1. 서론
안녕하세요. 컬리 데이터서비스개발팀의 ML Engineer 윤준호입니다. 분명 ‘배송 완료’ 알림을 받았는데 문 앞이 텅 비어있거나, 다른 곳으로 잘못 배송되어 당황했던 경험이 한 번쯤 있으신가요?
컬리의 배송은 ‘정확성’이 곧 고객 경험과 비용으로 직결됩니다. 잘못된 주소지로 물건이 배송되는 경우 비용적 손실과 더불어 고객의 만족도를 떨어트릴 수 있습니다. 따라서, 배송 프로세스에서 실시간으로 오배송을 탐지하고, 빠른 피드백을 통해 오배송을 방지하는 작업이 필요합니다.
문제는 현재 컬리의 배송 프로세스에서 오배송이 전체 배송 건수 대비 매우 낮은 비율로만 발생한다는 점입니다. 비록 발생 빈도는 낮지만, 한 번 발생하면 비용이 크기 때문에 데이터 불균형을 극복하고 오배송을 찾아내는 방법이 필요합니다.
배송 과정동안 매니저분들의 스마트폰으로 여러 모달리티(이미지, GPS 좌표, 센서 정보 등)의 정보들이 수집되고 있습니다. 본 포스팅에서는 그 중 배송 완료 사진의 유사도를 기반으로 장소를 재인식(Re-Identification)하여 오배송을 탐지하는 방법에 대해 다뤄보고자 합니다.
2. 방법
2.1 배송 완료 사진의 품질 확보
배송 완료 사진의 유사도 비교가 유효하려면 이미지의 품질 확보가 필수적입니다. 배송 완료 사진은 매니저분들께서 배송을 마친 시점에 스마트폰으로 직접 촬영하여 취득하는데, 현재는 촬영 방식에 제약이 없기때문에 <그림 1>과 같이 비정상적인 사진이 취득되기도 합니다. 따라서 저품질의 노이즈 데이터를 필터링하여 배송 완료 사진의 품질을 확보하는 과정이 선행되어야합니다.

© 2026. Kurly. All right reserved.
2.1.1 비정상적인 배송 완료 사진 필터링 모델
배송 완료 사진의 품질 확보를 위해 정상/비정상 이진 분류 모델을 학습하였습니다. 배송과 무관한 피사체, 심하게 흔들린 사진 등 몇 가지 비정상 유형을 정의했습니다. 그리고 이를 바탕으로 정상 사진만 솎아내는 분류 모델을 개발하여, 이 필터링 과정을 무사히 통과한 데이터만을 오배송 탐지 로직에 활용하고 있습니다.
이 필터링 모델은 오배송 탐지의 전처리 단계로 개발되었으나, 최근 배송 완료 사진의 품질 관리 이슈가 부각됨에 따라 현재는 더 다양한 영역으로 활용 범위를 넓히고 있습니다. 이에 대한 상세한 내용은 다른 포스팅에서 다룰 예정입니다.
2.2 잠재 공간 표현간 유사도 비교
처음 문제 해결 방법을 고민할 때, 얼굴 재인식(Face Re-Identification) 문제와 동일한 방법으로 해결할 수 있을 것 같다는 생각을 했습니다. 얼굴 재인식은 컴퓨터 비전 AI가 카메라나 영상에 포착된 사람의 얼굴을 분석하여, “이 사람이 데이터베이스에 있는 누구인지” 혹은 “서로 다른 카메라/시간대에 찍힌 얼굴들이 동일 인물인지”를 판별하는 기술입니다. 여기서 “얼굴”만 “장소”로 바꿔서 “서로 다른 카메라/시간대에 찍힌 장소가 동일 장소인지“를 판별하는 기술로 접근해보기로 했습니다.
2.2.1 유사도 기반의 오배송 탐지
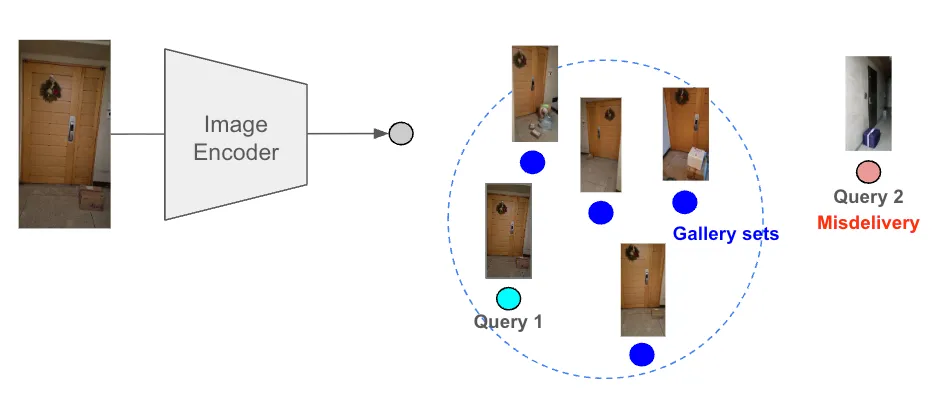
오배송 여부를 판별하려면 새로 찍힌 사진(Query Image)과 과거의 정상 배송 사진(Gallery Image)이 얼마나 비슷한지 비교해야 합니다. 이를 위해 인코더 모델로 두 이미지의 특징을 담은 임베딩(Embedding) 벡터를 추출하고, 잠재 공간(Latent Space) 상의 거리를 측정합니다. 앞으로 이 두 벡터를 각각 Query Embedding과 Gallery Embedding으로 부르겠습니다.
이미지 인코더는 기본적으로 유사한 이미지일수록 잠재 공간 내에서 서로 가까운 위치에 맵핑되도록 학습됩니다. 따라서 두 임베딩 벡터 간의 거리는 원본 사진들이 얼마나 유사한지를 나타내는 객관적인 지표가 됩니다.
결론적으로, 계산된 거리 값이 사전에 설정된 임계값(Threshold)을 초과할 경우, 시스템은 현재의 배송 환경이 과거의 정상적인 환경과 유의미하게 다르다고 판단하여 이를 최종적인 ‘오배송’으로 탐지하게 됩니다.
© 2026. Kurly. All right reserved.
2.2.2 학습: 임베딩 추출용 인코더의 Representation Learning
단순히 이미지를 벡터로 변환하는 것을 넘어, 잠재 공간 상에서의 거리 계산이 유의미하고 정확하게 작동하려면 기하학적 공간 자체를 최적화해야 합니다. 이를 위해 인코더 모델은 Centroid Triplet Loss를 사용한 대조 학습(Contrastive Learning)을 통해 학습되었습니다.
Centroid Triplet Loss는 개별 데이터 쌍이 아닌, 같은 클래스의 임베딩들이 이루는 ‘중심점(Centroid)‘을 기준으로 삼습니다. 데이터가 자신과 같은 클래스의 중심점을 향해서는 뭉치게 하고, 다른 클래스들의 중심점과는 멀어지도록 훈련시키는데, 이때 중심점과의 거리를 유클리디안 거리(L2 Distance)로 계산합니다. 다시 말해, 이는 잠재 공간 내에서 동일 장소 데이터 간의 군집도를 나타내는 클래스 내 거리(Intra-class Distance)는 줄이고, 서로 다른 장소 간의 여백을 의미하는 클래스 간 거리(Inter-class Distance)는 넓히는 방향으로 잠재 공간이 형성됨을 의미합니다. 따라서 이 손실 함수를 거쳐 학습된 모델은 유클리디안 거리를 통해 유사도를 비교할 때 가장 높은 정확도를 내는 잠재 공간을 갖추게 됩니다.
대조 학습과 더불어, 실제 배송 현장의 다양한 촬영 환경에 강건한 인코더를 만들기 위해, 학습 과정에서 밝기 및 조도 변화를 모사하는 데이터 증강(Data Augmentation) 기법을 적용했습니다. 이를 통해 인코더가 사진의 전반적인 밝기나 색감 같은 지엽적인 요소에 휘둘리지 않고, 현관문이나 주변 복도의 구조적 특징과 같은 장소 고유의 정보를 정확하게 추출하도록 유도했습니다.
결과적으로, 데이터 증강을 통한 전처리와 대조 학습을 통한 잠재 공간 최적화를 통해 인코더는 촬영 시점이나 각도, 조도가 제각각인 배송 현장일지라도 동일 주소지라면 유사한 임베딩을 추출할 수 있는 강건함을 가지게 됩니다.
추후 모델을 모바일 기기에 탑재하여 온디바이스(On-device) 추론까지 고려하고 있었기때문에, 낮은 계산 비용을 가지는 유클리디안 거리는 배터리 소모, 계산 속도면에서도 효율적이었습니다.
2.2.3 추론: 유클리디안 거리를 사용한 유사도 비교
학습 과정에서 유클리디안 거리(L2 Distance)를 기준으로 특정 장소의 임베딩들을 하나의 중심점(Centroid)으로 응집시키도록 설계되었으므로, 추론 단계에서도 이와 동일하게 해당 장소의 특성이 집약된 Gallery Embedding들의 중심점과 Query Embedding 사이의 유클리디안 거리를 계산하여 유사도를 판별합니다.
이러한 중심점 기반 추론 방식은 다음과 같은 기술적 이점을 가집니다:
-
대표성 기반의 강건한 판정: 개별 갤러리 사진들은 촬영 각도나 일시적인 장애물에 의해 노이즈를 포함할 수 있습니다. 하지만 해당 장소의 여러 임베딩 정보를 통합한 중심점과 비교함으로써, 특정 데이터의 편향(Outlier)에 휘둘리지 않고 해당 장소의 고유한 공간적 특징을 바탕으로 더욱 정확한 유사도 판별이 가능합니다.
-
연산 속도 및 저장 공간의 최적화: 수많은 Gallery Embedding을 모두 모바일 기기에 보관하고 일일이 비교하는 방식은 온디바이스 환경에서 큰 부담이 됩니다. 반면, 각 장소당 하나의 평균화된 중심점 벡터만 저장하고 비교하면 연산량이 획기적으로 줄어들어 온디바이스 환경에서의 배터리 소모와 메모리 점유율을 최소화할 수 있습니다.
-
새로운 배송지에 대한 Zero-shot 추론: 대조 학습(Contrastive Learning)은 단순히 특정 장소의 외형을 암기하는 것이 아니라, ‘같은 장소의 사진을 잠재 공간 내 동일한 구역에 매핑하는 방법’ 그 자체를 학습합니다. 덕분에 모델 훈련 과정에서 한 번도 본 적 없는 새로운 배송지라 하더라도, 소수의 과거 사진만 존재한다면 별도의 재학습 없이 즉각적으로 오배송 여부를 판별해 내는 강력한 제로샷(Zero-shot) 확장성을 제공합니다.
3. 실험
3.1 특징 추출을 위한 인코더 개발
본 절에서는 배송 완료 사진으로부터 오배송 탐지에 활용 가능한 특징을 추출하기 위해 이미지 인코더를 학습한 내용을 간단히 소개합니다.
3.1.1 실험용 데이터셋 구축
비정상 필터링 모델을 통과한 정상적인 배송 완료 사진들로 학습용 데이터셋을 구성했습니다. 주소당 10장씩 사진을 모았고, 주소지가 겹치지 않도록 train:val:test=8:1:1 비율로 학습 데이터를 분할하였습니다. Test셋은 학습되지 않은 주소지로만 구성되어 Zero-shot 성능을 측정할 수 있습니다.
3.1.2 학습 배치 구성: PK 샘플러(PK Sampler) 적용
대조 학습(Contrastive Learning)에서는 미니 배치 내에 동일 장소의 샘플이 충분히 포함되어야 유의미한 긍정 쌍(Positive Pair)이 형성되고 노이즈가 상쇄된 안정적인 중심점(Centroid)을 산출할 수 있습니다. 이를 위해 본 학습에서는 전체 데이터셋에서 무작위로 개의 장소를 고르고 각 장소당 개의 이미지를 추출하여 크기의 배치를 구성하는 PK 샘플러(PK Sampler)를 사용하여 미니 배치를 구성했습니다.
이 방식을 통해 매 배치마다 동일 장소의 이미지가 장씩 보장되므로, 특정 아웃라이어(Outlier)에 편향되지 않은 대표 중심점을 바탕으로 안정적인 대조 학습이 가능해집니다. 또한, 한 배치 내에 동일 장소의 다양한 환경(조도, 각도 등)이 포함된 샘플들이 묶이면서 표면적인 픽셀 차이를 극복하는 모델의 강건성(Robustness)도 자연스럽게 향상됩니다.
3.1.3 미니 배치 내 Hard Negative Mining
PK 샘플러로 긍정 쌍을 확보한 후에는 모델의 변별력을 극대화하기 위해 Hard Negative Mining 기법을 적용했습니다. 이는 배치 내에 존재하는 다른 장소 샘플 중 학습에 기여하지 못하는 쉬운 샘플(Easy Negative)을 배제하고, 기준 장소(Anchor)의 중심점과 잠재 공간상 가장 가까워 모델이 혼동하기 쉬운 어려운 샘플에 집중하여 페널티를 부여하는 방식입니다.이를 통해 전체적인 학습 수렴 속도가 비약적으로 향상되며, 비슷한 현관문이나 복도처럼 시각적으로 유사하지만 물리적으로 다른 장소 간의 미세한 차이(Fine-grained Feature)를 구분하는 정교한 변별력을 갖추게 됩니다.
3.1.4 잠재 공간에서의 거리 분포 분석
앞서 설명한 방식으로 인코더를 학습한 뒤, 같은 장소에서 찍힌 사진들끼리는 잠재 공간에서 가깝게 모이고, 다른 장소 사진들과는 멀어지도록 잘 학습되었는지 확인하기 위해 3.1.1에서 구축한 데이터셋 중 test 세트를 대상으로 임베딩 간 거리 분포를 분석했습니다.
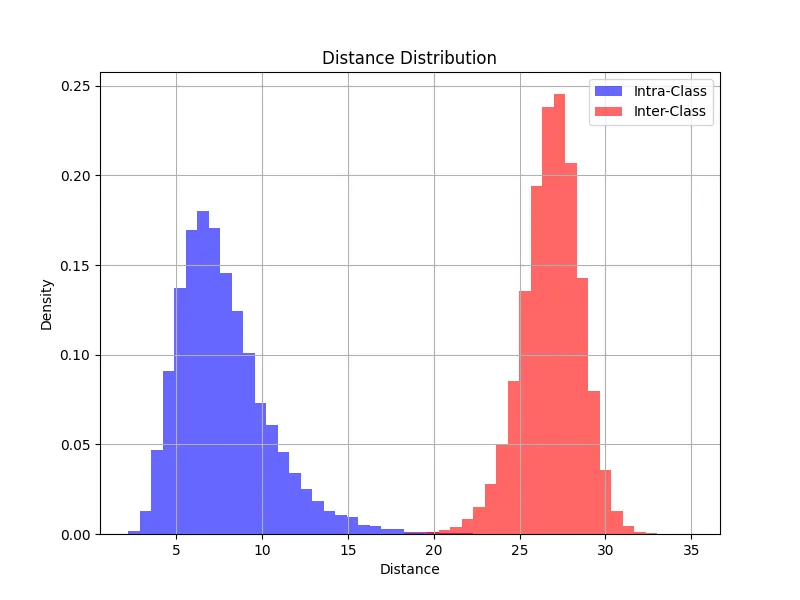
<그림 3>의 거리 분포를 살펴보면, 동일 주소(정상 배송)에서 얻어진 임베딩 거리(intra-class distance)는 주로 작은 값 구간에 밀집되어 있고, 다른 주소(오배송으로 간주)에서 얻어진 임베딩 거리(inter-class distance)들은 상대적으로 큰 값 구간에 분포해있습니다. 이처럼 두 유형의 거리 분포가 뚜렷하게 갈리는 덕분에, 잠재 공간 상에서도 서로 명확히 분리된 두 개의 군집이 형성됨을 확인할 수 있습니다. 이는 곧 “단일 거리 임계값(threshold)만으로도 정상 배송과 오배송을 효과적으로 구분할 수 있는 잠재 공간이 형성되었다”는 것을 의미합니다.
© 2026. Kurly. All right reserved.
3.1.5 거리 임계값(threshold)에 따른 오배송 분류 성능
거리 분포 분석으로 정상·오배송 샘플이 잠재 공간에서 잘 분리된다는 것을 확인한 뒤, 구체적인 거리 임계값(threshold) 을 적용했을 때 어떤 이진 분류 성능을 보이는지 평가했습니다.
만약 임계값을 18.0을 기준으로 정상 배송과 오배송을 구분한다면, 주요 분류 지표는 다음과 같이 측정되었습니다.
-
Accuracy: 99.95%
-
Precision: 99.97%
-
Recall: 99.97%
-
F1 score: 99.97%
한편, AUC(Area Under the ROC Curve)를 계산했을 때에도 99.99% 라는 높은 수치가 나왔는데, 이는 인코더의 성능이 특정 threshold에만 최적화된 것이 아니라, 전반적인 거리 기반 분류력을 가지고 있음을 보여줍니다.
요약하면, 학습된 인코더와 threshold = 18.0 조합만으로도 정상 배송과 오배송을 분류할 수 있는 잠재 공간이 형성되었음을 확인할 수 있습니다.
3.1.6 Zero-shot 일반화 성능 정리
앞서 3.1.4와 3.1.5에서 사용한 test 데이터는 학습/검증 데이터와 주소 단위로 완전히 분리된 데이터입니다. 즉, test 세트에 포함된 모든 주소지는 학습 과정에서 한 번도 본 적 없는 새로운 배송지입니다.
이런 데이터 분할 방식 덕분에, 3.1.4에서의 거리 분포와 3.1.5에서의 분류 성능은 단순한 “테스트셋 성능”을 넘어, 다음과 같은 Zero-shot 일반화 능력을 직접적으로 보여줍니다.
-
단순 암기가 아닌 ‘군집화 규칙’ 학습: 모델은 특정 주소 사진의 외형을 단순히 외우는 것이 아니라, “같은 장소의 사진들을 잠재 공간(Latent Space) 내 동일한 구역으로 모으는 보편적인 특징 추출 규칙”을 학습했습니다.
-
새로운 주소지에 대한 Zero-shot 추론: 학습하지 않았던 완전히 새로운 주소지라 하더라도, 해당 장소의 배송 완료 사진 몇 장으로 갤러리셋만 구성해 두면 곧바로 오배송 여부 판별이 가능합니다.
-
뛰어난 운영 확장성(Scalability): 실제 서비스 운영 중 새로운 배송지가 지속적으로 추가되더라도, 모델의 재학습 없이도 즉시 높은 수준의 오배송 탐지 시스템을 지속할 수 있음을 의미합니다.
4. 서비스 적용
4.1 갤러리셋 임베딩 관리
실시간 추론 시점에 매번 과거 배송 완료 사진의 임베딩을 새로 추출하는 것은 연산 비용과 처리 속도 측면에서 매우 비효율적입니다. 따라서 사전에 추출한 과거 사진의 임베딩을 데이터베이스(DB)에 모아두고, 추론시에 Gallery Embedding으로 참고할 수 있도록 시스템을 설계했습니다.
4.1.1 일배치 기반 갤러리셋 임베딩 적재 파이프라인
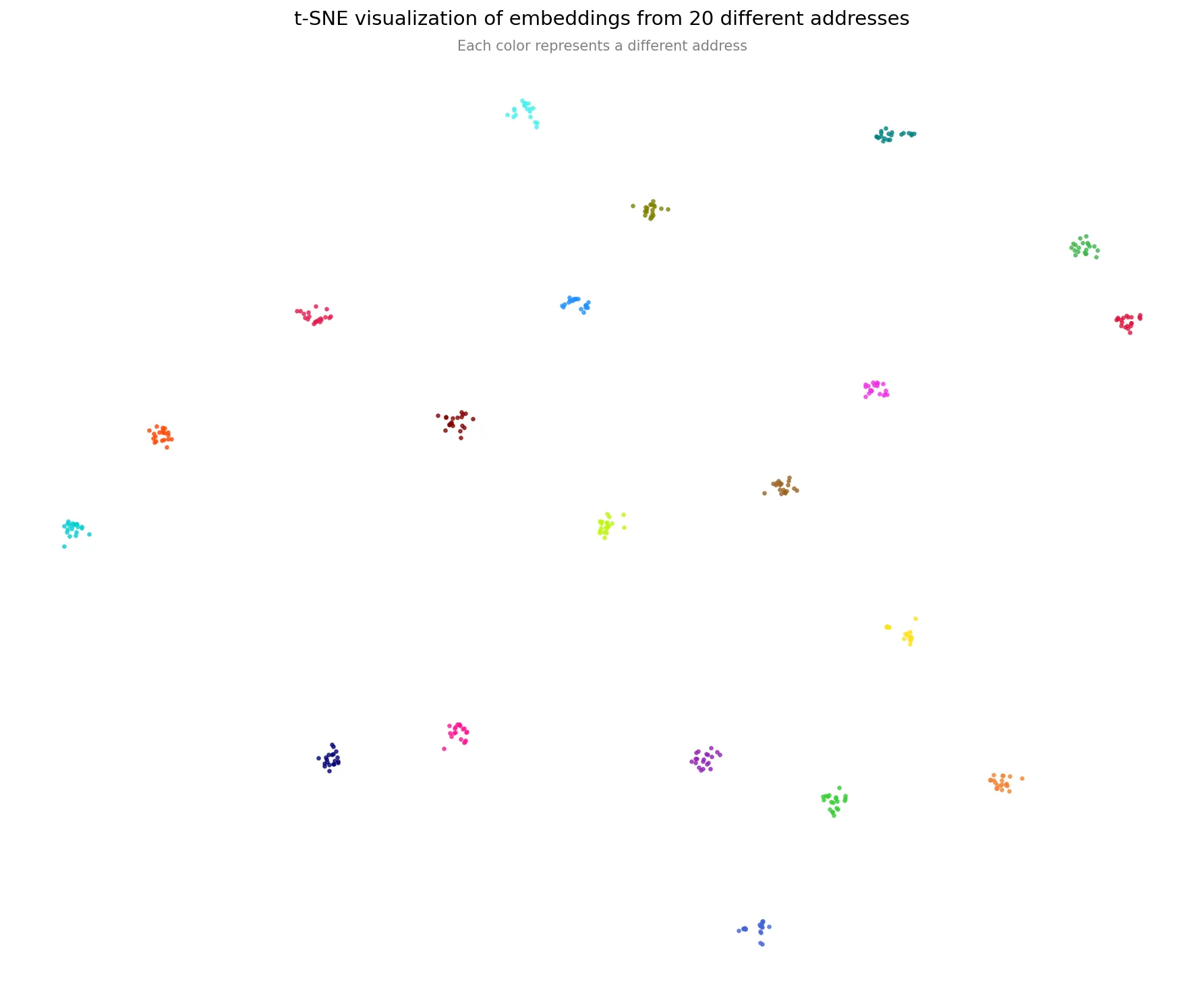
운영 환경에서는 매일 새로 쌓이는 배송 완료 사진들을 갤러리셋으로 반영하기 위해 Airflow 기반의 일배치 파이프라인을 구성했습니다. 비정상 배송 완료 사진 필터링 모델을 사용하여 전일 배송된 모든 건에 대해 정상적인 배송 완료 사진만 선별한 뒤, 임베딩을 추출하여 원본 이미지 정보, 배송 완료 시각, 주소지 정보 등과 함께 document 형태로 가공합니다. 이렇게 가공된 임베딩 및 메타 정보는 AWS DocumentDB에 적재되어, 이후 오배송 탐지 시 참조할 수 있는 형태로 관리됩니다. DB 비용 및 계산 효율성을 고려하여 주소당 최신순으로 최대 20개의 이력을 저장하도록 하였습니다. <그림 4>는 DocumentDB에 적재된 데이터 중, Gallery Embedding이 최대로 확보된 배송지 20곳을 무작위로 추출해 t-SNE로 시각화한 결과입니다. 서로 다른 색깔은 서로 다른 주소지를 의미합니다. 의도한 대로 동일 주소의 임베딩들은 각각의 중심점(Centroid)을 향해 조밀하게 응집되어 있으며, 서로 다른 주소 간에는 명확한 거리를 두며 분리된 모습을 보입니다.
© 2026. Kurly. All right reserved.
4.1.2 DocumentDB를 활용한 갤러리셋 조회 및 관리
주소지 단위의 신속한 임베딩 벡터 조회와 메타 정보의 통합 관리를 위해 DocumentDB를 도입했습니다. 배송 완료 사진마다 임베딩 벡터와 주소지 등 메타데이터를 하나의 Document로 묶어 저장합니다. 주소지 필드에 인덱스를 걸어두었기 때문에, 단일 쿼리만으로 원하는 주소지의 Gallery Embedding 전체를 즉시 조회할 수 있습니다. 별도의 조인이나 후처리 라운드트립이 없어 신규 사진의 거리 비교 단계에서 일관되게 낮은 지연 시간을 유지할 수 있습니다.
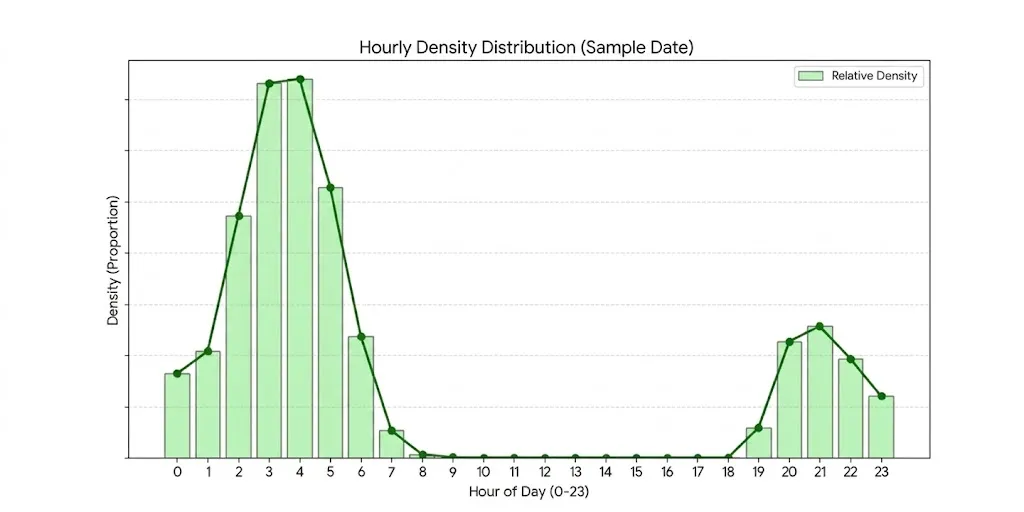
<그림 5>는 어느 날 시간대별 배송량을 밀도로 나타낸 그래프입니다. 이 그래프에서 볼 수 있듯이 현재 컬리의 배송은 특정 시간대에 트래픽이 집중되는 경향이 있습니다. 따라서 급격한 트래픽 변동에 유연하게 대응하고자 DB Cluster를 서버리스 인스턴스로 구성함으로써, 피크 시간대의 안정성과 유휴 시간대의 비용 효율성을 동시에 확보했습니다.
© 2026. Kurly. All right reserved.
4.1.3 어플리케이션의 실시간 임베딩 조회 파이프라인
<그림 6>은 실제 서비스 환경에서 오배송 판별을 위해 앞서 구축한 DocumentDB로부터 Gallery Embedding을 조회하는 전체 아키텍처 흐름입니다. 배송매니저분의 배송 업무 지원을 위한 모바일 배송 앱(컬리버드:KurlyBird), 갤러리셋 임베딩이 저장되는 Document DB, 그리고 이 둘간의 중간 다리 역할을 하는 오배송 API 서버 간의 데이터 흐름은 아래와 같습니다.
-
배송지 할당 및 Centroid 요청(KurlyBird → API Server): 배송매니저가 물류 센터에 도착하면, 다음 배송할 상품들의 주소지 목록을 할당받게 됩니다. 상품들을 차량에 싣는 상차 과정과 동시에, 모바일 앱은 할당된 배송지 목록을 API서버로 전송합니다.
-
DB 조회 및 Centroid 계산(API Server <→ AWS DocumentDB): API 서버는 전달받은 주소별로 DocumentDB에서 Gallery Embedding들을 불러오고, 임베딩을 평균내어 주소지별 Centroid를 계산합니다. 앞서 4.1.2에서 언급한 인덱스 최적화 덕분에 다수의 주소지 정보도 지연 없이 즉시 검색됩니다.
-
Centroid 리스트 전달 및 추론(API Server → KurlyBird): API 서버는 계산된 주소지별 Centroid 리스트를 KurlyBird에 최종 전달합니다. 배송매니저가 배송지에 도착하여 배송 완료 사진을 촬영하면, KurlyBird는 이 리스트를 활용해 방금 촬영된 배송 완료 사진의 임베딩과 거리를 비교하고 즉각적으로 오배송 여부를 판별하게 됩니다.
결과적으로 무거운 이미지 임베딩 추출은 Airflow 기반의 일배치(daily DB updater)로 미리 처리하고, 실시간 서비스 영역에서는 최소한의 모델 추론 및 벡터 거리 계산만 수행하도록 역할을 완전히 분리함으로써 실시간 추론시 계산 비용을 최소화할 수 있었습니다.

© 2026. Kurly. All right reserved.
4.2 ONNX 기반의 On-device 추론
오배송 탐지를 위한 인코더 모델을 ONNX 파일로 배포하여, KurlyBird 개발팀에 전달하였습니다. 해당 ONNX 파일을 사용하여 별도의 추론 전용 서버없이 배송매니저분들의 모바일 기기에서 On-device 추론이 가능하도록 하였습니다.
4.2.1 ONNX 파일 배포
4.1절에서 설명한 것처럼 Gallery Embedding은 서버(Airflow)에서 추출되지만, 실시간 추론 시 Query Embedding 추출은 모바일 기기에 탑재된 ONNX 모델을 통해 이루어집니다.
이때 가장 중요한 점은 서로 다른 플랫폼에서 추출된 임베딩 간의 거리 비교가 유효해야 한다는 것입니다. 즉, 서버의 Python 환경과 모바일의 On-device 환경에서 동일한 이미지에 대해 동일한 임베딩 값을 얻어야 합니다.
이미지 전처리 과정은 사용하는 라이브러리나 플랫폼별 연산 방식에 따라 미세한 결과 차이를 보입니다. 특히 특정 라이브러리를 사용할 수 없어서 로직을 직접 구현할 경우, 이러한 미세 오차는 모델 추론 과정에서 증폭되어 최종 임베딩 출력값에 유의미한 변동을 일으키는 원인이 됩니다. 이를 방지하기 위해 이미지 전처리부터 임베딩 추출 직전까지의 모든 과정을 하나의 End-to-End ONNX 파일로 패키징하여 배포했습니다.
이러한 접근을 통해 다음과 같은 이점을 얻을 수 있었습니다:
-
환경 간 오차 제거: 전처리 로직이 ONNX파일 내부에 포함되어 있어, 플랫폼에 관계없이 동일한 추론 결과를 보장합니다.
-
배포 및 사용성 극대화: 모바일 앱(KurlyBird) 측에서는 복잡한 전처리 코드를 별도로 구현할 필요 없이, 원본 이미지만 입력하면 즉시 임베딩을 얻을 수 있는 단순한 구조를 갖추게 되었습니다.
4.2.2 On-device 추론 구조
KurlyBird 앱은 설치 또는 업데이트 시점에 인코더 ONNX 모델을 로컬에 캐시하며, 배송 현장에서 발생하는 모든 추론 과정을 단말 내부에서 독립적으로 처리합니다. 세부적인 동작 메커니즘은 다음과 같습니다.
-
로컬 임베딩 추출: 배송 완료 사진이 촬영되는 즉시, 단말 내에 탑재된 ONNX 인코더를 통해 Query Embedding을 추출합니다.
-
거리 계산 및 판별: 추출된 Query Embedding과 서버로부터 받아놓은 Centroid간의 거리를 계산합니다. 이후 사전에 정의된 임계값(Threshold)을 기준으로 오배송 여부를 즉시 판별합니다.
이러한 온디바이스 추론 구조는 다음과 같은 강력한 이점을 제공합니다.
-
네트워크 독립성: 통신 환경이 불안정한 배송 현장(지하 주차장, 엘리베이터 등)에서도 모델 추론과 거리 계산이 끊김 없이 이루어지므로, 네트워크 지연 없는 실시간 피드백을 보장합니다.
-
인프라 비용 및 관리 최적화: 모든 추론이 기기 내에서 완결되어 별도의 추론 서버를 구축하거나 운영할 필요가 없습니다. 이미지 업로드와 서버 측 GPU 연산을 생략함으로써 트래픽 집중을 고려한 인프라 스펙 산정 및 확장성 고민에서 자유로워졌으며, 결과적으로 연산 비용과 관리 리소스를 획기적으로 절감했습니다.
4.3 리스크 관리 및 안정성 확보
실제 운영 환경(Production)에서 모델을 배포하고 안정적으로 운영하기 위해, 발생 가능한 주요 리스크를 정의하고 이를 기술적으로 보완하기 위한 내용을 소개합니다.
4.3.1 대응 채널별 알럿(Alert) 이원화 전략: Precision vs Recall
오탐(False Positive)으로 인한 현장의 부작용을 최소화하고 비즈니스 효율을 극대화하기 위해, 오배송 알럿 체계를 두 가지 채널로 이원화하고 각기 다른 전략을 고려할 수 있습니다. Precision과 Recall은 상충 관계(Trade-off)에 있으므로, 서비스 목적에 맞춰 유사도 거리의 임계값(Threshold)을 전략적으로 조정함으로써 이를 최적화합니다.
- On-device 직접 알림 (Precision 최우선): 배송 매니저의 앱 화면에 즉시 경고를 띄우는 채널입니다. 여기서는 정밀도(Precision)가 가장 중요합니다. 정상 배송임에도 오배송 알럿이 빈번하게 발생하면 매니저의 업무 흐름이 끊기고, 결국 알럿을 대수롭지 않게 여기는 ‘양치기 소년’ 현상이 발생할 수 있습니다. 따라서 유사도 거리의 임계값을 보수적으로 높게 설정하여 확실한 오배송 건만 알림을 주도록해야합니다. 또한, 오탐이 지속되어 현장의 피로도가 증가하는 상황에 대비하여 시스템의 개입 강도를 유연하게 조절할 수 있어야 합니다.
- 운영팀 슬랙(Slack) 알럿 (Recall 우선): 오배송으로 의심되는 건을 슬랙 채널로 전송하면, 백오피스 운영팀이 과거 배송 완료 사진과 육안으로 비교·검토한 뒤 조치를 취하는 방식입니다. 이 채널은 비즈니스 손실을 막기 위해 실제 오배송 건을 최대한 누락 없이 포착(Recall 우선)하는 것을 목표로 하되, 운영팀의 검토 리소스가 허용하는 범위 내에서 임계값을 설정합니다.
- 하이브리드 운영 전략: 앞선 두 채널을 결합하여 장점만을 취하는 방식입니다. 유사도 거리에 따라 다단계 임계값을 설정하여, 거리가 아주 멀어 오배송이 확실한 건은 운영팀의 리소스 투입 없이 On-device에서 즉시 처리합니다. 반면, 오배송 여부가 애매한 중간 거리 구간의 데이터만 슬랙으로 전송하여 운영팀이 검수하도록합니다. 이를 통해 On-device 단일 채널 운영 대비 Recall을 높이면서도, 운영팀 단독 검수 대비 운영 리소스와 검수 피로도를 줄일 수 있습니다.
4.3.2 프라이버시 보호 및 데이터 비가역성
일반적으로 On-device AI는 원본 데이터가 기기 외부로 전송되지 않고 단말기 내부에서 모든 추론 연산이 완결되므로 개인정보 보호에 매우 강력한 이점을 가집니다. 나아가 서버와 주고받거나 DB에 저장하는 과거 배송 이력 데이터 또한 원본 이미지로 역산할 수 없는 비가역적인 숫자 배열(Embedding Vector) 형태만을 사용하므로 프라이버시 침해 가능성을 구조적으로 방지할 수 있습니다.
5. 향후 확장성 및 레퍼런스로서의 가치
5.1 조직 및 플랫폼 레벨의 표준 아키텍처 제시
본 프로젝트에서 구축한 ‘임베딩 추출 + 잠재 공간 상 거리 비교 + On-device AI 추론’ 파이프라인은 단일 기능 개발을 넘어, 향후 사내의 다양한 비전 AI 과제에 즉시 이식할 수 있는 표준 아키텍처 레퍼런스로서의 가치를 가집니다.
5.1.1 물류 자동화 도메인으로의 확장 가능성
컬리의 물류 도메인에는 오배송 탐지와 유사하게 “압도적인 정상 데이터 속에서 극소량의 이상치(Anomaly)를 실시간으로 찾아내야 하는” 니즈가 매우 많습니다.
물류 센터 내 상품 파손 및 오염 탐지, 패키징 상태 검수, 배송 차량 외관 이상 탐지 등은 불량 데이터를 사전에 대량 확보하기 어렵습니다. 본 아키텍처는 정상 데이터 확보만으로도 사전에 정의되지 않은 다양한 유형의 이상을 잠재 공간 상의 거리로 판별하여 물류 현장에 최적화된 솔루션을 제공할 수 있습니다.
또한 On-device AI로 모든 추론을 단말기 단에서 처리함으로써, 어플리케이션 및 각종 Edge device들과 유기적으로 연동되어 중단 없는 자동화 프로세스 구축에 기여할 수 있습니다.
이 글을 마치며
본 프로젝트에서 PM의 역할을 수행해주신 컬리넥스트마일 강선보님, 성현창님 감사드립니다.
컬리버드 개발을 담당해주신 류충근님, 정석원님 감사드립니다.
갤러리셋 적재 파이프라인의 시간 효율 개선에 대해 조언을 주신 이봉호님 감사드립니다.
Document DB 사용을 추천해주신 김학철님 감사드립니다.
데이터 저장 관련 조언을 주신 박대성님 감사드립니다.
API 서버 서빙에 조언을 주신 한수진님 감사드립니다.
API 서버를 앞으로 고도화해주실 손성훈, 김수지님 미리 감사드립니다.
Reference
- Schroff, Florian, Dmitry Kalenichenko, and James Philbin. “Facenet: A unified embedding for face recognition and clustering.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
- Wen, Yandong, et al. “A discriminative feature learning approach for deep face recognition.” European conference on computer vision. Cham: Springer International Publishing, 2016.
- Deng, Jiankang, et al. “Arcface: Additive angular margin loss for deep face recognition.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019.
- Wieczorek, Mikołaj, Barbara Rychalska, and Jacek Dąbrowski. “On the unreasonable effectiveness of centroids in image retrieval.” International Conference on Neural Information Processing. Cham: Springer International Publishing, 2021.
- Gouda, Anas, et al. “Learning embeddings with centroid triplet loss for object identification in robotic grasping.” 2024 IEEE 20th International Conference on Automation Science and Engineering (CASE). IEEE, 2024.