Image Created by DALL-E
안녕하세요. 컬리 데이터 플랫폼팀에서 데이터 엔지니어링과 MLOps관련 업무를 맡고 있는 이상협입니다.
데이터 플랫폼팀에서는 데이터 엔지니어링은 물론 다양한 머신러닝과 관련된 업무를 진행중인데요, 최근에는 ML관련 다양한 업무를 위한 MLOps플랫폼을 구축하고 있습니다. MLOps에 관련된 다양한 자료들이 많아지고 있는 요즘, Kurly만의 MLOps 플랫폼을 만들기 위해 고민했던 부분들을 기술 블로그를 통해 공유해보려고 합니다.
이 글에서는 MLOps 플랫폼, 그 시작에 대한 기록입니다. MLOps를 위해서는 어떤 것이 준비되어야 할까요?
Kurly 데이터 플랫폼팀에서는 MLOps플랫폼을 만들기 위해 어떤 준비를 하고 있는지 한 번 살펴보도록 하겠습니다.
MLOps
MLOps라는 말이 최근에 많이 보이고 있습니다. ‘ML업무를 하는데 MLOps가 필요하다’고 하시는 분들도 굉장히 많아졌고, 이에 대한 서적들과 강의들도 등장하고 있습니다. 구글 트렌드로도 보니 검색량이 지속적으로 올라가고 있는 것을 볼 수 있네요.
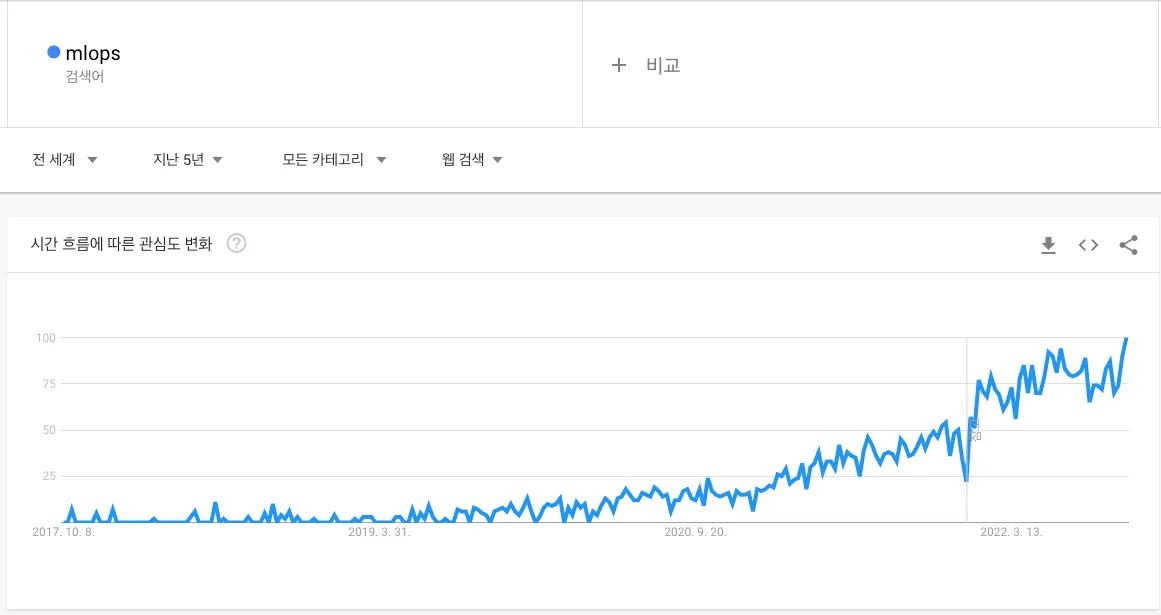
도대체 MLOps가 뭐길래 이렇게 핫한 걸까요? 기본적으로 MLOps는 ML + Ops로서, ML시스템의 운영을 위해 DevOps의 원칙을 적용한 것입니다. 그러니까 ML시스템이 점점 커지면서 운영에 손이 많이 가게 되니, 이것을 DevOps화 하겠다는 것입니다.
‘Designing Machine Learning System(Chip Huyen, 2022)’ 에 ML App 스케일에 따라 필요한 인프라 정도를 설명한 부분이 있습니다. 이를 바탕으로 이해한 내용을 그림으로 나타내면 다음과 같습니다.
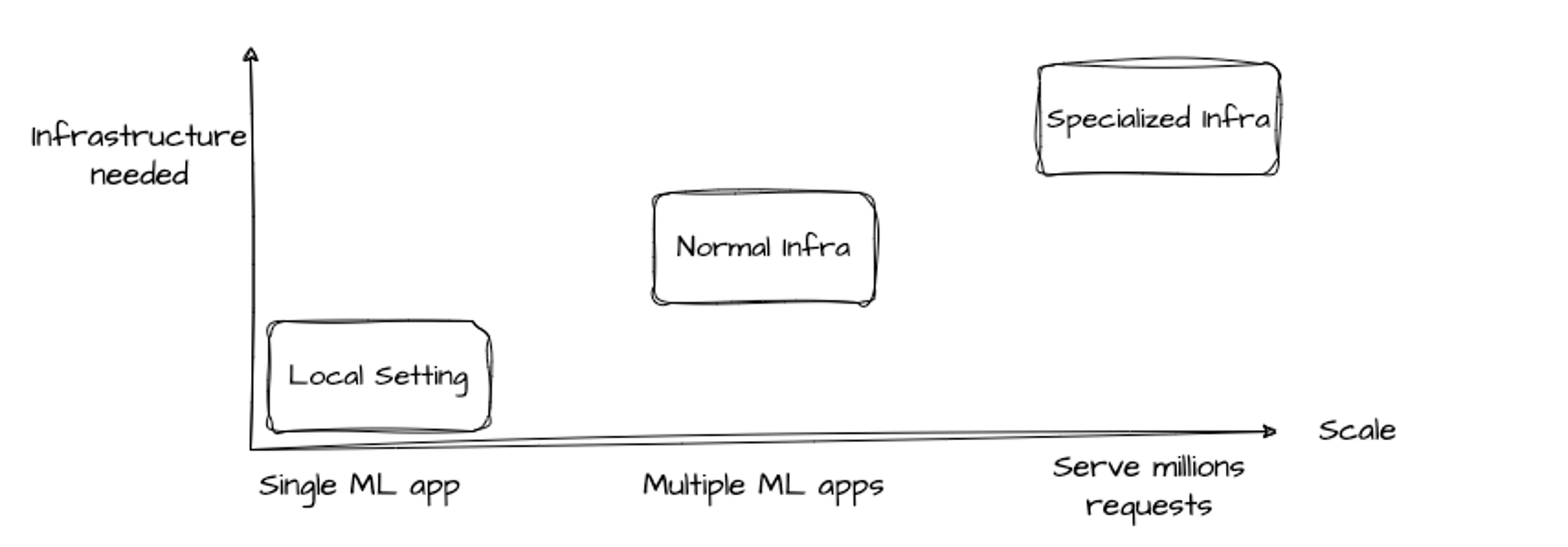
x축은 프로덕션 스케일을 말하고 y축은 인프라에 필요한 투자정도를 말합니다. 위에 그림에서처럼 점점 ML app들이 많아지면서 ML만을 위한, 특별한 인프라가 필요해지는 것이죠, 이 ML을 위한 특별한 인프라를 조성하는 것이 MLOps적인 일이라고 생각합니다. 사실 회사마다 조금씩 의미는 다를 수 있지만 큰 의미에서는 통할 것 같네요.
MLOps가 필요했던 이유
Kurly도 ML앱이 점점 늘어가면서 운영에 손이 많이 가다 보니 ‘MLOps에 대한 니즈’가 생겨나게 되었습니다. 그래서 니즈에 맞는 툴을 하나 둘씩 적용하면서 ML생태계를 구축하기 시작했습니다.
MLOps를 본격적으로 구상하기 전에, Data Engineering업무를 수행하기 위한 ‘Airflow’와 분석가나 데이터 사이언티스트를 위한 ‘JupyterHub’와 ‘MLFlow’가 쿠버네티스(Kubernetes)로 구성되어 있었습니다. 물론 여기에서도 ML업무를 수행할 수 있었지만 편하게 사용하고 자유롭게 쓸 수 있는 상황은 아니었습니다. 학습에 사용되는 ‘GPU’가 문제였습니다.
모델을 돌려보신 분들은 아시겠지만, GPU는 모델을 학습하는데 정말 필요하고 중요한 자원입니다. 무엇보다도 빠른 연산속도 덕분에 시간을 줄여줍니다. 하지만 클라우드에서 사용하려면 굉장히 비싸기 때문에 자원관리를 잘해야 합니다. 쓸 때만 쓰고, 안 쓸땐 얼른 종료시켜야 하는 것이죠. 물론 워크스테이션을 구매해서 사용하면 부담이 덜 하겠지만, 클라우드 환경에서는 아무래도 GPU인스턴스에 대한 관리를 예민하게 할 수 밖에 없습니다.
그래서 GPU는 사용하기 까다로운 존재가 되었습니다. 사용하고 싶을 때 권한이 있는 엔지니어에게 요청을 해야하고, 담당 엔지니어가 모니터링을 계속 해야만 하기 때문입니다. 엔지니어의 리소스가 많이 투입 되다 보니, DS분들도 마음 편히 요청하기는 힘든 상황이었습니다. 그래서 GPU를 편하게 Provisioning하고, 안 쓸때는 자동으로 Deprovisioning하는 구조가 필요했습니다.
그 외에도 위에서 말한 JupyterHub, Airflow, MLFlow 등을 통합해서 사용하는 환경도 필요했습니다. 각각의 도구들을 사용하고있긴 했지만 각각이 연결되어 있다기 보다는 독립적으로 운영되는 느낌이 강했기 때문에, 더 쉽게 다른 도구에 접근해서 ML업무를 할 수 있는 환경을 만들고 싶었습니다. 그래서 통합된 환경을 제공하는 AWS의 SageMaker나 GCP의 VertexAI를 사용해볼까도 고민했었습니다. 하지만 또 다시 마주하게 된 것은 비용 문제였고, 사용하기에 조금 비싸다고 생각이 되었습니다.
어떻게 구성할까?
이미 팀에서 Kubernetes를 기반으로 기존 툴들을 직접 운영하고 있었기 때문에 조금만 더 학습해서 개발하면 ‘컬리만의 MLOps 플랫폼’을 만들 수 있을 것 같았습니다.
Kurly의 데이터 사이언티스트와 ML Engineer들의 니즈를 반영한 MLOps 플랫폼을 만들어보자!라는 목표를 세웠습니다. 자세한 환경 구축은 다음 편에서 더 다룰 예정입니다.
가장 먼저 진행했던 것은 자동으로 GPU Provisioning, Deprovisioning 하는 기본적인 구조를 만드는 것이었습니다. Jupyter Notebook을 생성할 때 GPU옵션을 설정하면 GPU 서버를 할당하고, 이것을 활용해 모델 학습 등에 사용하다가 노트북을 종료하면 GPU 서버가 Deprovisioning되는 구조를 기획했습니다. 이런 환경을 구축하기 위한 자료를 조사하고 개발하기 시작했습니다.
Karpenter?
그래서 도입하려고 찾아본 것이 Karpenter입니다. AWS에서 만들고 운영중인 프로젝트로 굉장히 활발하게 개발이 진행되고 있는 오픈소스입니다. AWS re:Invent 2021 행사에서 Karpenter v0.5이 정식으로 오픈되었고 GA(Generally Available)로 릴리스 되었습니다. 정식으로 오픈되었다는것은 이것을 가져다가 운영환경에서도 사용을 하는 것도 가능하다는 의미입니다. 적용해 볼만한 것이라고 생각이 되었습니다.
Karpenter는 ‘Kubernetes의 Worker Node 자동 확장 기능을 담당하는 오픈소스 프로젝트’라고 할 수 있는데, 기존의 Node 자동 확장(Auto Scaling)을 대체할 수 있습니다. 기존의 Auto Scaling과 비교하면 어떤 장점이 있었는지 알아보겠습니다.
Kubernetes의 장점, Node Auto Scaling
먼저 쿠버네티스에 대해서 간략하게만 알아보도록 하겠습니다. 쿠버네티스는 컨테이너 관리 플랫폼으로 빠른 배포와 뛰어난 확장성을 가졌습니다. 쿠버네티스를 활용하면 관리자 입장에서 편한 부분이 많지만, 운영쪽으로 신경써야하는 부분은 여전히 존재했기에 이 리소스를 줄여주는 것이 필요하게 됩니다. 그래서 AWS를 사용하시는 분들은 Managed Kubernetes 서비스인 EKS를 찾게됩니다.
Control Plane 운영 부담을 줄이는 것이 중요한데, 이를 위해서는 컨테이너 사용량에 따라 Computing Node를 빠르게 추가할 수 있는 탄력성(Elasticity)있는 컴퓨팅 자원이 필요합니다. 이 개념에 딱 맞는게 AWS에 이미 존재하는데 이것이 바로 EC2 인스턴스입니다.추가적인 노드가 필요할 때 Elastic한 컴퓨팅 자원인 EC2를 불러서 쿠버네티스 노드로 붙이는 것입니다. 그리고 여기에 Auto Scaling을 적극적으로 활용하면서 Worker Node의 운영 부담을 줄일 수 있게 되는 것이죠. 만약 EC2와 Auto Scaling이 없다면 리소스가 필요할때 일일이 노드를 늘려줘야하고, 리소스가 빠져나가면 노드도 줄여줘야 할 것입니다.
여기까지 읽으셨다면 Auto Scaling으로 충분하다고 느껴지실 것입니다. 그럼 Karpenter를 굳이 왜 적용했는지에 대한 의문이 생겨나기 시작합니다. 이제 그 이유를 차근차근 알아보겠습니다.
Why Karpenter?
Karpenter는 신규 배포될 pod를 지속적으로 체크하고 Worker Node가 부족하면 자동으로 Worker Node를 추가배포하고 확장하는 역할을 담당합니다. 추가적인 노드를 확장하는 것 뿐만 아니라, 불필요한 Worker Node도 정리하기도 합니다. 따라서, 노드의 비용 효율화와 운영 부담을 최소화 하기 위한 자동화 도구로 사용할 수 있게 되는 것입니다. 그런데 보아하니, Auto Scaling과 하는 역할이 똑같은 것 같습니다. 그렇다면 구체적으로 어떤 부분이 다른지에 대해서 알아보겠습니다.
기존의 Node Auto Scaling
기존의 노드 오토스케일링 방법은 “Cluster Auto Scaler(이후 줄여서 CA로 표기)“가 대표적입니다.
CA는 Cloud Provider(AWS, GCP)마다 구현방법이 다른데, AWS는 EC2 Auto Scaling Group을 사용하여 CA를 구현했습니다. AWS EKS는 “ASG(Auto Scaling Group)“와 “Launch Template”을 이용하여 worker node를 그룹핑하여 Node Group으로 관리하는 기능을 제공합니다. Worker Node는 ASG를 통해 확장하는 구조를 가졌으며 ASG를 CA가 컨트롤하게 됩니다.
Node Group의 자동 확장
AWS EKS를 사용했을 때의 노드 자동 확장하는 모습을 살펴보도록 하겠습니다. 가상 상황을 만들어보겠습니다. 현재 노드 내에 pod가 가득 찼고 더 이상 pod를 배포할 수 없는 상태가 되었고, 이 상황에서 신규 pod 생성 요청이 들어왔습니다. 더 세부적으로 예를 들어본다면 노드에 pod capacity가 꽉 찼는데 Airflow에서 KubernetesPodOperator를 사용한 Dag이 돌아가고 있는 경우라고 보면 되겠습니다.
이런 경우에 kube-scheduler는 신규 Pod를 배치할 적절한 노드를 선정하려고 합니다. 다양한 Label 정보와 가용량 등을 확인하면서 pod가 배치될 대상 노드를 필터링 하고 최종으로 자리잡을 노드를 선정하게 됩니다. 노드 선정 전까지는 Pod가 Pending상태 (Unschedulable) 입니다. 만약 여기서 적당한 노드가 없다면 실패(Failed) 상태가 됩니다. Pod 상태 확인 후 노드 선정에 실패하게 된다면 Node Group의 ASG값 중 Desired Capacity값을 하나 늘린 값으로 수정하게 되고, 워커 노드의 개수를 증가시킵니다.
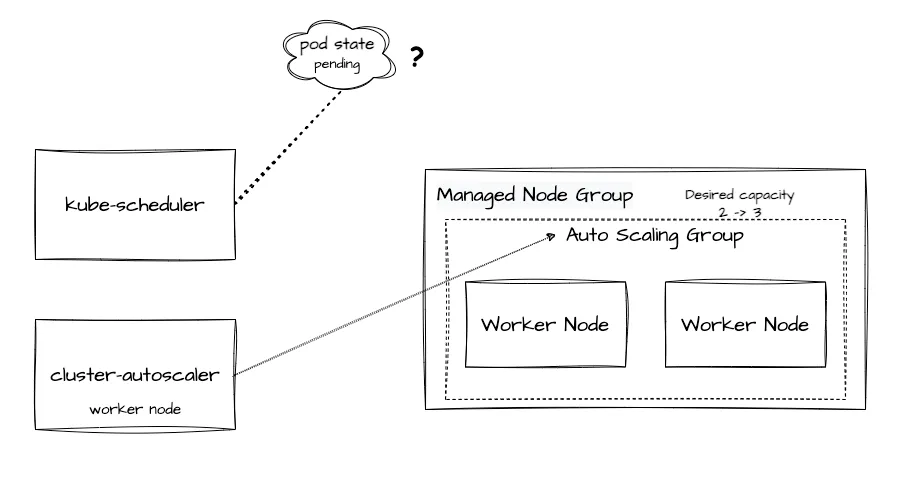
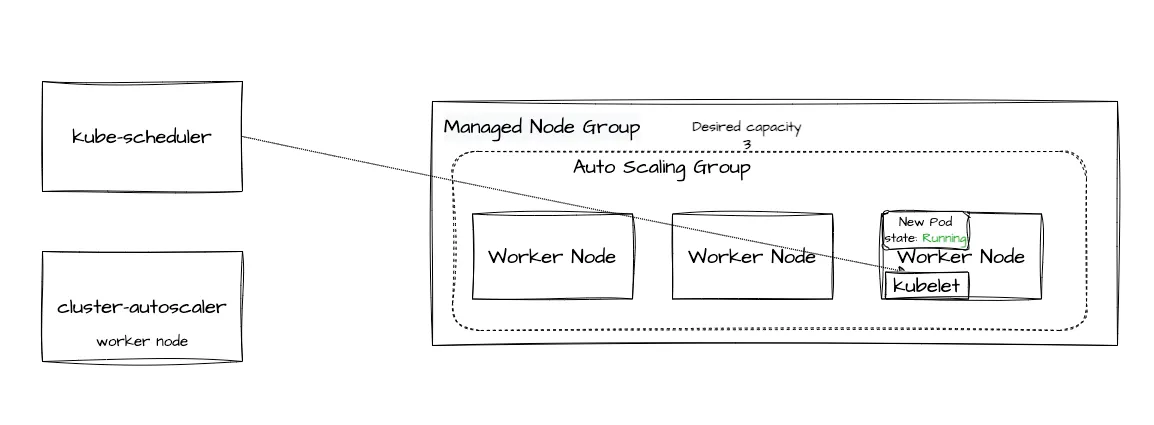
ASG는 변경된 desired capacity값을 읽고 EC2 워커 노드를 추가로 배포합니다. 이는 Kubernetes와는 무관하고, AWS의 ASG에 의해 실행된 작업입니다. EC2 AMI, Instance Type은 AWS에 정의된 Launch Template에 있는 내용을 따릅니다. 배포가 완료되어 Ready 상태가 되면 kube-scheduler는 배포되고 있지 못하던 pod를 새로운 워커 노드로 할당시킵니다. kube-apiserver에 해당 정보를 전달하고 kube-apiserver는 워커 노드에서 실행중인 kubelet에게 pod 배포 명령을 보내게 됩니다. 이로써 노드가 하나 더 생성되고 신규 Pod가 배포되었습니다.
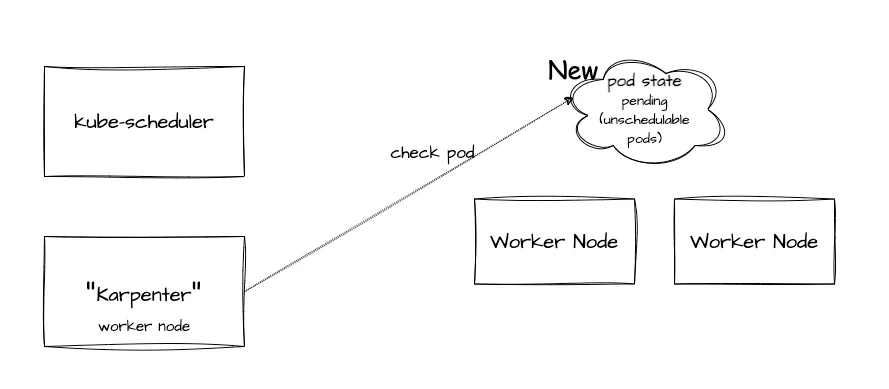
Karpenter의 동작방식
이번엔 Karpenter의 동작방식을 살펴보겠습니다. Karpenter는 ASG와는 다른 구조로 동작합니다. Karpenter는 AWS에서 개발은 했지만 Cloud Provider와 무관하게 동작 가능한 구조로 설계되어서 AWS외에 GCP나 Azure에서도 잘 동작합니다. Karpenter는 지속적으로 신규 pod의 상태를 확인하고 필요하다면 워커노드의 배포와 삭제도 직접 수행합니다. 그리고 kube-scheduler를 대신해 pod를 특정 워커 노드쪽으로 바인딩 하는 요청도 수행하기도 합니다.
Karpenter의 자동 확장
Karpenter의 노드 자동확장은 어떻게 진행될까요? 위와 같이 가용공간이 없는 상태에서 신규 pod생성 요청이 오는 동일한 상황을 가정해보겠습니다. kube-scheduler가 신규 pod 배치할 적정 노드를 선정하는 것, 그리고 필터링 하는 과정은 같습니다. Karpenter는 unschedulabel 한 pod를 프로비저닝 합니다.
Karpenter가 워커 노드를 선정하려 할 때 더 이상 가용할 수 있는 워커 노드가 없다면 노드를 생성하려고 합니다. 여기서 워커 노드를 생성할 때 어떤 인스턴스 타입을 선택해서 배포할 것인지는 Karpenter의 Custom Resource인 Provisioner에 의해서 결정됩니다. 이 Provisioner는 조금 이따 설명하도록 하겠습니다. Karpenter는 모든 워커 노드의 lifecycle을 결정하는데 Provisioner에 의해 새 노드가 배포된 이후에 Ready상태가 되면 karpenter는 직접 pod를 새로운 워커 노드에 배포될 수 있도록 바인딩 요청을 합니다. 이를 통해 새 파드가 새 워커노드에 배포가 되었습니다.
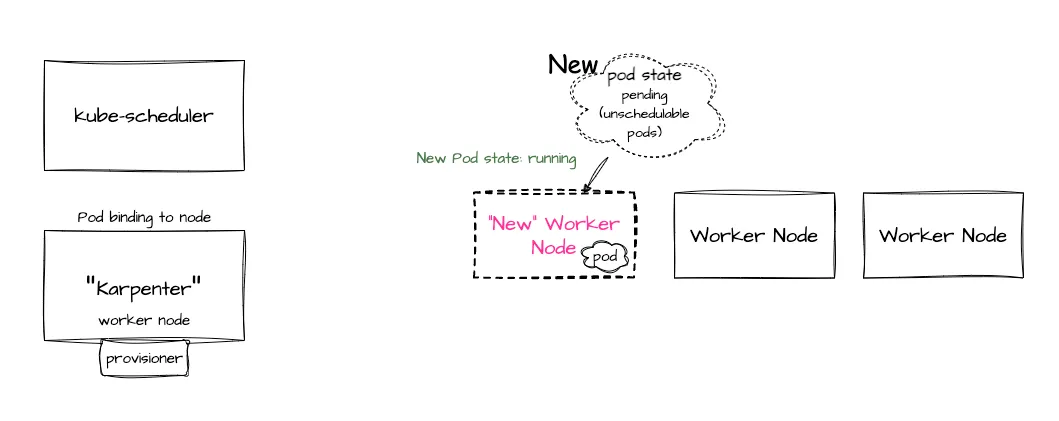
둘의 차이점?
둘의 차이점은 그럼 무엇일까요? CA(Cluster Auto Scaler)는 Auto Scaling 할 때 Cloud Provider가 제공하는 기능을 연계할 수 밖에 없습니다. 훨씬 더 많은 단계를 거쳐야 하기에 노드 확장이 느리고 번거로운 과정을 거치게 됩니다.
반면 Karpenter는 Auto Scaling 할때 일어나는 많은 부분을 직접 처리해버립니다. 이를 통해 기존 ASG대비 단순한 구조로 훨씬 빠르게 처리가 가능해집니다.
Karpenter의 주요 개념
Karpenter의 주요 개념을 4가지로 요약해 볼 수 있을 것 같네요.
- Watching : unschedulable한 pod를 계속 보고 있습니다.(파드 자체를 계속 체크)
- Evaluating : 스케쥴링 하는데 제약이 없는지를 확인합니다.
- Provisioning : 요구사항에 맞는 노드에 파드를 배포합니다.
- Removing : 더 이상 노드가 필요없다면 삭제합니다.
이런 개념을 살펴봤을 때, 무엇에 의해 노드가 생성되고 어떤 종류의 인스턴스일 것인지 등등을 결정할 무엇인가가 필요하다는 게 느껴지는데, 여기에 필요한 것이 바로 위에서 잠깐 짚고 넘어간 Provisioner입니다.
Provisioner
Provisioner는 Custom Resource에 대해 작성한 것으로서, 노드 프로비저닝에 제약사항이나 노드가 필요없다고 판단할 설정들과 timeout 설정과 같은 것들을 설정합니다.
- taints : 프로비저닝 된 노드들에 테인트를 정합니다. 파드가 taint에 대한 toleration이 맞지 않다면 taint에 설정된 대로 이벤트가 발생합니다. - NoSchedule, PreferNoSchedule, or NoExecute
- labels : 파드에 매칭될 수 있는, 임의의 key-value를 노드에 붙입니다.
- requirements : Acceptable한 것에 In, Unacceptable한 것에 Out을 설정합니다.
- limits : 클러스터에서 사용할 전체 CPU와 메모리의 제한을 설정합니다.
- 이 설정을 통해 노드 프로비저닝을 효과적으로 중지할 수 있습니다.
GPU가 달려있는 서버를 프로비저닝 하고 싶다면 Provisioner에 GPU requirements를 넣어줌으로써 본격적으로 GPU를 프로비저닝할 수 있게 됩니다.
Karpenter GPU 세팅 팁
NVDP
하지만 GPU노드가 프로비저닝 되었다고 해서 GPU를 바로 쓸 수 있지는 않습니다. 실제로 프로비저닝 된 노드에서 gpu학습을 하려고하면 제대로 되지가 않습니다. 그 이유는 바로 노드에 Nvidia 관련 세팅이 되어 있지 않기 때문입니다. NVIDIA device plugin for Kubernetes를 설치해줘야 합니다.
NVDP(NVIDIA device plugin for Kubernetes)
nvdp는 쿠버네티스에 데몬 셋으로 NVIDIA device plugin을 설치해줍니다. 이 데몬 셋은 계속해서 GPU가 달려있는 노드들이 있는지를 체크하다가 해당 노드가 들어오면 재빠르게 Plugin을 노드에 설치해줍니다. 그래서 만약 GPU노드로 학습을 하고 싶다면 전체적인 순서는 다음과 같습니다.
GPU를 통한 학습이 필요해 → Jupyter Notebook 생성 (GPU 할당 요청) → Karpenter를 통해 GPU 노드 생성 → NVDP 데몬 셋에서 플러그인 설치 → Nvidia plugin이 세팅된 GPU노드 등장 → GPU 학습 가능
Deprovisioning -1. Affinity
아직 다 끝난 것이 아닙니다. 앞서 말했듯이 원하는 구조는 학습이 끝났으면 Deprovisioning이 깔끔하게 되어야 하는 것입니다. GPU 노트북 사용을 중지하면 대부분 정상적으로 Deprovisioning 되지만, 가끔 노드가 제대로 삭제되지 않는 일이 발생합니다. GPU사용과 관련없는 파드가 GPU 노드에 할당된 경우 발생합니다. 한 클러스터 내에는 다양한 Application들이 배포되고 이 앱들은 파드로 할당되었다가 죽기를 반복합니다. 만약 파드가 죽었다가 다시 올라올 때 GPU노드쪽에 생성되면서 문제가 발생하는 것입니다. GPU노드에서 Notebook사용을 중지했다고 하더라도 다른 파드가 붙어있게 되면, Karpenter 는 이 노드는 사용 중인 것으로 판단하고 노드를 정리하지 않게 됩니다. 이런 상황을 방지하려면 GPU를 사용하지 않는 파드가 GPU노드로 할당되지 않도록 조치해야 합니다.
다행히도 노드에는 노드를 구분할 수 있는 이름표가 붙어있습니다. ‘Tag’와 ‘Label’입니다.

굉장히 다양한 label값들이 있습니다. 이 label값을 활용해보면 어떨까요? 파드가 생성되려 할때는 노드를 선택하려고 합니다. 이 때 gpu노드에만 있는 label이 있다면 파드들이 여기에 할당되지 않도록 하면 될 것 같습니다!
‘Label’을 이용하는 방법은 크게 두 가지가 있습니다. 위에서 봤듯이 특정 Label을 가진 노드에 파드가 할당되지 않도록 하는 방법과 특정 Label을 가진 노드에만 할당되도록 하는 방법이 있습니다. 전자에 해당하는 방법이 Anti Node Affinity이며, 후자에 해당하는 방법이 Node Selector, 그리고 Node Affinity 입니다. 두 방법은 구글에 검색하면 잘 나오는 내용이니 다음 링크를 참고하시면 좋을 것 같습니다.
Deprovisioning -2. Consolidation
Karpenter v.0.15.0부터 “Consolidation” 옵션을 사용할 수 있게 되었습니다. 문서를 보시면 다음과 같이 나와있습니다.
Consolidation: If enabled, Karpenter will work to actively reduce cluster cost by identifying when nodes can be removed as their workloads will run on other nodes in the cluster and when nodes can be replaced with cheaper variants due to a change in the workloads.
요약하자면 자동으로 노드 관리를 해주겠다는 것입니다. 하지만 기존에 karpenter를 사용하시던 분들이 이 ‘Consolidation’을 활성화 하려고하면 제대로 적용이 안되는 경우가 종종 있었습니다. 구글링을 해봐도 속시원한 답이 나오지 않아서 Kubernetes 슬랙 Karpenter채널에 직접 문의해봤습니다.

error validating data: ValidationError(Provisioner.spec): unknown field "consolidation" in sh.karpenter.v1alpha5.Provisioner.spec; if you choose to ignore these errors, turn validation off with --validate=false
위와 같이 계속해서 validation 에러가 발생한다면 CRD를 업그레이드 해야합니다. Karpenter 버전을 업그레이드 해서 배포했다 하더라도 Karpenter의 CRD는 이전 버전으로 남아있었기 때문에 consolidation이라는 옵션을 찾을 수 없었던 것입니다. 시간을 많이 잡아먹었던 에러라서 혹시 관련 에러로 고통스러워 하고 계신 분이 있다면 이 글이 도움이 될 수 있을 것 같네요!
앞으로…
지금까지 Karpenter 를 기반으로 GPU노드를 관리하기 위한 기본적인 환경구성을 마쳤습니다. 정말 기본적인 환경 구성을 위한, MLOps의 시작을 위한 단계였다고 생각합니다. 이렇게 구성된 환경을 기반으로 좀 더 편하고 훌륭하게 ML애플리케이션과 시스템을 만들어보려고 합니다. 현재는 작업공간을 만들어놓았다고 볼 수 있고 GPU operator와 taint/toleration을 자동설정해 주는 Adminssion Control을 적용해서 보완이 필요한 부분을 점진적으로 개선해 나갈 예정입니다.
Reference
-
https://kubernetes.io/ko/docs/concepts/scheduling-eviction/assign-pod-node/
-
Designing Machine Learning System, Chip Huyen 2022
-
Kubernetes Slack Channel