = commands.get(i);
ps.setString(1, command.getName());
ps.setString(2, command.getAge());
}
@Override
public int getBatchSize() {
return commands.size();
}
}
);
}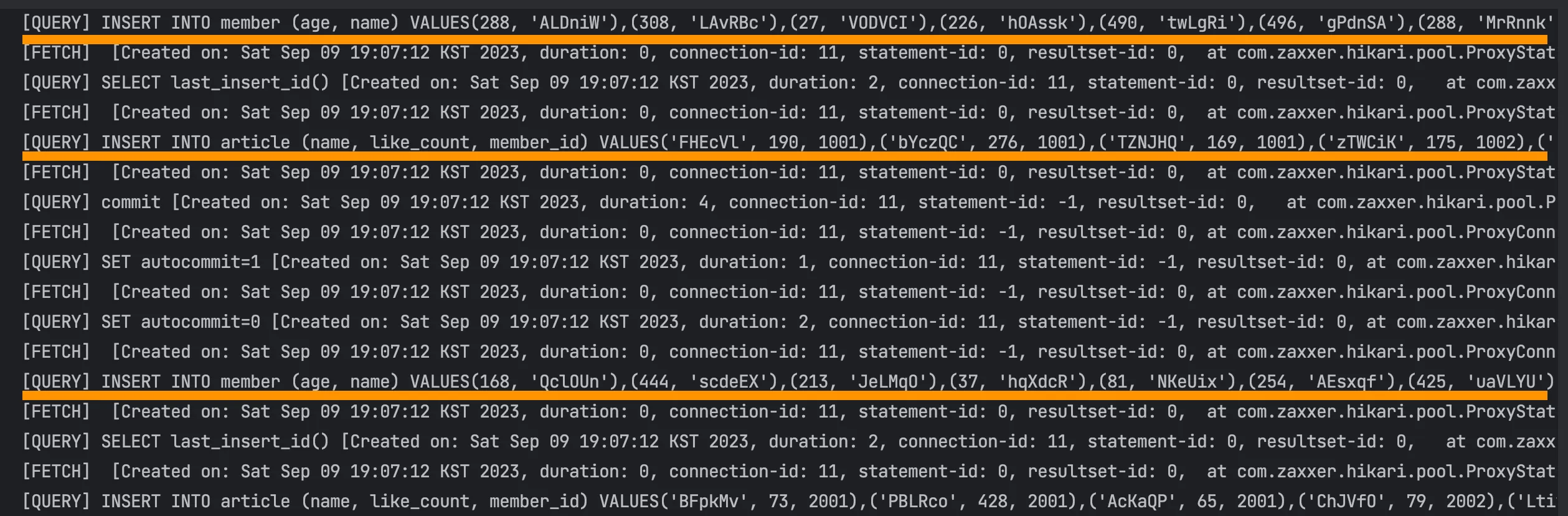
batchUpdate() 로 실행된 쿼리 로그
Write 개선 2
JDBC의 batchUpdate도 사용하기 까다로운 상황
하지만 다음과 같은 경우에는 BULK로 insert쿼리를 작성할 수 없는 상황이 발생하게 됩니다.
- 외부에서 인입되는 member(회원), article(게시글) 1:N 정보를 → member, article 1:N 테이블에 마이그레이션 insert
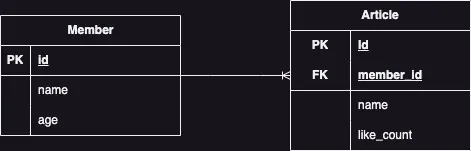
member, article ERD
- 외부에서 인입되는 데이터 예시
[ { name: 'member_name1', // 회원 정보 age: 10, article: [ // 회원의 게시글 목록 { name: 'member1_article_1', like_count: 1, }, { name: 'member1_article_2', like_count: 155, }, ], }, { name: 'member_name2', age: 23, article: [ { name: 'member2_article_1', like_count: 32, }, { name: 'member2_article_2', like_count: 53, }, ], }, // ... 100만 member ];
insert된 row들의 PK를 알 수 없기 때문에 외래키 또한 설정할 수 없습니다.
위처럼 연관관계가 필요한 구조에서는 단순 jdbcTemplate의 batchUpdate만으로는 성능에 대한 이점을 가질 수 없게 됩니다.
정확하게는 jdbc의 batchupdate라서 불가능한 것이 아니라 bulk insert구조에서 불가능합니다.
> insert into member (name, age) values
('member_name_1', 10), -- PK: 57
('member_name_2', 23), -- PK: 58
...
('member_name_10', 27); -- PK: 66 (insert 10 row)
> select last_insert_id(); -- result: 57 (첫번째 row의 PK)위처럼 bulk insert 완료 후에 last_insert_id()를 이용해도 insert된 첫 번째 row의 PK만 알 수 있습니다.
결국 insert된 모든 row들의 PK를 알 수 없기 때문에 연관 스키마에도 Foriegn Key를 설정할 수 없게 되고 → 결국 아래 예시와 같이 1 row별로 insert할 수밖에 없게 됩니다.
-- 첫번째 memeber
> insert into member (name, age) values ("member_name_1", 10); -- PK: 57
> select last_insert_id(); -- result: 57
> insert into artice (member_id, name, like_count) values
(57, "member1_article_1", 1), (57, "member1_article_2", 155);
-- Foriegn Key를 57로 설정하여 insert
-- 두번째 memeber
> insert into member (name, age) values ("member_name_2", 23); -- PK: 58
> select last_insert_id(); -- result: 58
> insert into artice (member_id, name, like_count) values
(58, "member2_article_1", 32), (58, "member2_article_2", 53);
-- Foriegn Key를 58로 설정하여 insert
-- 세번째 memeber
> insert into member (name, age) values ("member_name_3", 490); -- PK: 59
> select last_insert_id(); -- result: 59
> insert into artice (member_id, name, like_count) values
(59, "member3_article_1", 312), (59, "member3_article_2", 93);
-- Foriegn Key를 59로 설정하여 insert
.....
-- member수만큼 insert쿼리 별도 실행위와 같은 구조는 성능 하락의 원인이 될 뿐 아니라 DB 부하의 원인이 되기도 합니다.
애플리케이션의 간단한 연산을 이용하면 insert된 모든 row의 PK를 알 수 있습니다.
INSERT INTO member(name, age) VALUES ("name1", 10), ("name2", 20), ("name3", 30);위 형태의 bulk insert는 PK가 Auto Increment인 테이블에서 3개의 row가 1씩 증가하는 순차적인 PK를 가진다는 것을 보장할 수 있습니다.
- 그렇다면 따로 row별로 조회하지 않아도
last_insert_id()로 가져온 첫번째 row의 PK가 57이라면- name2는 58, name3은 59라는것까지 알 수 있습니다.

PK는 1씩 증가
위 내용을 기반으로 각 data들의 PK는 다음과 같은 방식으로 구할 수 있게 됩니다.
// 1. memberList bulk insert 로직 완료
jdbcTemplate.batchUpdate(.....);
// 2. lastInsertId 조회
Long firstPK = jdbcTemplate.queryForObject("SELECT last_insert_id()", Long.class);
// 3. lastInsertId기반으로 PK 연산
for(i = 0; i <= memberList.size(); i++) {
MemberDto insertedMember = memberList.get(0);
insertedMember.setId(lastInsertId + i); // PK 설정
}
// 4. PK가 설정된 memberList를 풀어서 `article`에 대한 bulk insert 리스트 생성
List<ArticleDto> articleList = memberList.stream()
.flatMap(....) // FK가 설정된 articleList
.collect(Collectors.toList());
// 5. `article` bulk insert 로직 실행
jdbcTemplate.batchUpdate(.....);
연산으로 PK 추론이 가능하다.
위와 같은 구조를 이용하면 bulk insert 쿼리 2번의 실행만으로 외래키가 포함된 데이터를 insert할 수 있게 됩니다.
테스트 결과
결과적으로 member 10000건 + member별 article 1~5개 (article 약 30000건)의 실행 결과는 아래와 같습니다.
정리
- 장점
- 대용량 데이터 insert 처리 속도가 대폭 개선됩니다.
- DB 부하도 대폭 개선됩니다.
- 단점
- DB의 외래키가 복잡하게 설정되어 있을수록 application의 로직이 복잡해집니다.
- JPA의 영속성과는 다르기 때문에 함께 사용할 경우 JPA 영속성에 대해 더욱 주의해야 합니다.
JPA와 JDBC는 명확하게 장단점이 나뉩니다.
JPA는 DB를 Java 객체로 추상화해서 바라볼 수 있다는 장점이 있지만 객체로 추상화하는 과정으로 인해 성능상의 trade off가 발생하게 됩니다.
JDBC는 좋은 성능의 쿼리 사용이 가능하지만 그만큼 복잡도가 높아져 테스트 코드에서도 문제가 된다는 trade off가 있습니다.
그렇다면 결국 JPA, JDBC 혼용하는 상황이 많이 발생하는데 JPA의 영속성과 JDBC는 다르기 때문에 함께 사용할 경우 JPA 영속성에 대해 더욱 주의해야 합니다.
두 기술 중 정답은 없고, 상황에 맞게 잘 선택하는 것이 개발자의 덕목이 아닐까 싶습니다. 😄😄