소개
안녕하세요. 컬리 데이터서비스개발팀에서 일하고 있는 머신러닝 엔지니어 구국원, 데이터 사이언티스트 박수형입니다. 저희 팀은 컬리의 다양한 영역에 머신러닝을 도입하여 여러 지표들을 개선하기 위한 시도를 지속하고 있습니다. 그중에서 추천은 컬리에서의 상품 탐색 및 구매 의사 결정을 보조해 주는 중요한 기술이기 때문에 추천 모델을 개발하고 개선하는 것은 팀에서 담당하는 중요한 도메인 중 하나라고 할 수 있습니다.
이번에 컬리 앱에 장바구니 페이지와 결제 페이지 사이에 장바구니 바텀시트(이하 바텀시트)라는 새로운 UI를 도입하였습니다. 바텀시트는 결제 페이지로 넘어가기 전 함께 구매할 만한 상품을 제안하여 고객 여정의 가장 마지막 단계에서 상품 탐색과 구매 경험을 향상해 드리고자 하는 목적을 가지고 있습니다.
© 2024.Kurly.All right reserved
따라서 저희는 이 영역에 노출할 적합한 추천 시스템을 고민하게 되었고, 결과적으로 함께 구매할 만한 보완재 상품을 추천하는 모델을 개발하고 서비스에 적용했습니다. 이 과정에서 다양한 고민들이 있었고, 최종적으로 A/B 테스트를 통해 실제 유저를 대상으로 성과를 측정한 후에 성공적으로 모델을 서빙하였습니다. 본 글에서는 고민했던 내용과 실험 결과를 공유드리고자 합니다. 참고로 후속편에서는 이 모델을 서빙하기 위한 아키텍처를 공유드릴 예정입니다.
모델 개발 과정
장바구니에 적합한 추천 모델의 컨셉을 잡자
바텀시트에 추천 모델을 서빙하기 위한 프로젝트를 시작하는 단계에서 가장 고민이었던 부분은 어떤 컨셉의 추천을 제공할까였습니다. 다시 말해 추천 모델이 제안하는 상품들은 어떤 특징을 보여야 지표를 유의미하게 향상시킬 수 있을까에 대한 고민이었습니다. 유저가 이커머스 사이트에서 상품을 구매하는 의사 결정은 크게 2가지 단계로 구분할 수 있습니다.
- Stage 1: 많은 상품셋에서 흥미 있을만한 상품을 탐색하는 과정
- Stage 2: 후보 상품을 추리고 구매 결정을 위한 단계
바텀시트는 장바구니 페이지와 결제 페이지 사이에 존재하는 영역이므로 바텀시트에 노출되는 유저는 Stage2에 가깝다고 판단했습니다. 그리고 이와 관련된 레퍼런스를 찾던 중 행동 경제학 논문에서 Stage2에 있는 유저들에게는 대체재 보다 보완재를 추천하는 것이 WTP(Willingness To Pay, 지불 용의)가 상대적으로 더 높다는 연구 결과를 발견했습니다. 또한 여러 이커머스 사이트를 조사해 본 결과, 고객 여정의 마지막 단계에서 제안되는 추천은 대체로 보완재 성격의 상품을 추천하는 것을 확인하였습니다. 따라서 바텀시트에는 현재 장바구니에 담긴 상품의 보완재 성격의 상품을 제안하는 것이 성과 향상에 유의할 것이라는 가설을 세웠습니다.
모델 선택
추천 모델은 다음의 요구 조건을 만족할 수 있어야 했습니다.
- 장바구니 담긴 상품들을 모두 고려하여 상품을 추천해야 함
- 실시간 추천이 가능해야 함
- 향후 추가 피쳐를 손쉽게 반영할 수 있어야 함
먼저, 장바구니에 담긴 모든 상품을 빠짐없이 고려해야 한다는 점에서 Transformer에 기반한 추천 영역에서 검증된 모델을 리서치 해보았습니다. 그중에서 sequential recommendation 도메인에서 성능이 검증된 BERT4Rec이라는 모델을 살펴보았고, 간단한 PoC 끝에 위 요구 조건을 모두 만족할 수 있겠다고 판단하여 BERT4Rec을 보완재 추천을 위한 모델로 선정하였습니다.
© 2024.Kurly.All right reserved
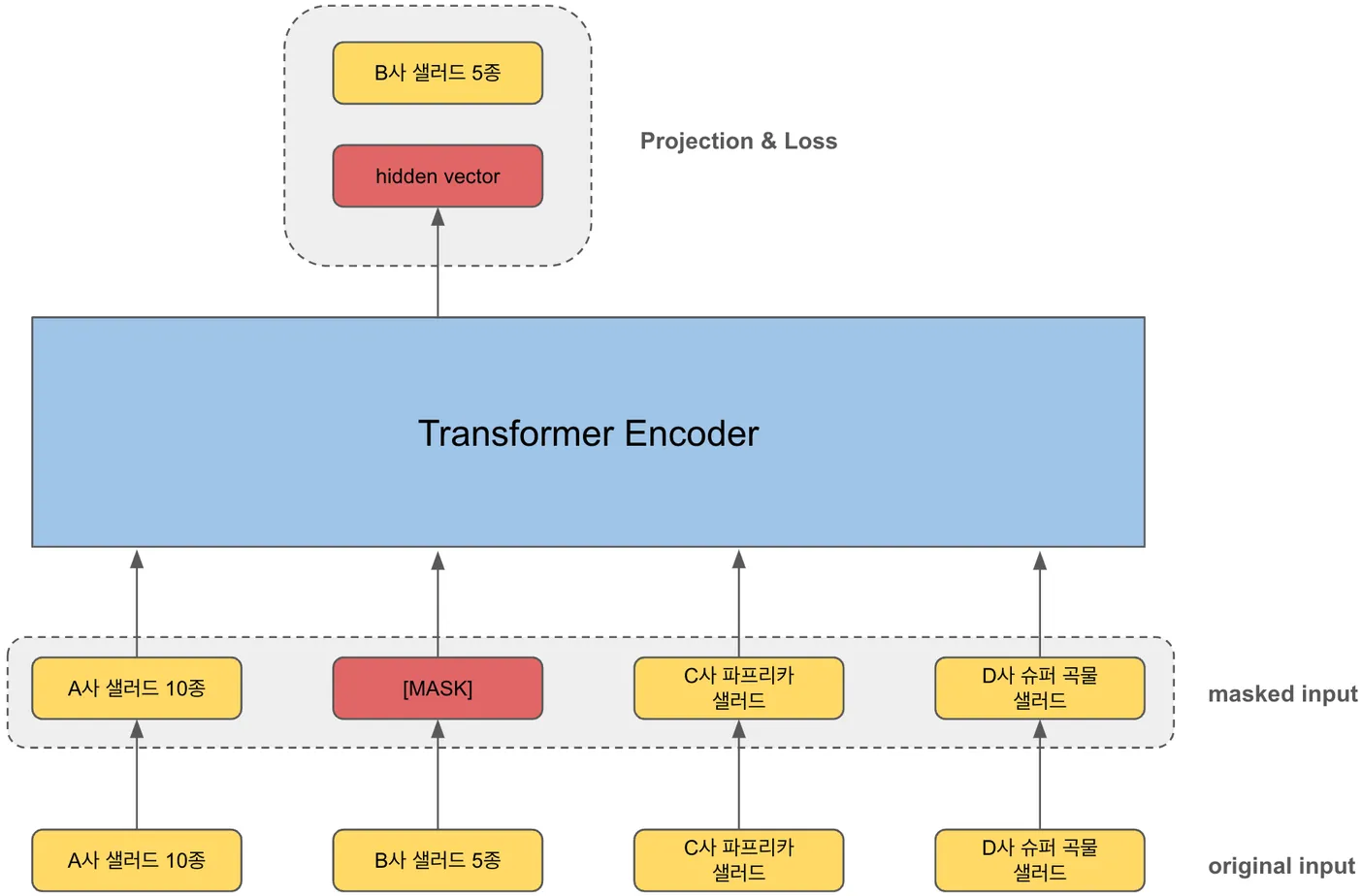
BERT4Rec은 Transformer의 인코더 부분을 차용하여 Cloze Test를 통해 모델을 학습시킵니다. Cloze Test란 BERT의 학습 기법 중 MLM(Masked Language Modeling)을 의미하는데, 쉽게 말하면 주어진 인풋값에 랜덤하게 빈칸을 만들고 주변 토큰들을 활용해 빈칸에 들어갈 정답을 맞히는 태스크를 말합니다.
컬리 상품으로 예시를 들어 보죠. original input은 샐러드 상품으로 이루어진 장바구니입니다. 이 값이 BERT4Rec 모델에 그대로 입력되기 전에 특정한 확률로 특정 토큰이 마스킹(masking) 됩니다. 이 후에 트랜스포머 인코더 블럭을 통과하게 되고, 마스킹된 토큰 자리의 히든 벡터와 마스킹 되기 전 입력값(=정답값)의 크로스 엔트로피 손실을 계산하고, 역전파를 통해 학습되는 원리입니다.
이러한 학습 원리에 비추어 생각해 보았을 때, 같이 구매할 만한 보완재 상품을 추천하는 것이 충분히 가능하다고 판단했습니다. 트랜스포머 레이어와 어텐션 헤드의 개수도 손쉽게 조정 가능하기 때문에 모델을 가볍게 만들면 실시간 추천이 가능할 것이라고 생각했습니다.
전처리
컬리에서 결제가 이루어지면 장바구니에 있던 상품들은 하나의 주문서라는 개념으로 묶이게 됩니다. 첫 학습에서는 하나의 주문서에 담기는 상품들은 서로 보완재라는 단순한 가정하에 이 데이터를 그대로 활용하여 BERT4Rec을 학습시켰습니다. 그러나 좋은 결과로 이어지지 못했습니다. 가장 문제가 되었던 부분은 추론 시에 어떤 상품을 입력하든 E사 우유 상품이 계속해서 추천되는 것이었습니다. 사실 이는 유저의 실제 구매 패턴을 모델이 ‘너무 정확히’ 반영해서 발생하는 문제입니다. 실제로 E사 우유는 컬리의 어느 상품과도 함께 자주 구매되는 패턴이 있기 때문입니다. 그러나 이는 직관적으로 보완재 추천이라는 느낌이 없었기 때문에, 구매 패턴에서 의미 있는 보완재 관계를 찾아서 이를 학습 시 반영할 필요가 있었습니다.
컬리에는 다양한 카테고리가 있고 서로 같이 자주 구매되는 카테고리가 있습니다. 저희는 이러한 데이터를 잘 정제하면 유의미한 보완재 관계를 찾을 수 있을 것이라고 생각했습니다. 예를 들어 우유는 채소와 같이 많이 구매되긴 하지만, 우유와 베이커리가 더 적절한 보완재 관계라고 생각됩니다. 즉, 단순히 자주 같이 구매되는 카테고리가 아닌 직관에 부합하는 보완재 카테고리를 발굴해야 합니다. 그러나 사람이 수작업으로 이러한 카테고리 간의 보완재 관계를 설정하는 것은 매우 어려운 일뿐더러 객관적으로 평가하기 어렵다는 단점이 있습니다. 따라서 카테고리 간의 보완재 관계성을 데이터에 기반하여 정량적으로 평가하는 시도를 했습니다.
이를 위해 정보이론에서 확률 변수 간의 상호 정보량을 측정하는 NPMI(Normalized Pointwise Mutual Information)를 카테고리쌍별로 계산해 보았습니다. NPMI란 PMI를 -1 부터 1 사이의 값으로 노말라이즈한 값입니다. NPMI는 아래와 같은 수식으로 계산할 수 있습니다.
위 수식을 살펴보면 결합 확률이 클수록, 주변 확률은 낮을수록 PMI 값이 증가하는 것을 알 수 있습니다. 다시 말해 서로 같이 구매되는 카테고리이면서도 서로 이외의 다른 카테고리와는 잘 구매되지 않을수록 NPMI가 크다는 것입니다. NPMI 스코어는 아래와 같이 해석할 수 있습니다.
- 1에 가까울수록 다음과 같은 속성이 있음
- 같이 많이 구매됨
- 서로 이외의 다른 상품들과는 많이 구매 안 됨
- -1에 가까울수록 다음과 같은 속성이 있음
- 같이 많이 구매 안 됨
- 서로 이외의 다른 상품들과 많이 구매됨
NPMI를 통해 서로 간의 의존성이 높은 유의미한 보완재 카테고리쌍을 발견할 수 있고, 특히 얼마나 유의미한지를 -1 부터 1 사이 값으로 평가할 수 있는 것이 장점입니다. 아래는 요거트/생크림 카테고리에 대해서 카고리쌍별로 NPMI 스코어를 계산하여 내림차순으로 정렬한 예시입니다. 직관에 반하지 않는 카테고리쌍을 잘 묶는 것을 확인할 수 있습니다.
| p1_catnm | p2_catnm |
|---|---|
| 요거트·생크림 | 선식·시리얼 |
| 요거트·생크림 | 냉동·건과일 |
| 요거트·생크림 | 우유·두유 |
| 요거트·생크림 | 간식·음식 |
| 요거트·생크림 | 꿀·과일청 |
| 요거트·생크림 | 수입과일 |
| 요거트·생크림 | 친환경 |
최종적으로는 보완재 카테고리쌍을 NPMI 스코어로 계산한 다음에 일부 필터링 적용하고, 한 건의 구매(주문서) 데이터를 보완재 카테고리쌍에 따라 부분 집합으로 분리하여 학습을 진행하였습니다. 그 결과, 이 전보다 훨씬 추천 결과가 개선된 것을 정성적으로 확인할 수 있었습니다.
학습 및 오프라인 지표
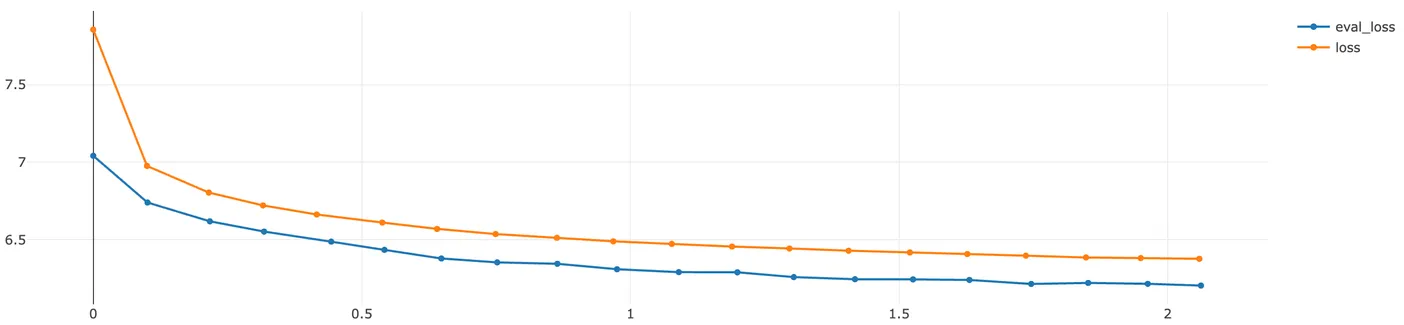
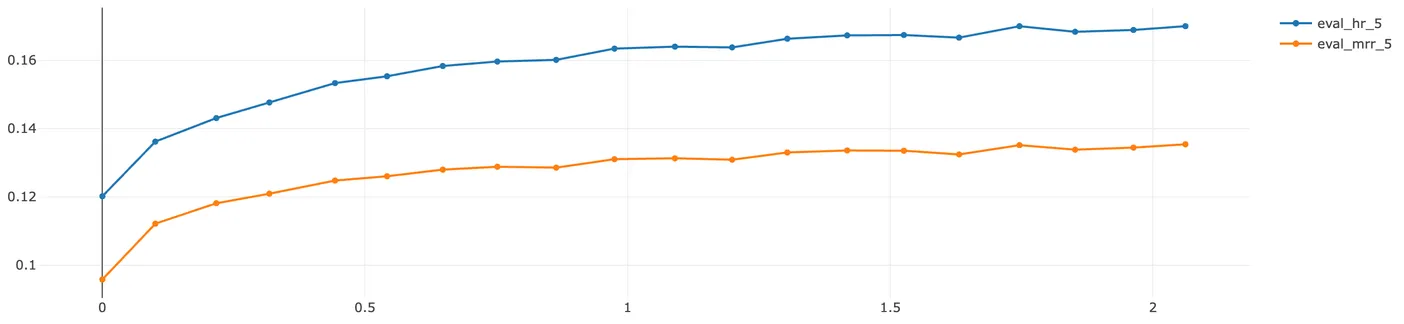
학습은 GPU를 활용하여 진행되었으며, 특정 스텝마다 오프라인 지표를 계산하여 모델의 성능을 모니터링했습니다. 맞추고자하는 정답값은 하나이므로 HR@5, MRR@5를 오프라인 지표로 선정하였습니다. 참고로 바텀시트에서 스크롤을 내리지 않으면 기본적으로 노출되는 상품의 개수는 4개이므로 5개 상품 이내에 정답 상품이 있는지를 판단하였습니다. 또한 저희 팀에서는 머신러닝 학습 시 생성된 파일(모델, 사전 등)과 오프라인 지표는 mlflow를 통해서 관리하고 있습니다.
© 2024.Kurly.All right reserved
© 2024.Kurly.All right reserved
학습은 huggingface에서 제공하는 모듈을 활용했습니다. huggingface의 Trainer는 학습 시 특정 스텝마다 오프라인 지표를 계산할 수 있도록 커스텀 함수를 지원하는데요. 이때 검증셋 대해 HR과 MRR 계산 시 GPU OOM 에러가 발생할 수 있습니다. 그 이유는 검증셋에서 메트릭 산출 시에 추론된 모든 텐서를 GPU에 누적 시켰다가 한번에 평가하기 때문입니다. 그러나 추천 오프라인 지표의 특성상 상위 K개의 결과에 대해서만 연산하면 되기 때문에 모든 추론 결과가 필요하지 않습니다. 따라서 아래와 같은 함수를 통해서 추론 결과를 전처리한 후 오프라인 지표를 계산하면 OOM 에러를 피할 수 있습니다.
def preprocess_logits_for_metrics(logits, labels):
k = 5
rows, cols = torch.where(labels != -100) # -100 means pad
logits = torch.argsort(logits[rows, cols, :], dim=1, descending=True)[:,:k]
labels = labels[rows, cols] # (len(rows),)
return logits, labels
def compute_metrics(eval_prediction):
k = 5
logits, labels = eval_prediction.predictions
hit_idx_mat = comput_hit_idx_mat(logits, labels, k=k)
hr = compute_hr(hit_idx_mat)
mrr = compute_mrr(hit_idx_mat)
return {f"hr_{k}": hr, f"mrr_{k}": mrr}정성 평가
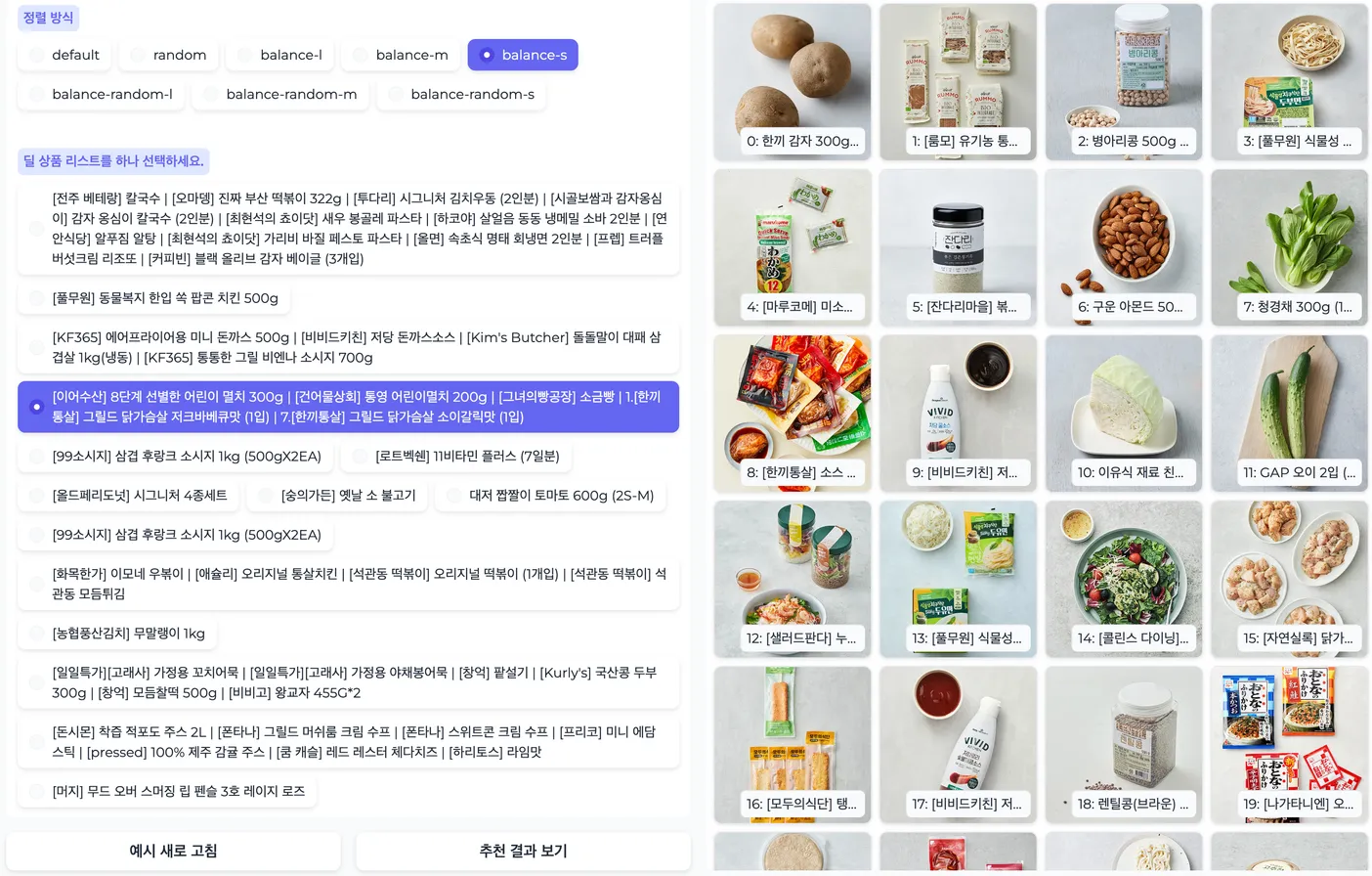
추천 서비스는 정량적 평가도 중요하지만 정성적 평가도 역시 중요합니다. 따라서 모델의 추천 결과를 쉽게 공유하여 지속적으로 피드백을 수렴할 수 있는 플랫폼이 필요했습니다. 따라서 파이썬의 gradio라는 패키지를 활용하여 추천 결과를 바로 확인해 볼 수 있는 데모 페이지를 제작하고 사내 인원을 대상으로 공유하였습니다. 실제로 기획자분들께서 데모 페이지를 활용해 보신 다음에 다양한 피드백을 주셨고, 이를 검토하여 후처리 로직을 개발 및 개선했습니다.
© 2024.Kurly.All right reserved
후처리
사내 테스트를 진행하면서 취합된 여러 의견 중, 대부분이 ‘특정 카테고리에 추천 상품이 편중된다’였습니다. 바텀시트에는 모델의 score 순으로 정렬된 결과의 상위 30개 상품을 노출하고 있었는데요. 편중된 사례의 전체 추론 결과를 확인했을 때, 상위 score에 특정 카테고리 상품이 몰려있고 하위 score로 내려갈수록 다양한 상품군이 존재하는 경우가 대다수였습니다. 따라서 추천되는 상품의 구성 자체에는 문제가 없다고 판단되어 저희는 후처리 로직으로 편중 현상을 해결해 보기로 했습니다.
추천 결과의 퀄리티와 API의 레이턴시를 동시에 고려할 필요가 있었기 때문에 여러 후처리 방법을 고민하던 중, 저희는 Spotify의 셔플링 알고리즘을 참고해 보았습니다. 음악을 들을 때, 랜덤 재생을 설정해도 같은 가수의 노래가 연속으로 나올 때가 있었을 텐데요. 이와 같이 동일한 특성으로 클러스터가 생성되는 현상을 방지하고자 고안된 알고리즘입니다. 대략적인 원리는 아래와 같습니다.
- 동일 클러스터 내의 개체 간 간격은 기본적으로 1/n(n=클러스터 내 개체 수)로 설정
- 처음 개체의 위치에 uniform(1, 1/n)에서 샘플링된 값을 더해 시작 위치를 변경
- 각 개체의 위치에 uniform(-0.1/n, 0.1/n)에서 샘플링된 값을 더해 개체 간 간격에 무작위성을 부여
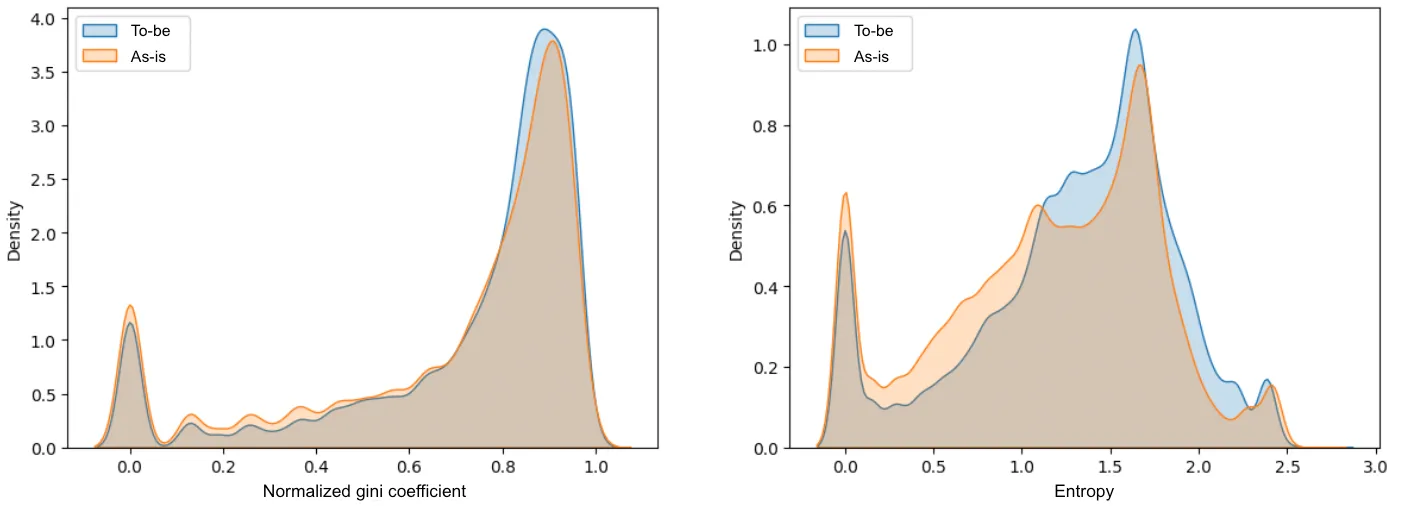
핵심은 같은 특성을 지닌 개체 간에 랜덤한 간격을 설정한다는 것입니다. 저희는 이 알고리즘을 구현하여 최종적으로 셔플링된 결과를 만들 수 있었는데요. 카테고리 다양성이 얼마나 개선되었는지 정량적으로 알아보기 위해 Shannon entropy와 Gini coefficient를 이용하여 분석을 수행했습니다. 두 지표 모두 값이 클수록 카테고리 분포가 균등하고 값이 작을수록 분포가 불균형하다는 것을 의미합니다.
© 2024.Kurly.All right reserved
실제 장바구니 데이터를 기반으로 실험을 진행하였으며, ‘기존 방식(score 순 정렬)으로 구성한 상위 30개의 추천 결과’와 ‘200개의 상품을 셔플링하여 구성한 상위 30개의 추천 결과’의 카테고리별 상품 수에 대해서 지니 계수와 엔트로피를 계산해 보았습니다. 위 그래프에서도 보실 수 있듯이 셔플링된 결과에서 전반적으로 두 지표가 높은 쪽의 밀도가 더 많았으며, Kruskal-Wallis 검정을 통해 통계적으로도 두 결과의 중앙값에 유의한 차이가 있음을 확인할 수 있었습니다 (p < .05).
서비스 적용 및 테스트
지금까지 장바구니 페이지에 서빙할 추천 모델을 개발하는 과정과 그 과정에서 발생한 고민을 어떻게 해결했는지 설명드렸습니다. 하지만 추천 서비스는 결국 실제 엔드 유저를 대상으로 온라인 지표를 측정하여 성과를 판단하는 것이 중요합니다. 모델을 학습하고 테스트하는 시점의 오프라인 지표는 결국 과거의 데이터일 뿐이기 때문에 실제 추천 서비스에 노출되는 현재 시점의 유저의 반응을 대변하지 못하기 때문입니다. 따라서 저희는 실제 일부 컬리 유저를 대상으로 A/B 테스트를 진행하였습니다. 실험 셋팅은 다음과 같습니다.
- 대상: 전체 유저의 약 8%
- 기간: 1주일
- 실험 그룹
- 대조군(50%): 비개인화 추천
- 실험군(50%): BERT4Rec 보완재 추천
© 2024.Kurly.All right reserved
실험 모니터링 및 결과 판단은 growthbook을 활용하였습니다. 그 결과 대조군 대비 장바구니 전환 유저 비율, 유저당 담은 상품 개수, 유저당 담은 상품 금액이 약 100% 가까이 상승하였고, 통계적으로도 유의한 수치임을 확인하였습니다. 이를 통해 유저들에게 현재 컨텍스트와 연관성이 있는 상품을 추천 해주는 것이 주효하다는 것을 확인할 수 있었습니다. 다시 말해 현재 유저의 장바구니에 담긴 상품과 보완재라는 연관성이 있는 상품을 추천할 때가 그렇지 않을 때보다 더 유저의 반응을 잘 이끌어 낸다는 것입니다.

© 2024.Kurly.All right reserved
향후 과제
실험이 성공적으로 마무리되었기 때문에 현재 컬리 앱에서 특정 유저군을 대상으로 BERT4Rec 보완재 추천 모델이 서빙되고 있습니다. 하지만 아직 보완해야 할 점도 많습니다. 먼저 아직 개인화 피쳐나 다른 맥락 정보(예: 시간)를 고려하지 못하기 때문에 장바구니에 같은 상품을 담은 서로 다른 유저에게 동일한 추천 결과가 보여지고 있습니다. 따라서 개인화 추천으로 나아가도록 모델 및 아키텍처를 개선할 예정입니다. 그리고 컬리의 상품은 매일 추가되거나 삭제되고 있기 때문에 부득이하게 단어 사전을 매번 학습 때마다 새로 만들어서 스크래치부터 학습하고 있습니다. 이는 학습 과정상 비효율을 초래하기 때문에 이를 극복할 수 있는 방안을 찾고자 합니다. 이외에 다양한 실험 아이디어들이 있는데, A/B 테스트를 통해 지속적으로 검증하여 유저들의 쇼핑 경험을 계속 개선해 나갈 것입니다. 컬리의 추천이 진화하는 모습을 앞으로도 기대해 주세요!
참고 자료
- Zhang, M., & Bockstedt, J. (2020). Complements and substitutes in online product recommendations: The differential effects on consumers’ willingness to pay. Information & Management, 57(6), 103341.
- Sun, F., Liu, J., Wu, J., Pei, C., Lin, X., Ou, W., & Jiang, P. (2019, November). BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM international conference on information and knowledge management (pp. 1441-1450).
- https://engineering.atspotify.com/2014/02/how-to-shuffle-songs/
- https://en.wikipedia.org/wiki/Pointwise_mutual_information