안녕하세요, 컬리 데이터플랫폼팀에서 ML Engineer로 일하고 있는 한수진입니다.
ML Engineer로 일하다보면 모델의 성격에 맞는 효율적인 서빙 파이프라인을 고민하기 마련인데요, 이번 주제는 그 고민의 일원으로 컬리의 준실시간 수요 예측 시스템의 파이프라인을 Apache Beam 모델 기반의 구글 Dataflow 서비스로 구현한 경험기를 1, 2편에 나눠 소개하고자 합니다. 본 글 1편에서는 Dataflow 도입 배경 및 서비스 전반에 대한 개념과 배포 과정을 다루고 2편에서는 실제 예측 시스템에서 Beam 파이프라인을 어떻게 사용하고 있는지에 대해 소개하려고 합니다.
Dataflow 도입을 고려하고 계시다면 이 글을 참고로 업무에 활용하시는 데에 도움이 되었으면 좋겠습니다.
어떤 파이프라인이 필요했나?
준실시간 수요예측 모델 서빙
현재 컬리에는 다양한 수요 예측 모델이 있고, time series 통계 모델도 활용하고 있습니다. 이 모델은 1년치 과거 데이터를 사용하여 시계열 데이터간의 연관성을 통계적으로 찾아내어 수요량을 예측하는 방식인데, 시시각각으로 변하는 고객의 주문 데이터가 예측에 상당한 영향을 주는만큼 실시간 데이터를 모델에 빠르게 반영하는것이 중요했습니다. 즉, 준실시간으로 수요예측 모델을 안정적으로 서빙하기 위한 파이프라인이 필요했습니다.
BigQuery 데이터 기반의 파이프라인
컬리에서 고객의 주문 데이터는 스트리밍으로 AWS MSK(Kafka)에 수집된 후 BigQuery로 적재되고 있습니다. 여기서 Kafka 데이터와 BigQuery 데이터의 역할을 좀 더 구분짓자면, Kafka는 스트리밍 처리를 위해 메세지를 전달해주는 매개체 역할이기 때문에 최신 스트리밍 데이터만 담고 있는 반면 BigQuery는 모든 과거 데이터를 담고 있습니다. 앞서 설명한 수요예측 통계모델은 결국 1년이라는 과거 데이터를 input으로 사용해야하기 때문에 기본적으로 GCP BigQuery 데이터를 기반으로 하는 파이프라인이 필요했습니다.
Dataflow
![]()
이러한 니즈에서 GCP 환경의 파이프라인을 구축하고자 Dataflow를 도입하게 되었습니다. Dataflow에 대한 간단한 설명은 다음과 같았는데요,
Dataflow는 2015년 구글에서 공개한 대용량 분산처리 시스템을 배치와 스트리밍 프로세싱으로 구현하는 완전관리형(fully-managed) 클라우드 서비스
“대용량 분산처리” 그리고 “스트리밍 프로세싱” 두 단어가 눈에 띄었습니다. 1년치 주문 데이터는 그 양이 상당하기도 할테고, 준실시간으로 모델을 서빙하려면 스트리밍 환경을 마련해야하는데 이를 모두 충족하기 때문입니다. 이와 더불어 managed라는 점에서 Dataflow는 대용량 데이터로 분산처리를 하면서 고려해야할 auto-scaling, rebalancing을 알아서 수행하여 Cloud 리소소 사용을 최적화해주기 때문에 인프라에 대한 관리 포인트를 줄여준다는 점 역시 매력적으로 보였습니다. 아무래도 주문량이라는 데이터는 언제든 급증하거나 감소할수도 있을텐데 그때마다 scale-out이 필요할지와 같은 고민을 하지 않아도 된다는 점에서 충분히 써볼 가치가 있다고 판단했습니다.
Dataflow에 대해 처음 들어보셨다면 아직 개념이 생소할 수 있을 것 같습니다. 좀 더 이해를 돕기 위해, Dataflow 서비스 생태계에 대해 차근차근 살펴보겠습니다.
Dataflow의 프로그래밍 모델, Apache Beam
Dataflow를 사용하려면 먼저 Apache Beam을 알아야 하는데, 그 이유는 Dataflow의 프로그래밍 모델이 바로 Beam이기 때문입니다. Apache Beam은 2016년 공개된 배치와 스트리밍 파이프라인을 모두 처리할 수 있는 프로그래밍 모델로 Beam이라는 이름도 Batch+Streaming이 합쳐져서 만들어진 것입니다. Beam은 현재 Java, Python, Go 세가지 언어로 지원되며 모델을 실행하는 런타임 엔진으로는 Apache Flink, Apache Spark, Google Cloud Dataflow 등이 있습니다. 결국 Dataflow도 이 Beam을 실행하는 프레임워크 중 하나인 셈이죠. 이 둘의 관계를 각각의 역할로 나누어 설명하자면, 분산처리에 대한 내부 로직은 Beam 파이프라인의 구성방식에 따르고 이를 감싸고 있는 백엔드의 성능과 속도는 Dataflow의 영역이라고 볼 수 있겠습니다.
(Beam에 대한 더 자세한 설명은 공식문서 참고)
Dataflow가 Beam 모델을 실행하는 방식
그렇다면 Dataflow가 Beam 모델을 어떻게 읽고 실행시키는 것일까요? 크게 보면, 파이프라인이 Dataflow가 인식할 수 있는 형태로 변환되어 Dataflow 서비스 엔드포인트로 전송되고나면 비로소 작업이 실행되는 방식입니다. 이러한 일련의 과정을 각각 작업 전 준비 단계(queued state) 그리고 실행 단계(running state)로 정의합니다.
준비 단계(Queued state)
작업이 시작되면 GCE에 launcher-xxxxx 이름을 가진 Virtual Machine이 생성됩니다. 이 launcher는 말그대로 작업을 런칭하는 역할로 작업 실행에 필요한 그래프를 생성해주는 역할까지만 맡기 때문에 그래프 생성이 끝나는 즉시 VM은 종료됩니다. 그럼, 이 그래프 생성까지 어떤 과정을 거치는지 좀 더 자세히 들여다보겠습니다.
- 환경 설정: Beam 모델 실행에 필요한 환경을 worker에 설정합니다. 이 과정에서 필요한 라이브러리를 설치하기도 하고 모델을 불러오기 위한 도커 이미지를 pull 하기도 합니다.
- 리소스 권한 및 유효성 검사: GCS 버킷, BigQuery 테이블 등 파이프라인이 참조하는 모든 리소스의 유효성을 검사합니다. 만약 존재하지 않는 리소스이거나, 작업에 사용하는 service account가 리소스에 접근권한이 없다면 이 과정에서 오류를 반환하고 그래프 생성은 중지됩니다.
- Beam 객체 메서드 변환(serialize): Beam pipeline에서 run()과 같은 스크립트 최상위 진입점에 있는 코드 조각을 실행합니다. 이때 데이터 소싱 혹은 변환 단계의 Beam 객체 메서드는 직접 호출되지 않고 대신에 그래프 노드로 변환만 됩니다. 즉, beam 메서드에 따라 그래프 노드가 만들어지지만 아직 활성화되지 않은 상태에 해당합니다. 만약 메서드가 잘못되었거나 메서드끼리 연결짓는 파이프라인에 문제가 있다면 이 과정에서 오류를 반환하고 그래프 생성은 중지됩니다.
위 과정을 무사히 거쳤다면 그래프가 정상적으로 생성되고, 이 그래프는 json으로 변환되어 Dataflow 서비스 엔드포인트로 전송됩니다.
실행 단계(Running state)
Running state가 되면 GCE에 worker VM이 생성되고 이 worker는 이전에 노드로 변환되었던 파이프라인 객체 메서드에서 선언된 코드를 실제 실행시켜줍니다. 이 과정에서 자동확장 기능이 설정되어있다면 필요한 리소스에 맞춰 worker 개수를 자동으로 조정합니다.
Dataflow 파이프라인 유형
배치 파이프라인
지정한 일정에 맞춰 새로운 작업이 생성되고 종료되는 것을 반복합니다. 이때 launcher 인스턴스가 생성되고 종료되는 과정으로도 꽤 시간이 소요되기 마련이니, 작업 실행 시간까지 고려한다면 배치 주기를 넉넉하게 가져가도 되는 경우에 사용하는 게 좋을 것 같습니다. 일례로, 준실시간성을 구현하고자 1분 단위 배치를 설정해보았는데 런칭 과정에서만 5분 이상이 걸려서 대차게 실패하기도 했습니다.
스트리밍 파이프라인
배치와 달리 스트리밍 파이프라인에서는 한번 생성된 작업은 계속 실행되며 작업 환경 스펙은 한번만 설정하면 됩니다. 즉, 맨 처음에만 런칭과정을 거치면 그 이후엔 동일한 환경에서 worker가 작업을 수행합니다. 하지만 모든 경우에 스트리밍 파이프라인을 적용할 수 있는건 아니고, 데이터 소스가 무한한 스트리밍성의 unbounded인 경우에만 가능합니다. 카프카, Pub/Sub이 그 대표적인 예가 되겠습니다. 반면 BigQuery 데이터를 처리할 때 스트리밍 파이프라인을 적용해보면 따로 에러를 반환하진 않지만 결국 배치 모드처럼 최초 한번만 실행될 뿐입니다. 언뜻 보기에 BigQuery에도 데이터가 꾸준히 적재되고 있는데 왜 스트리밍 모드가 불가한지 의문이 들 수도 있는데, 본래 빅쿼리는 유한한 데이터를 저장하는 데이터 웨어하우스라는 점을 감안하면 bounded라는 게 납득이 갈 것입니다.
Dataflow 템플릿
Beam 모델을 만들었다면 이제 원하는 유형의 Dataflow 파이프라인으로 작업을 생성하면 됩니다. 이때 반복적으로 파이프라인을 설계하고 Dataflow에 배포해야한다면 그때마다 개발 환경이나 파이프라인 종속 항목 설치가 필요할텐데 Dataflow 템플릿을 사용하면 이런 번거로움을 줄일 수 있습니다. 즉, 파이프라인을 패키징하여 reusable artifact 형태로 만들어서 사용한다는 개념입니다. 구글에서는 다양한 기본 pre-built 템플릿을 제공해주고 있기 때문에 각자 사용하는 서비스 종류에 맞게 잘 고른 후 파라미터만 잘 지정해주면 됩니다.
하지만 제공된 템플릿을 보면 알 수 있듯이 대부분 A에서 B로 데이터를 전송하는 단순 데이터 처리 정도에 불과합니다. 실제로는 좀 더 복잡한 데이터 전처리 과정이 필요하거나 수요예측 모델처럼 비즈니스 모델을 실행해야 할 수도 있겠죠. 이럴땐 직접 개발한 파이프라인을 커스텀 템플릿으로 등록해서 사용하면 되는데, 자체적으로 만들어 flexible하다는 의미로 flex 템플릿이라고 불립니다.
Flex 템플릿
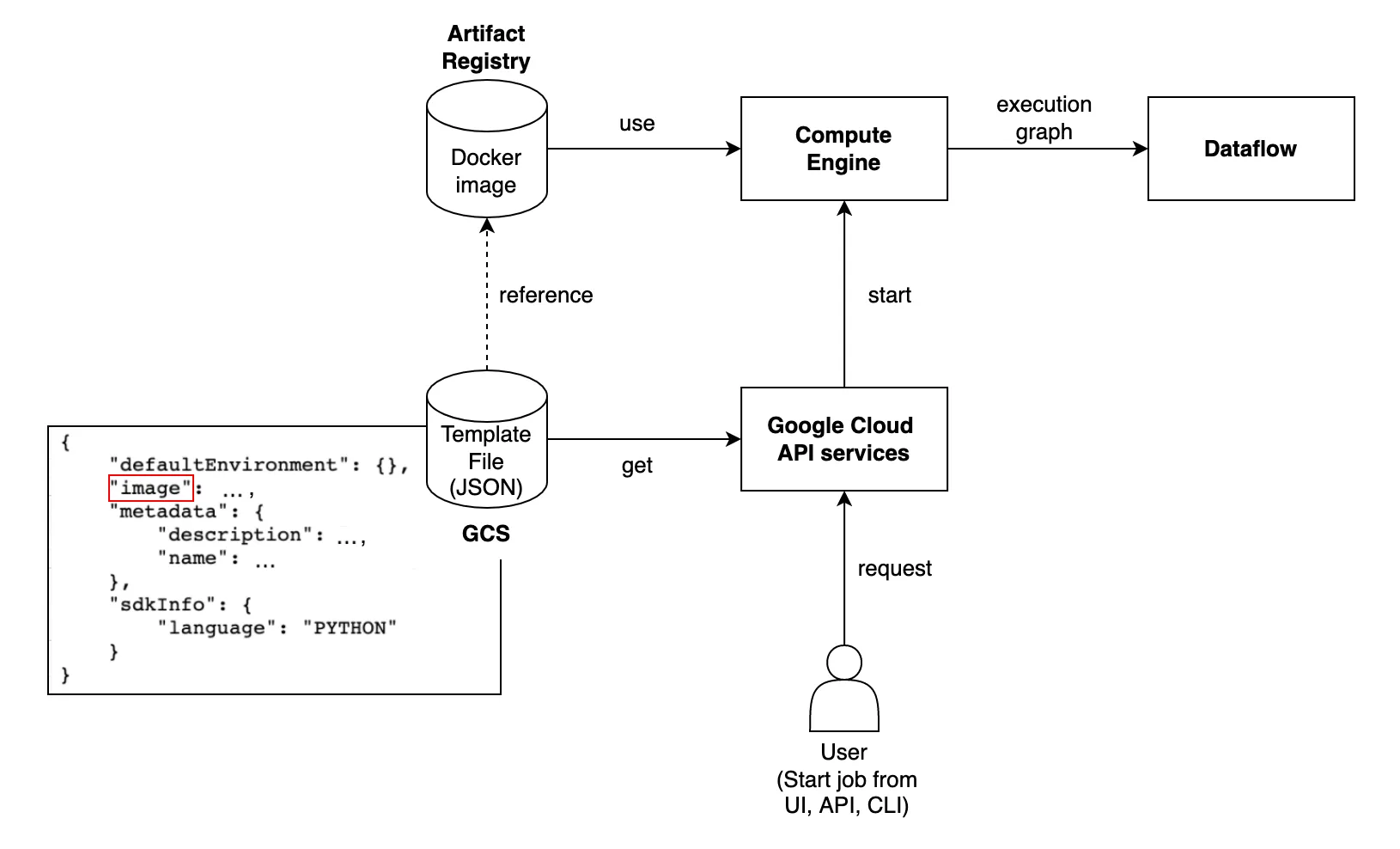
Flex 템플릿에는 두 가지 요소가 필요합니다. 파이프라인을 패키징한 도커 이미지(in Artifact Registry)와 해당 이미지를 참조하여 프로젝트를 실행시키겠다고 정의하는 템플릿 스펙 파일(in GCS bucket)인데요, 사실상 이 스펙 파일만 템플릿으로 등록해주면 GCP 콘솔, CLI, REST API 등 다양한 채널에서 Dataflow 작업을 만들 수 있습니다. 그 이유는 아래 작업 과정을 보면 이해가 쉬울 것 같습니다.
- 유저가 작업 시작을 위해 Cloud API에 request를 보냅니다. 이때 템플릿 파일이 저장된 GCS 버킷 URI를 명시하는데, 이 템플릿 파일에는 불러올 도커 이미지에 대한 정보를 포함하고 있습니다.
- 작업이 시작되면 Compute Engine에서 Beam 파이프라인의 compiled code가 담긴 도커 이미지를 실행합니다.
- 생성된 작업 그래프가 Dataflow에 전송됩니다.
Flex 템플릿이 어떻게 실행되는지 원리를 알았다면 이제 템플릿 빌드로 넘어가겠습니다.
그 전에, 아래의 전제 조건이 필요합니다.
- 템플릿 파일을 저장할 GCS 버킷 생성
- 도커 이미지를 저장할 Artifact Registry 생성
- 스토리지 관리자, Dataflow 관리자, Dataflow 작업자 권한을 가진 worker service account 생성
템플릿 빌드를 위한 프로젝트 레이아웃은 아래와 같습니다.
.
├── Dockerfile
├── beam-flex-metadata.json
├── main.py
├── utils
│ ├── __init__.py
│ └── ForecastModel.py
├── user_do_fns
| ├── __init__.py
| └── MyDoFn.py
├── setup.py
└── requirements.txt-
Dockerfile: 파이프라인 코드 패키징용 도커 이미지 설정파일
FROM gcr.io/dataflow-templates-base/python3-template-launcher-base ARG WORKDIR=/dataflow/template RUN mkdir -p ${WORKDIR} WORKDIR ${WORKDIR} COPY . ${WORKDIR}/ ENV FLEX_TEMPLATE_PYTHON_REQUIREMENTS_FILE=${WORKDIR}/requirements.txt ENV FLEX_TEMPLATE_PYTHON_SETUP_FILE=${WORKDIR}/setup.py ENV FLEX_TEMPLATE_PYTHON_PY_FILE=${WORKDIR}/main.py # Install apache-beam and other dependencies to launch the pipeline # Do not include `apache-beam` in requirements.txt !!! RUN apt-get update \ && pip install --no-cache-dir --upgrade pip \ && pip install -U apache-beam[gcp]==2.45.0 \ && pip install --no-cache-dir -U -r $FLEX_TEMPLATE_PYTHON_REQUIREMENTS_FILE # Install OpenJDK-11 RUN apt-get update && \ apt-get install -y openjdk-11-jre-headless && \ apt-get clean;- Flex Template Base Image를 사용하여 설정을 간소화합니다.
- 파이프라인이 실제 읽어들이게 될 driver 파일(FLEX_TEMPLATE_PYTHON_PY_FILE)과 FLEX_TEMPLATE_PYTHON_SETUP_FILE이 환경변수로 반드시 지정되어 있어야 합니다.
- apache-beam 버전을 지정해주면 런칭시 호환할 Beam SDK가 설치됩니다. 이때 Beam SDK는 Dataflow에서 지원하므로 따로 requirements.txt를 통해 설치하지 않고 Dockerfile 안에서 설치하면 됩니다. requirements에 포함시키게되면 필요 이상으로 완전 처음부터 설치가 진행되기 때문에 런칭 단계가 느려지게 됩니다.
- I/O 인터페이스 중에는 Python보다 Java로 완성도 있게 구현된 경우가 많습니다(ex. ReadFromKafka). 이 경우 Java 환경에서 해당 I/O 작업을 별도로 실행하기 위해 Python 내부에서 Java Expansion Service를 사용하는데 이때 필요한 JDK를 추가적으로 설치해줍니다.
-
beam-flex-metadata.json: 파이프라인에 대한 메타데이터와 PipelineOptions 파라미터에 대한 regex등 validation rule을 담은 파일
-
main.py: 파이프라인의 main entry point로 아래 utils, user_do_fns를 메인 세션에서 사용하기 위해서는 save_main_session은 반드시 True로 설정해야 합니다. 만일 세션을 저장하지 않으면 불러올 모듈이나 변수 등을 찾을 수 없다는 에러를 반환합니다.
-
utils: global하게 사용할 Python 함수, 모듈 등 beam.Map()을 통해 파이프라인에서 호출되는 공통 루틴 목록 (비슷한 맥락에서 user defined DoFns을 모아둔 user_do_fns를 따로 만들어줄수도 있음)
-
setup.py: Beam 라이브러리 및 requirements.txt에 명시한 프로젝트 dependency와 metadata를 정의한 파일로 Python의 packaging tool인 setuptools를 사용해서 패키지를 설치합니다. 한마디로 requirements 파일에 어떤 모듈을 쓸것인지 정의했다면 실제 파이프라인 실행 위치에서 설치를 한다는 개념인데, 라이브러리를 import해서 사용하는 주체는 main.py이므로 main.py와 동등한 경로상에 위치해야 합니다. 그렇지 않으면 라이브러리를 찾을 수 없다는 에러를 반환합니다.
setuptools.setup( name='beam-flex', version='1.0', install_requires=[], packages=setuptools.find_packages(), include_package_data=True, # warnings suppressors (없으면 런칭 단계 로깅에서 warning이 뜸) description='Beam Flex', author=..., author_email=... )
Dataflow CI/CD
이제 GitHub Actions로 템플릿 빌드에서부터 Dataflow 배포까지의 CI/CD workflow를 작성해보겠습니다. 설명을 위해 각 실행 단계별로 끊어서 보겠습니다.
-
Credential을 설정하고 Cloud SDK를 설치합니다.
jobs: deploy: name: Build Dataflow flex template runs-on: ubuntu-latest steps: - name: Checkout uses: actions/checkout@v2 - name: Auth GCP credentials uses: google-github-actions/auth@v1 with: credentials_json: ${{secrets.GCP_CREDENTIAL_KEY}} - name: Set up Cloud SDK uses: google-github-actions/setup-gcloud@v1 with: project_id: { PROJECT } -
Dataflow 스트리밍 파이프라인은 한번 생성되면 직접 작업을 삭제하지 않는 이상 계속 실행됩니다. 따라서 템플릿 버전에 따른 신규 작업 배포를 위해서는 기존 스트리밍 작업을 삭제해줘야 합니다. 이를 위해 작업명의 prefix를 기준으로 running중인 작업이 있는지 확인하고 삭제합니다. 만약 해당 prefix를 가진 작업이 없다면 아무 일도 일어나지 않습니다.
- name: Stop previous Dataflow job run: | gcloud dataflow jobs list --filter=“name:{JOB NAME PREFIX}” --format=“value(id)” | xargs -I{} gcloud dataflow jobs cancel {} --region {REGION} -
도커 이미지를 생성하여 registry에 저장합니다. 이때 동일한 이미지에 tag를 두개(버전명, latest)로 두어 버전별 트래킹에 용이하도록 했습니다. 추후 이 버전명은 Dataflow 작업 배포시 작업 버전을 구분하는 데에도 활용됩니다.
- name: Get image tag id: image run: | VERSION=$(echo ${{ github.sha }} | cut -c1-8) echo VERSION=$VERSION echo "::set-output name=version::$VERSION" - name: Build, tag, and push image to Google Artifact Registry env: IMAGE_TAG: ${{steps.image.outputs.version}} TEMPLATE_IMAGE: {REGION}-docker.pkg.dev/{PROJECT}/{REGISTRY PATH} run: | docker build -t flex . gcloud auth configure-docker {REGION}-docker.pkg.dev docker tag flex $TEMPLATE_IMAGE:$IMAGE_TAG docker push $TEMPLATE_IMAGE:$IMAGE_TAG docker tag flex $TEMPLATE_IMAGE:latest docker push $TEMPLATE_IMAGE:latest -
JSON 형식의 템플릿 파일을 빌드해서 GCS 버킷에 저장합니다. 이때 이미지는 늘 최신 버전을 들고오기 위해서 latest 태그로 고정했습니다.
- name: Build flex template env: TEMPLATE_IMAGE: {REGION}-docker.pkg.dev/{PROJECT}/{REGISTRY PATH} run: | gcloud dataflow flex-template build {TEMPLATE FILE GCS LOCATION} \ --image $TEMPLATE_IMAGE:latest \ --sdk-language PYTHON \ --metadata-file metadata.json -
템플릿을 가지고 Dataflow 작업을 시작합니다. 여기서 staging과 temp 경로를 지정하는 부분이 있는데, 이는 launcher가 worker에 필요한 코드 패키지나 임시 파일 등을 스테이징할 공간을 지정하는 것입니다. 선택사항이기 때문에 지정하지 않으면 버킷이 임의로 생성됩니다.
- name: Deploy flex template env: SA: ${{ secrets.SERVICE_ACCOUNT }} JOB_TAG: ${{ steps.image.outputs.version }} run: | gcloud dataflow flex-template run {JOBNAME}-$JOB_TAG \ --template-file-gcs-location {TEMPLATE FILE GCS LOCATION} \ --region {REGION} \ --service-account-email $SA \ --staging-location {GCS STAGING PATH} \ --temp-location {GCS TEMP PATH}
Dataflow 설정에 유용한 팁
- 스트리밍 파이프라인에서는 streaming engine을 쓰자
기본 설정시 DataflowRunner는 스트리밍 파이프라이닝 과정을 worker VM에서 실행합니다. 하지만 worker 사용이 늘수록 CPU, memory, Persistent Disk storage를 많이 소모하게 되므로 비용 부담이 클 수밖에 없습니다.
이때 streaming engine을 가동하면 이 실행 단계를 worker VM 대신 Dataflow의 서비스 백엔드단으로 역할을 넘길 수 있습니다. 이렇게 되면 worker에 부담을 줄일 수 있으니 스펙을 낮춰 비용을 줄일 수도 있고 Dataflow가 제공하는 horizontal autoscaling을 더욱 효율적으로 사용할 수 있다는 장점이 있습니다. (단, streaming engine 요금이 별도로 부여될 수 있음)
- 파이프라인 코드의 main session에서 정의된 global imports, variables, functions를 사용하기 위해서 save_main_session=True를 지정해주자
기본 설정시 Python main session에서 정의된 global imports, variables, functions는 Dataflow job으로 serialize하는 과정에서 저장되지 않습니다. 하지만 코드의 재사용성 및 가독성을 높이기 위해서는 세션을 저장하는 것이 좋습니다.
예를 들어 DoFns에서 사용할 모듈이나 imports는 한번만 정의해두고 파이프라인 코드에선 이를 참조하는 형식처럼 말이죠. 다만 세션이 너무 무거우면 serialization 과정이 오래 걸릴 수도 있기 때문에 퍼포먼스간 trade off를 고려해야 합니다.
- Dataflow에 올바른 권한 설정을 위해서 worker service account 외에, Dataflow service agent도 적절한 역할을 가지고 있어야 한다
Dataflow는 작업을 실행하는 과정에서 Dataflow service account와 worker service account 두 가지 계정을 모두 사용합니다.
처음 작업이 시작될 때 사용되는 것이 Dataflow service account인데, 이는 구글에서 default로 제공하는 서비스 에이전트로 인스턴스 생성과 같은 작업 시작의 request 단계에서부터 사용됩니다. 계정은 “service-@dataflow-service-producer-prod.iam.gserviceaccount.com”처럼 생겼습니다. 그 다음 실행 단계로 넘어서면 worker service account가 사용됩니다. 이것은 파이프라인 옵션을 통해 설정하는 custom controller 계정으로 작업 실행에 필요한 권한을 가지고 있어야 합니다. 기본적으로 roles/dataflow.admin, roles/dataflow.worker가 필요합니다.
그런데 계정이 두개이다보니 권한 이슈 발생시 무엇이 문제인지 찾기 쉽지 않을 수 있습니다. 예를 들어 VPC 통신이 필요한 경우를 가정해보겠습니다. 이때 worker service account에 Compute Network User 역할이 있음에도 불구하고 1초만에 작업이 실패하고 아래와 같은 권한 부족이 발생할 수 있습니다.

원인은 worker가 아닌 작업 초기에 사용되는 Dataflow service agent입니다. 이 계정에 Compute Network User 역할이 없기 때문이고 역할을 부여해주면 자연스레 해소됩니다.
마치며
이번 글에서는 모델 서빙 파이프라인으로 Dataflow를 도입한 이유와 Dataflow 전반에 대한 설명을 다뤄보았습니다. 스트리밍 데이터 처리와 안정적인 모델 서빙에 대한 관심이 높아진 만큼 Dataflow는 이를 대비하여 다양한 프로젝트에 적용해볼 만한 유용한 도구인 것 같습니다. 컬리에서도 이번 Dataflow PoC를 바탕으로 통계/ML모델 어플리케이션에 활용해보고자 합니다. 처음으로 도입한 사례는 준실시간 수요예측 시스템이 되겠는데요, 다음 편에서 Beam 모델로 파이프라인을 어떻게 구성했는지 소개하도록 하겠습니다. 긴 글 읽어주셔서 감사합니다.
참고자료
- https://cloud.google.com/dataflow/docs/about-dataflow
- https://beam.apache.org/get-started/
- https://cloud.google.com/blog/topics/developers-practitioners/dataflow-backbone-data-analytics?hl=en
- https://medium.com/cts-technologies/building-and-testing-dataflow-flex-templates-80ef6d1887c6
- https://medium.com/google-cloud/dataflow-flex-templates-2819572f165f
- https://stackoverflow.com/questions/63304401/dataflow-error-message-required-compute-subnetworks-get-permission