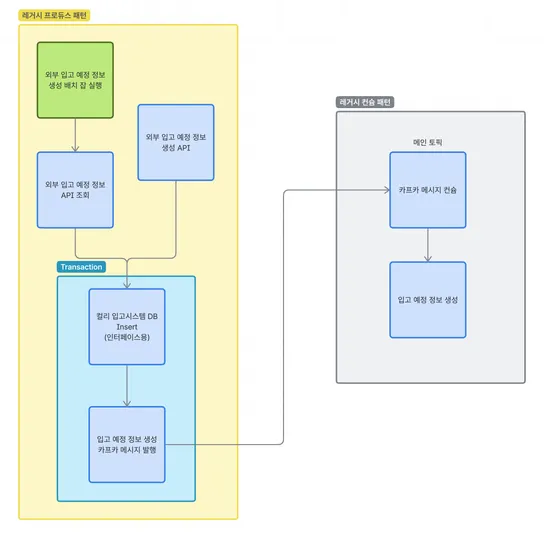
1. Intro
안녕하세요, 현재 컬리에서 회원/마케팅서비스 개발을 담당하고 있는 박준규입니다.
컬리에 입사한 지 1년이라는 시간을 보내면서 많은 시행착오와 경험들을 하였는데요, 그 중 하나로 컬리 전반적으로 사용하고 있는 공통 암호화 SDK 모듈 이슈에 대한 경험을 공유드리려고 합니다.
E-Commerce 도메인 뿐 아니라 웹 서비스에서는 수많은 고객의 개인정보를 처리해야 할 텐데요, 개인정보 보호법 제7조에 의하여 개인정보처리자는 안전한 알고리즘을 사용하여 개인정보를 암호화하여야 합니다. 컬리에서는 AWS KMS를 이용하여 개인정보 암호화를 처리하고 있습니다.
이번 포스트에서는 암호화 SDK 공통 모듈의 간단한 구조와 함께 내부적으로 발생한 Buffer 관련 이슈를 간략히 설명하고, 이를 개선하기 위한 삽질을 공유하고자 합니다
2. AWS KMS 란
앞서 컬리에서는 AWS KMS를 이용한다고 말씀드렸는데요,
AWS KMS (Key Management System)는 AWS Cloud 환경에서 제공하는 서비스에 대한 암호화를 관리할 수 있게 해주는 서비스입니다.
간단하게 그림으로 KMS에서 제공하는 암/복호화 기능에 대해 확인해보겠습니다.
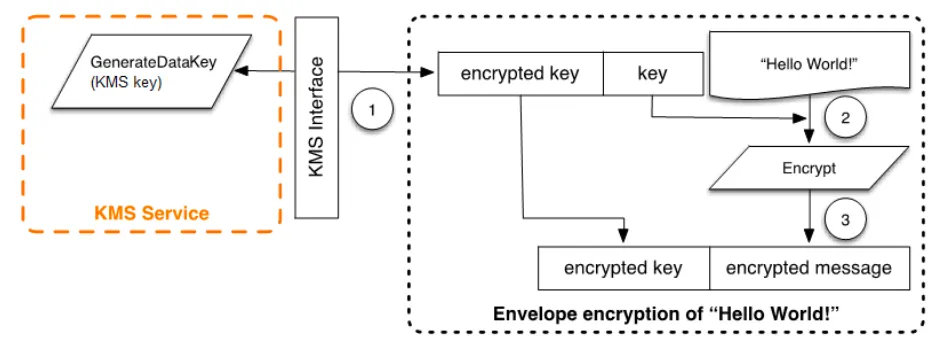
위 그림은 AWS KMS 클라이언트를 통한 평문 암호화 동작을 그림으로 나타낸 것입니다.
KMS에서 제공하는 GenerateDataKey 라는 인터페이스를 통해 평문을 봉투 암호화 할 수 있습니다.
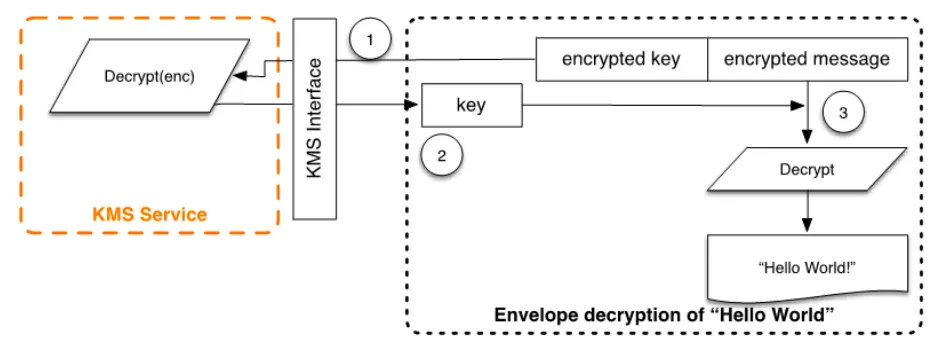
위 그림은 AWS KMS 클라이언트를 통한 암호문 복호화 동작을 그림으로 나타낸 것입니다. KMS에서 제공하는 봉투 암호화를 사용했다면, 암호화 시 사용하였던 암호화 키를 요청하여 KMS의 Decrypt 서비스를 통해 정상적으로 암호문을 복호화할 수 있습니다.
위에서 볼 수 있듯이 평문을 암/복호화하기 위해서는 암호화 키가 필요합니다. 또한 이 키를 IAM 정책이나 교체 주기, 암/복호화 알고리즘 등의 정책에 따라 관리할 수 있어야 하는데요. 암호화 키를 적절한 정책을 통해서 관리하고, 원하는 암/복호화 기능을 정상적으로 수행할 수 있도록 하는 기술이 KMS 라고 볼 수 있습니다.
KMS의 원리에 대한 더 자세한 내용은 백서 를 참고해주시면 좋을 것 같습니다.
3. 컬리의 공통 암호화 모듈
컬리에서는 AWS KMS를 어떻게 사용할까요?
AWS 서비스 사용을 위해서는 비용을 고려해야 합니다. 서울 리전의 AWS KMS에서는 다음과 같은 정책 으로 요금을 청구합니다.
월별 총 비용 = (고객 관리형 마스터 키의 개수) * 1.00 USD + (API 요청 횟수) * 0.000003 USD따라서 비용 최소화를 위해 저희는 가용한 키를 최소한으로 유지하고, API 요청 빈도를 줄일 수 있는 방법을 검토하였고, 그 결과 자바의 고성능 캐시 라이브러리인 Caffeine을 채택했습니다. Caffeine은 캐시 적재/삭제/갱신 기능에 여러 전략을 제공하는 라이브러리로, 환경에 따라 적절하게 사용하여 시스템의 성능 향상을 이끌어 낼 수 있습니다. Caffeine의 성능에 대한 내용은 Caffeine Wiki 에서 확인하실 수 있습니다.
캐시를 사용하지 않는다면 암/복호화 요청이 필요할 때마다 KMS 클라이언트를 호출해야 합니다. 그 대신 AWS KMS에 요청하여 응답받은 Data Key를 특정 시간동안 Caffeine 캐시에 보관해 활용하는 전략을 통해, API 요청 횟수와 이에 따른 비용을 줄일 수 있었습니다.
컬리에서는 이렇게 캐시를 활용한 공통 암호화 SDK 모듈을 암/복호화가 필요한 서비스에 주입하여 각 어플리케이션의 설정에 따라 암/복호화를 수행하고 있습니다.
4. 간헐적 버퍼 오류를 마주하다
현재 제가 담당하고 있는 1:1 문의 게시판 서비스 역시 공통 암호화 SDK 모듈을 사용하여 개인정보를 암호화 하고 있습니다. 그런데.. 해당 서비스를 모니터링하던 중, 암호화 서비스에서 지속적으로 오류가 발생하는 것을 발견하게 되었습니다. 일부 요청에 대해서만 간헐적으로 말이죠..
간헐적으로 발생하는 해당 서비스의 오류를 확인해 보겠습니다.
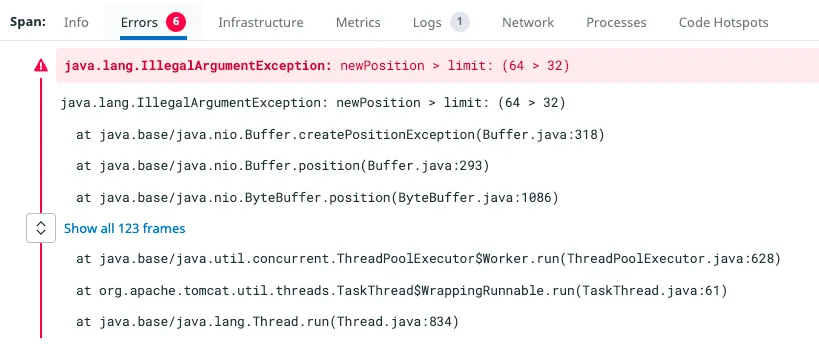
1:1 문의 게시판 서비스에서 newPosition > limit 라는 Buffer 연산 오류가 발생하고 있습니다.
해당 오류가 발생하면 고객은 아래처럼 마스킹 처리된 전화번호를 보지 못하고, 빈 칸을 보게 됩니다.

즉, 간헐적으로 일부 고객은 답변받을 전화번호를 확인하지 못하고 1:1 문의글을 등록하는 것입니다.
암호화 로직에서 발생하는 문제이기 때문에 1:1 문의 서비스에서만 발생하는 것이 아니라 암호화 SDK 모듈을 사용하는 모든 서비스에서 발생하고 있을 확률도 배제할 수 없고, 그로 인한 이펙트도 알 수 없었기 때문에 왜 이런 문제가 발생하는 지에 대한 파악이 시급해 보였습니다.
4.1 Digging
그럼 왜 이런 문제가 발생하는 지 어떻게 파악해야 할까요? 저는 위 프레임에서 보이는 플로우를 따라가기로 히고, 먼저 암호화 SDK 모듈에서 오류가 발생하는 최초의 구간에서 시작하였습니다.
EncryptService.java
// 캐시에서 AWS DK(Data Key)를 가져옵니다.
final GenerateDataKeyResult dataKeyResult = dataKeyCacheManager.getDataKey();
// 평문 암호화 Key를 생성합니다.
final Key key = SecretKey.createKey(dataKeyResult.getPlaintext());위 2줄에서 기대하는 바는 다음과 같습니다.
- 캐시에서 DK를 가져온다.
- DK를 통해 평문 암호화 키를 생성한다.
위 코드에서 SecretKey.createKey 함수의 매개가 되는 GenerateDataKeyResult 객체 는 위에서 말씀드린 AWS 에서 제공하는 Key 스펙이며, createKey 함수 내부는 오류가 발생하는 구간입니다.
이어서 SecretKey 클래스를 살펴보겠습니다.
SecretKey.java
/**
* 입력받은 ByteBuffer를 참조하여 Key를 생성해 리턴합니다.
*/
public static Key createKey(ByteBuffer key) {
// 내부 메소드 호출
return new SecretKeySpec(getByteArray(key.clear()), KEY_ALGORITHM);
}
private static byte[] getByteArray(ByteBuffer b) {
byte[] byteArray = new byte[b.remaining()]; // 버퍼의 잔여용량만큼 바이트 배열 생성
b.get(byteArray); // 오류 발생 지점
return byteArray;
}저희가 호출한 createKey 함수 내부 로직을 보면, 내부 메소드인 getByteArray를 호출하는 데, clear 메소드를 호출한 값을 매개변수로 사용합니다. key.clear()는 데이터 읽기를 위해 버퍼를 준비(초기화)하는 메소드입니다.
getByteArray 메소드에서는 버퍼의 잔여용량만큼 바이트 배열을 생성하고, get 메소드를 통해 할당된 버퍼 용량만큼 바이트를 읽고 반환합니다.
오류 발생 지점인 ByteBuffer의 get(byte[] dst) 메소드를 파고 들어가 보겠습니다.
ByteBuffer의 get(byte[] dst) 메소드
/**
* Relative bulk <i>get</i> method.
*
* <p> This method transfers bytes from this buffer into the given
* destination array. An invocation of this method of the form
* {@code src.get(a)} behaves in exactly the same way as the invocation
*
* <pre>
* src.get(a, 0, a.length) </pre>
*
* @param dst
* The destination array
*
* @return This buffer
*
* @throws BufferUnderflowException
* If there are fewer than {@code length} bytes
* remaining in this buffer
*/
public ByteBuffer get(byte[] dst) {
return get(dst, 0, dst.length);
}get 메소드의 자바독을 보면, 상대적 전송 방법임을 알 수 있습니다. 참조된 바이트 배열 크기만큼 벌크로 바이트를 읽어 destination array로 전송하는 메소드입니다.
해당 메소드를 보면 다시 get(dst, 0, dst.length) 메소드를 호출하고 있는데, 이 때 HeapByteBuffer의 오버라이드된 get 메소드를 호출한다는 사실을 디버깅을 통해 알 수 있었습니다. 계속해서 HeapByteBuffer 객체의 get 메소드 내 로직을 확인해 보겠습니다.
HeapByteBuffer의 get(byte[] dst, int offset, int length) 메소드
public ByteBuffer get(byte[] dst, int offset, int length) {
checkBounds(offset, length, dst.length);
int pos = position();
if (length > limit() - pos)
throw new BufferUnderflowException();
System.arraycopy(hb, ix(pos), dst, offset, length);
position(pos + length);
return this;
}위 메소드는 버퍼로부터 바이트를 읽어 destination array로 전송하는 내용을 실제 구현한 로직이며, 버퍼 크기 검증, 배열 복사, 버퍼의 position을 재설정하는 로직으로 구성되어 있습니다. limit(), position() 등 알아볼 수 없는 메소드가 몇 개 있긴 하지만 일단 익숙한 용어들이긴 합니다. newPosition > limit 라는 오류로 여기까지 온 거니까요 ㅎㅎ 뭔가 가까워져 오는 것 같습니다.
핵심 라인인 position(pos + length) 구문이 어떻게 동작하는지 보겠습니다.
Buffer의 position(int newPosition) 메소드
/**
* Sets this buffer's position. If the mark is defined and larger than the
* new position then it is discarded.
*
* @param newPosition
* The new position value; must be non-negative
* and no larger than the current limit
*
* @return This buffer
*
* @throws IllegalArgumentException
* If the preconditions on {@code newPosition} do not hold
*/
public Buffer position(int newPosition) {
if (newPosition > limit | newPosition < 0)
throw createPositionException(newPosition);
if (mark > newPosition) mark = -1;
position = newPosition;
return this;
}드디어 newPosition이라는 용어가 나왔군요..! 자바독을 보니, 버퍼의 position을 세팅하는 메소드입니다. position 메소드의 실행 이유는, 버퍼의 기존 position에서 length 만큼 버퍼를 읽었기 때문에 newPosition으로 위치를 새로 세팅해주어야 하기 때문입니다.
그런데.. if 문을 보니 매개변수로 넘어온 newPosition이 limit보다 크거나 음수이면 createPositionException을 발생시키고 있습니다. 왠지 연관이 있을 것 같습니다.
Buffer의 createPositionException 메소드
/**
* Verify that {@code 0 < newPosition <= limit}
*
* @param newPosition
* The new position value
*
* @throws IllegalArgumentException
* If the specified position is out of bounds.
*/
private IllegalArgumentException createPositionException(int newPosition) {
String msg = null;
if (newPosition > limit) {
msg = "newPosition > limit: (" + newPosition + " > " + limit + ")";
} else { // assume negative
assert newPosition < 0 : "newPosition expected to be negative";
msg = "newPosition < 0: (" + newPosition + " < 0)";
}
return new IllegalArgumentException(msg);
}오류가 여기에서 발생하고 있었군요. position 메소드의 매개인 pos + length가 간헐적으로 버퍼의 limit인 32를 넘어가면서 createPositionException을 발생시킨 것이었습니다.
4.2 동시성 이슈를 의심하다
그렇다면 왜 createPositionException이 간헐적으로 발생하는 것일까요? 처음 지점부터 생각을 해보면, 캐시에서 꺼내온 키는 특정 시간동안 계속 같은 키일텐데.. ‘키가 교체되는 시점인가?’ 라는 생각도 했지만, 유지 시간 내에도 n 회 발생하고 있었기 때문에 그건 아니라고 판단했습니다. 그럼 특정 시간동안은 늘 같은 값을 가지고 키 생성 요청을 하는데, 간헐적으로 오류가 나는 것이죠.
늘 같은 값인데 간헐적으로 오류가 발생한다..
직감적으로 동시성 이슈의 냄새가 났습니다. 파악한 내용을 팀원들과 공유해 의견을 주고받은 결과 또한 동시성 이슈에 대한 의심이었습니다. 저는 동시성 이슈에 대한 의심을 확신으로 바꾸기 위해 동시성 이슈가 맞는지 테스트를 수행하여 확인하기로 하였습니다.
4.3 의심을 확신으로
다음은 제가 간단하게 작성한 테스트 코드입니다.
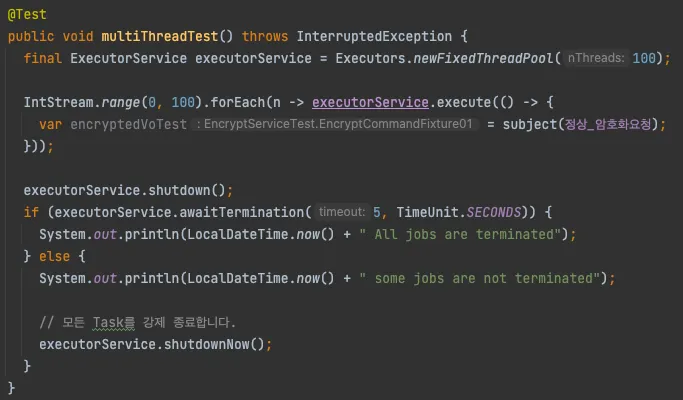
테스트 코드는 다음과 같은 내용을 포함하였습니다.
- 100개의 고정된 스레드 풀을 생성하고, 100개 스레드로 암호화 로직 수행 요청
- 암호화 로직 수행 중 바이트 배열을 가져오는 부분에 ByteBuffer의 속성 값을 출력하여 확인
- 모든 스레드 완료 5초 대기 후 강제종료
여기서 중요한 내용은 테스트 중에 버퍼의 limit, position, length 를 확인하는 것입니다.
limit은 Buffer에서 읽거나 쓸 수 있는 위치의 최대치를 의미하고, position은 Buffer의 현재 위치를 의미합니다. 따라서, position은 limit보다 큰 값을 가질 수 없습니다.
현재 문제가 발생하는 것은 newPosition (position + length) > limit 즉, 버퍼의 position과 배열의 길이를 더한 값이 버퍼의 limit을 넘기기 때문입니다.
아까 키 생성하는 로직에서 보았듯이 키는 초기화된 버퍼로 넘어갑니다. clear() 메소드를 호출하면 position은 0으로 초기화하고, limit은 capacity로 초기화 합니다. 그런데 아래를 보시죠.
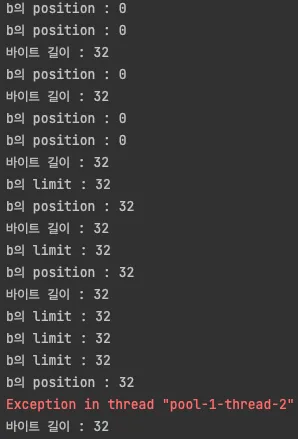
일부 스레드에서 ByteBuffer(b)의 position이 32로 출력되는 것을 확인됩니다. 정상적으로는 버퍼를 clear 한 값을 매개로 넘겼기 때문에 0이어야 할 position 값이 32로 출력되는 것은 즉, 해당 메소드가 thread-safe 하지 않음을 말합니다.
저는 이 테스트를 진행하면서 Buffer 관련 API 문서를 확인하게 되었는데요, 문서의 내용을 확인해 보면 Buffer 사용 시 thread-safe에 대한 주의점이 명시되어 있습니다.
Buffers are not safe for use by multiple concurrent threads. If a buffer is to be used by more than one thread then access to the buffer should be controlled by appropriate synchronization.
5. 동시성 이슈 해결을 위해
버퍼 사용 시에 동시성 이슈가 존재한다는 것을 확인하고, 어떻게 이를 해결할 수 있을 지에 대해 고민하게 되었습니다.
간단하게 정리한 방법은 2가지로 다음과 같습니다.
- ByteBuffer를 사용하는 메소드에 동기화를 위한 코드를 추가해주어 해결
- synchronized 구문 추가
- ByteBuffer 사용 시에 duplicate() 메소드를 사용하여 해결
- 단일 스레드를 위한 지역 버퍼를 생성함으로써 동시성 이슈가 해소될 것을 기대
첫 번째 방법인 synchronized 구문 사용은 성능 이슈를 trade-off로 가져가야 하기 때문에 다른 방법을 선택하는 것이 좋아 보였습니다.
더불어 GenerateDataKeyResult 객체 내 getPlaintext() 메소드의 자바독에는 thread-safe를 위해 asReadOnlyBuffer() 메소드 사용을 권장하는 다음과 같은 내용이 명시되어 있습니다.

이에 따라 채택한 방법은 두번째입니다. SDK 모듈의 HeapByteBuffer의 duplicate()는 위 가이드의 asReadOnlyBuffer()와 동작 원리가 동일하므로, 이를 호출하여 스레드마다 새로운 객체를 생성하면서 동시성 이슈를 해결할 수 있었습니다.
6. Outro
이번 편에서는 컬리 공통 암호화 모듈의 동시성 이슈 해결 과정에 대해서 공유드려 보았습니다.
저의 삽질을 컬리 테크블로그의 독자 님들과 공유할 수 있어서 매우 영광입니다.
이 글을 작성할 수 있게 도움주신 회원/마케팅개발 팀원 분들에게 감사드립니다 :)
궁금한 내용은 댓글로 남겨주시면 답글 드리도록 하겠습니다. 글 읽어주셔서 감사드립니다!