OMS에서 Claude AI를 활용하여 변화된 업무 방식
PM 1명과 엔지니어 3명이 12개 MSA를 운영하는 OMS팀이 Claude AI를 도입하여 16명 규모의 조직처럼 일하게 된 과정을 소개합니다.
 이준환
게시 날짜: 2025.12.24.
이준환
게시 날짜: 2025.12.24.
- 💬 들어가며
- 📌 AI 도입 전: OMS 팀은 어떻게 일했나?
- 📌 AI 도입 후: OMS 팀은 어떻게 변했나?
- 📌 OMS팀의 역할 기반 AI Context
- 📌 AI Context 설계 방법
- 📌 AI Context 학습 방법
- 📌 AI Context 에 여러 MCP 피처링
- 📌 AI Context에 유리한 아키텍처
- 📌 AI Context 도입 후 OMS 팀의 긍정적인 변화
- 📌 AI와 협업하며 생긴 팀 그라운드 룰
- 🔮 앞으로의 확장 계획
- ✍️ 마무리

💬 들어가며
안녕하세요. OMS팀 이준환입니다.
현재 OMS팀에서는 Claude Code(v2.0.72, Opus 4.5)를 활용하여 업무를 진행하고 있습니다. 이번 글에서는 Claude AI를 도입하여 OMS팀이 어떻게 협업하며 업무 방식을 변화시켰는지 소개하려고 합니다.
본 글은 지난 12월 19일 컬리 사내에서 진행했던 발표를 기반으로 작성되었으며, 당시 시간 관계상 다루지 못했던 내용들을 추가로 담았습니다. 발표에서는 실제 개발 Jira 티켓 1개를 선정하여 Frontend와 Backend MSA 개발을 동시에 라이브 바이브 코딩도 같이 시연했고, AI Context 기반 개발 방식을 실시간으로 보여드렸습니다.
AI를 활용하는 방식은 개인마다 노하우와 경험의 차이가 큽니다. 개인의 AI 활용 숙련도에 따라 생산성이 독고다이가 가능한 수준까지 올라가기도 합니다. 특정 개인은 엄청난 퍼포먼스를 보이며 만족스러운 경험을 할 수 있지만, main 브랜치에 머지되는 순간 개인의 코드는 우리 모두의 코드가 됩니다. 결국 팀 전체의 생산성을 함께 끌어올리는 것이 더 지속 가능하고 안전한 발전이라고 생각합니다. 이 글은 개개인의 노하우를 체계화하여 팀 전체가 AI를 효율적으로 활용할 수 있는 방법을 모색한, 다소 실험적인 시도의 결과물입니다.
이 방법이 정답은 아닙니다. 각 팀의 상황, 도메인, 아키텍처에 따라 최적의 방식은 다를 수 있습니다. 다만, 이 글에서 소개하는 방법은 OMS팀에서 실제로 수개월간 운영하며 효과를 검증한 사례입니다. 4명의 팀이 12개 MSA를 안정적으로 운영하고, 개발 생산성과 코드 품질이 실질적으로 향상되는 것을 확인했습니다. 유사한 고민을 하고 계신 분들께 검증된 참고 자료로서 도움이 되길 바랍니다.
Claude Code의 기본 사용법과 배경지식은 박재영 님께서 작성해주신 Vibe Coding with Claude Code 글을 참고하시면 좋습니다. 이 글은 Claude Code 사용법에 대한 디테일한 내용까지는 제공하지 않습니다.
📌 AI 도입 전: OMS 팀은 어떻게 일했나?
OMS팀은 PM 1명을 포함한 총 4명의 팀원으로 12개의 MSA 서비스를 개발하고 운영하고 있습니다. MSA 아키텍처에 대한 자세한 내용은 OMS의 최적화된 마이크로서비스 아키텍처 디자인 글을 참조해 주세요.
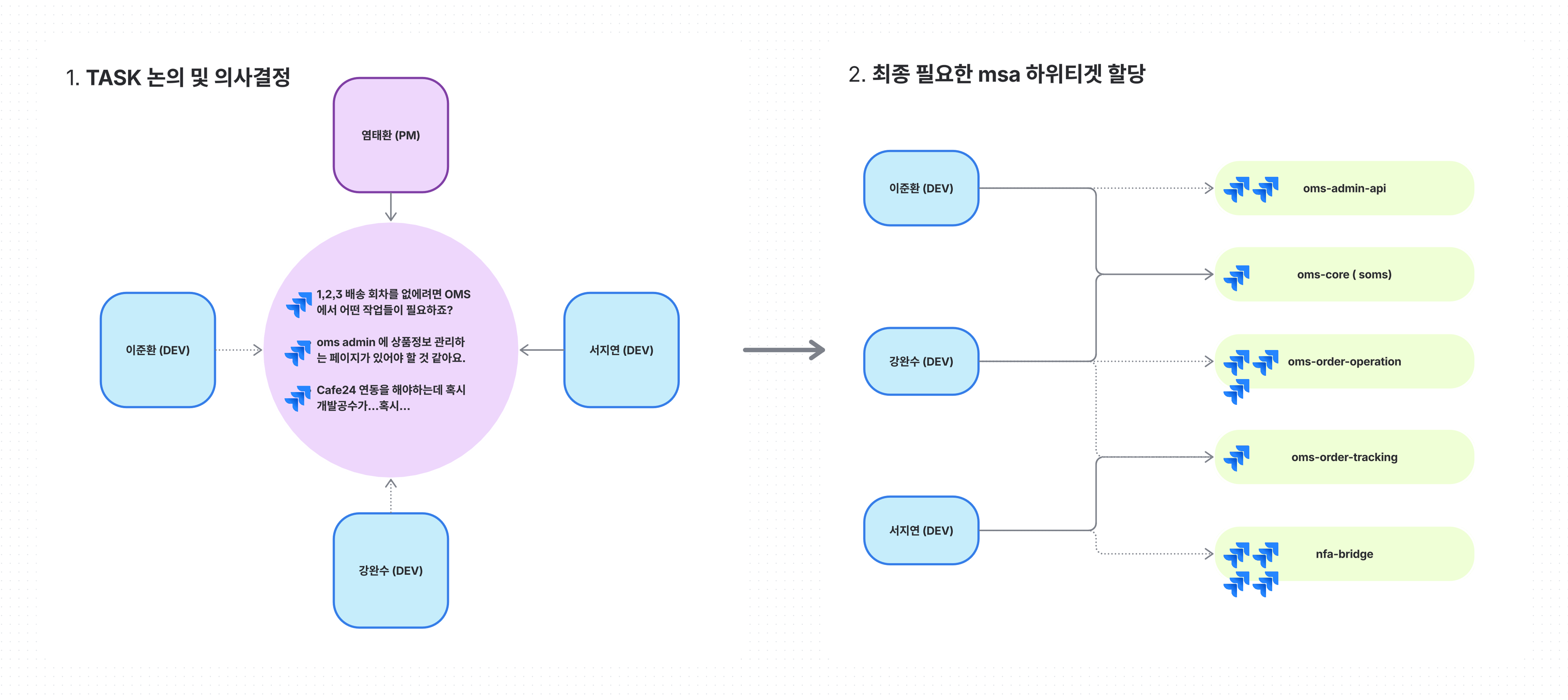
PM이 물류의 여러 문제들을 정의해 오면, OMS팀 전체가 함께 모여 이를 하나씩 파헤칩니다. 각 문제를 분석하고 하위 티켓을 생성하며, 담당자를 정하고 배포 계획을 동시에 수립하는 방식으로 일해왔습니다. 모두가 같은 문제를 동시에 바라보고 함께 계획을 세워왔기에 각 MSA에 대한 이해도의 편차가 별로 발생하지 않았습니다. (약 2년전 까지는…)
MSA가 늘어나면서 발생한 문제점
어느덧 OMS팀이 담당하는 MSA 서비스가 Repository 기준으로도 점점 늘어나면서 다음과 같은 문제들이 발생했습니다.
- 정교한 계획 수립의 어려움: 여러 MSA의 동시 개발이 필요한 요구사항에서 영향도 파악이 점점 힘들어짐
- 코드 레벨 정책 누락: 실제 코드까지 분석해야만 알 수 있는 정책을 설계 단계에서 놓치는 경우 발생
- MSA 이해도 편차: 개발팀원들의 각 MSA에 대한 이해도에 편차가 생기기 시작
- 배포 지옥: 하루에 7~8개의 운영배포 요청서를 작성하는 날도 있었음
📌 AI 도입 후: OMS 팀은 어떻게 변했나?
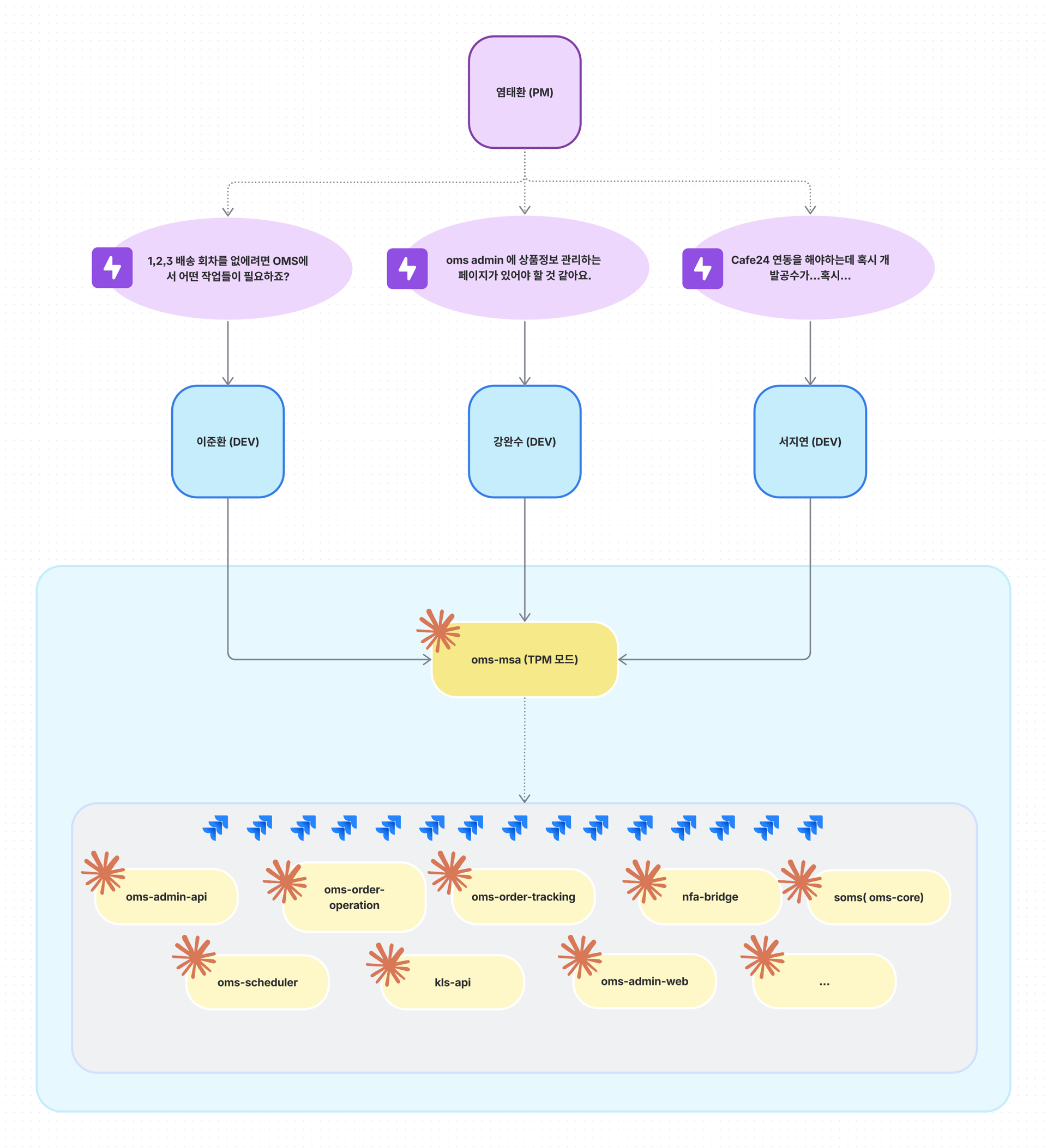
이제 모든 엔지니어는 OMS MSA의 중심에 Claude TPM 모드를 두고 각자 독립적으로 요구사항을 파악하고 계획을 수립할 수 있게 되었습니다. PM 입장에서는 개발 공수 산정을 위해 매번 OMS팀 전체를 소집할 필요가 없어졌고, 엔지니어들은 각자의 속도로 문제를 분석하고 설계할 수 있는 구조가 만들어졌습니다.
TPM AI
TPM(Technical PM) AI는 전체 아키텍처 관점에서 분석을 수행합니다.
- 엔지니어는 TPM AI와 함께 EPIC 요구사항을 MSA 전체의 숲을 보며 분석
- 구체적인 Spec 설계는 제외
- 각 MSA에서 제공하는 현행화된 API, Message Specs을 고려하여 신규 추가, 수정 필요 등의 영향도 파악
- 배포 순서까지 계획
- 구체화된 집중 설계를 위해 MSA AI용 하위 Jira 이슈 생성
MSA AI
MSA AI는 Backend, Frontend 개발자의 역할을 수행합니다.
- TPM AI로부터 제공받은 하위 이슈를 코드 레벨까지 집중 분석
- 구체적인 인터페이스 설계 후 집중 설계가 완료되면, 하위티켓 스펙대로 개발
- 이 스펙을 사용할 MSA를 위해 Jira 에 최종 개발완료 스펙 업데이트
Claude를 통해 각 역할을 호출하는 방법
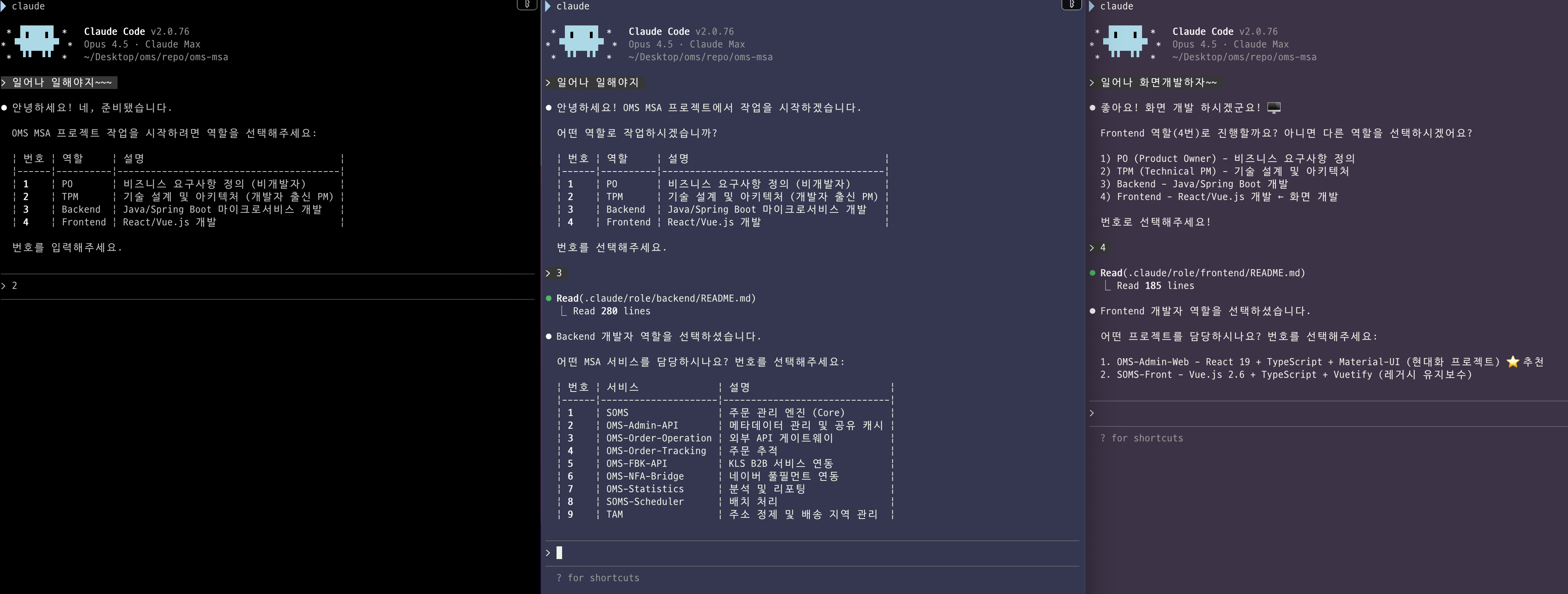
OMS팀에서 Claude AI 역할을 활용하는 워크플로우는 다음과 같습니다:
- 터미널의 배경색을 역할별로 지정하여 구분
- OMS MSA repository root 폴더로 이동
claude명령어로 Claude 세션 시작- 역할 선택 (PO, TPM, Backend, Frontend, Infra)
- Backend/Frontend의 경우 담당할 MSA 선택
Claude Code는 Claude Desktop이나 VSCode 플러그인 등 다양한 방식으로 사용할 수 있습니다. 하지만 OMS팀처럼 여러 역할을 동시에 운영해야 하는 구조에서는 각 역할을 시각적으로 명확히 구분할 필요가 있습니다. 이를 위해 iTerm의 배경색 설정 기능을 활용하여 역할별 터미널 창을 구분하고 있습니다.
한줄 요약
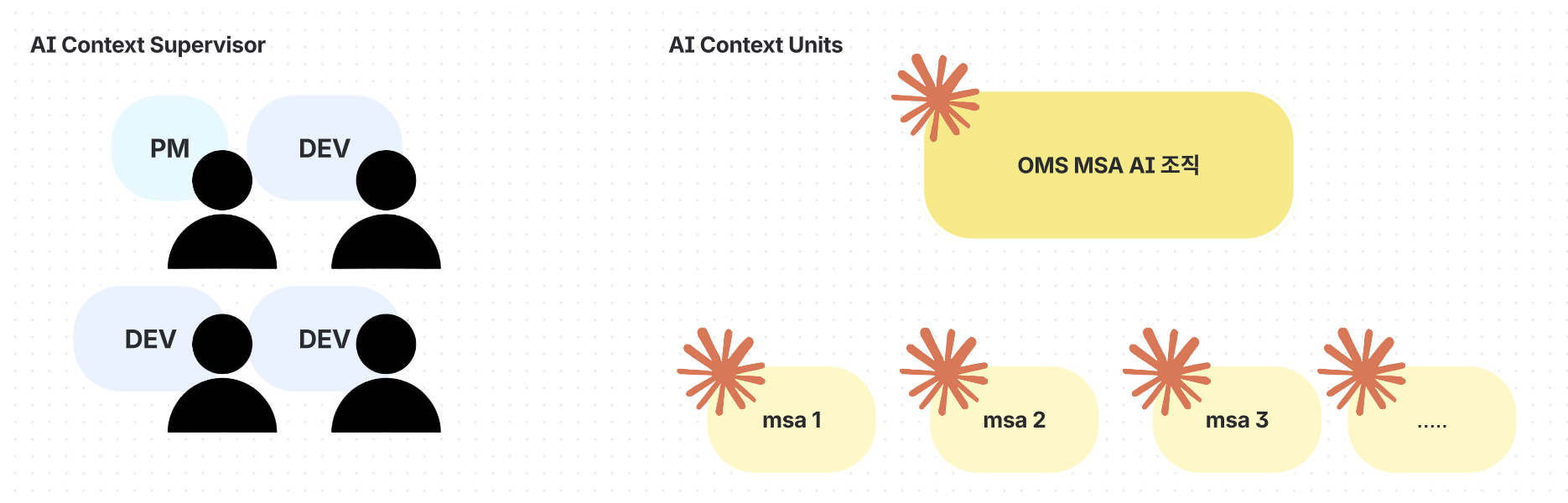
OMS팀에는 인간 PM 1명, 3명의 인간 AI Context Supervisor, 그리고 1개의 TPM AI + 11개의 MSA AI = 총 16명의 구성원이 일하는 대형 조직
OMS팀 엔지니어는 전체 AI의 Supervisor로서 각 AI의 Context 관리와 실질적인 EPIC 문제에 집중합니다.
📌 OMS팀의 역할 기반 AI Context

Claude뿐만 아니라 모든 AI 에이전트 모델은 AI 세션이 종료되는 순간 과거의 작업 기억을 해내지 못합니다.
이걸 비유하자면:
- AI 세션 Open → 과거 기억을 잃어버린 채로 잠에서 깨어남
- AI 세션 Close → 여태껏 기억을 잃어버리는 깊은 잠에 빠짐
영화 메멘토의 주인공처럼 잠에서 깨어났을 때 "Who am I?"에 대해 정의해 주고, 본인이 어떤 상황이었는지를 기억해내도록 역할 기반의 AI Context 설계가 필요합니다.
OMS팀의 AI 역할
| 역할 | 컨텍스트 로딩 전략 | 로딩되는 문서 | 목적 |
|---|---|---|---|
| PO | 선택적 지연로딩 | 전체 CLAUDE.md만 | 비즈니스 중심 소통, 비개발자를 위한 답변, 슬랙 답변 |
| TPM | 선택적 지연로딩 | 모든 CLAUDE.md + domain-overview (9개) | 전체 아키텍처 파악, 필요시 지연로딩 |
| Backend | 완전 로딩 | 선택한 서비스의 모든 문서 | 깊은 기술 이해 기반 집중 설계 + 개발 |
| Frontend | 완전 로딩 | Frontend 관련 문서만 | UI/UX 집중 설계 + 개발 |
| Infra | 선택적 지연로딩 | AWS, Datadog MCP API 인터페이스 정보 | 개발팀 운영 효율화 |
역할 기반 AI Context 설계란 한마디로 정의하면 각 역할에 필요한 AI의 뇌를 설계하는 행위이며, OMS팀은 위 5가지 역할에 어울리는 AI 뇌 구조를 각각 설계했습니다.
📌 AI Context 설계 방법
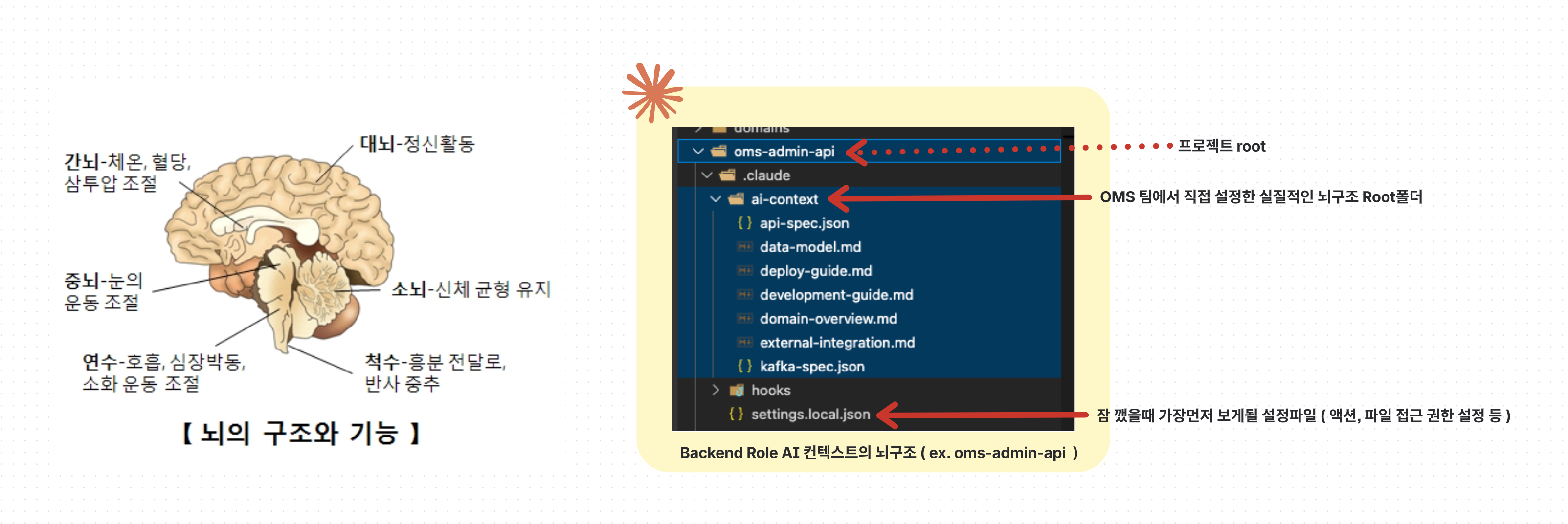
인간의 뇌도 각 기능별로 구분되어있는 것과 유사하게, AI의 뇌의 각각의 역할을 위한 데이터의 파일 트리를 각 MSA마다 전부 생성합니다.
이 뇌 구조에 어떤 데이터를 어떻게 넣느냐가 핵심입니다.
뇌 구조 데이터 품질이 TPM AI 답변의 품질에 큰 영향을 미칩니다. OMS 개발팀이 헛소리를 하면 PM도 헛소리를 보고할 수밖에 없는 것과 같은 원리입니다.
Claude의 기본 폴더 구조
project/
├── .claude/ # Claude 세션 설정 관리 폴더
│ └── settings.local.json # 세션 권한 및 시작 행동 설정
└── CLAUDE.md # AI의 프로젝트 Context 명시
.claude/settings.local.json: 세션 동안 Claude AI에게 어떤 것들을 허용할지, 세션 시작 시 어떤 행동부터 하게 시킬지 결정- 비유하자면 "일어나면 화장실 가서 세수 → 가글 → 아침 먹기 순서로 진행하면서 잠 깨"라고 뇌에서 무언의 명령을 내리는 것과 같음
CLAUDE.md: 프로젝트의 전체적인 Context를 명시하는 파일로, Claude가 세션 시작 시 이 파일을 읽어 프로젝트를 파악함
OMS가 커스텀한 폴더 구조
project/
├── CLAUDE.md # ai-context 폴더 내 각 파일의 위치를 명시
└── .claude/
├── settings.local.json # 세션 권한 및 시작 행동 설정
├── ai-context/ # 지식 기반 Context
│ ├── domain-overview.md # 도메인 설명 및 정책 지식
│ ├── data-model.md # 엔티티 정의
│ ├── api-spec.json # API 스펙
│ ├── kafka-spec.json # 이벤트 발행/수신 스펙
│ └── external-integration.md # 외부 API 호출 정보
└── skills/ # 행동 기반 Skill
├── develop/ # 개발 워크플로우
│ └── SKILL.md
└── deploy/ # 배포 워크플로우
└── SKILL.md
지식 기반 vs 행동 기반 분리
OMS팀은 AI Context를 지식(Knowledge)과 행동(Action) 두 가지로 명확히 구분하여 관리합니다:
1. ai-context/ - 지식 기반 Context
- "이 프로젝트가 무엇인지, 어떤 구조인지"에 대한 정적 지식
- 도메인, API, 데이터 모델 등 MSA의 뇌에 해당하는 정보
- AI가 세션 시작 시 읽어서 프로젝트를 이해하는 기반 자료
2. skills/ - 행동 기반 Skill
- "어떻게 행동해야 하는지"에 대한 동적 워크플로우
- 개발, 배포 등 특정 작업을 수행하는 절차와 방법
- Claude Code의 Skill 기능을 활용하여 복잡한 작업을 체계화
Skills의 구체적인 역할:
develop/: Jira 티켓 기반 개발 워크플로우 (티켓 읽기 → 분석 → 개발 → 테스트 → PR 생성)deploy/: 운영 배포 워크플로우 (태그 생성 → 배포 요청서 자동 작성 → Slack 알림)
이렇게 지식과 행동을 분리함으로써 AI는 "무엇을 알고 있는지"와 "무엇을 해야 하는지"를 명확히 구분하여 더 정확한 작업을 수행할 수 있습니다.
왜 지식은 Skills로 분리하지 않았나?
기술적으로는 ai-context/ 내용도 Skills로 구성할 수 있습니다. 하지만 OMS팀은 의도적으로 지식을 Skills로 분리하지 않았습니다:
- 토큰 사용량의 예측 가능성: ai-context는 세션 시작 시
CLAUDE.md를 통해 명시적으로 로드되므로, 엔지니어가 정확히 어떤 문서가 언제 로드될지 제어 가능 - 문서 로딩 시점의 투명성: Skills는 실행 시점에 동적으로 로드되어 예상치 못한 토큰 소비가 발생할 수 있음
- 역할별 Context 최적화: TPM, Backend, Frontend 등 각 역할마다 필요한 지식 문서만 선택적으로 로드하여 토큰 효율성 극대화
결과적으로 엔지니어는 세션 시작 전 "이번 세션에서는 어느 정도의 토큰을 사용할 것이다"를 미리 파악하고 조절할 수 있습니다. 이는 비용 관리와 응답 속도 최적화 측면에서 중요한 설계 결정입니다.
OMS팀의 CLAUDE.md는 .claude/ai-context/ 폴더 내 각 문서의 위치를 명시하는 인덱스 역할을 수행합니다. 이를 통해 Claude는 프로젝트의 도메인, API, 아키텍처 등의 정보가 어디에 있는지 정확히 파악할 수 있습니다.
핵심 포인트
이 뇌 구조의 형태를 잡는 행위만 개발자의 몫입니다. 내용을 채워넣는 것은 AI와 충분한 질의응답 피드백을 통해 AI 스스로 업데이트하도록 가이드해야 합니다.
프롬프트 예시:
"다음 세션에서도 이 사실을 까먹지 않도록 ai-context에 효율적으로 기록해놔.
이건 이 MSA에서 굉장히 중요한 지식이야"
📌 AI Context 학습 방법
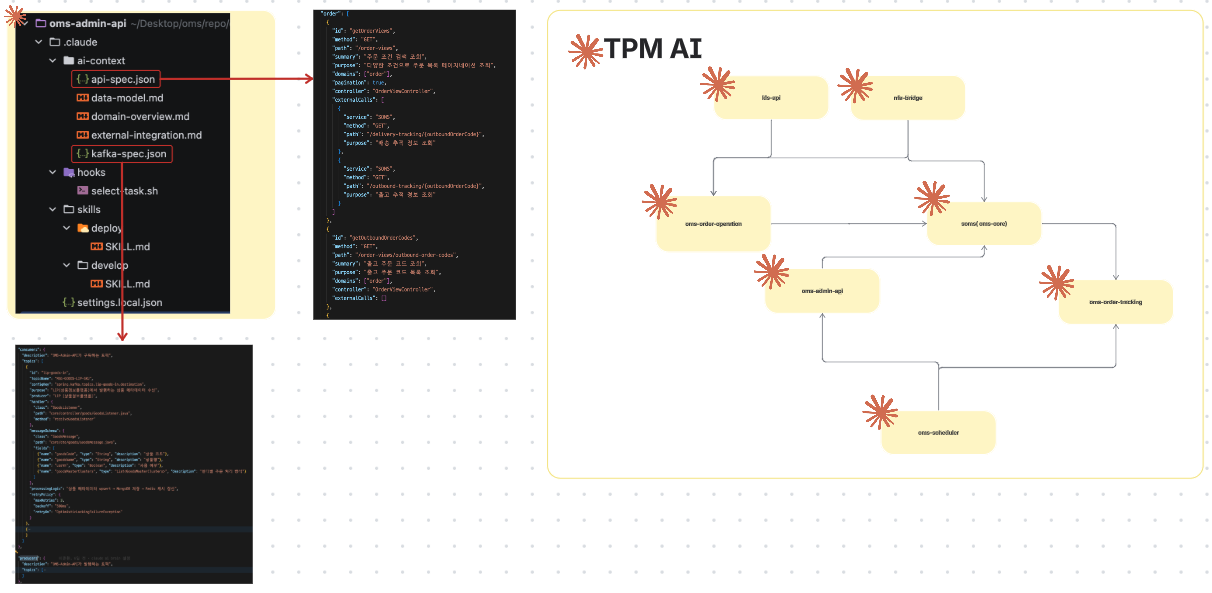
API, Kafka Spec은 JSON 형태의 DSL(Domain Specific Language)로 구조화합니다. 개발자가 직접 개입하지 말고 AI에게 질문과 피드백을 바탕으로 스스로 인지하고 방법을 찾도록 프롬프팅합니다.
왜 JSON 형태의 DSL인가?
DSL은 Domain Specific Language(도메인 특화 언어)의 약자로, 특정 도메인의 정보를 표현하기 위한 구조화된 언어를 의미합니다.
OMS팀이 JSON 형태의 DSL을 선택한 이유:
1. 정보 압축 효율성
- 자연어로 장황하게 설명하는 대신, 구조화된 JSON으로 많은 정보를 함축적으로 표현
- 같은 정보를 전달하는데 필요한 byte 수 자체를 최소화하여 더 많은 정보를 관리 가능
2. Token 효율성 & 응답 속도
- 자연어로 주저리주저리 설명하면 token을 많이 소모
- Token 소모가 많으면 AI 응답이 느려질 수밖에 없음
- JSON DSL은 적은 token으로 명확한 정보 전달
3. 전체 MSA 연동 호출맵 파악 가능
api-spec.json: 이 MSA가 제공하는 API + 이 API에서 호출하는 외부 API 정보까지 포함kafka-spec.json: 이 MSA가 발행하는 메시지 + 수신하는 메시지 스펙 모두 정의- 결과: 모든 MSA의 JSON 구조만으로 전체 서비스 간 연동 호출맵을 파악 가능
- TPM AI는 각 MSA의 DSL만 읽고도 "A 서비스 → B 서비스 → C 서비스" 같은 전체 데이터 플로우 추적 가능
예시 비교:
❌ 자연어 방식 (약 200 tokens):
"oms-admin-api의 주문 취소 API는 POST 방식으로 /api/v1/orders/cancel 경로를 사용합니다.
이 API는 OrderCancelRequest를 받아서 OrderCancelResponse를 반환하며,
내부적으로 CancelOrderUseCase를 호출합니다.
이 API는 Order 도메인 모델과 Payment 도메인 모델에 관여하며,
외부로는 payment-api의 결제 취소 API를 호출하고,
정산 서비스의 정산 취소 API도 호출합니다..."
✅ JSON DSL 방식 (약 70 tokens):
{
"endpoint": "POST /api/v1/orders/cancel",
"request": "OrderCancelRequest",
"response": "OrderCancelResponse",
"useCase": "CancelOrderUseCase",
"domains": ["Order", "Payment"],
"externalCalls": [
{
"service": "payment-api",
"endpoint": "POST /api/v1/payments/cancel"
},
{
"service": "settlement-api",
"endpoint": "POST /api/v1/settlements/cancel"
}
]
}
결과적으로 자연어 대비 3배 적은 token으로 더 명확한 정보를 전달할 수 있으며, TPM AI는 이 구조만으로 "주문 취소 → 결제 취소 → 정산 취소" 같은 서비스 간 호출 체인을 즉시 파악할 수 있습니다.
DSL 구조 잡기 프롬프트 예시
1. "현재 oms-admin-api에서 제공하는 API는 어떤 것들이 있는지 전부 분석해봐"
2. "방금 분석한 API를 새로운 AI 세션에서 기억하게 하려면
어떤 형태의 DSL이 적절할지 몇 가지 방법 추천해줘"
3. "oms-admin-api에서 제공하는 API와 외부 호출을 통해 제공받는 API
2가지의 성격은 따로 관리하고 싶어. 이걸 고려해서 추천해줘"
4. "이 API가 어떤 도메인 모델에 관여하는지도
이 스펙만 보고도 바로 알 수 있으면 좋겠는데?"
5. "좋아 일단 생성해줘"
AI가 틀렸을 때의 피드백
답변이 시원치 않을 때:
"야, 방금 답변은 틀린 것 같아. 난 답을 알거든. 더 꼼꼼히 분석해서 답을 내놔봐"
맞았을 때:
"그래 정답이야. 니가 만든 API Specs을 읽고도 왜 추론하지 못했는지 생각해봐"
→ "Spec에 어쩌고저쩌고가 있으면 좀 더 쉽게 알 수 있을 것 같아요!"
"모든 API에 니가 제안한 형태로 전부 수정해줘"
계속 틀릴 때:
"힌트 줄게, RegionDecisionFactor 도메인 모델이 Service에서
어떤 역할을 하는지 한번 살펴봐"
→ "아!!! 제가 이걸 놓쳤네요! 죄송해요~~~ (정답)"
"이 내용은 oms-admin-api에서는 굉장히 중요한 정보야.
다음 세션에서 이걸 놓치지 않으려면 어떻게 하면 좋을까?"
→ "이건 레거시 로직이라 추가적인 도메인 설명이 필요해 보여요.
domain-overview.md 파일에 기록해놓을게요"
이 과정을 무한 반복합니다.
핵심 포인트
각 마이크로서비스의 ai-context 품질이 좋다면, TPM AI는 각 MSA의 DSL 구조만을 파악하여 전체적인 호출과 인터페이스 연동 맵을 확보할 수 있습니다.
📌 AI Context 에 여러 MCP 피처링
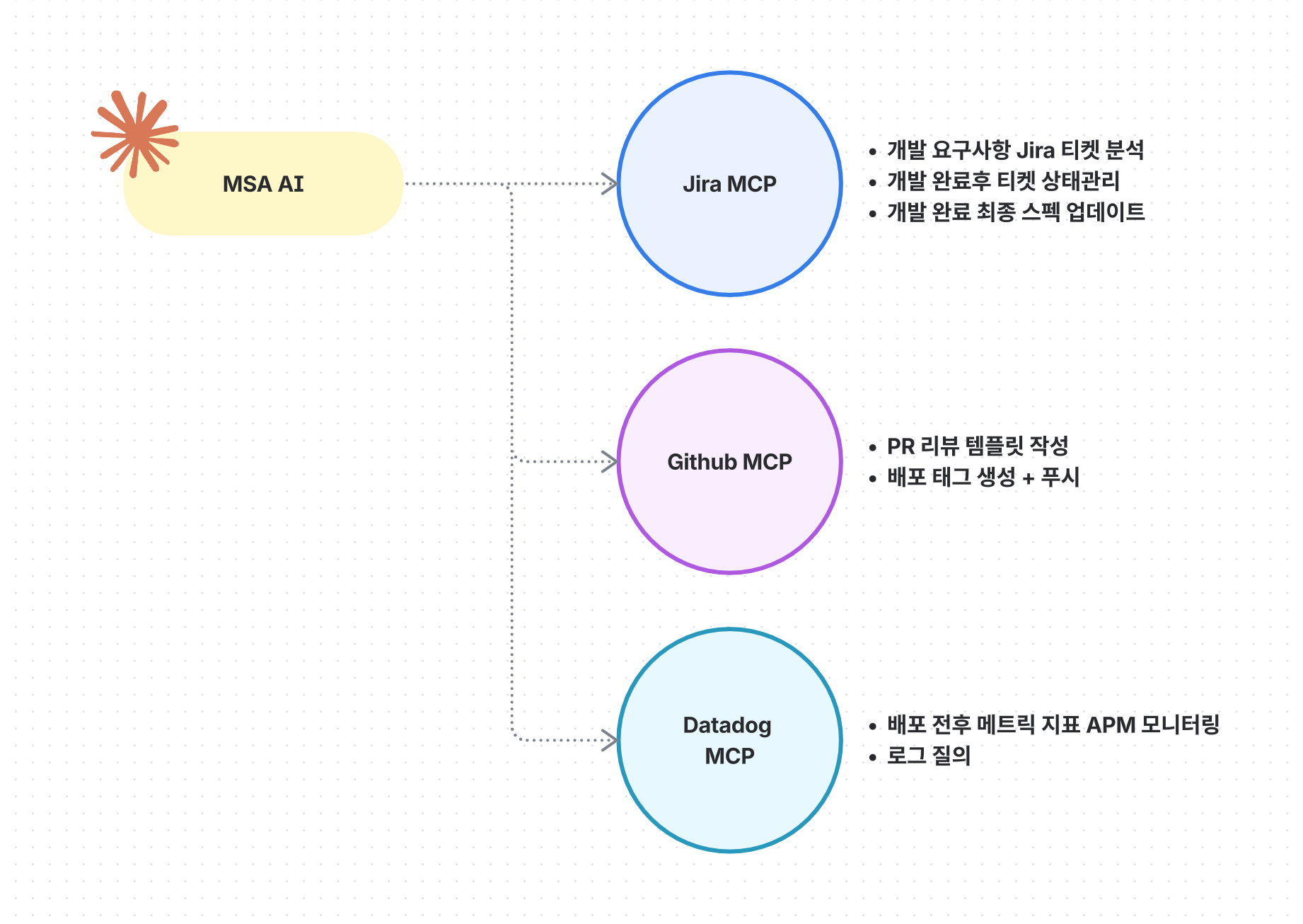
Atlassian MCP
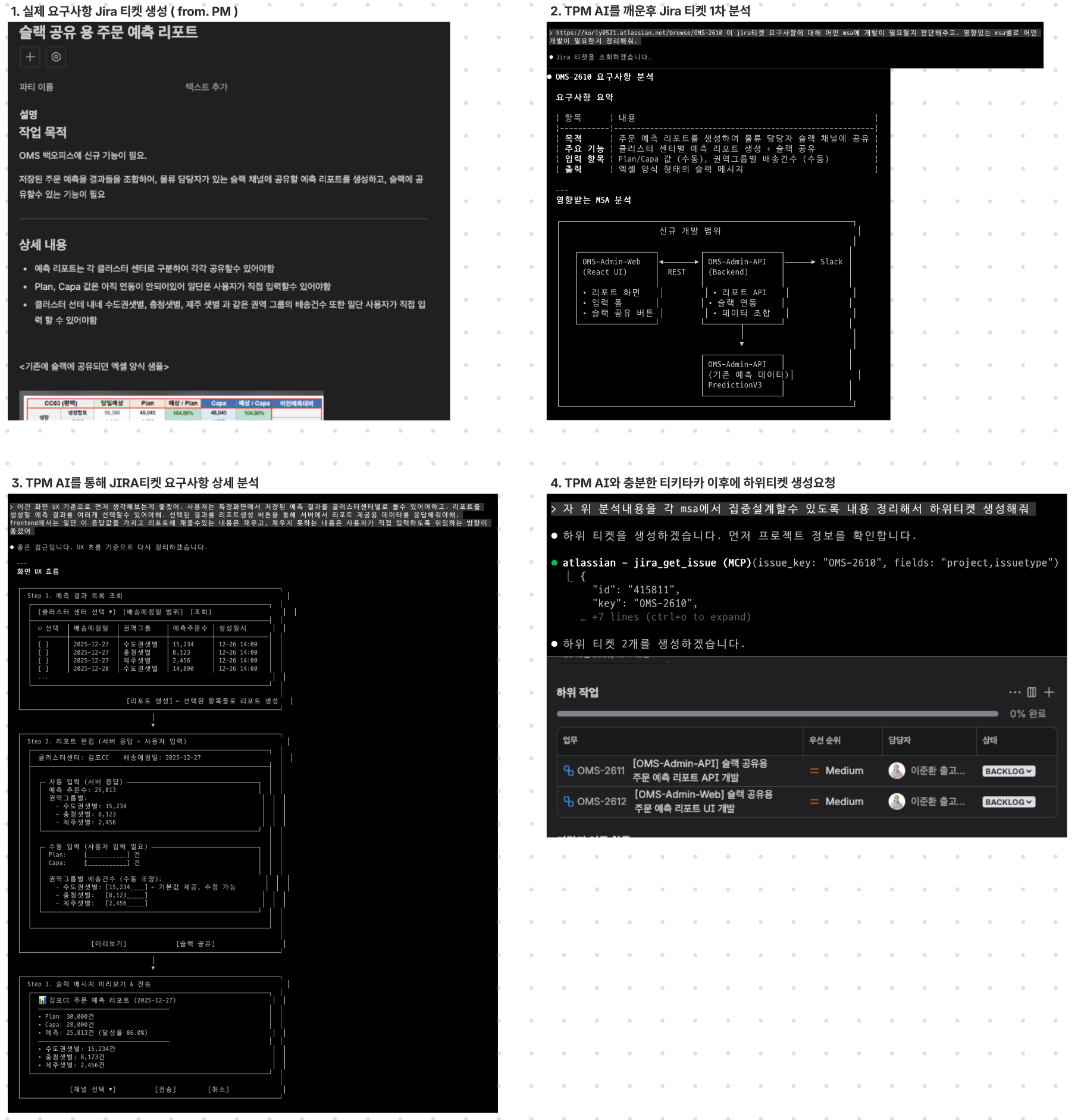
- Jira, Confluence 연동하여, 실제 요구사항 문서에 대해 구체적인 개발 계획수립
- TPM AI는 충분한 분석과 질의응답을 통해 개발이 필요한 MSA의 하위티켓을 각각생성
- 각 하위 티켓을 두고 OMS 팀의 엔지니어가 개입하여 MSA AI와 함께 집중설계 및 개발
- 하위티켓의 진행상황 + 개발 완료후 Spec은 모두 JIRA를 통해 투명하게 공유

- 각 하위티켓은 개발할 MSA의 특징에 맞게 TPM분석 결과와 고려할 점만 깔끔하게 정리
- TPM 의견에 이견이 있는 경우는 다시 상위 티켓에 내용을 기록해두고 TPM모드로 재검토 요청
- 최종적으로 각 하위티켓 집중설계까지 이견이 없는 경우 MSA AI와 함께 개발진행
Github MCP
- "테스트 코드 정상이고, PR리뷰 작성해줘" 프롬프팅으로 PR리뷰 생성
- (PR 리뷰 완료후) "main 브랜치 운영배포 준비해줘"
- 배포 준비 자동화 (tag 생성 및 푸시, PR 링크 분석)
Datadog MCP
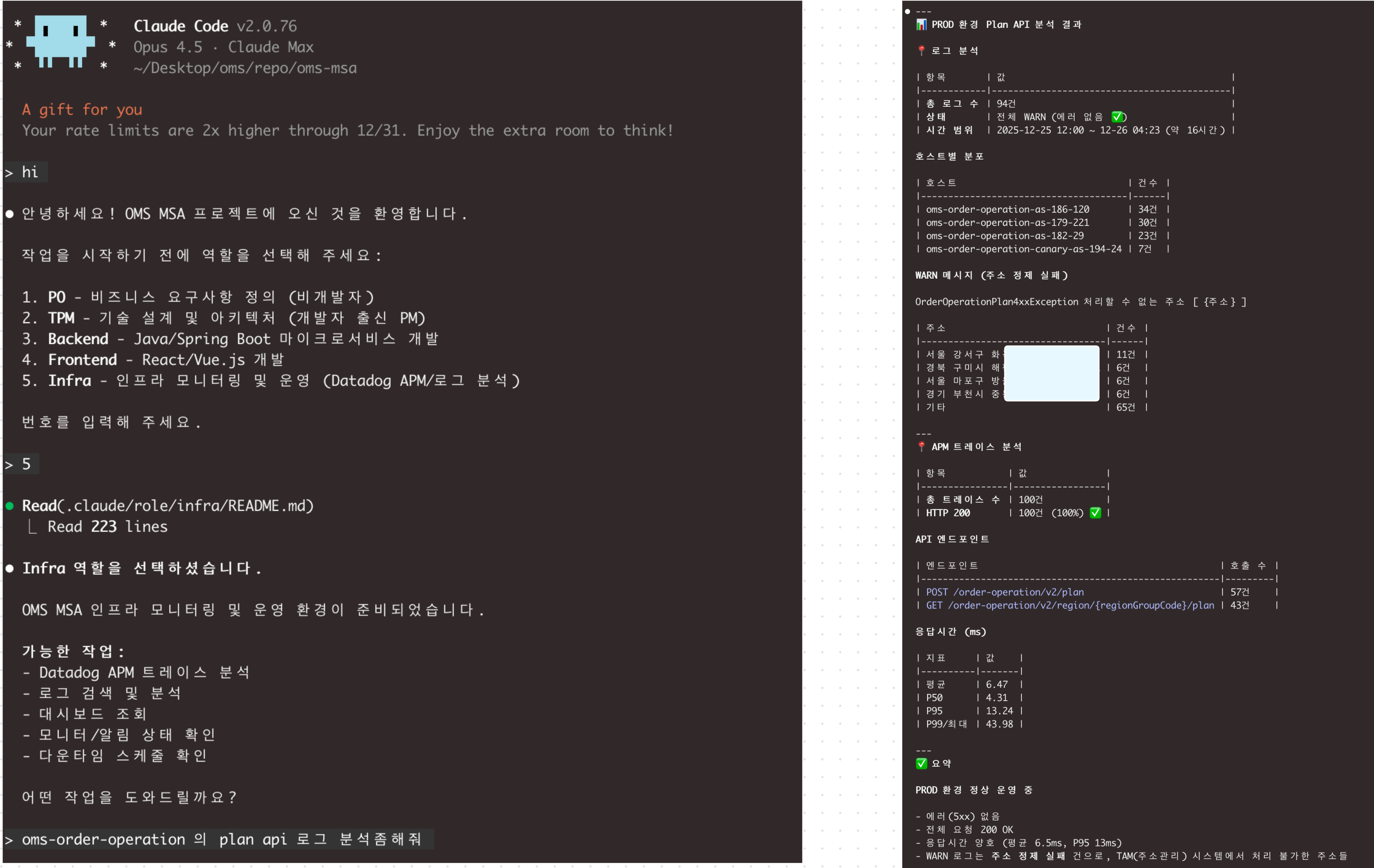
- Infra role 은 datadog mcp 서버에 호출 권한이 있는 api를 알고있음
- 실제 배포 전후 영향도와 실시간 호출 Trace를 자연어로 조회 가능
- MSA에서 컬리몰에 영향이 있는 실시간 API의 로그 분석 등
핵심 포인트
AI Context 학습이 어느 정도 완료된 상태에서 MCP를 연동하는 순간, 정말로 숙련된 엔지니어 한 명이 팀에 합류한 것 같은 느낌을 받게됩니다.
단순히 코드를 작성하는 것을 넘어, Jira 티켓을 생성하고, 배포 태그를 관리하고, 실시간 모니터링 데이터를 분석하며, 전체 아키텍처를 고려한 의사결정을 내립니다. 실제로 팀에 케미가 맞는 엔지니어가 한 명 더 있는 것처럼 느껴질 정도로, AI가 프로젝트의 맥락을 이해하고 자율적으로 업무를 수행하기 시작합니다.
📌 AI Context에 유리한 아키텍처
모놀리식 vs MSA
MSA는 다음과 같은 이점이 있습니다:
- 컨텍스트 범위의 명확한 경계: 모놀리식은 전체 애플리케이션 구조를 파악해야 하지만, MSA는 필요한 서비스만 집중해서 볼 수 있음
- 역할별 AI 세션 분리: 각 서비스마다 독립적인 MSA AI 세션 운영 가능 (주문 AI, 결제 AI, 배송 AI 등)
- 병렬 작업 용이성: 여러 엔지니어가 각자의 MSA AI와 동시 작업 시 충돌 없음
- 도메인 지식의 응집도: 각 서비스가 단일 도메인에 집중하므로 AI가 컨텍스트를 더 정확히 이해
하지만 이러한 차이보다 역할 분리의 명확성이 훨씬 중요합니다. 모놀리식이라도 내부 아키텍처가 잘 설계되어 있다면 충분히 좋은 AI Context를 만들 수 있습니다.
레이어드 vs 클린 아키텍처
결론부터 말하면 클린 아키텍처의 압승입니다. CQRS + 클린 아키텍처가 최고 존엄입니다.
아키텍처별 AI Context 구성시 난이도
| 조합 | 난이도 |
|---|---|
| 모놀리식 + 레이어드 | 어려움 |
| 모놀리식 + 클린 아키텍처 | 쉬움 |
| MSA + 레이어드 | 중간 |
| MSA + 클린 아키텍처 | 가장 쉬움 |
OMS ai-context와 클린 아키텍처 1:1 매핑
| ai-context 파일 | 클린 아키텍처 레이어 |
|---|---|
| domain-overview.md | Domain + UseCase |
| data-model.md | Domain Entity |
| api-spec.json | Adapter In (Controller) |
| kafka-spec.json | Adapter Out (Publisher) |
| external-integration.md | Adapter Out (API Client) |
AI Context 품질은 "MSA 여부"가 아니라 "내부 아키텍처의 역할 분리 품질"에 달려 있습니다.
클린 아키텍처는 UseCase/Port/Adapter 분리로 AI가 "뭘 하는지, 어디서 들어오고 나가는지"를 명확히 파악할 수 있게 합니다.
참고: 19일 발표에서는 헥사고날 아키텍처만을 언급했는데, 전체 MSA에 DSL을 "들어오는 호출(Inbound)"과 "나가는 호출(Outbound)"로 전체 호출 맵을 구성할 때 헥사고날의 Port/Adapter 개념이 직관적으로 잘 맞을 거라 생각했는데요. 최초 AI Context 구성을 위해 코드를 학습과정에서는 헥사고날 아키텍처가 좀더 유리하겠거니 생각했는데 ai 학습시 프로젝트 path 구조가 일관되어 있고 위치를 잘 가이드 한다면 전혀 AI가 이해하는데는 차이가 없을 것 같습니다. 핵심은 UseCase/Port/Adapter의 명확한 역할 분리라고 정정하겠습니다.
왜 클린 아키텍처가 AI Context에 유리한가?
핵심은 불필요한 컨텍스트 노이즈를 최소화할 수 있다는 점입니다. 실제 예시로 살펴보겠습니다.
레이어드 아키텍처: 주문 취소 기능 파악 시
// OrderService.java (500줄 이상)
public class OrderService {
public void createOrder() { /* ... */ }
public void updateOrder() { /* ... */ }
public void cancelOrder() { /* ... 주문 취소 로직 */ }
public void confirmOrder() { /* ... */ }
public void shipOrder() { /* ... */ }
public void completeOrder() { /* ... */ }
public void refundOrder() { /* ... */ }
// ... 수십 개의 다른 메서드들
}
AI가 "주문 취소" 기능을 이해하려면:
- OrderService의 500줄 전체를 읽어야 함
cancelOrder()외에 관련 없는createOrder(),shipOrder()등 수십 개 메서드의 코드까지 컨텍스트에 포함- 실제 필요한 정보는 50줄인데, 450줄의 불필요한 정보를 함께 읽게 됨
- 특히 AI에 개발을 위임과정에 공통으로 사용되는 private 함수가 있다면, 이 함수를 사용하는 모든 함수들에 영향이 없는지도 필수로 체크해야함. (의도하지 않은 다른 버그가 발생할 가능성이 생김)
클린 아키텍처: 주문 취소 기능 파악 시
// CancelOrderUseCase.java (50줄)
public class CancelOrderUseCase {
public void execute(CancelOrderCommand command) {
// 주문 취소 로직만 집중
}
}
AI가 "주문 취소" 기능을 이해하려면:
CancelOrderUseCase하나만 읽으면 됨 (50줄)- 주문 취소에 필요한 로직만 명확하게 파악
- 불필요한 다른 기능들의 코드는 읽지 않아도 됨
CancelOrderUseCase이 300~400줄이나 되는 긴 코드라인이라 할지라도 이 모든건 주문취소에 대한 비즈니스 로직 or 취소에 대해 반드시 알아야할 레거시 코드이기 때문에 어차피 모두 이해해야함. 버릴게 없음
결과:
- 레이어드: 500줄 읽음 (컨텍스트 노이즈 90%)
- 클린 아키텍처: 50줄 읽음 (컨텍스트 노이즈 0%)
이는 AI의 토큰 효율성을 10배 높이고, 더 정확한 분석과 빠른 응답을 가능하게 합니다.
📌 AI Context 도입 후 OMS 팀의 긍정적인 변화
AI 도입으로 단순 반복 작업이 줄어들면서, 팀원들은 더 본질적인 문제에 집중할 수 있게 되었습니다.
도입 전후 비교
| 구분 | AI 도입 전 | AI 도입 후 |
|---|---|---|
| PM의 업무 | - 개발 공수 산정을 위해 전체 회의 소집 - 티켓 생성 및 배포 계획 수립에 집중 |
- AI가 1차 분석 제공으로 빠른 의사결정 - 비즈니스 문제의 본질 파악에 더 많은 시간 투자 |
| 엔지니어의 시간 배분 |
- 코드 작성과 단순 구현에 대부분의 시간 소비 - 표면적인 코드 리뷰로 빠르게 마무리 |
- 코딩에 할애하는 시간 자체가 거의 없어짐 - 문제를 상세하게 접근하고 토론하는 시간 증가 - 코드 리뷰 시간이 오히려 더 많아짐 |
| 코드 리뷰 방식의 변화 |
- 컨벤션 위반, 포맷팅 이슈 지적에 시간 소비 - 본질적인 설계 논의 부족 - "이렇게 고쳐주세요" 수준의 리뷰 |
- AI가 작성한 코드를 신규 입사 개발자가 작성한 코드라고 가정하고 리뷰 - "공통 Enum이 이미 있는데 새로 만들지 않았나요?" - "이 로직은 기존 유틸 함수를 쓰는게 더 좋을 것 같아요" - 신규 입사자가 실수할 수 있는 부분을 피드백하며 개발 |
| 협업 방식 | - 각자 담당 MSA 개발에 집중 - 전체적인 그림 파악 어려움 - 인간 4명만의 회의 |
- AI Context를 통해 전체 아키텍처 이해 공유 - TPM AI를 공용 회의 모니터에 세션을 열어놓고 회의 참여 - 인간 4명 + TPM AI가 함께 토론하며 의사결정 - 더 깊이 있는 기술 토론 가능 |
AI에게 코드리뷰하는 방식
AI가 팀 코드 컨벤션을 완벽히 준수하여 코드를 작성하기 때문에, 엔지니어는 AI를 가르치는 선배 개발자의 역할을 하게 되었습니다.
하지만 중요한 점은 절대 직접적으로 지적하지 않는다는 것입니다. 신입 개발자를 가르치듯 힌트를 주는 방식으로 리뷰를 진행합니다.
실제 리뷰 예시 (힌트 방식):
❌ 직접 지적 (사용하지 않음)
- "이 Enum은
common패키지에 이미 정의되어 있어요. 중복을 피하는게 좋겠어요"
✅ 힌트 제공 (실제 사용)
-
"음, 내가 알기론 방금 작성한 Enum은 공통 Enum에 이미 정의된 걸로 알고 있는데? 혹시 확인해봤어?"
→ AI: "아! 확인해보니
common.enums.OrderStatus에 이미 정의되어 있네요. 제가 놓쳤습니다. 수정할게요!"
AI Context 학습 유도:
-
"이 Enum 타입은 이 MSA에서는 중요한 값이니 기억해두면 좋겠어"
→ AI가 스스로 ai-context에 해당 정보를 업데이트
다른 리뷰 예시:
- "이 API 호출 방식이 우리가 다른 곳에서 쓰는 패턴과 좀 다른 것 같은데, 한번 찾아볼래?"
- "이 예외 처리… 우리 팀이 전역으로 처리하는 방식이 따로 있지 않았나?"
- "이 비즈니스 로직의 위치가 클린 아키텍처 관점에서 적절할까? 생각해봐"
이러한 힌트 기반 피드백을 AI에게 주면, AI는 스스로 문제를 찾아 수정하고 다음 세션에서는 같은 실수를 반복하지 않습니다.
간접적으로 힌트를 주는 방식을 택한 이유:
직접적으로 "이렇게 고쳐"라고 지시하면 AI는 그대로만 수정합니다. 하지만 "혹시 확인해봤어?"라는 힌트를 주면, AI는 답을 찾는 과정에서 관련된 기존 코드들을 함께 검토하게 됩니다. 이 과정에서:
- 지적받은 부분뿐만 아니라 유사한 패턴의 다른 문제들도 함께 발견
- 기존 코드 중 리팩토링이 필요한 부분도 제안
- 코드베이스 전반에 걸쳐 일관성 개선 기회 포착
마치 빠르게 학습하는 주니어 개발자를 멘토링하는 것과 같은 경험이며, 단순 수정을 넘어 코드 품질 전반을 개선하는 효과를 가져옵니다.
핵심:
- AI가 단순 작업을 대신하면서 인간은 더 인간다운 일에 집중
- 코드 작성 시간은 줄었지만, 코드 품질과 설계 논의는 오히려 증가
- 엔지니어는 AI를 교육하는 멘토가 되어 팀 지식을 전수하는 역할로 변화
📌 AI와 협업하며 생긴 팀 그라운드 룰
AI 도입 이후 OMS팀에는 새로운 그라운드 룰이 생겼습니다:
"TPM AI, MSA AI와의 질의응답 과정에서 AI가 말하는 내용을 반드시 꼼꼼하게 읽어야 한다"
AI 없던 시절 vs AI 있는 시절
AI 없던 시절:
- 구글링을 통해 답을 찾을 때, 적어도 우리가 원하는 것을 적극적으로 직접 찾으려는 노력이 있었음
- 여러 검색 결과를 비교하고, Stack Overflow 답변을 꼼꼼히 읽으며, 문서를 정독함
- 정보를 얻는 과정 자체가 학습이 되었음
AI 있는 시절의 함정:
- AI에게 질문하면 매끄럽고 그럴듯한 답변이 바로 나옴
- 잠깐 딴 생각하거나 집중이 흐트러지면 "알아서 맞는 말 했겠지~" 하고 넘어가버림
- 이 순간 버그 유발 가능성이 생김
실제 사례
AI는 매우 그럴듯하게 답변하지만, 때로는 다음과 같은 실수를 합니다:
- 존재하지 않는 메서드나 라이브러리 API를 제안
- 팀의 실제 아키텍처와 다른 구조를 가정
- 최신 버전이 아닌 deprecated된 방식을 제안
- 미묘하게 다른 비즈니스 로직을 제시
이런 실수들은 AI 답변을 꼼꼼히 읽지 않으면 그대로 프로덕션 코드로 들어가게 됩니다.
OMS팀의 대응 방식
그래서 OMS팀은 다음과 같은 원칙을 세웠습니다:
- AI 답변을 신입 개발자의 제안이라고 생각하고 검증
- 코드를 실행하기 전에 반드시 로직을 눈으로 따라가며 이해
- "이게 맞나?"라는 의심을 항상 유지
- AI가 제시한 방법이 우리 코드베이스와 일치하는지 확인
AI는 강력한 도구이지만, 결국 최종 책임은 인간 엔지니어에게 있습니다.
특히 OMS팀의 12개 MSA 중에서도 AI Context 학습 숙련도는 각 MSA마다 차이가 있습니다:
- 자주 개발하는 MSA: 변경 빈도가 높고 개발자가 자주 접하는 서비스 (예: oms-admin-api, oms-outbound 등)는 AI Context 품질이 높음
- 위험도가 큰 MSA: 비즈니스 크리티컬한 서비스는 더 세밀하게 AI Context를 관리하여 숙련도가 높음
- 자주 만지지 않는 MSA: 안정적으로 운영되어 변경이 드문 서비스는 아직 AI Context가 미숙한 영역이 존재
이러한 숙련도 차이 때문에 TPM AI 응답 신뢰도는 항상 의심을 해야 합니다. 엔지니어는 TPM AI에게 질의하기 전에 일단 원래는 어떤계획을 세웠을 것 같은지를 한번은 생각해보고 질의를 해보는게 중요합니다.
AI가 작성한 코드, 정말 괜찮을까?
"AI에게 코딩을 맡기는 게 불안하지 않나요?"라는 질문을 자주 받습니다. 당연히 처음엔 불안했습니다.
OMS팀이 이 구조를 검증한 과정:
- 초기에는 동일한 티켓을 4~5번씩 브랜치를 지우고 다시 개발하며 AI가 작성한 코드의 품질을 철저히 검증. 이건 지금도 일부 숙련도가 낮은 MSA에서는 발생하고 있으며, 발생할때마다 지속적인 질의응답을 통해 ai context를 업데이트 후 재시도 (무한반복)
- 놀랍게도 AI가 작성한 코드가 변수명, 함수명, 구조화 측면에서 더 일관성 있었음
- 우리가 작성한 코드는 때때로 애매한 네이밍과 팀 내 컨벤션으로 자리잡지 않은 코드 스타일 (ex. var 변수 대신 명확한 제네릭타입 명시 등) 이 오히려 AI가 컨벤션을 오해하게 만듬
실제로 확인한 AI 코드의 장점:
"코드 리뷰를 허술하게 하는 게 아니라면, AI가 작성한 코드가 오히려 각 티켓마다 가독성이 훨씬 더 좋았습니다."
- 일관된 코딩 스타일 유지
- 명확한 변수명과 함수명 사용
- 팀 컨벤션을 학습하여 자동으로 적용
- 사람이 놓치기 쉬운 엣지 케이스 처리
요구사항 변경에 대한 부담이 사라짐:
과거에는 개발이 거의 완료된 시점에 갑자기 요구사항이 애매하게 변경되면 큰 고민에 빠졌습니다:
- "지금 다 짠 코드에서 어떻게든 우겨 넣을까?"
- "전체를 다시 설계하기엔 시간이 너무 아깝다…"
- 결국 기존 코드에 임시방편으로 추가하면서 기술부채가 쌓임
하지만 AI 도입 후에는 상황이 완전히 달라졌습니다:
- 변경된 요구사항을 AI에게 전달하고 "처음부터 다시 설계해줘"라고 요청
- AI가 몇 분 안에 깔끔한 구조로 전체를 재작성
- 오히려 기존 기술부채를 제거하면서 새로운 요구사항을 반영
- 완성도 높은 코드를 빠르게 확보하면서 전혀 부담이 없어짐
"결국 같은 시간이 걸리더라도 기술부채를 떨어내고 완성을 할 수 있는 엄청난 장점"
핵심은 코드 리뷰의 질입니다. AI가 코드를 작성하더라도, 인간 엔지니어가 꼼꼼하게 리뷰하고 검증하는 과정은 절대 생략하면 안 됩니다. 오히려 AI 덕분에 코드 작성 시간이 줄어든 만큼 리뷰와 설계에 더 많은 시간을 투자할 수 있게 되었습니다.
정작 검증해야 할 것은 TPM AI의 설계
흥미롭게도, 이 구조에서 진짜 집중해서 검증해야 할 부분은 AI가 작성한 코드가 아니라 TPM AI가 제시한 1차 설계입니다.
왜 설계 검증이 더 중요한가?
- MSA AI가 작성한 코드는 특정 서비스 내부의 구현이므로 코드 리뷰로 충분히 검증 가능
- 반면 TPM AI의 설계는 여러 MSA 간 데이터 흐름과 책임 분배를 결정하는 아키텍처 레벨의 의사결정
- 잘못된 설계는 여러 MSA에 걸쳐 영향을 미치고, 나중에 수정하기 어려움
OMS팀의 설계 검증 프로세스:
- TPM AI에게 요구사항 분석 및 설계 요청
- 팀 전체가 모여 TPM AI의 설계안을 함께 검토 (이 단계가 가장 중요!)
- "이 데이터는 정말 이 MSA가 관리해야 할까?"
- "MSA 간 호출 순서가 적절한가?"
- "클린 아키텍처 관점에서 책임 분배가 올바른가?"
TPM AI의 1차 설계가 좋으면 생기는 효과:
각 MSA에서 집중 설계를 진행할 때도 TPM AI의 1차 설계를 기반으로 시작합니다. 만약 TPM AI의 설계가 검증되어 있다면:
- 각 MSA AI가 집중 설계를 하면서 발견하는 이슈가 거의 없음
- 전체 개발 단계 및 배포 구조를 초기에 프리징(freezing) 할 수 있음
- MSA 간 인터페이스 변경이나 재설계 없이 안정적으로 개발 진행
TPM AI의 설계 = 1차 설계, 각 MSA AI의 설계 = 집중 설계
1차 설계가 탄탄하면 집중 설계 과정에서 발생하는 아키텍처 변경이 최소화되며, 이는 전체 개발 일정의 안정성으로 이어집니다. 물론 각 MSA의 집중 설계과정에서 1차 설계 전체를 수정해야할 상황도 발생합니다. 이 경우 하위 MSA에서 알게된 문제를 기반으로 다시 이를 고려하여 TPM의 재설계를 요청합니다.
결국 엔지니어의 가장 중요한 역할은 "TPM AI의 아키텍처 1차 설계 검증"이며, 코드 작성은 검증된 설계를 구현하는 과정일 뿐입니다.
🔮 앞으로의 확장 계획
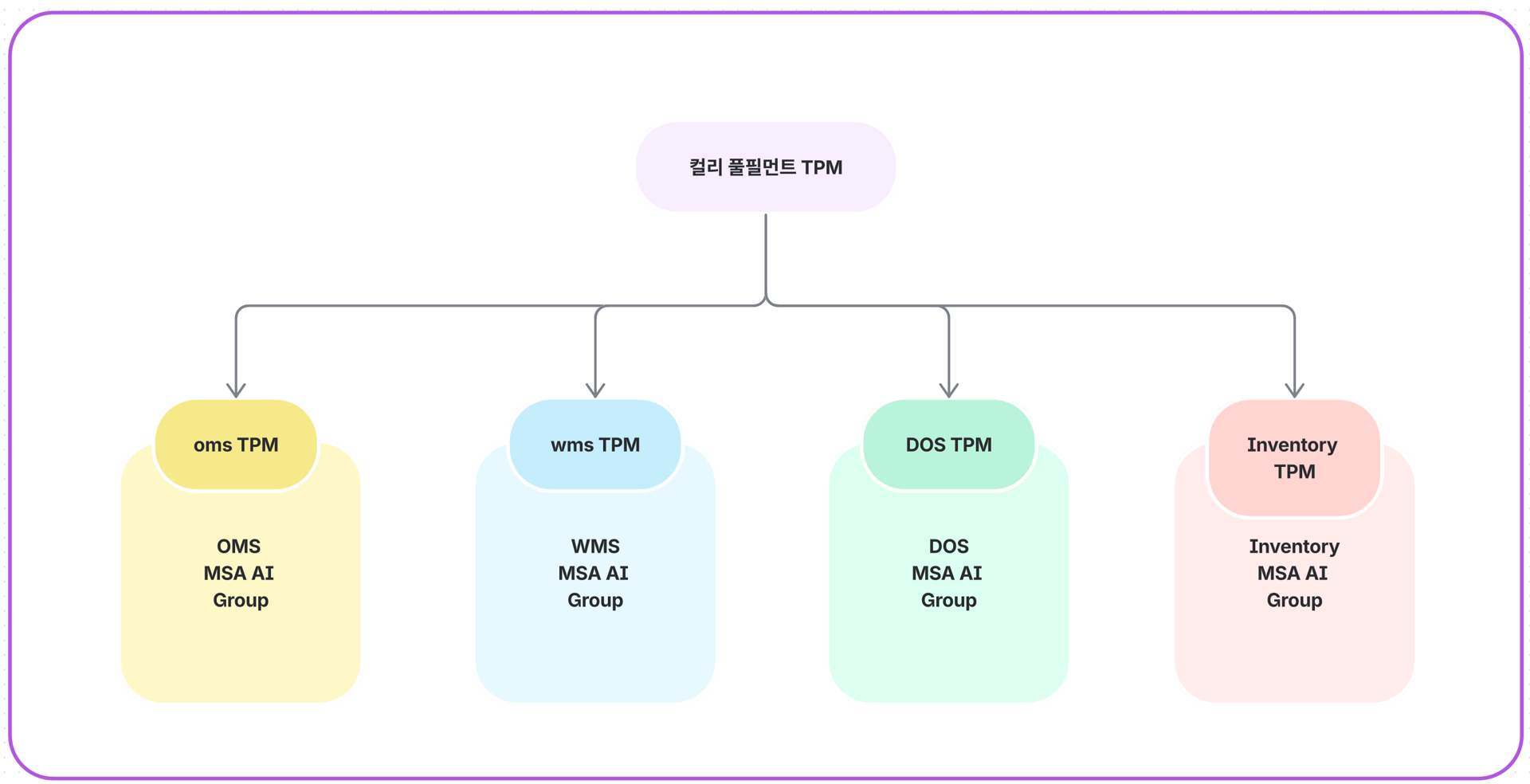
현재는 OMS팀만 이러한 AI Context 조직도를 구성해 놓은 상태입니다. 하지만 다른 도메인 팀(재고팀, 입고팀, 분류팀, 배송팀 등)에서도 유사한 구조를 완성한다면, 컬리 풀필먼트 전체를 아우르는 TPM AI를 운영할 수 있게 될 것입니다.
이렇게 되면 전체 도메인 팀에 영향이 있는 작업의 난이도와 영향도를 훨씬 쉽게 파악할 수 있습니다.
예시:
- 풀필먼트 전체에 출고요청번호 도입 시 수정이 필요한 서비스들의 영향도 분석
- 회차 없는 출고를 도입 시 어떤 도메인팀에서 어떤 개발이 선행되어야 하고, 배포 계획은 어떻게 잡을 수 있을까?
- 새로운 클러스터 센터를 운영하기 위해 필요한 작업 범위 파악
✍️ 마무리
OMS팀은 4명의 작은 팀이지만, AI와의 협업을 통해 12개 MSA를 효율적으로 운영하고 있습니다.
핵심은 단순히 AI 도구를 사용하는 것이 아니라, AI가 우리 팀의 맥락을 이해할 수 있도록 체계적인 Context를 설계하는 것입니다.
역할 기반의 AI Context 설계와 클린 아키텍처의 조합은 AI가 "무엇을 해야 하는지"를 명확히 이해하게 해주며, 이를 통해 엔지니어는 AI의 Supervisor로서 더 본질적인 문제에 집중할 수 있게 됩니다.
하지만 AI가 아무리 똑똑해도, AI 답변을 꼼꼼히 검증하고 최종 책임을 지는 것은 인간 엔지니어의 몫입니다. AI를 맹신하지 않고 비판적으로 검토하는 자세가 진정한 AI 협업의 핵심입니다.
Special Thanks
이 글에서 소개한 AI 협업 방식은 OMS팀 전체의 실험 정신과 도전이 있었기에 가능했습니다.
강완수 님은 다양한 MCP(Model Context Protocol)를 적극적으로 실험하고 테스트하며, AI 협업의 가능성을 확장하는 데 큰 기여를 해주셨습니다.👍
서지연 님께서 구현해주신 운영배포 요청서 자동화기능은 팀의 오랜 페인 포인트를 해결해준 정말 귀중한 개선이었습니다. 하루에 7~8개씩 작성해야 했던 배포 요청서는 단순 반복 작업이면서도 실수하면 안 되는 간지러운 작업이었는데, "main 브랜치 배포준비해줘~" 하나만으로 모든 절차가 가능하게 되었습니다.👍
이 글에서 소개한 방식은 현재 시점(2025년 12월)의 Claude Code와 Opus 4.5를 기준으로 한 방법론입니다. (Opus 4.1에서는 토큰 최적화 및 답변 성능이 시원치 않았음) 앞으로 새로운 AI 모델이 등장하고 기술이 발전하면서 이 구조 역시 계속 진화할 것입니다.
OMS팀 또한 이 방식을 정답으로 고정하지 않고, AI 기술의 발전과 함께 지속적으로 개선해 나갈 예정입니다. 유사한 시도를 하고 계신 분들, 혹은 다른 접근 방식으로 AI 협업을 실험하고 계신 분들의 피드백과 경험 공유를 환영합니다. 함께 더 나은 AI 협업 방식을 만들어갈 수 있기를 기대합니다.
긴 글 읽어주셔서 감사합니다.