안녕하세요? 데이터사이언스팀 송훈화입니다.
저는 아래 2가지 목적을 가지고 이번 포스트를 작성하였습니다.
- 데이터사이언스팀은 채용을 진행하고 있습니다.
- 팀의 주요 업무를 소개하고 문화도 같이 소개합니다.
- 저희 팀에서 같이 문제를 풀어가고자 하시면 아래 링크를 통해 적극적인 지원 부탁드리겠습니다.
- 모델을 개발하고 운영하면서 그 과정에서 배운 점과 경험을 공유하고자 합니다.
- 이미 모델 개발 측면(알고리즘, feature engineering, validation, parameter tuning 등)의 방법론은 책이나 블로그를 통해 많이 공유되고 있습니다.
- 반면에 모델을 비즈니스 현장에 적용하는 과정에 대한 경험이나 과정은 많지 않은 것 같습니다.
- 이번 포스트에서는 모델 개발후 실제 현장에 모델을 배포/운영하는 과정을 중심으로 기술하였습니다.
1. 데이터사이언스팀을 소개합니다.

- 위 캐릭터는 데이터농장 마스코트인 데박이입니다.
- 데이터농장이라는 상위 조직에 데이터사이언스, 데이터거버넌스, 데이터프로덕트 팀이 속해있습니다.
- 데이터사이언스팀은 수요예측/최적화모델, 추천/랭킹모델를 개발하고 운영함으로써 비즈니스에 다양한 방식으로 기여하고 있습니다.
- 수요예측모델을 통해 미래에 발생할 수요를 예측하여 주문/배송/발주에 활용하는 리소스를 효율적으로 투입하도록 의사결정을 지원합니다.
- 추천/랭킹모델을 통해 고객의 선호와 행동을 예측하여 고객에 접근하는 활동을 최적화하고 유저경험을 개선하도록 노력합니다
- MLOPS를 통해 모델을 안정적으로 운영하고 서빙하는 기반을 마련하고 있습니다.
1.1 수요예측모델 개발 및 운영은 팀의 핵심 업무입니다.
- 컬리의 물류 조직은 새벽배송이라는 핵심가치와 서비스를 고객에게 제공하기 위해 많은 리소스를 사전에 준비하고 이를 적재적소에 투입하고 있습니다.
- 고객이 주문한 대로 상품을 분류/포장/배송 등의 프로세스를 진행하기 위해 많은 인력과 리소스를 투입합니다.
- 예측을 기반으로 상품을 적시에 발주하고 적정 재고량을 유지하며, 박스/드라이아이스와 같은 부자재를 충분히 확보하여 배송 준비를 합니다.
- 데이터사이언스팀은 주문처리 및 배송 등 물류 프로세스와 상품/부자재 등 재고관리가 원활히 이루어질수 있도록 수요예측 모델을 개발/운영하고 있으며, 팀의 업무 중 가장 임팩트가 큰 업무라고 할수 있습니다.
- 단 1%의 정확도가 물류 비용의 증감에 큰 영향을 미칠수 있습니다. 소폭이라도 정확도를 높일수 있는 여러 방안을 고민하고 실험하며 적용합니다.
- 비즈니스 변화와 외부 현황에 민감하게 대응하며 모델을 안정적으로 운영/관리하고 있고, 모델을 활용하는 부서와 밀접히 협업하고 있습니다.
1.2 수요예측은 다음과 같은 방식과 구조로 진행하고 있습니다.
- 권역/지역별, 배송유형, 상품(SKU), 온도별(예, 냉동상품, 냉장상품) 등 다양한 기준으로 구분하여 수요를 예측합니다.
- 주문수, 총수량, 매출액, 소요시간 등 다양한 타깃을 대상으로 예측합니다.
- 30일후(D+30), 7일후(D+7), 1일후(D+1), 당일(D-day) 등 여러 시점과 타이밍을 기준으로 예측합니다.
- D-day에 가까워질수록 최신 데이터를 모델에 자주 적용하며 예측주기를 짧게 운영함으로써 예측값을 정교하게 만듭니다.
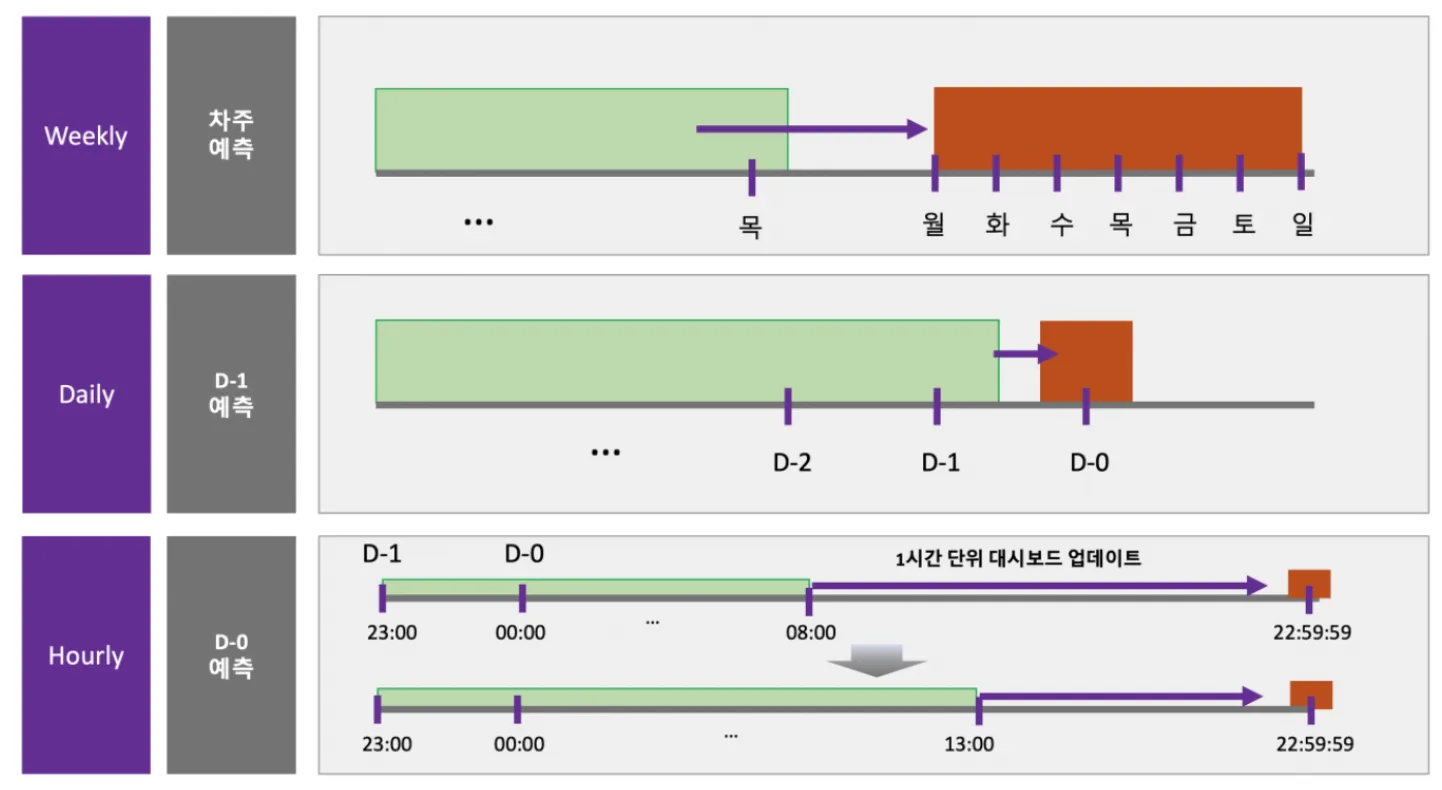
- 아래 예시는 당일에 30분에 한번씩 모델링을 진행하면서 당일에 발생할 매출액과 주문수를 전사에 제공하는 서비스입니다.
- 이를 위해 데멍이(데이터를물어다주는멍멍이)라는 봇을 운영하고 있으며 대시보드 및 슬랙을 통해 여러 부서에 제공하고 있습니다.
1.3 개인화 모델링 및 추천/랭킹 모델을 통해 효율적인 타깃팅을 진행하고 있습니다.
- 푸시 및 LMS 등 마케팅 활동이 효율적으로 진행할수 있도록 개인화 예측모델과 추천모델을 개발/운영하고 있습니다.
- 고객별로 상품에 대한 반응(구매, 클릭 등)을 사전에 예측하여 정교한 타깃팅이 가능함으로써 마케팅 비용의 효율화에 기여하고 있습니다.
- 혹시 모를 불필요한 고객와의 커뮤니케이션을 최소화하기 위해 관련도가 낮은 고객을 예측/분류하고 있습니다.
- 상품랭킹 알고리즘을 개발/운영함으로써 고객이 원하는 상품을 추천하고 주요 지표(예, Conversion, Diversity 등)를 개선하고 있습니다.
1.4 MLOPS 도입을 통해 안정적인 서빙 환경을 구축하고 있습니다.
- 아무리 정교한 모델이 개발된다고 해도, 만약 안정적으로 서빙이 되지 않으면 의미가 없을 것입니다.
- MLOPS 파트에서는 복잡하고 다양한 예측모델이 안정적으로 현업에 운영/서빙할수 있도록 필수적인 시스템과 인프라를 도입하고 있습니다.
- Feature Store, MLflow, Anomaly Detection System 등 다양한 프레임워크와 시스템을 적용하고 있습니다.
- 아래는 Airflow 기반으로 배치프로세스에 대한 구조를 도식화한 결과입니다.
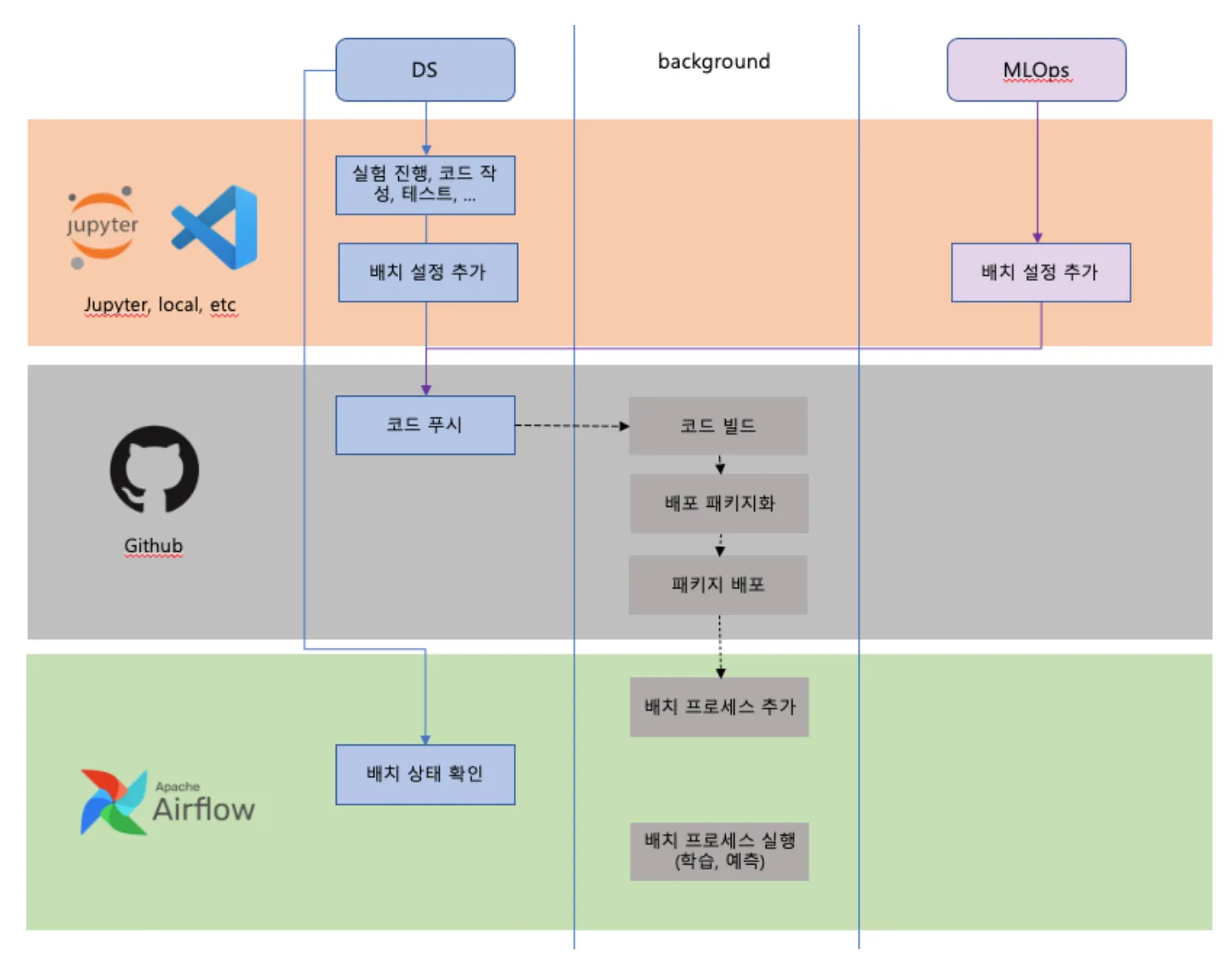
1.5 데이터사이언스팀의 문화와 업무 방식을 소개합니다.
- 구성원 각자의 성향과 역량, 커리어 방향성 등을 고려하여 프로젝트를 담당하며 담당자는 프로젝트 오너이자 리더이면서 실무자로서 역할을 수행합니다.
- 모델 개발 뿐만 아니라, 프로젝트 계획/관리부터 문제 정의, 사후 분석 및 성능 트래킹 등 비교적 넓은 영역을 단독으로 커버해야 하며, 커뮤니케이션도 직접 진행합니다.
- 실무자에게 많은 위임과 의사결정, 책임이 제공되는 환경이므로 일에 대한 욕심과 성장에 대한 니즈가 있다면 좋은 환경이라고 할수 있습니다.
- 단독으로 다수의 프로젝트를 수행하지만, 공통적인 부분(코드리뷰 등)에서는 다른 팀원과 활발히 공유하며 같이 성장하는 문화를 가지고 있습니다.
- 모델링이 실험이나 리서치 단계에서만 머무는 것이 아니라 실제 현장까지도 적용되므로 모델의 퍼포먼스를 직관적으로 확인하고 유저로부터 피드백을 받을수 있습니다.
- 컬리는 온라인 기반 서비스와 오프라인 기반의 물류 서비스를 모두 보유하고 있으므로, 복수의 도메인에서 데이터사이언스 프로젝트를 경험해볼수 있습니다.
- 자세한 내용은 JD 링크에서 확인할수 있습니다. https://www.wanted.co.kr/wd/51283
2. 수요예측 모델 개발/운영을 통해 배운 것들을 공유합니다.
- 알고리즘이나 피처 엔지니어링 등 보편적이고 이론적인 내용은 이미 책이나 인터넷을 통해 많이 공유되어 있습니다.
- 이번 파트에서는 모델을 실제로 배포하고 현장에서 운영하면서 얻은 경험과 배운 점을 위주로 공유하고자 합니다.
2.1 모델 배포후 사후 대응이 상당히 중요합니다.
- 타깃값(y)으로만 모델링을 진행하는 전통적인 시계열 모델 보다는 다수의 Regression 모델을 주로 사용합니다.
- Regression 모델이 정확도가 높은 경향이 있지만, 모델에 넣어주는 피처의 영향도와 퀄리티 등에 따라 성능이 크게 달라진다는 단점이 있습니다.
- 복잡하고 외부변화가 빠른 환경이므로 정확한 피처 엔지니어링과 데이터 퀄리티 관리가 까다롭고 어려운 업무입니다.
- 해당 이슈중 가장 흔한 경우가 데이터 수집/처리의 누락 이상치 및 오염 데이터 발생 등이며 수많은 원인으로 인해 발생합니다.
- 구성원들이 주요 원인을 해결하고 문제 발생시 바로 대응하기 위해 많은 노력을 하고 있습니다.
- 특히 배포된 모델이 많을수록 모델 개발/실험 보다는 위와 같은 사후작업과 성능 측정, 커뮤니케이션에 상대적으로 많은 시간을 사용하게 됩니다.
- 대응 효율과 정확성을 높이기 위해 Anomaly Detection 시스템도 준비하고 있습니다.
- 데이터 퀄리티 이슈 뿐만 아니라 비즈니스 변화에 맞춰 코드와 대시보드를 대응하는 부분에도 시간을 많이 할애합니다.
- 예를 들어 DB 구조 변경, 물류 권역의 변경과 확장, 상품 및 정책 변경 등 많은 수많은 활동이 진행되면 모델에도 즉시 이를 반영해줘야 합니다.
- 특히 신규 이벤트/프로모션/명절특수/공휴일/계절변화 등 외부 변화에도 민감하게 대응해줄 필요가 있습니다.
- 특별한 문제가 없음에도 모델 성능이 낮거나 시스템 리소스 문제로 모델 서빙에 문제가 있다면,
- 리서치 및 실험을 진행하여, 새로운 피처 및 알고리즘을 탐색/실험하거나 모델링 구조를 변경하면서 성능을 고도화하는 작업을 진행합니다.
- 주어진 환경과 사양에 맞게 학습/예측하는 기간을 줄이기도 하고 가벼운 연산방법을 탐색하거나 배치 프로세스를 점검 해보기도 합니다.
- 모델링으로만 문제 해결에 한계를 보일때는 현업 운영 단에서 새로운 프로세스나 대응을 진행하는 방식으로 진행하기도 합니다.
- 유관 팀과 리소스 유연화/강화, 알람 프로세스 도입 등을 논의하여 대응하는 방식을 진행하기도 하고,
- 모델이 정상적으로 작동하지 않을 경우를 대비해 룰 기반의 대응을 준비하여 긴급한 상황에 대안으로 운영하기도 합니다.
- 수요예측의 경우 연관된 팀이 많고 복잡하게 프로세스가 엮인 경우가 많기 때문에
- 유관 팀과 꾸준히 상황을 공유하고 협의하여 운영을 진행하는 것이 중요합니다.
2.2 예측성능 분석시 다각적인 접근과 세심한 판단이 필요합니다.
- 수요예측 모델의 정확도는 주로 예측값과 실제값의 차이가 얼마나 적은지를 기준으로 지표를 설정하고 트래킹을 합니다. (예, MAPE, RMSE 등)
- 보통의 정상적인 경우는 위와 같은 기준으로 예측 성능을 파악하고 의사결정하는 것에 이슈가 없습니다.
- 단 비즈니스라는 불확실성이 높은 환경에서는 위 기준을 일괄적으로 적용하여 판단하면 잘못된 판단을 할수가 있습니다.
- 간혹 발생하는 천재지변이나 크리티컬한 시스템장애 등으로 인해 수요발생이 불가능 경우는 다른 방식으로 측정하거나 측정에서 제외할 필요가 있습니다.
- 모델 개발시 무조건 정확도만 집중하기 보다는 실제 모델을 활용/운영하는 협업팀 관점에서 모델을 개발할 필요가 있습니다.
- 예를 들어 예측값을 과대하게 예측하는 경우와 과소예측하는 경우가 50%씩 발생하는 경우보다,
- 평균적인 정확도가 떨어지더라도 한 방향으로 꾸준히 예측하는 방향이 모델의 유용성을 더 높일수 있습니다.
- 경우와 목적에 따라 복잡성이 높고 시간 소요가 많은 모델링보다는 간단하고 단순한 공식 기반의 예측이 유용할수 있습니다.
- 예측은 예측일 뿐 항상 오차는 있으므로 사후 대응 프로세스가 중요합니다.
- 매번 완벽하게 예측하는 것은 오직 신만 할수 있는 일이므로,
- 실제로 할수 있는 일은 오차를 최소화하기 위해 노력하고 여러 소통 채널을 통해 빠르게 현황과 이슈를 공유하여 대응할수 있도록 하는 것입니다.
- 그리고 다각적으로 현황을 분석하여 개선 방안과 대체안을 고민하고, 사후 대응을 잘하는 것이 최선의 방법이라고 생각합니다.
- 특히 성능 관련 Adhoc 분석이나 트래킹을 할 때는 비즈니스 변화, 외부적 환경과 맥락, 히스토리 및 한계점 등 많은 요인을 종합적으로 고려하여 세심하고 신중하게 분석할 필요가 있습니다.
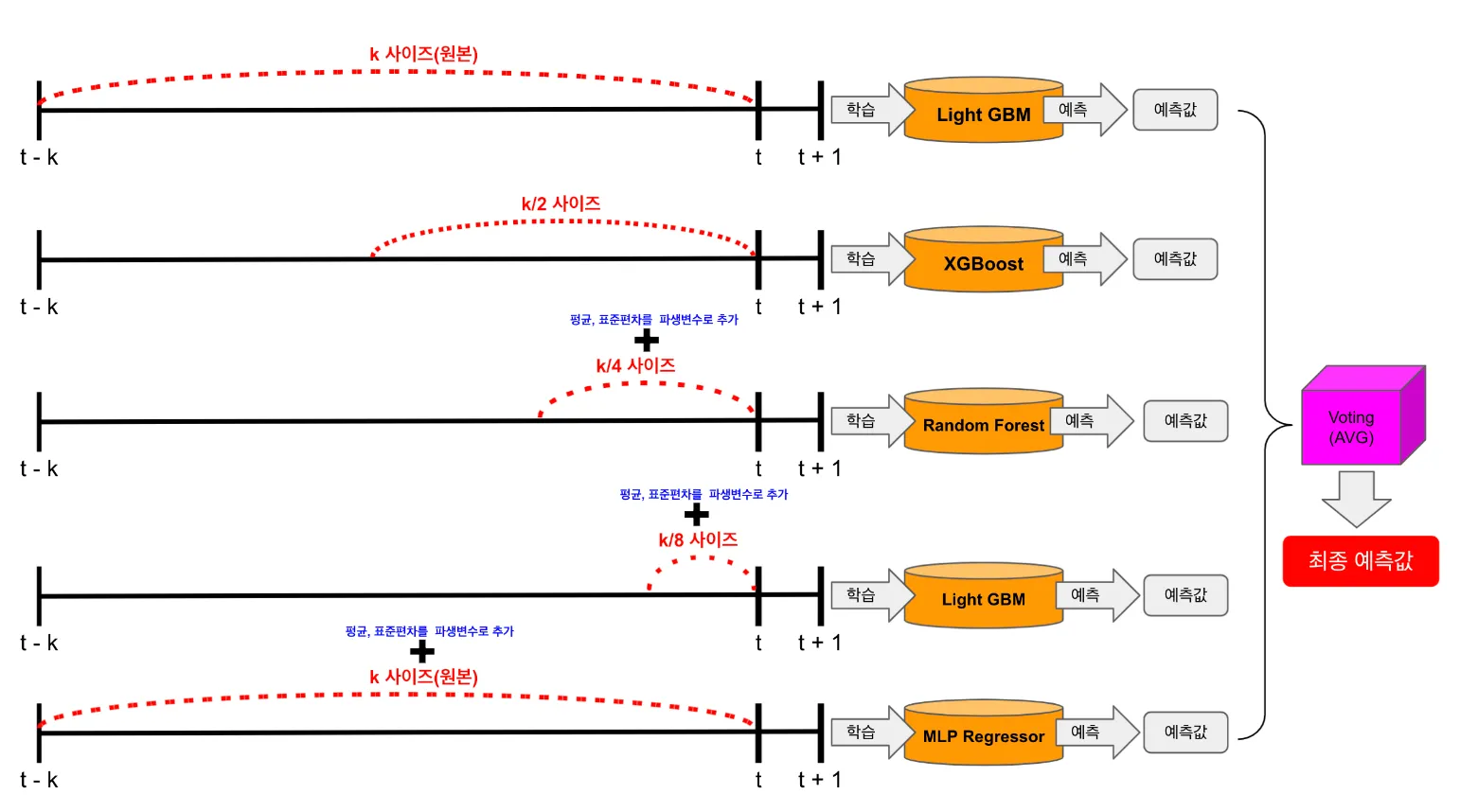
2.3 전통적인 시계열 모델 보다는 다수의 Regression으로 앙상블 방식을 활용합니다.
- 수요 예측모델의 경우 시간적인 순서가 있는 시계열 데이터를 다루면서 모델을 학습합니다.
- 전통적인 시계열모델은 t+1 시점의 Y값은 t-k ~ t 시점 기간의 Y값과 상관관계가 있다고 가정합니다.
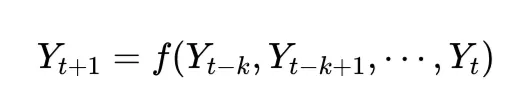
- 저희는 과거 발생한 실제값(y)만을 이용하여 예측하는 전통적인 시계열 예측모델(예, ARIMA, Prophet 등) 보다는
- LGBM이나 Random Forest와 같은 트리 기반 Regression 모델을 시간적인 순서를 고려하여 예측하는 접근법을 주로 이용합니다.
- 이유는 Regression 모델이 정확도가 높은 경향이 있고 다양한 피처를 적용해볼수 있기 때문입니다.
- 단, 피처 수집이 제대로 되지 않을때 예측값에 안 좋은 영향을 줄수 있다는 단점도 있으므로 피처 관리가 매우 중요합니다.
2.4 수요예측 모델링 실험에서는 Overfitting과 특히 Leakage를 주의해야 합니다.
- Overfitting
- 시계열을 포함해 비시계열 모델(Regression, Classification 등)에서도 해당하는 주요 이슈입니다.
- 과거 특정기간의 데이터를 추출하여 모델을 학습하고 검증을 하게 되는데
- 이 과정은 실험이라는 그리고 특정 과거 시점에 발생한 결과를 가지고 개발하는 것이기 때문에 많은 한계를 가집니다.
- 즉 실험 결과를 통해 도출된 모델을 실제 상황(시계열인 경우 미래의 상황)에 모델을 적용했을 때는 실험 결과와 다르게 모델이 낮은 퍼포먼스를 보일수 있습니다.
- 이러한 현상이 나타나는 이유는 학습 데이터에 대해 모델이 지나치게 학습하였기 때문이며,
- 이를 방지하기 위해 모델이 학습 데이터에 지나치게 의존하지 않도록 다양한 방법을 고려합니다.
- 예를 들어 가중치에 패널티를 적용하거나 피처의 수를 임의로 줄이거나 Cross-validation을 해보거나, 딥러닝 모델의 경우 drop-out 등의 방식으로 이를 해결합니다.
- Leakage
- 수요예측 모델링 과정에서도 당연히 Overfitting 이 발생할수 있으며, 이를 잘 다루어야할 뿐만 아니라 Leakage 문제도 상당히 조심해야할 필요가 있습니다.
- Leakage는 누수문제라고도 하며, 시계열 예측에서 주로 활용하는 lagging 피처(예, Yt-1, Yt-2, Yt-k 등 지난 특정 시점의 Y값)을 활용할 때 자주 발생합니다.
- Lagging 피처 뿐아니라 강수량, 기온과 같은 날씨 데이터를 실험하는 경우도 Leakage를 주의할 필요가 있습니다.
- 실험에서는 실제 발생한 강수량, 기온을 이용하지만 실제 모델이 배포시에는 부정확한 예보 데이터를 사용해야합니다.
- 아래 데이터 형상과 코드는 ord_cnt 라고 하는 예측타깃(y)에 대해 지역별, 시간대별 과거 특정시점(n)별의 해당 값을 가져오는 코드입니다.
- 예측하는 시점과 타이밍에 따라 Leakage를 어떻게 고려하여 실험하는지 참고차 공유하고자 합니다.
| biz_date | biz_hour | region_group_code | ord_cnt |
|---|---|---|---|
| 2022-12-01 | 1 | SEOUL | 100 |
| 2022-12-01 | 2 | SEOUL | 120 |
| 2022-12-01 | 3 | SEOUL | 150 |
| 2022-12-02 | 1 | SEOUL | 80 |
| 2022-12-02 | 2 | SEOUL | 110 |
| 2022-12-02 | 3 | SEOUL | 120 |
| 2022-12-03 | 1 | SEOUL | 10 |
| 2022-12-03 | 2 | SEOUL | 20 |
| 2022-12-03 | 3 | SEOUL | 30 |
# 과거 1일전부터 30일까지
# 지역별 시간대별 실제 발생한 주문수(ord_cnt)를 shift 하는 코드 예시
max_lagging_n = 30
for n in np.arange(1, max_lagging_n):
df[f'ord_cnt_d{n}'] = df.groupby(['region_group_code', 'biz_hour'])['ord_cnt'].shift(n)| biz_date | biz_hour | region_group_code | ord_cnt | ord_cnt_d1 |
|---|---|---|---|---|
| 2022-12-01 | 1 | SEOUL | 100 | null |
| 2022-12-01 | 2 | SEOUL | 120 | null |
| 2022-12-01 | 3 | SEOUL | 150 | null |
| 2022-12-02 | 1 | SEOUL | 80 | 100 |
| 2022-12-02 | 2 | SEOUL | 110 | 120 |
| 2022-12-02 | 3 | SEOUL | 120 | 150 |
| 2022-12-03 | 1 | SEOUL | 10 | 80 |
| 2022-12-03 | 2 | SEOUL | 20 | 110 |
| 2022-12-03 | 3 | SEOUL | 30 | 120 |
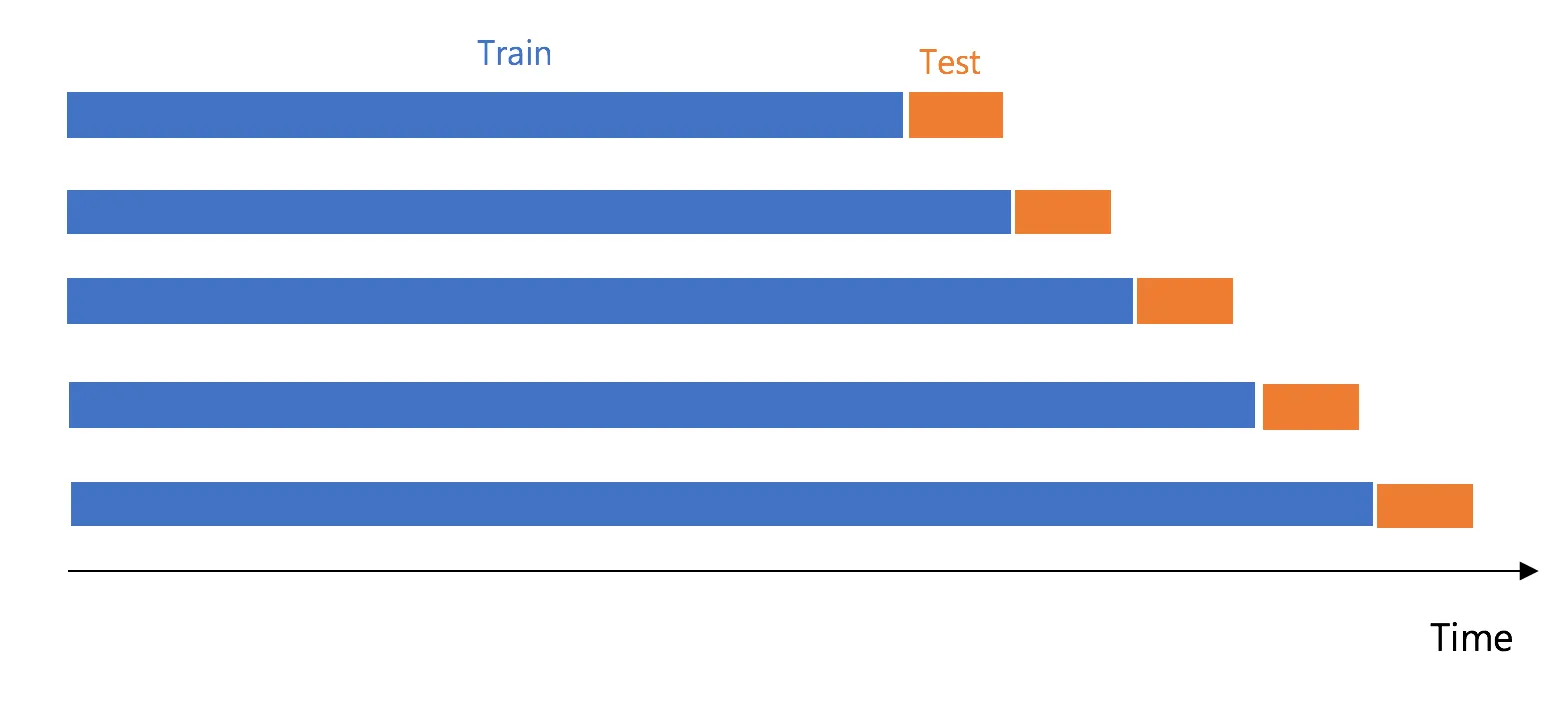
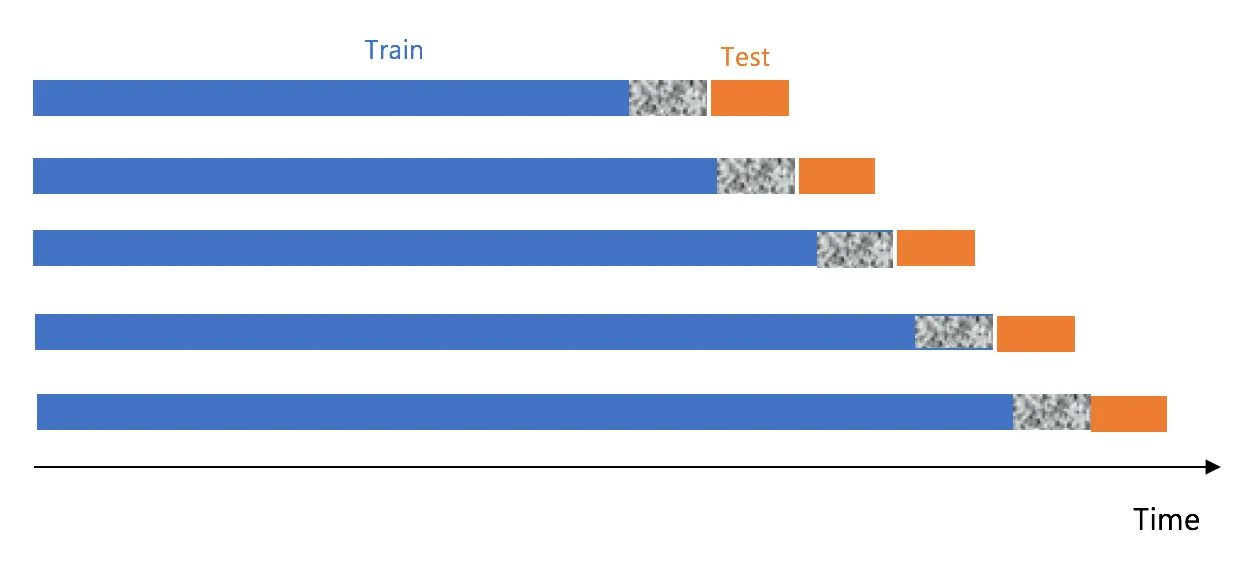
- 만약 당일 예측모델인 경우 즉 당일 오전에 바로 어제까지 발생한 데이터를 추출하여 당일 마지막 시점에 대해 예측하는 경우는 n=1 이 있어도 Leakage 문제가 없습니다.
- 따라서 아래와 같이 테스트일 바로 전까지 발생한 데이터를 가지고 lagging 피처를 만들어 실험하고 배포할 경우 Leakage 문제가 발생할 가능성이 적습니다.
- Training: 2022-12-01~2022-12-02 까지는 모델 학습용 데이터로 이용 (ord_cnt_d1는 피처 중에 하나)
- Test: 2022-12-03 에 대해서 모델 테스트 (ord_cnt_d1를 피처로 이용 가능. 예측수행을 12-03 오전에 하면서 12-02까지 데이터 수집이 가능하기 때문)
- 하지만 하루 전에 예측을 하는 경우는 다른 방식으로 실험을 진행해야 합니다.
- 예를 들어 2023년 1월 1일 오전에 2023년 1월 2일 발생할 수요에 대해 예측하는 경우가 이에 해당합니다.
- 위와 같은 경우는 아래와 같이 실험 구조를 고려하여 모델을 개발해야 leakage 문제가 발생하지 않습니다.
- 아래 회색의 경우 (모델 학습에 이용 불가능한) 예측을 수행하는(1월1일)의 데이터라고 보시면 됩니다.
- 아래 코드는 하루 전 예측하는 모델의 경우 피처를 생성하는 예시코드입니다.
- 위 코드와 달리 n=2부터 시작하여야하며, rolling mean이나 ewm 수치를 구할때 Yt-1의 실제값(y)이 아니라,
- Yt-2의 실제값(즉 이틀 전에 발생한 실제값)을 이용하고 있음을 유의깊게 볼 필요가 있습니다.
# 기간을 과거 2일전부터 30일까지
# 지역별 시간대별 실제 발생한 주문수(ord_cnt_d2)를 shift 하는 코드 예시
# ord_cnt를 shift 하게 되면 leakage 문제 발생함.
max_lagging_n = 30
for n in np.arange(2, max_lagging_n):
# lagging values
df[f'ord_cnt_d{n}'] = df.groupby(['region_group_code', 'biz_hour'])['ord_cnt'].shift(n)
df[f'ord_cnt_roll_d{n}'] = df.groupby(['region_group_code', 'biz_hour'])['ord_cnt_d2'].transform(lambda x: x.rolling(n,1).mean())
df[f'ord_cnt_ewm_d{n}'] = df.groupby(['region_group_code', 'biz_hour'])['ord_cnt_d2'].transform(lambda x: x.ewm(span=n, adjust=False).mean())| biz_date | biz_hour | region_group_code | ord_cnt | ord_cnt_d2 | ord_cnt_roll_d2 |
|---|---|---|---|---|---|
| 2022-12-01 | 1 | SEOUL | 100 | null | null |
| 2022-12-01 | 2 | SEOUL | 120 | null | null |
| 2022-12-01 | 3 | SEOUL | 150 | null | null |
| 2022-12-02 | 1 | SEOUL | 80 | null | null |
| 2022-12-02 | 2 | SEOUL | 110 | null | null |
| 2022-12-02 | 3 | SEOUL | 120 | null | null |
| 2022-12-03 | 1 | SEOUL | 10 | 100 | null |
| 2022-12-03 | 2 | SEOUL | 20 | 120 | null |
| 2022-12-03 | 3 | SEOUL | 30 | 150 | null |
| 2022-12-04 | 1 | SEOUL | 100 | 80 | 90 |
| 2022-12-04 | 2 | SEOUL | 100 | 110 | 115 |
| 2022-12-04 | 3 | SEOUL | 100 | 120 | 135 |
- 만약 12-03에 12-04을 대상으로 대해 예측 수행을 한다면 아래와 같이 모델 학습 및 테스트를 해야 Leakage 발생 가능성이 적습니다.
- Training: 2022-12-02를 포함해 이전까지만 모델 학습용 데이터로 이용 (2022-12-03는 예측수행일이므로 traning 데이터셋에 포함불가)
- Test: 2022-12-04 에 대해서 모델 성능을 테스트 (예측수행을 12-03에 한다면 실제로는 12-02까지만 데이터 수집이 가능하기 때문)
- 정리하면, 위와 같이 모델의 예측시점과 타이밍에 따라 Leakage 발생 가능성이 달라지므로 주의를 하면서 모델 개발을 진행해야 소중한 시간을 아낄수 있습니다.
2.5 여전히 문제 정의 및 프로젝트 관리는 중요합니다.
- 문제 정의 및 프로젝트 관리는 모델링 프로젝트가 아니더라도 모든 프로젝트에 해당되는 중요한 단계입니다.
- 문제 정의를 잘하고 계획을 잘 세우고 결과물을 잘 전달해야하는 기본 공식만이라도 잘 진행한다면 프로젝트의 반은 성공이라고 할수 있습니다.
- 다소 시간이 소요되더라도 프로젝트를 시작하기 전에 충분한 시간을 가지고 방향을 잘 설정하는 것이 좋은 판단이라고 생각합니다.
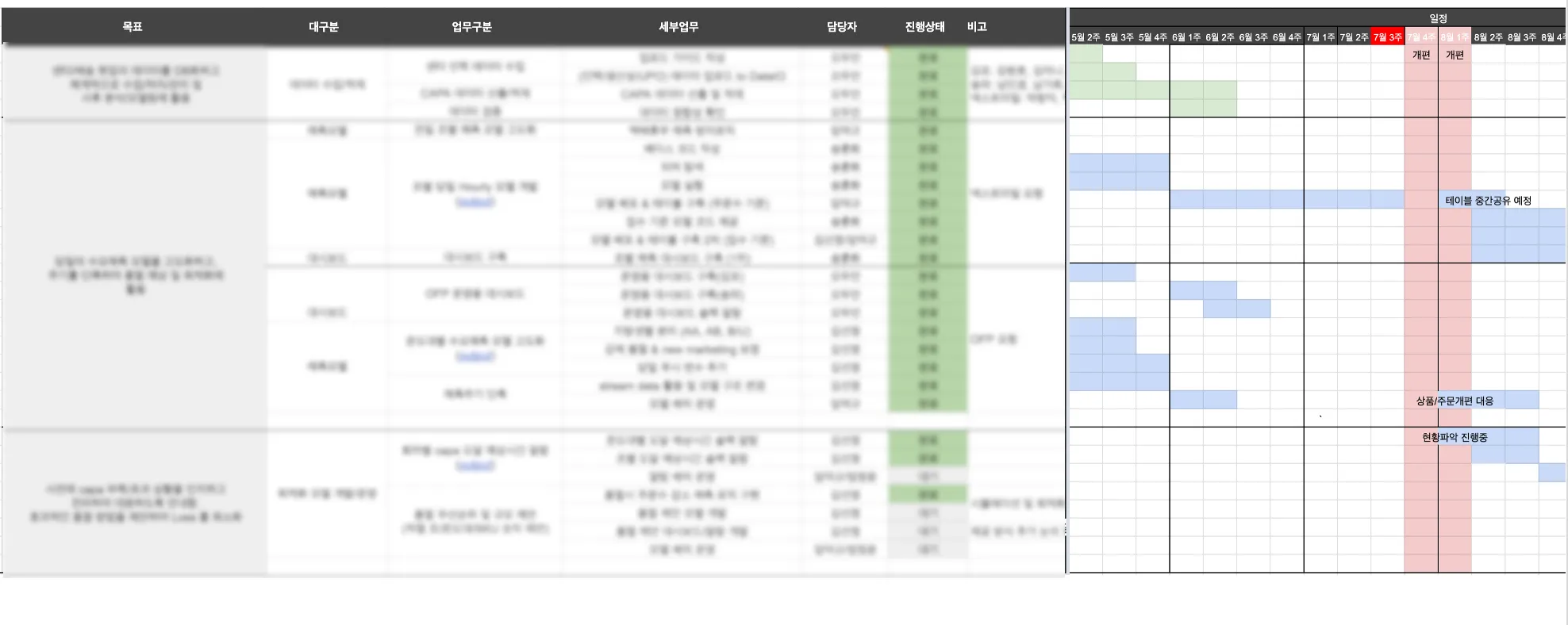
- 문제 정의후에는 아래와 같은 WBS 양식을 이용해 요청사항을 분석하고 예상 기간과 현황을 공유하는 프로세스로 진행하고 있습니다.
- 요청사항을 상세히 분석/분류/우선순위화하고 예상기간을 미리 생각해보며, 요청자와 실제 효과에 대한 명확한 기대치를 합의하는 것이 중요합니다.
- 미리 결과물의 샘플과 형상을 만들어 요청자와 합의함으로써 기대 수준을 맞춰가고 적절한 시간에 전달하도록 합니다.
- 구두로 협의하는 것보다 실제 결과물을 눈으로 확인하는 과정이 효과가 좋으며, 중간에 지속적으로 커뮤니케이션 하면서 현황을 공유하는 것도 중요합니다.
마무리
- 컬리에서 약 2년간 데이터사이언스 프로젝트를 수행하며 경험한 내용을 간략히 공유하였습니다.
- 누군가에게 조금이나마 도움이 되길 바라며 포스팅을 마치겠습니다. 긴글 읽어주셔서 감사합니다.