안녕하세요. 컬리 데이터플랫폼 팀에서 Data Scientist로 일하고 있는 강동윤입니다.
컬리 물류센터는 접수된 주문에 따라 상품을 분배하고 포장하고 안전하게 배송하기 위한 준비로 매일매일 분주합니다.
이 모든 과정을 보다 효율적으로 만드는 것은 최적화의 영역이며, 수많은 변수가 개입할 수 있기에 매우 어려운 주제 중 하나입니다.
컬리는 이러한 문제에 어떻게 접근해서 풀어나가고 있을까요?
1부(이번 글)에서는 그 과정을 다루려고 하며, 2부에서는 결과를 검증하는 내용을 이어서 소개하도록 하겠습니다.
물류센터는 이렇게 돌아간다
먼저 이해를 돕기 위해 물류센터 주문처리 과정을 간단하게 설명하겠습니다.
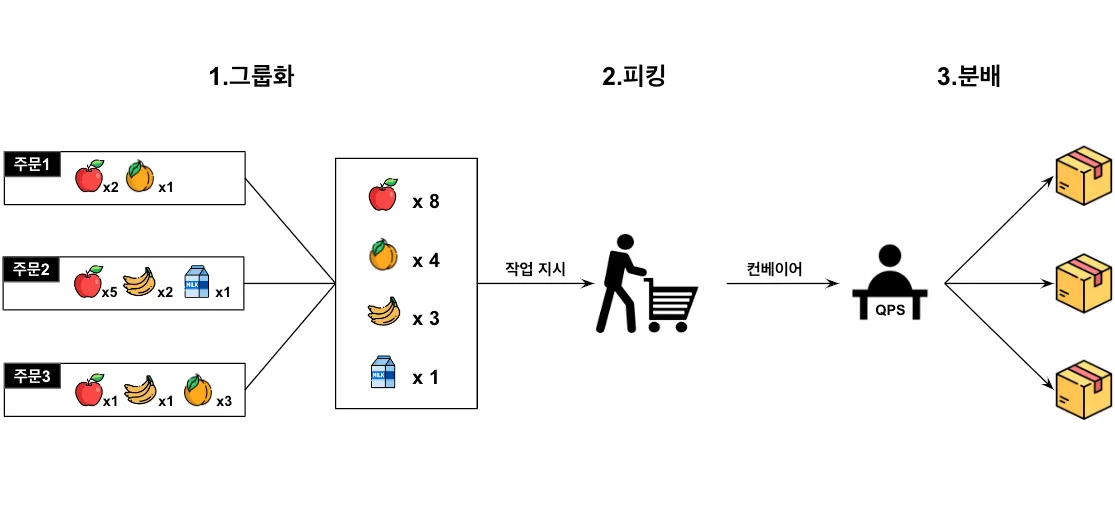
그림의 첫 번째 단계에서, 접수된 주문을 특정 규모의 그룹으로 묶습니다. 이를 ‘주문 그룹’이라고 하겠습니다. 다음 두 번째 단계에서는 주문 그룹에 대한 작업 지시가 만들어지고(예: ‘A존에서 사과를 3개 담으세요’), 작업 지시를 확인한 작업자는 창고형 대형마트와 유사한 적재공간을 돌아다니며 바구니에 상품을 담습니다. 이러한 작업을 피킹(picking)이라고 하며, 앞서 주문을 묶는 이유는 보다 효율적으로 피킹하기 위함이기도 합니다. 예를 들어 위와 같이 사과를 포함하고 있는 3가지 주문을 하나씩 처리하려면 사과를 3번 가지러 가야 하지만, 이를 주문 그룹으로 묶으면 한 번만 가지러 가도 되기 때문입니다(이를 총량 피킹이라고 합니다). 그리고 마지막 세 번째 단계에서 꽉 찬 바구니들은 차례로 컨베이어에 오른 뒤 QPS라는 장비로 이동하여 다시 원래의 주문 단위로 분배되고, 포장 후 고객에게 배송됩니다.

저희는 위 주문처리 과정 중 QPS(Quick Picking System)에 집중했습니다. 수많은 피킹완료 바구니를 실시간으로 분배하는 핵심 공정으로, 대부분 자동화되어 있어 최적화를 잘하면 생산성이 높아질 수 있다고 판단했기 때문입니다.
무엇을 최적화해야 할까?
자, 그렇다면 QPS의 생산성을 높이기 위해 어떤 지표를 최적화해야 할까요? 이를 결정하려면 먼저 QPS의 생산성을 정의하고 이에 영향을 주는 요인들을 파악할 필요가 있습니다.
QPS(Quick Picking System)
그 전에 QPS가 어떤 장비인지 소개하겠습니다.
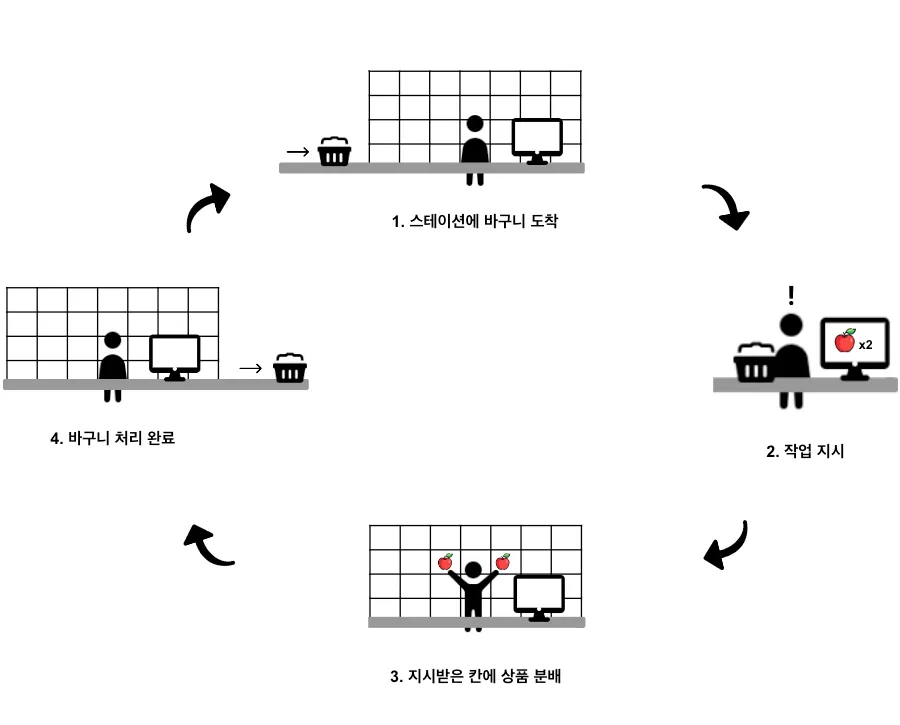
QPS에서는 위 그림과 같은 순서로 작업이 이루어집니다. 먼저 작업자가 위치한 작업대(스테이션, station)로 바구니가 도착합니다. 작업대 입구에 설치된 스캐너가 바구니를 인식하고, 처리해야 할 상품들을 차례대로 모니터에 보여줍니다. 작업자가 상품을 하나씩 스캔하면 상품을 넣을 칸 번호가 모니터에 출력됩니다. 작업자는 칸 번호를 확인하고 뒤에 위치한 칸에 상품을 넣습니다(각 칸은 주문 하나를 의미합니다). 상품 분배가 완료된 칸(주문)은 선반 뒤 작업자가 포장 공간으로 이동시킵니다.
바구니 안의 상품 종류를 줄이자
위 과정을 고려해서 저희는 QPS의 생산성을 ‘개별 바구니 처리 속도’로 정의하였습니다. QPS로 들어오는 총 바구니 수를 포함한 모든 조건이 동일하다면, 개별 처리 속도의 감소는 곧 전체 생산시간의 감소로 이어질 것이기 때문입니다.
Y를 정의했으니 이제 X들을 찾아야겠죠. 바구니 처리 속도와 상관관계가 있는 수많은 변수들 중 해석을 저해할 만한(ex- 다공선성, 내생성..) 것들을 제외하고 아래와 같이 회귀분석을 수행한 결과, 가장 영향력 있는 변수는 ‘바구니 안의 고유한 상품 수’라는 사실을 알 수 있었습니다.
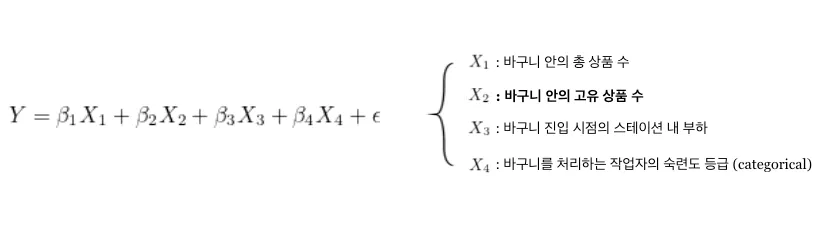
이 값이 클수록, 그러니까 바구니에 다양한 상품이 들어있을수록 처리 속도가 증가한다는 것은 어찌 보면 자명한 사실입니다. 총 상품 수가 5개로 같더라도 서로 다른 상품(예를 들어 사과, 배, 감, 귤, 우유 1개씩)을 각각 스캔해서 뒤쪽 선반에 넣는 것보다 사과 하나를 5번 스캔하는 게 더 효율적이겠죠. 좀 더 생각해 보면 사실 이 변수는 QPS에서뿐만 아니라 그 이전의 피킹 작업 효율에도 영향을 미칩니다. 바로 직전 예시처럼 서로 다른 5개의 상품을 바구니에 담아야 한다면 피킹 작업자가 들러야 하는 장소는 다섯 곳이지만, 같은 상품 5개를 담는다면 한곳만 가면 되기 때문입니다.
이와 같은 논리 흐름대로, 저희는 바구니 안 고유한 상품 수를 줄이는 것을 목표로 최적화를 수행하자는 결론에 다다를 수 있었습니다.
어떻게 최적화해야 할까?
앞서 설명한 작업 과정을 고려했을 때 QPS에서의 최적화는 Open shop scheduling이라는 널리 알려진 문제로 치환해 볼 수 있습니다. 좀 더 자세히 설명하자면 QPS에서는 서로 다른 주문(job)이 작업자(machine)에게 계속 할당되는데, 여기서 저희의 목적은 총 생산시간(makespan)을 줄이기 위한 최적의 할당 시나리오를 찾는 것이기 때문입니다. 결국 목적을 이루기 위해서는 바구니 안의 고유한 상품 수를 최소화하는 주문의 조합을 구해야 하는 것이죠.
일반적으로 이러한 문제에 대한 해의 개수는 셀 수 없이 많습니다. 특히 그중 어떤 것이 최적 해인지를 판별하는 것이 쉽지 않기에 매우 복잡한 문제(NP-Hard) 중 하나로 분류됩니다.
예전에는 이렇게 접근했다
이 문제를 풀기 위해 아래와 같은 시도가 있었습니다.
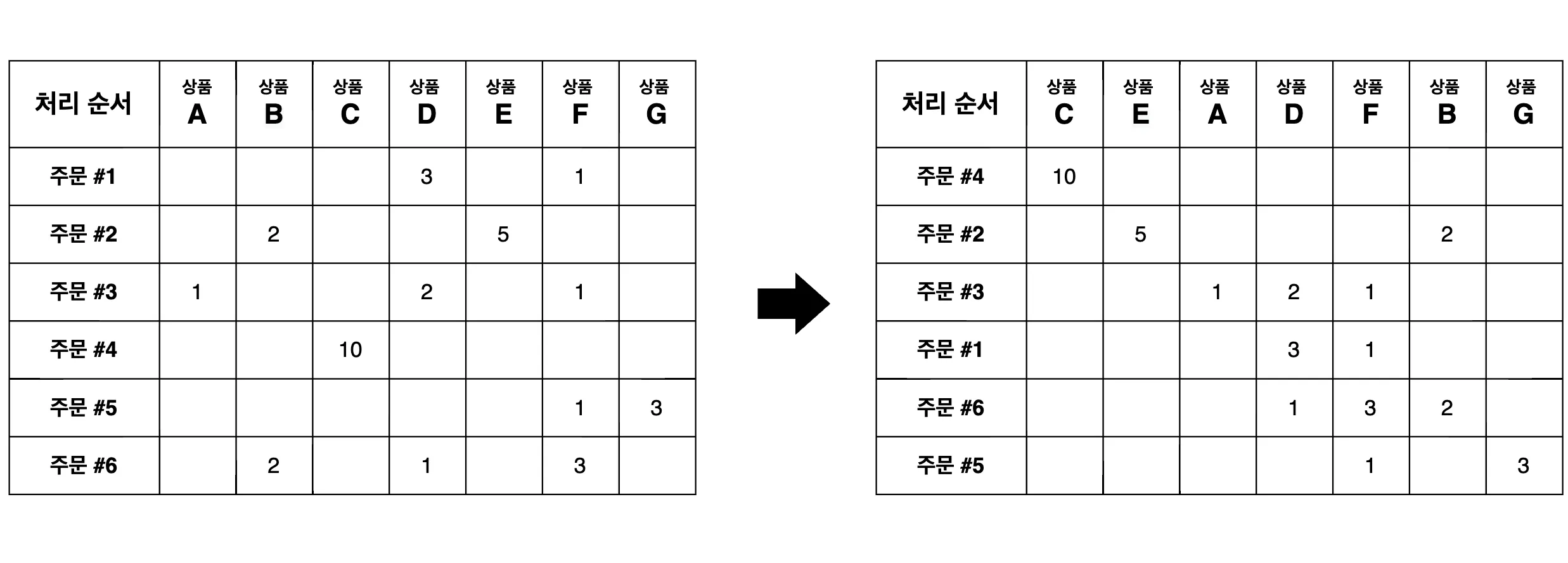
먼저 주문-상품 행렬을 만들고, 오른쪽과 같은 대각(에 가까운) 행렬을 지향하면서 행과 열을 특정 횟수만큼 섞어줍니다. 그 과정이 완료된 다음 인접한 주문들끼리 묶어주면 고유한 상품 수를 최소화하는 주문의 조합을 구할 수 있게 됩니다. 만약 주문을 정렬하지 않고 왼쪽과 같이 3번과 4번 주문을 묶는다고 가정하면 이 주문 조합의 고유한 상품 수는 4개지만, 오른쪽과 같이 정렬된 상태에서 인접한 3번과 1번을 묶어준다면 고유한 상품 수가 3개로 적어집니다. 대각화가 어느 정도 잘 진행된다면 충분히 합리적인 결과를 보여줄 수 있는 알고리즘인 것이죠.
유전 알고리즘(Genetic Algorithm)이란
이번에 저희는 조금 다른 방법을 통해 접근해보기로 했습니다. 위처럼 명확한 최적 해를 찾기 어려운 문제의 경우, 계산 비용을 지불하여 최적에 가까운 대안을 찾는 알고리즘들이 존재하는데요. 그중 특히 효과적이라 알려진 방법으로는 유전 알고리즘이 있습니다(참고 문헌). 구한 해가 최적임을 확신하기 어려운 단점이 있지만, 간편하고 효율적으로 더 나은 대안을 찾아나갈 수 있다는 큰 장점이 있죠.
이 유전 알고리즘은 다음 그림과 같은 컨셉을 가집니다.
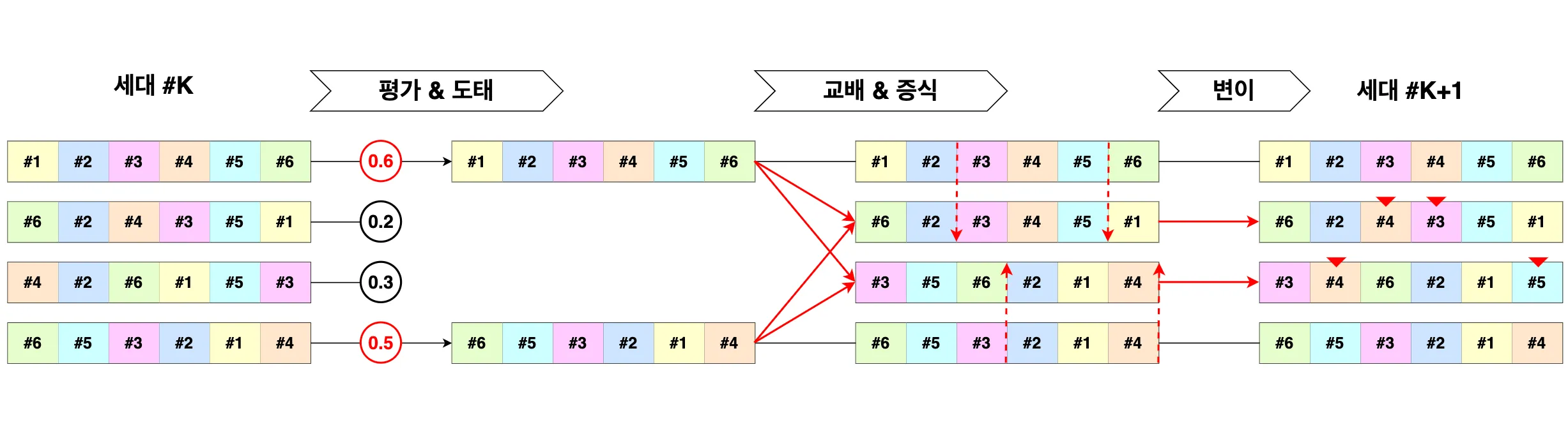
다윈의 적자생존론에 의하면, 환경에 잘 적응하는 우수한 유전자를 가진 부모들이 우선적으로 선택되고 그들 간의 교배를 통해 자손들에게 그 유전자가 전달되며 때로는 돌연변이를 통해 부모를 뛰어넘기도 합니다. 세대를 거치면서 이 과정을 반복하면 결국 환경에 잘 적응하는 우수한 유전자만 남게 되죠.
위 그림을 보면, 먼저 해결할 문제에 대한 다양한 해를 각각 유전자로, 그 해의 집합을 세대라고 정의합니다. 그중 임의의 함수로 계산된 적합도를 기준으로 우수한 부모 유전자를 선택하고 교배와 변이 연산자를 적절하게 적용해 자식을 결정합니다. 자식 세대는 부모 세대보다 적합도가 높을 것이며 세대를 거듭할수록 최적에 가까운 해를 구할 수 있게 되겠죠.
실제로 적용해보자
위 컨셉을 실제로 적용하는 과정은 결코 순탄치 않았습니다. 세대를 거듭할수록 보다 나은 해를 얻겠지만, 자칫하면 알고리즘 수행 시간이 길어지면서 물류센터 내 작업을 지연시킬 수 있기 때문입니다. 따라서 저희는 첫 세대를 공들여 만듦으로써 속도와 성능 두 마리 토끼를 잡기로 했습니다. 왠지 모르게 씁쓸하지만, 시작부터 우월한 유전자라면 더 빠르게 좋은 결과를 얻을 테니까요.
그럼 저희가 적용할 유전 알고리즘은 다음과 같이 요약할 수 있습니다.
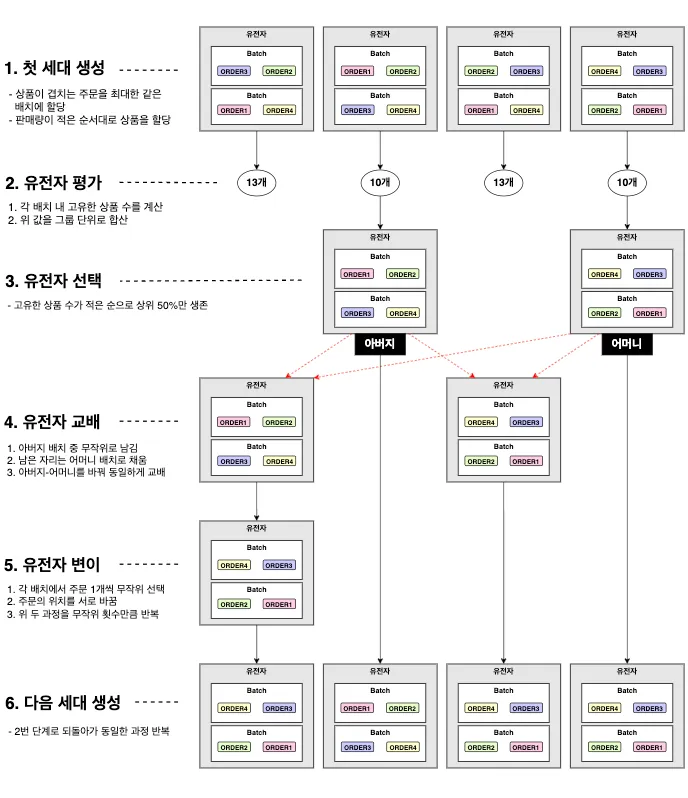
우선 같은 batch 안에 서로 유사한 주문들이 담기도록 최대한 신경 쓰면서 첫 세대를 생성합니다. 그다음 각 유전자 내 고유한 상품 수를 계산하고, 이 값이 작은 순으로 상위 50%만 생존시킵니다. 저희가 원하는 것은 바구니 안의 고유한 상품 수를 최소화하도록 할당할 수 있는 주문 조합(=유전자) 이기 때문에 그 목적에 맞는 적합도를 계산해서 평가하는 것이죠. 이제 batch 단위로 특정 조건에 따른 교배 및 변이를 수행함으로써 자식 세대를 생성하고, 이 과정을 특정 횟수만큼 반복하면서 최적의 주문 조합을 탐색해나갑니다.
결과는 어땠을까?
실제 과거의 주문 데이터를 가지고 기존 알고리즘(대각 행렬 알고리즘, Legacy)과 유전 알고리즘(GA)을 각각 적용하여 나온 결과는 다음과 같습니다.
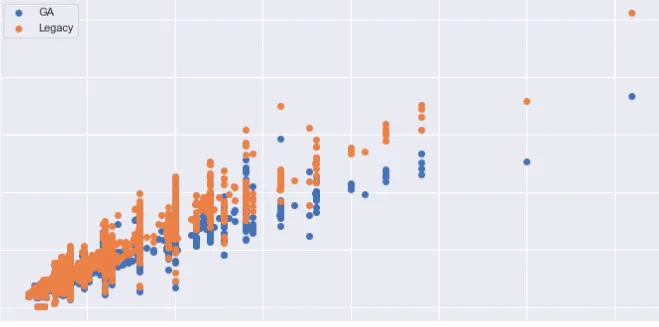
위 scatter plot의 x축은 batch 내 주문 수를, y축은 batch 내 고유한 상품 수를 의미합니다. 보시다시피 주문 수 규모에 관계없이 파란색 점(유전 알고리즘)의 고유 상품 수가 주황색(기존 알고리즘)보다 대체로 적습니다. 전체적으로 보면 대략 10% 이상의 감소 폭으로 꽤나 고무적인 성과라고 볼 수 있습니다. 참고로 여기까지의 내용을 담은 논문은 올해 12월, 말레이시아에서 개최되는 IEEM 2022 에서 발표될 예정입니다. 👏👏
그러나 글 초반부에서 말씀드렸듯 실제 물류센터 내 작업 과정은 매우 복잡하고 수많은 변수의 개입 여지가 있습니다. QPS 공정 전후로 여러 알고리즘이 촘촘히 맞물려 있기 때문에 예상치 못한 곳에서 작업이 지연될 수 있는 것입니다. 따라서 유전 알고리즘을 실제 환경에 적용하기 위해서는 조금의 확신이 더 필요합니다. 그 확신을 얻기 위해서 이왕이면, 실제와 최대한 닮은 가상 환경을 구성하고 통제된 실험을 해볼 수 있다면 좋겠죠.
이어지는 2부에서는 위 결과의 유효성을 추가 검증하기 위해 Digital Twin을 구축한 과정을 소개하도록 하겠습니다.
References
F. Werner, GENETIC ALGORITHMS FOR SHOP SCHEDULING PROBLEMS: A SURVEY, 2011
* 본 게시물에 사용된 이미지들의 저작권은 컬리에 있습니다. 사용 시 출처를 꼭 명시해주세요.