컬리에서 데이터 분석가로 일한다는 것
맛있는 데이터를 만드는 방법
 이민식
게시 날짜: 2022.02.15.
이민식
게시 날짜: 2022.02.15.
- [Step1] ‘무슨 말일까?’라고 생각하고 ‘요구사항 정리'라고 적는다.
- [Step2] 요구사항에 부합하는 데이터를 찾기 위해 질문하자
- [Step3] 기초부터 탄탄하게 시공을 하자
- [Step4] 데이터라고 다 같은 데이터가 아니다
- [Step5] 로직이 완벽하면 타이밍도 완벽해야지?
- [Step6] 어디 이상한 것 없나?
- 후기
안녕하세요. 데이터농장팀 이민식입니다.
데이터 맛집이라고 소문난 컬리에서 데이터 분석을 진행하는 과정을 이야기하려 합니다.
[Step1] ‘무슨 말일까?’라고 생각하고 ‘요구사항 정리'라고 적는다.
운영팀, 기획팀, 재무팀, 홍보팀 등 저희 데이터를 필요로 하시는 사내 고객님들은 매우 많습니다. 각 팀에서 데이터 관련 협조 요청은 모두 다른 방식, 다른 수준으로 주시기 때문에 고객님들이 원하는 의미를 파악해야 합니다.
🗣 컬리 사과 판매 대시보드가 필요합니다.
😺 ( select sum(판매금액) from 오더 where 상품명 = 사과)
어떤 용도로 사용하시나요?
🗣 센터 입고, 적치 공간 계산에 쓰려고 합니다.
😺 ( select 센터 , sum(판매금액판매수량 ) from 오더 where 상품명 = 사과 group by 센터 )
어떤 주기로 데이터를 확인하시나요?
🗣 하루에 한 번씩 확인합니다.
😺 ( select 일자 , 센터, sum(판매금액판매수량) from 오더 where 상품명 = 사과 group by 일자, 센터 )
처음부터 완벽한 요청은 없습니다. 스무 고개의 느낌으로 요청 팀과 소통하며, ① 사용목적 ② 사용주기 ③ 세부조건 등을 상세화합니다.
[Step2] 요구사항에 부합하는 데이터를 찾기 위해 질문하자
사용하고자 하는 데이터가 분석 용도로 준비가 되었다면, 바로 작업에 들어가면 되지만, 준비된 데이터가 없다면 데이터를 찾으러 나서야 할 때입니다. 사용자와 일상의 언어로 요구사항을 이해했다면, 이제 조건 하나하나를 정리할 수 있는 (준) 기계언어로 기획/개발팀과 소통해야 합니다.
😺 안녕하세요. 데이터 프로덕트 팀 이민식입니다.
상품 판매 대시보드를 만들기 위해서 SHPDH, SPHDI 테이블을 사용하고자 합니다.
데이터 사용 중 문의가 있어서 질문드립니다.① 상태 값 : CMS의 배송 완료 상태인데, FPK 상태를 가지고 있는 건, 어떤 경우일까요?
② 적재 : 한 시간 전에 적재 데이터 중 16xxx 주문은 현재 조회되지 않습니다. 왜일까요?
③ 조건 : CREDAT으로 데이터를 확인하니 당일 주문인지 어제 주문인지 확인할 수가 없습니다.
어떤 컬럼을 사용하면 좋을까요?
[Step3] 기초부터 탄탄하게 시공을 하자
필요한 데이터를 찾았다면, 이제 각 요소들을 분석용 테이블로 만들어야 합니다.
🤔 그냥 데이터를 바로 조회해서, 대시보드로 만들면 되지 않나요?
😺 넵, 안됩니다! 운영용 데이터는 시스템이 동작하기 위한 데이터이지 분석을 위한 데이터가 아닙니다.🤔 분석용 데이터라는 것은 무엇일까요?
😺 ① 데이터의 사용성이 보장되고 ② 퀄리티가 확보된 데이터를 말합니다.
데이터 사용성이 보장된다는 건, 운영계 데이터와 분석계 데이터를 분리시키는 것을 말합니다. 하나의 사례를 말씀드리면, 데이터 농장 팀에서는 재고 관련 데이터 프로덕트를 3개 운영하고 있었습니다. 당시 컬리는 새로운 가상 재고 시스템을 도입하기로 했고, 기존의 상품 KEY와 다른 KEY를 기준으로 재고 수량을 확인할 수 있는 구조로 변경될 예정이기 때문에 데이터 농장 팀에서도 이와 동일한 구조로 변경해야 했습니다. 저희는 분석계와 운영계를 분리시킬 수 있는 코어 테이블을 생성했고 코어 테이블을 Source로 기존 데이터 프로덕트의 사용성을 유지시켰습니다.
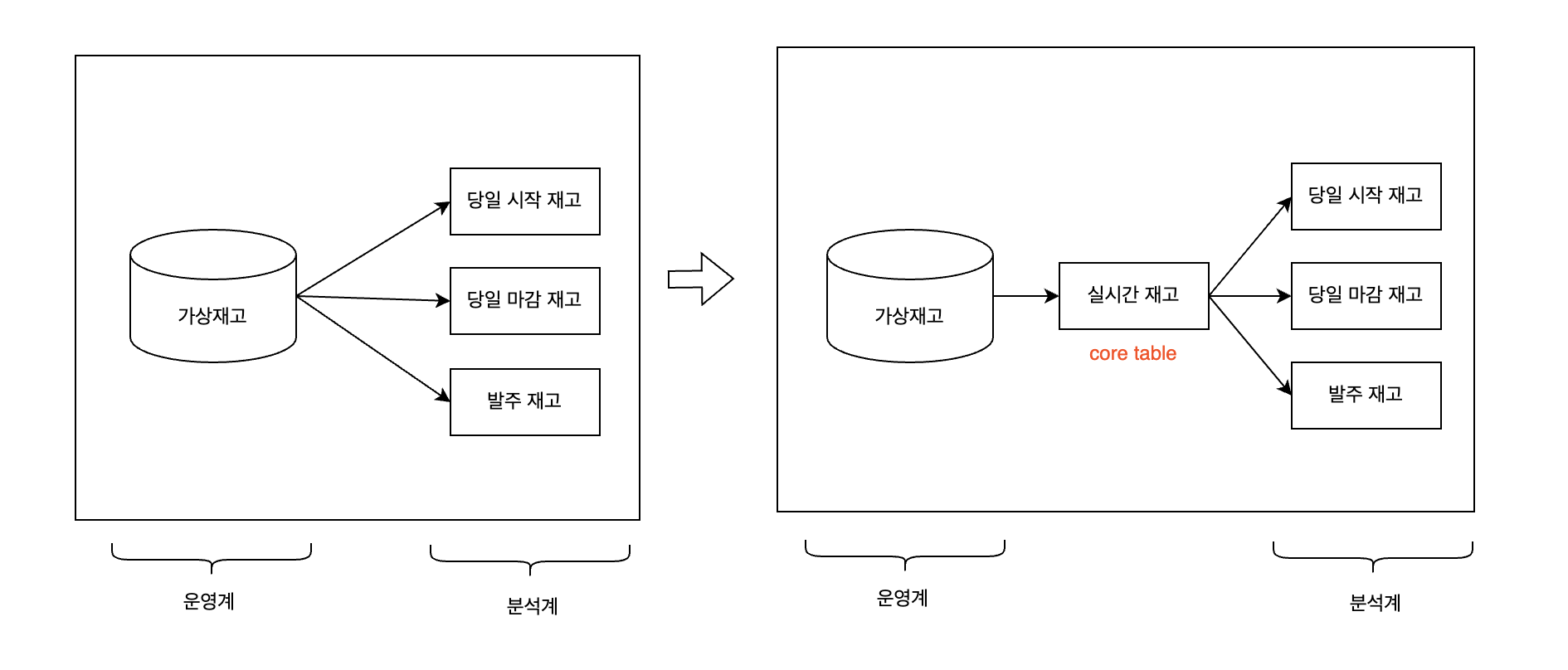
이러한 구조로 운영계 데이터와 분석계 데이터를 분리시킴으로써 시스템 변경에 대한 데이터 사용성을 유지시키고 체계적인 데이터 구조를 확보하였습니다.
[Step4] 데이터라고 다 같은 데이터가 아니다
퀄리티가 확보된 데이터는 “치열한" 데이터 QA 과정을 거친 후 탄생하는 산출물입니다.
데이터로 지표를 만들다 보면, 가끔 아주 놀라운 숫자를 만나게 됩니다.
😺 아니 왜 어제 똑같은 거리를 가는데,
A 기사님은 1시간 30분이 걸리는 걸 B 기사님은 2시간이 걸리지?
실제로 데이터를 확인해 보니 알 수 없는 이유(디바이스 고장 or 작업자 실수)로, 운행 완료 후에 도착이 찍혀야 하는데, 운행을 시작하자마자 도착이 기록된 데이터가 발생하였습니다. 분석 용도로 이상적인 테이블을 만들었다고 해서 모든 것이 해결되는 것은 아닙니다. 여러 가지 경우의 수가 있을 수 있기 때문에 철저한 검증을 해야 합니다. 이 과정은 보통 ‘전처리', ‘데이터 QA’라고 부르지요.
[Step5] 로직이 완벽하면 타이밍도 완벽해야지?

51,459건의 주문이 들어와 51,459건의 배송 완료가 되었습니다. 근데 출고 건수는 왜 이보다 9건 적은 51,450건일까요? 각 속성을 저장하는 테이블의 적재 배치 시간을 보면, 주문 완료는 23시(컬리 주문 마감시간) 배송 완료는 7시(컬리 배송 완료 시간) 출고는 X시(쉿! 비밀이에요)라서 X시로 적재 배치를 잡았었습니다. 실제로 현황을 확인해 보니 당일 출고 물량이 너무 많아서 일반적인 출고 완료 시간인 X 시간 보다 30분 늦게 출고된 상황에서 발생한 문제였습니다. 팀에서는 해당 문제를 인지하고 각 속성별 데이터 만들기 위해 약간의 버퍼를 두고 데이터를 적재했습니다.
퀄리티가 확보된 데이터를 만드는 건 꼼꼼한 QA를 통해 단단한 로직을 만드는 것뿐만 아니라 적절한 시점에 데이터를 조회해야 우리가 원하는 데이터를 얻을 수 있습니다.
[Step6] 어디 이상한 것 없나?
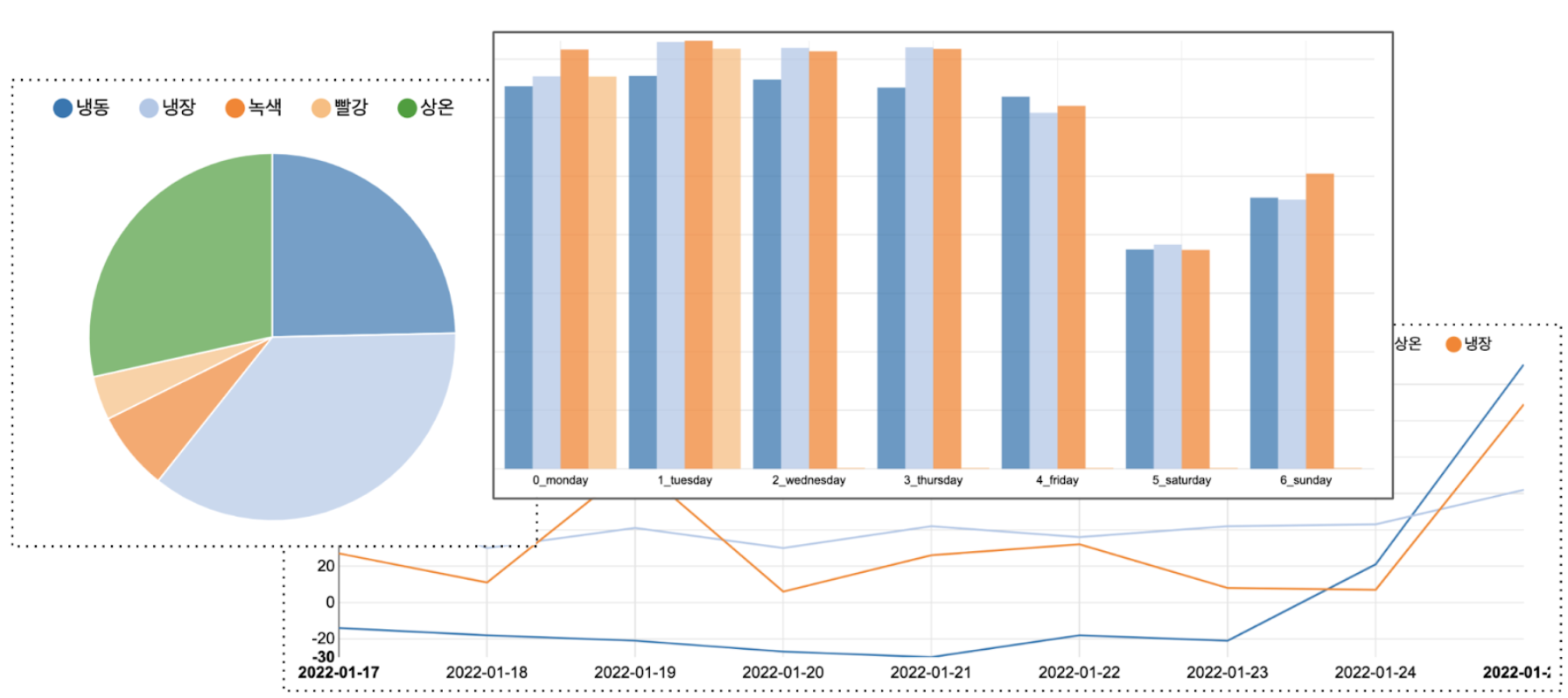
원하는 데이터를 모으기 시작했다면, 이제부터는 데이터를 활용할 타이밍입니다. 요구사항을 주는 부서에서 입맛을 맞췄다면 “프로젝트 끝?!” 이 아니라 우리에게는 데이터가 남아있기 때문에 본격적으로 데이터를 해부할 시간입니다. 대시보드를 만들어서 특이한 지점을 확인하고 분석하는 활동을 하기도 하고 새로 확보한 분석용 데이터를 사용해 다양한 시뮬레이션을 하기도 합니다. 하나의 사례를 말씀드리면, 컬리에서는 2020년 냉장 센터 이원화 작업을 했습니다. 당시 재고 운영의 핵심은 최적의 재고 운영 비율을 활용하여 센터 간 재고 이동을 최소화하는 것이었습니다. 데이터 농장 팀에서는 ① 최초 정책으로 설정된 재고 운영 비율과 ② 데이터 농장 팀이 새로 개발한 재고 운영 비율을 가지고 재고 시뮬레이션을 진행했습니다. 시뮬레이션 결과 새로 개발한 재고 운영 비율이 재고 이동에 더 효율적임을 확인했고 발주, 재고운영에 해당 비율을 사용했습니다.
후기
고객이 행동하는 순간부터 배송이 완료되는 모든 시점에 데이터가 쌓여있는 컬리는 데이터 분석가로서는 정말 다양한 걸 많이 경험해 볼 수 있습니다. 그 속에서 데이터 농장 팀은 경험과 직관에 의존해서 일하는 게 아니라 데이터를 기반으로 객관적인 수치로 일하고 있습니다. 저희는 다양한 데이터의 매력에 빠지실 데이터 팀원들을 기다리고 있습니다.