주문을 모니터링 하는 개발팀, 출처 : GIPHY
들어가며
컬리 개발팀은 24시간 운영되는 마켓컬리 쇼핑몰과 잠들기 전에 주문한 상품을 다음 날 아침 바로 받아 볼 수 있는 샛별 배송 서비스를 문제없이 제공하기 위해 각고의 노력을 하고 있습니다.
게다가 가파른 성장 곡선 덕분에 주문 시스템의 이상 여부, 각 주문의 상태 현황과 처리 과정, 상품과 주문 통계를 수집하는 실시간 모니터링 시스템에 대한 필요성도 나날이 높아지고 있었습니다.
이 글에서는 Legacy 시스템에서 실시간 주문 정보를 Kafka에 적재하여 Elasticsearch로 전환하는 과정을 소개하고자 합니다.
느린 속도! 반복되는 장애!
Legacy 시스템에서는 다음과 같은 문제들이 있었습니다.
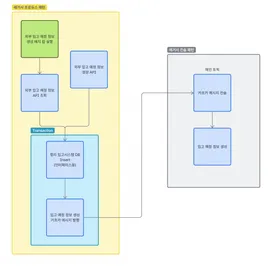
- 주문량이 몰릴 경우 주문서 검색이 되지 않는 현상
- 시간 단위로 분할하여 검색 해야 함
- 데이터 정합성 이슈로 인해 검색되지 않는 현상
위와 같은 문제로 운영팀에서 잦은 버그 제보가 쏟아졌습니다.
느린 속도의 주요 원인은 다름 아닌 복잡하고 느린 쿼리였습니다.
복잡하고 느린 쿼리
간단하게 쿼리를 요약해 본다면 다음과 같습니다.
SELECT
(SELECT IF(...) FROM order AS ... WHERE ... ORDER BY ... ),
EXISTS (select ... from ... where ... ),
EXISTS (select ... from ... where ... (select ... from ... where ...)),
COUNT(distinct(...)),
SUM(...),
(SELECT COUNT(...) FROM ... WHERE ... LIKE ...)
FROM
main_table
LEFT JOIN join_table_a ON ...
LEFT JOIN join_table_b ON ...
LEFT JOIN join_table_c ON ...
LEFT join join_table_d ON ...
LEFT join join_table_e ON ...
LEFT JOIN join_table_f ON ...
WHERE
date_column BETWEEN "2020-02-01 23:00:00" AND "2020-02-02 00:59:59"
AND (... in (...) and ..column... )
GROUP BY ...
HAVING ...7개 이상의 테이블 조인4개 이상의 서브 쿼리Group byHAVINGsum()count()distinct
주문 리스트를 확인 하면서 테이블 전체 범위를 처리하는 sum, count 함수와 정렬을 발생시키는 distinct를 사용하고, 많은 테이블 조인과 서브 쿼리, Group by와 Having을 사용하고 있었습니다.
또한 주문서 리스트 검색 버튼을 누르면 응답이 올 때까지 무한 대기하는 구조였기 때문에 타임아웃이 발생하여 시스템에 많은 부하를 주었습니다.
복잡하게 얽힌 스파게티 코드

출처 : Unsplash
복잡한 쿼리들과 함께 2,000라인 이상의 비즈니스 로직과 뷰가 하나의 파일에 환상적으로 합쳐져 있는 구조였습니다.
ORM이 아닌 복잡한 쿼리문을 수많은 조건문을 통해 문자열로 생성 하기 때문에 가독성이 낮아 개발자의 튜닝 의욕을 상실시켰습니다.
물론 서비스는 지속적인 운영이 필요했기 때문에 스케일업하여 운영하였지만, 앞으로도 급속도로 성장할 서비스 규모를 고려하여 개선 작업에 착수하게 되었습니다.
개선 작업에 착수하다
성능과 유실을 보장하는 Kafka를 중심으로 Kibana 대시보드 구현
Legacy 시스템에서 모니터링을 하기 위해선 많은 공수가 필요하다고 판단했습니다.
그리고 새로 개발하게 되더라도 자칫 모니터링 개발에만 매달리게 될 것 같았습니다.
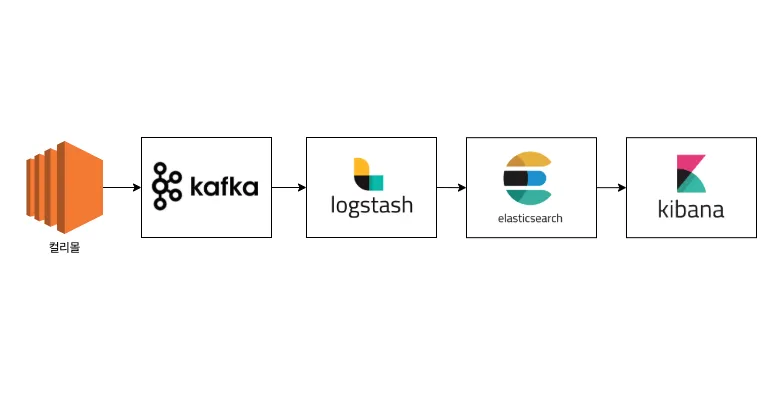
따라서 Application에서 주문 도메인에 Event가 발생할 때마다 Kafka에 실시간으로 데이터를 적재하기로 하고 ELK를 통해 대시보드를 구현하게 되었습니다.
사내에는 이미 Kafka와 ELK를 통한 데이터 저장/분석 플랫폼이 구축되어 있었기 때문에 Application과 Kafka의 연동과 전송할 데이터 구조 및 Kibana 대시보드 구현에만 집중 할 수 있었습니다.
개선 작업에 Kafka를 사용해보는 것은 어떨까?
Kafka는 링크드인의 고민을 통해 탄생한 분산 스트리밍 플랫폼입니다.
메시지 큐를 스트림으로 publish & subscribe 하며 내결함성과 같은 데이터 유실 방지를 위한 구조를 갖추고 메시지 전달을 보장합니다.
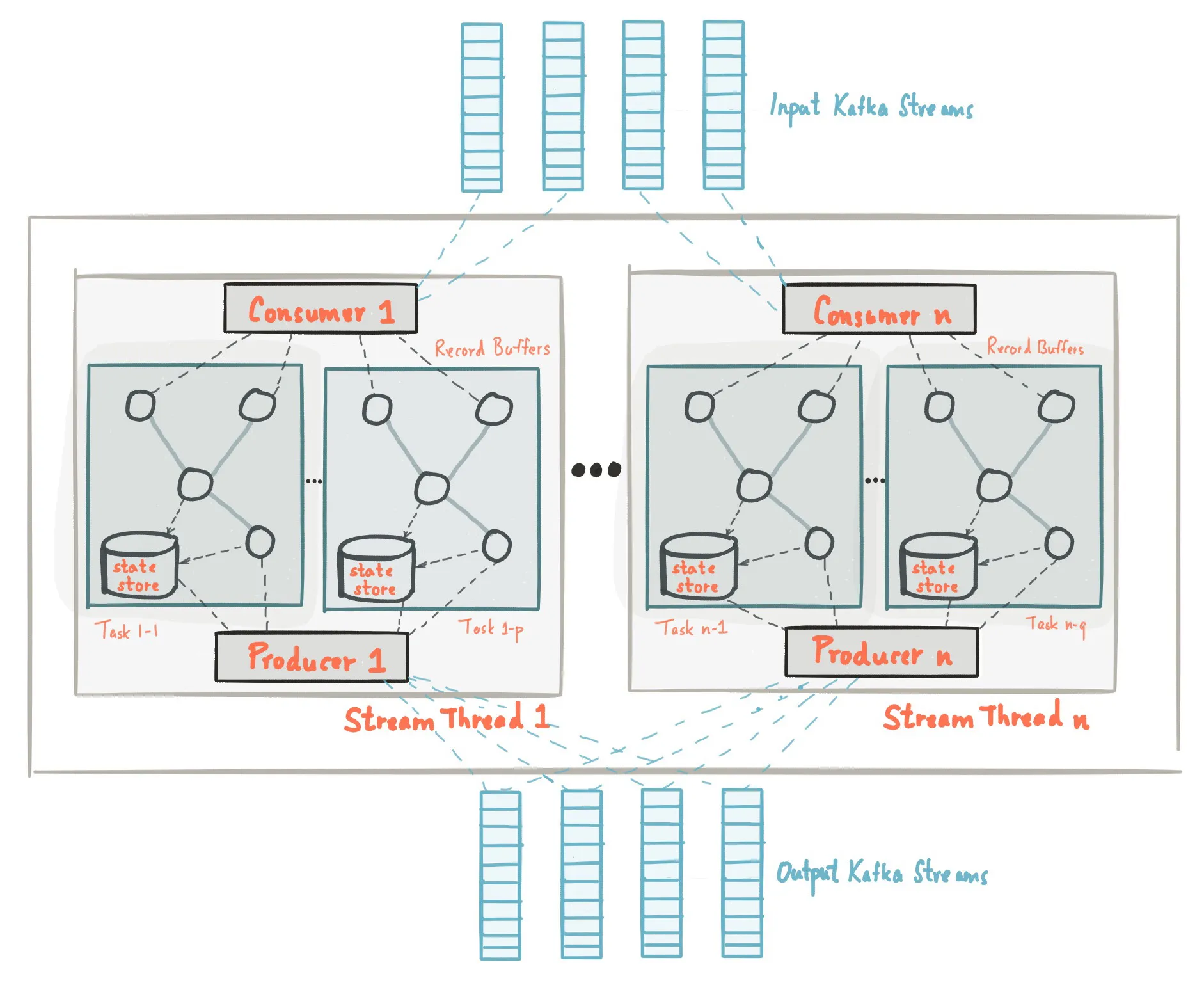
Kafka의 주요 개념
- Producer : 메시지를 Broker에 전달하는 역할
- Consumer : Broker의 메시지를 읽는 역할
- Broker : 메시지를 관리하는 서버 (Producer와 Consumer의 중간 역할)
- Topic : 메시지 발행/구독 대상이 될 수 있음
- Zookeeper : 카프카의 전반적인 구동을 관리하며, Zookeeper 없이 실행이 불가함
출처 : kafka.apache.org
Kafka와 파일 로깅과의 비교
기존에 각 인스턴스에서 파일로 로깅하고 filebeat를 통해 Elasticserach에 적재하여 Kibana에서 볼 수 있는 플랫폼이 구축되어 있었습니다.
그러나 각 서버 인스턴스에 의존하고 있었기 때문에 disk full 문제 및 권한 관리 실수로 인한 파일 쓰기 오류가 아주 가끔씩 발생하곤 했습니다.
또한 배포 중 오류가 발생하면 파일이 유실될 가능성도 존재하였기 때문에 데이터 유실 방지 기능과 성능을 함께 고려하여 Kafka를 선택하게 되었습니다.
Kafka 클라이언트를 사용해 개선하자
Application이 Kafka와 통신하기 위해서는 카프카 클라이언트를 설치해야 합니다.
Kafka는 C/C++, Node.js, Java, PHP 등 다양한 언어를 지원합니다.
저는 PHP Application과 통신시키기 위해 php-rdkafka 를 설치하였으며, Producing의 핵심적인 구문은 다음과 같습니다.
// Producer 를 생성 합니다.
$producer = new RdKafka\Producer($conf);
$producer->addBrokers('0.0.0.1:9092,0.0.0.2:9092');
// Producing 을 진행 합니다.
$topic->produce(RD_KAFKA_PARTITION_UA, 0, $orderPayload);경고문구를 제대로 읽지 않았다! 😱
Producing은 비동기로 실행되기 때문에, 데이터 전송이 끝나기 전에 프로세스가 종료되면 데이터가 유실되는 특징이 있습니다.
이 특징을 알지 못했기에 패턴을 찾을 수 없는 데이터 유실을 경험하기도 했습니다.
힘겹게 삽질하던 중 README.md에 보란 듯이 경고 문구가 적혀 있던 것을 발견했습니다.

데이터 전송이 끝나지 않았다면 flush를 실행하여 대기해야만 데이터 유실이 발생하지 않습니다.
문서를 잘 읽도록 합시다..!! 🙈
// 데이터 전송이 끝나지 않았다면 대기합니다.
$producer->flush($timeout);Application에서 주문 도메인에 Event가 발생할 때마다 Kafka에 주문 정보를 Producing 하도록 구현하고, 이를 Kibana 에서 확인할 수 있도록 구성하였습니다.
프로덕션에 배포! ✅
그리고 대시보드를 구성하여 다음과 같은 화면을 만날 수 있었습니다.
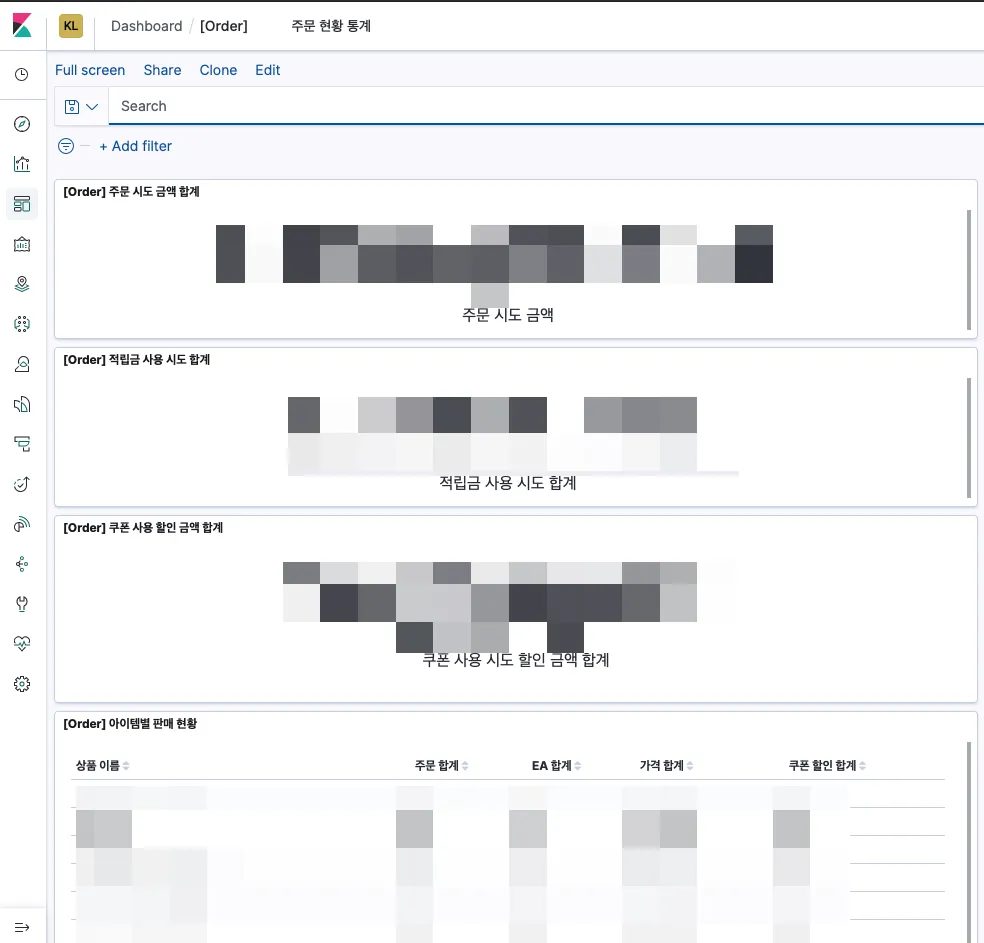
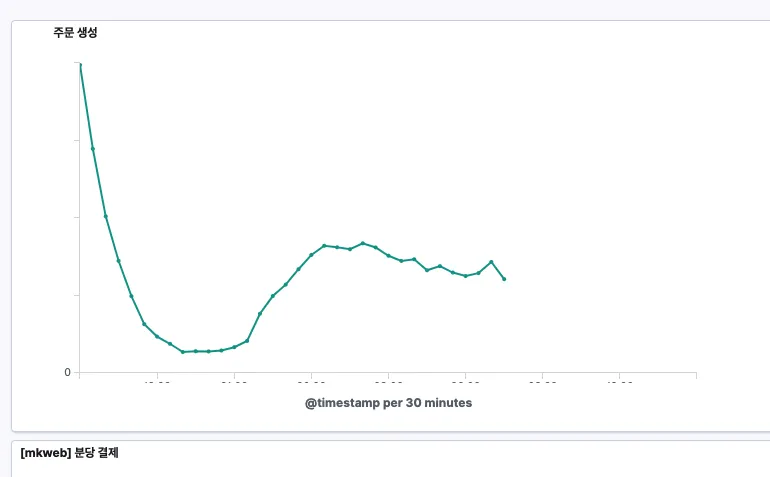
어느 정도 데이터가 쌓이고 난 뒤에는 키바나 대시보드를 통해 실시간/누적 주문건 및 금액과 주문 상품에 관한 통계를 확인 할 수 있게 되었습니다.
- 접속하자마자 체감
1초내외로 바로 조회되는 속도! - 아름다운 UI는 덤!
개선 작업을 마친 후
나는 무엇을 주문했었지?
프로덕션에 배포된 이후, 제가 마켓컬리에서 주문한 건들이 제대로 쌓이고 있는지 살펴보았습니다.
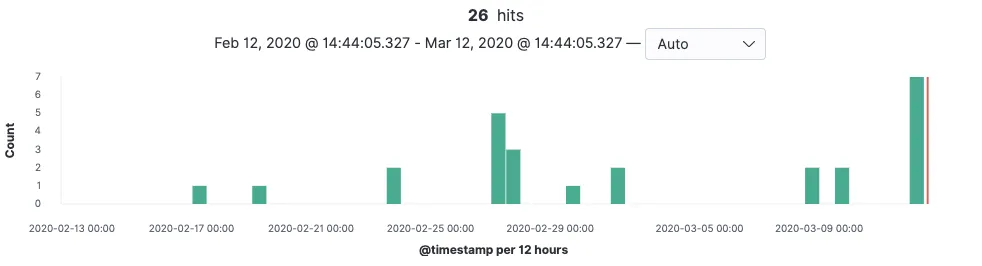
최근 들어서 저는 거의 일주일에 한 번은 주문했던 것을 확인 할 수 있었네요!
얼마 전에 주문한 만년설 딸기가 제대로 쌓이고 있는 것 또한 확인 할 수 있었습니다.
조회가 잘 되니 기분이 좋습니다!


첫 배포 후 겪었던 이슈들 😅
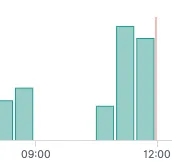
성공적으로 첫 배포를 마친 후, 약 일주일이 지났을 때, 특정 시간대에 주문 데이터가 사라졌다는 제보를 받았습니다.
저는 대시보드를 보고 해당 시간에 데이터 인프라에 문제가 발생했던 것을 알게 되었습니다.
주문 시스템의 장애가 아니었지만 이를 계기로 주문에 쌓이는 데이터를 활용해 장애 제보뿐만 아니라 비즈니스 측면에서 고려되는 다양한 인사이트들을 Slack으로 공유 할 수 있겠다는 아이디어를 얻었습니다.
정합성에 대한 이슈
주문 도메인의 Event 들을 실시간으로 Kafka에 적재하는 방식이다 보니 수집이 누락된 Event가 있을 경우, DB상의 정보와 데이터가 상이한 이슈가 있어 추가 보완 작업이 필요했습니다.
그리고 ack(acknowlegement) 옵션을 별도로 설정하지 않아 추가해 주었습니다.
ack는 카프카에 데이터 전송 여부를 확인하느냐에 대한 옵션입니다. 유실에 대해 얼마나 감당할 수 있는지에 따라 속도와 유실률의 비율을 상황에 따라 설정 할 수 있습니다.
또한 데이터가 중복으로 발생할 수 있는 상황을 고려하여 멱등성을 보장하기 위해 로그의 ID를 지정하였습니다.
결론

Kafka를 처음 접했을 때에는 어디에 어떻게 활용해야 할지 잘 몰랐습니다.
저희는 Kafka를 실시간으로 변화하는 주문 정보 적재를 위해 활용하였습니다.
저희가 공유한 경험을 통해 이 글을 읽으시는 다른 분들도 좋은 영감을 얻으셨길 바랍니다.
앞으로도 주문 모니터링 서비스 개선 작업을 하며 이것으로 어떤 인사이트를 도출할 수 있을지, CMS에서 타 모니터링 기능들을 이관할 수 있을지에 대해 고민할 예정입니다.
컬리에서는 이처럼 현실의 다양한 문제들과 Legacy 시스템을 집요하게 분석하고 Refactoring 하고자 합니다.
저희와 함께 품질 좋은 소프트웨어를 개발하실 뛰어나고 멋진 개발자 분들을 찾고 있습니다.
채용 링크를 통해 많은 지원 바랍니다!