DevOps 엔지니어의 Redis Test 분투기 - Part 1
Redis 테스트를 진행했습니다.
- 계기: Redis 성능 측정과 Key/Value 값 저장 문제
- 측정/테스트 도구를 찾아보자
- 테스트 전에 Redis 용도를 정리해보자
- API를 사용해 테스트를 시작
- 테스트 결과와 해석
- Part 1 결론
계기: Redis 성능 측정과 Key/Value 값 저장 문제
최근 서비스 고도화를 위해 회사의 중요 서비스들을 MSA로 변환하던 중, 성능 향상 및 용도를 이유로 개발팀은 Redis 도입을 고려하고 있었습니다.
그러다 최근 api 하나의 버전이 업데이트된 이후 덜컥 장애가 발생했습니다.
확인해보니 APM을 통해서 분석을 하던 도중 이번에 도입된 Redis에서 적재된 key 값을 가져오지 못하여 AWS RDS에 그대로 부하가 쏠려 문제가 발생했던 것이었습니다.
문제가 발생한 API는 Look-Aside-Caching 방법을 사용하고 있습니다.
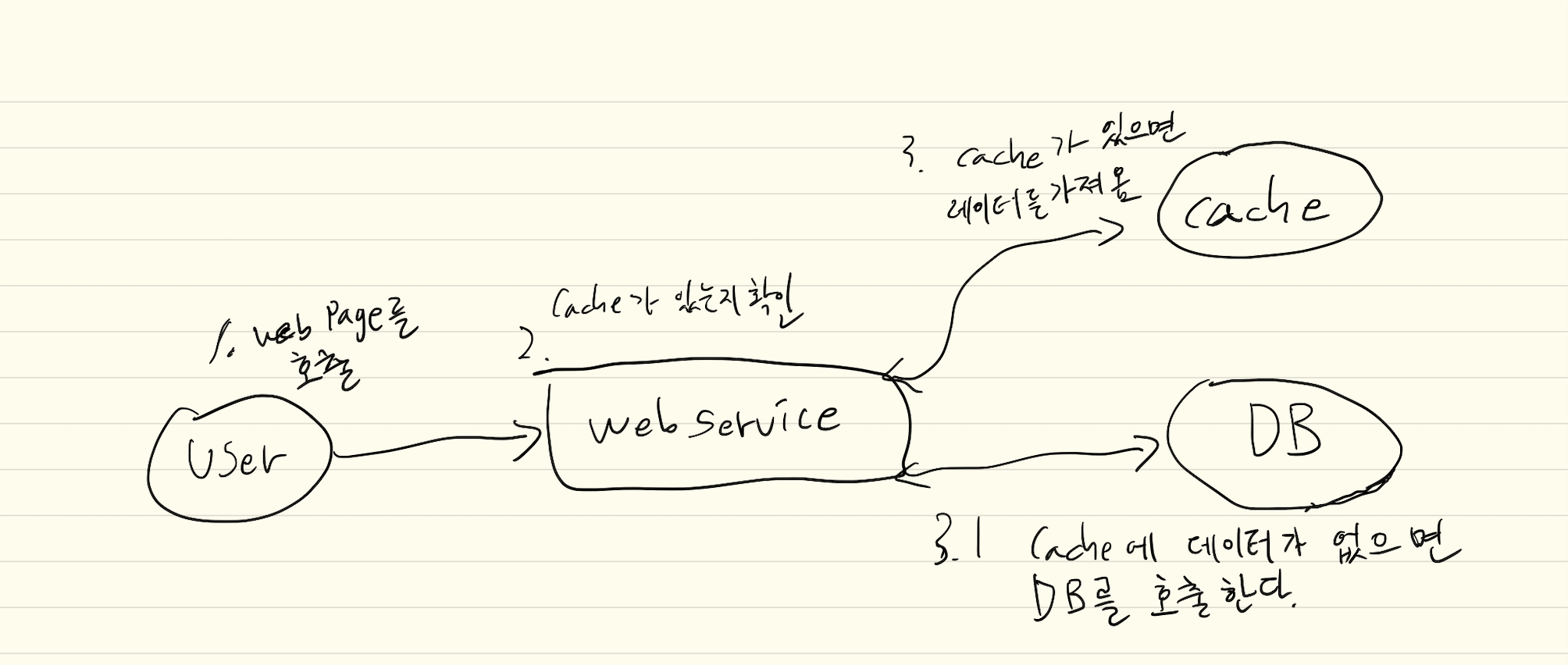
원인 분석 회의에서 두 개의 궁금한 사항이 생겼습니다.
- 해당 Key/Value를 Redis에 세팅을 하지 못한 이유가 무엇이었을까?
- 그리고 생성된 Redis 사이즈가 과연 우리 서비스 애플리케이션에서 사용하기에 적절한 용량인가?
회의 중에 주요 원인은 어느 정도 밝혀진 상태였지만 아직까지 회사에는 표준 Redis 규격이 없었으며, 성능 테스트를 통한 Redis Sizing 작업의 모델이 될 만한 좋은 케이스가 없었습니다.
그래서 원인 분석을 위해 간단하게 테스트한 다음, 추후에 테스트 데이터를 많이 쌓아 표준 사이징을 해보기로 했습니다.
측정/테스트 도구를 찾아보자
Redis는 기본적으로 성능을 테스트하고 용량 측정을 도와주는 redis-benchmark 명령어를 지원해줍니다.
이 명령어를 사용하여 임의의 Key/Value를 생성 및 호출하고 다양한 옵션을 사용해서 폭넓게 성능 측정을 할 수 있습니다.
다만 저희 컬리에서는 redis-benchmark 명령어만으로 성능 측정을 하기는 힘들었습니다.
이유는 다음과 같습니다.
- AWS에서 Elasticache를 사용합니다.
- Elasticache에서는
redis-benchmark명령어를 외부에서 받지 못합니다. - AWS Elasticache에서는 성능에 영향을 주는 명령어들이 disable 되어 있습니다.
- Elasticache에서는
- 발생된 문제를 재현하여 검증을 하고 싶었습니다.
- Redis 문제를 해결하고 그 경험을 팀에 공유하고 싶었습니다.
redis-benchmark 사용법
redis-benchmark는 기본적으로 주요 명령어(PINK, SET, GET, LPUSH, RPUSH, LPOP, RPOP, SADD, HSET, STOP, LRANGE, MSET)을 10만회씩 실행해서 성능을 측정 합니다.
# 기본적으로 Redis 서버를 지정하고 명령어를 실행하면 기본값으로 주요 명령어를 10만번씩 호출 합니다.
$ redis-benchmark -h <Redis 서버 IP> -p 6379
====== PING_INLINE ======
100000 requests completed in 0.95 seconds
50 parallel clients
3 bytes payload
...
아래의 옵션을 사용하면 다양한 테스트가 가능합니다.
-h: Redis 서버를 지정합니다. Default는127.0.0.1-p: Redis Port를 지정합니다. Default는6379-a: Redis 인증을 위한 패스워드를 지정합니다.-c: parallel connections 수를 지정합니다. Default는50--threads: thread 수를 지정 할 수 있습니다. Default는No-n: 요청 수를 지정합니다. Default는100000-d: GET/SET Value 사이즈를 지정합니다. Default는3-t: benchmark를 실행할 명령어를 지정합니다. Ex)SET,GET
redis-benchmark --help 명령어로 자세한 내용을 확인 할 수 있습니다.
테스트 도구 조사 결과
결과: Node.js와 Express로 만든 간단한 API가 우리 목적의 테스트에 적합하다.
장애 상황을 최대한 비슷하게 재현하기 위해 node.js와 express를 사용하여 redis에 데이터를 저장하고 호출할 수 있는 간단한 API를 작성했습니다.
그리고 nGrinder 에서 부하를 주어 테스트를 진행하기로 결정했습니다.
테스트 전에 Redis 용도를 정리해보자
Redis는 무슨 목적으로 만들어졌나?
만들어진 목적을 정확히 알아야 잘 쓸 수 있다고 생각했기 때문에 Wikipedia에서 누가 만들었고 용도를 확인해 보았습니다.
이탈리아의 Salvatore Sanfilippo 님이 MySQL을 사용하여 실시간 웹 로그 분석 애플리케이션을 개발하던 중에 성능의 한계를 느껴 직접 C 언어를 사용하여 Redis를 개발하였다고 합니다. (출처)
소스가 궁금하시면 해당 Github 저장소로 가서 다양한 이슈 내역을 확인할 수 있습니다. github 주소: antirez/redis
Redis 용도를 생각해보자

지난날의 저는 Redis가 정확히 어떤 역할들을 수행하는지 잘 이해 하지 못했습니다.
처음 Redis를 접하는 많은 분이 cache로서의 사용을 고려하며 접근합니다.
저 또한 처음에는 Redis를 Cache 용도로 접근하게 되었습니다.
Cache란 무엇일까요?
최대한 간단히 말하자면 요청된 결과를 미리 저장해두고 빠르게 보여주는 것을 말합니다.
그래서 Redis 하면 떠오를 수 있는 키워드를 먼저 정리 해보았습니다.
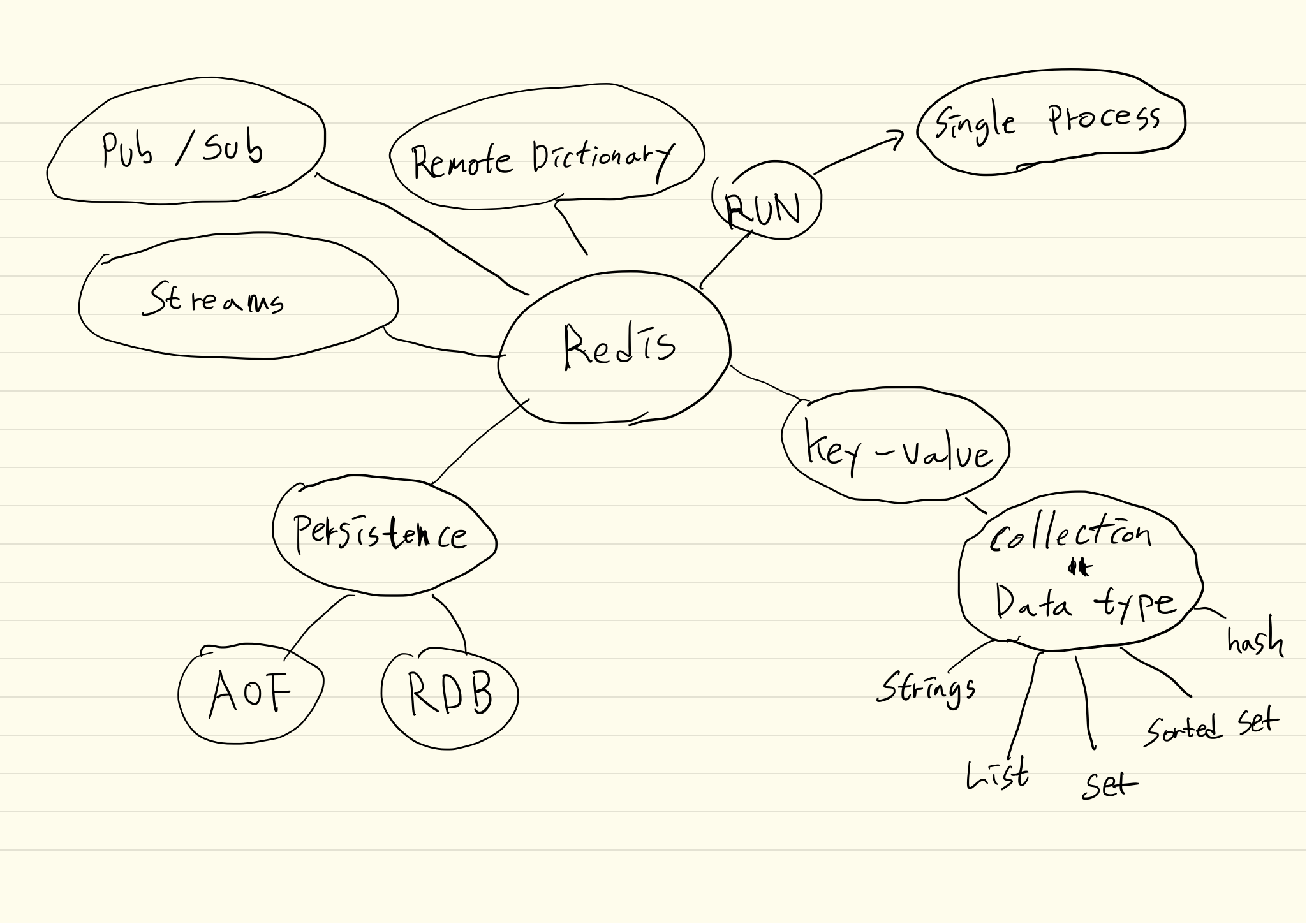
정리된 키워드별로 무슨 역할인지 간단히 정리해 보았습니다.
- Key-value
- Collection
Strings: 일반적인 Key와 Value가 1:1 관계를 가지는 구조List: 1개의 key 값에 n개의 값을 가지는 List 형태의 구조Set: 1개의 key 값에 중복되지 않는 하나의 데이터만 저장하는 구조Sorted Set: 실수형 스코어값을 줘서 데이터에 우선순위를 주는 구조Hash: 1개의 key 값에 여러 개의 Field와 Value 형태를 가지는 구조
- Collection
- Run
- Single Process: 한 번에 하나의 명령만 수행 가능
- Pub/Sub: Channel을 통해서 메시지를 보관하지 않고 즉시 모든 Subscriber에게 메시지를 전달 가능
- Streams: 연속적으로 발생하는 데이터를 보관하고 처리 가능
이 글을 작성하기 전에는 Redis 책(Mastering Redis)을 읽었습니다. 그리고 googling을 통해서 Redis를 생성 시의 여러 주의점을 접하게 되었습니다.
당연히 모든 것을 테스트한 것은 아니지만 주의점을 알아두면 사전에 문제를 회피 할 수 있다고 생각하여 아래와 같이 간단히 정리하였습니다.
- 메모리 관리에 유의하자
- Physical Memory 이상을 사용할 경우 swap 영역까지 사용하여 성능 이슈가 발생 될 수 있기 때문에 주기적으로 RSS 값을 모니터링 해줘야 합니다.
- Cluster mode와 Failover 모드의 사용처를 확실히 구분하자
- Redis 사용 용도에 따라 Cluster/Failover 모드를 구분해서 사용해야 합니다. 무조건 Cluster 모드가 좋다고 볼 순 없습니다.
- Pub/Sub은 Message Queue 기능은 아니다.
- 메시지를 보관하지 않고 바로 메시지를 전달하기 때문에 Message queue랑은 다릅니다.
- 명령어 사용에 주의하자.
- 실제 운영환경에서 모든 key 값을 조희 하는 명령어나 collection을 삭제하는 명령어는 사용을 피해야합니다.
- Single Process 이기 때문에 느린 명령어를 실행하면 성능 저하를 발생시킨다.
API를 사용해 테스트를 시작
테스트 환경
- AWS Elasticache: cache.m5.large failover 모드 준비
- EC2 instance: c5.large 사이즈로 2대를 준비
- nGrinder
- Test Application: node.js를 사용한 redis 호출 역할
현재 PHP 기반의 API에서는 Strings를 사용하여 데이터를 넣고 있기 때문에 기본적으로 Strings를 데이터를 처리할 테스트 코드를 작성하였습니다.
Redis Client 작성
NodeRedis 라이브러리를 작성하였으며 AWS Elasticache를 접근하기 위해서 아래와 같이 Client 부분을 작성하였습니다. github 주소: NodeRedis
import dotev from 'dotenv';
import redis from 'redis';
import { promisify } from 'util';
dotev.config()
const redisPort = process.env.REDIS_PORT;
const redisUrl = process.env.REDIS_URL;
const redisRoUrl = process.env.REDIS_READ_URL;
const client = redis.createClient(redisPort, redisUrl, { detect_buffers: true });
const clientRo = redis.createClient(redisPort, redisRoUrl);
const getAsync = promisify(client.get).bind(client);
const getAsyncRo = promisify(clientRo.get).bind(clientRo);
getAsync.then(console.log).catch(console.error);
getAsyncRo.then(console.log).catch(console.error);
Redis Strings를 호출하는 get/set 함수 작성
실제로 Redis에서 Strings를 Get하고 Set 할 함수를 아래와 같이 작성하였습니다.
문제가 된 API에서는 정책 변경이 일어나기 전에는 주기적으로 Redis에 저장된 Strings를 호출하고 변경 사항이 있을 경우 Set을 하여 내용을 반영하는 구조입니다.
간단히 key 값에 expire 값을 60초로 지정하고, 값이 없는 경우 Set으로 갱신하도록 만든 함수입니다.
// Read Endpoint에서 지정된 key 값을 조회한다.
export const getFun = async(key) => {
try {
const result = await getAsyncRo(key);
return result;
} catch(err) {
console.log(err);
}
};
// expire를 60초로 설정하여 Strings 를 넣는다.
export const setFun = (key, value) => {
try {
const res = client;
res.multi({ pipeline: false });
res.set(key, value);
res.expire(key, 60);
res.exec(function(err, result) {
});
} catch(err) {
console.log(err);
}
};
Controller를 작성
미리 정의한 json 데이터를 Strings 데이터를 집어넣는 Controller입니다.
이 Controller에는 strings 값을 가져와서 loop 문으로 체크하고 변경하는 로직이 있습니다.
테스트를 위해 간단히 작성된 코드이며 고의로 이슈를 발생시키기 위해 작성한 코드라는 점을 감안하고 읽어 주시길 바랍니다.
// data:icon 이라는 key 값이 없는 경우 해당 key 값을 다시 밀어 넣고 Value 값을 체크 한다.
export const setTestData = async (req, res) => {
try {
const key = 'data:icon';
const value = jsonfile_row[0].data;
const callNumber = req.params.call;
const checkKey = await getFun(key);
for (let i = 0; i < callNumber; i++) {
if (checkKey === null ) {
setFun(key, JSON.stringify(value));
checkValueTest(i, JSON.stringify(value));
}
}
return res.json({ result: 'success' });
} catch (e) {
return res.json({ result: 'fail', message: e.message });
}
};
테스트 결과와 해석
역시나 Total Vuser 설정을 1,500명으로 맞추고 nGrinder에서 부하를 주는 도중에 무수한 Error가 발생하는 것을 확인하였습니다.
무엇이 문제지!?
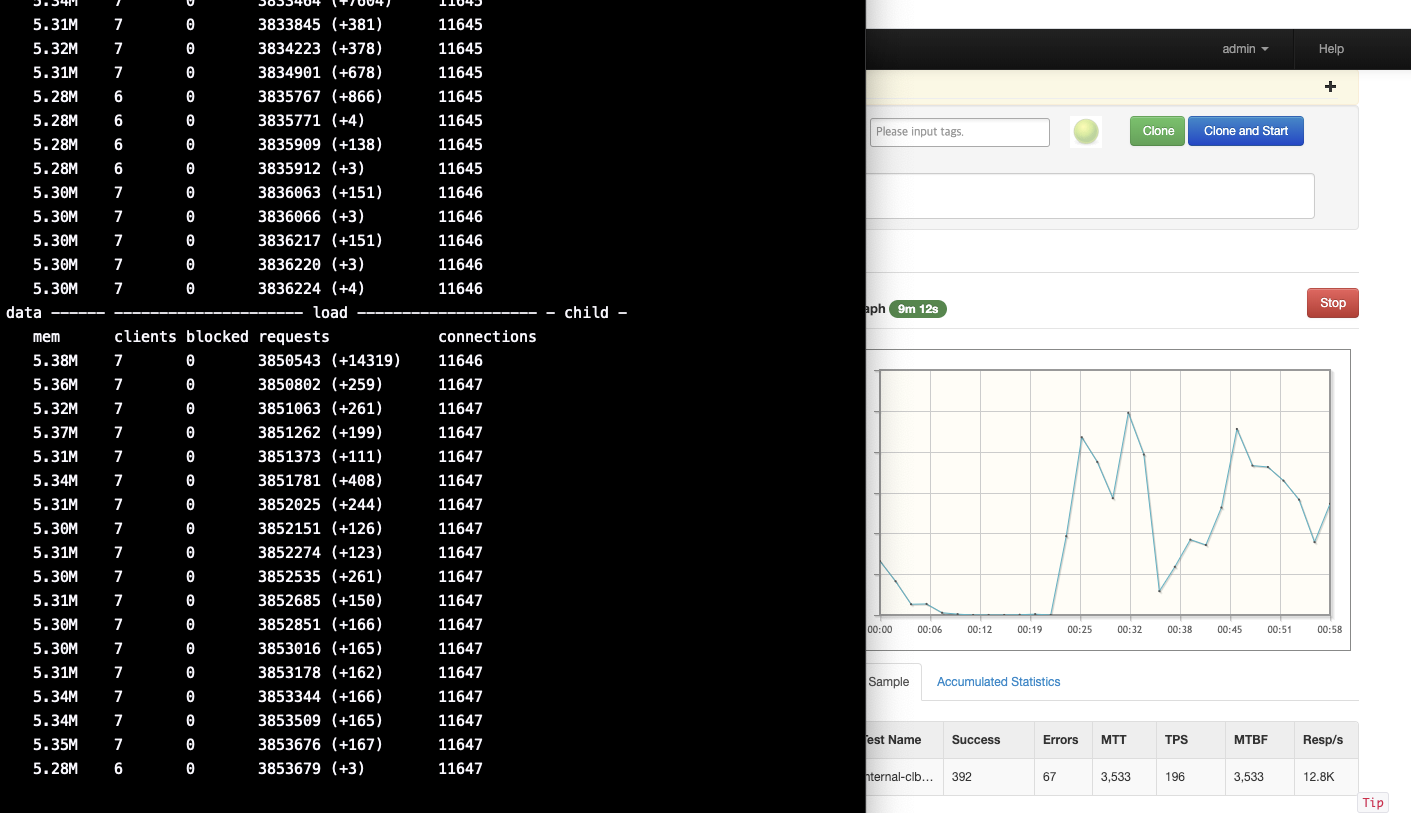
nGrinder에서 처음 시점에 Request가 발생할 때 TPS가 바닥을 치며 Error가 발생하는 것을 확인할 수 있었습니다.
해당 시점에 redis-cli --stat로 현재 request 수와 사용 메모리를 확인하고,
redis-cli --latency 옵션으로 지연 시간을 확인했을 때 무엇이 문제인지 확인을 해보았습니다.
그 결과 초반에 Key 값이 없거나 key 값이 Expire 되고 데이터를 Set하고 데이터값을 체크 할 때 발생 되는 이슈라는 것을 알 수 있었습니다.
Redis 리소스를 얼마나 사용했나?
실제 Redis 리소스 사용률이 어떠했는지 확인해 보았습니다.
모니터링 시에는 일반적으로 Cache Hit Rate와 CPU Utilization 등의 지표를 확인합니다.
그러나 이 테스트에서는 CPU 지표가 Current Connection 수나 실제 사용 중인 Memory 지표보다 더 중요하여 CPU 사용률을 확인하였습니다.
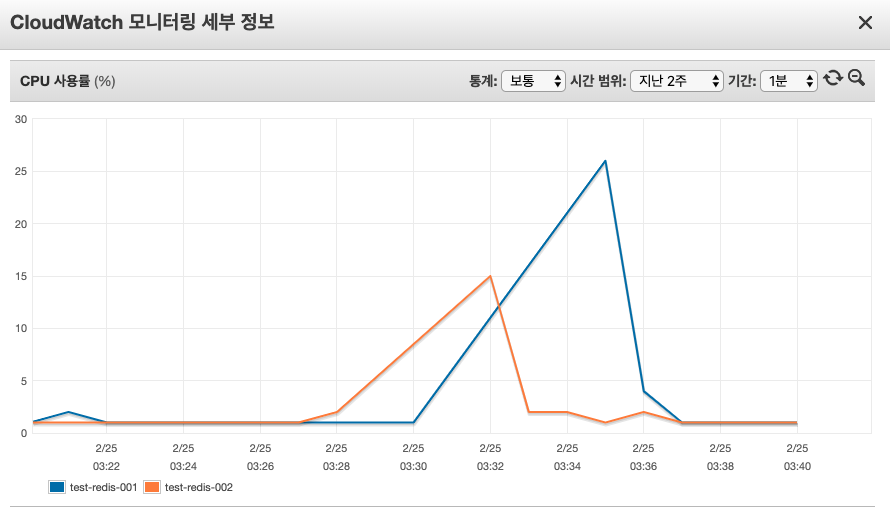
기본적으로 운영망과 동일한 cache.m5.large 사이즈의 Redis Failover 모드로 구성하여 테스트한 결과
실제로 key 값이 있는지 체크하는 시점에는 Read 쪽 Endpoint에서 CPU 사용률이 높고 그와 동시에 200 유저 이상이 요청하여 GET/SET 명령어로 값을 넣을 때
Primary Endpoint에서 사용률이 올라가는 것을 확인 할 수 있었습니다.
단순히 한 개의 키값을 GET/SET 하면서 loop 문으로 체크하는 로직일 뿐인데도 CPU 사용률이 25% 이상으로 올라갔습니다.
즉 동시에 여러 유저들이 GET을 하여 해당 키가 있는지를 확인 할 때 호출 수가 많은 경우 Error가 발생하지만, 해당 데이터가 정상적으로 Redis에 SET이 된 이후에는 정상적으로 호출이 성공하는 것을 확인 할 수 있었습니다.
만약 loop 문을 제거하고 icon:data 값을 Get 하였을 때 expire가 된 경우 다시 SET 하는 심플한 로직으로 부하를 주면 어떻게 될까?
// loop문을 제거하고 data:icon 이라는 key 값이 없는 경우 해당 key 값을 다시 밀어넣고 Value 값을 체크한다.
export const setTestData = async (req, res) => {
try {
const key = 'data:icon';
const value = jsonfile_row[0].data;
const checkKey = getFun(key);
if (checkKey == null) {
setFun(key, JSON.stringify(value));
checkValueTest(i, JSON.stringify(value));
}
return res.json({ result: 'success' });
} catch (e) {
return res.json({ result: 'fail', message: e.message });
}
};
위와 같이 loop 문을 제외한 다음, nGrinder로 Total vUser 1,500명으로 다시 부하를 주었습니다.
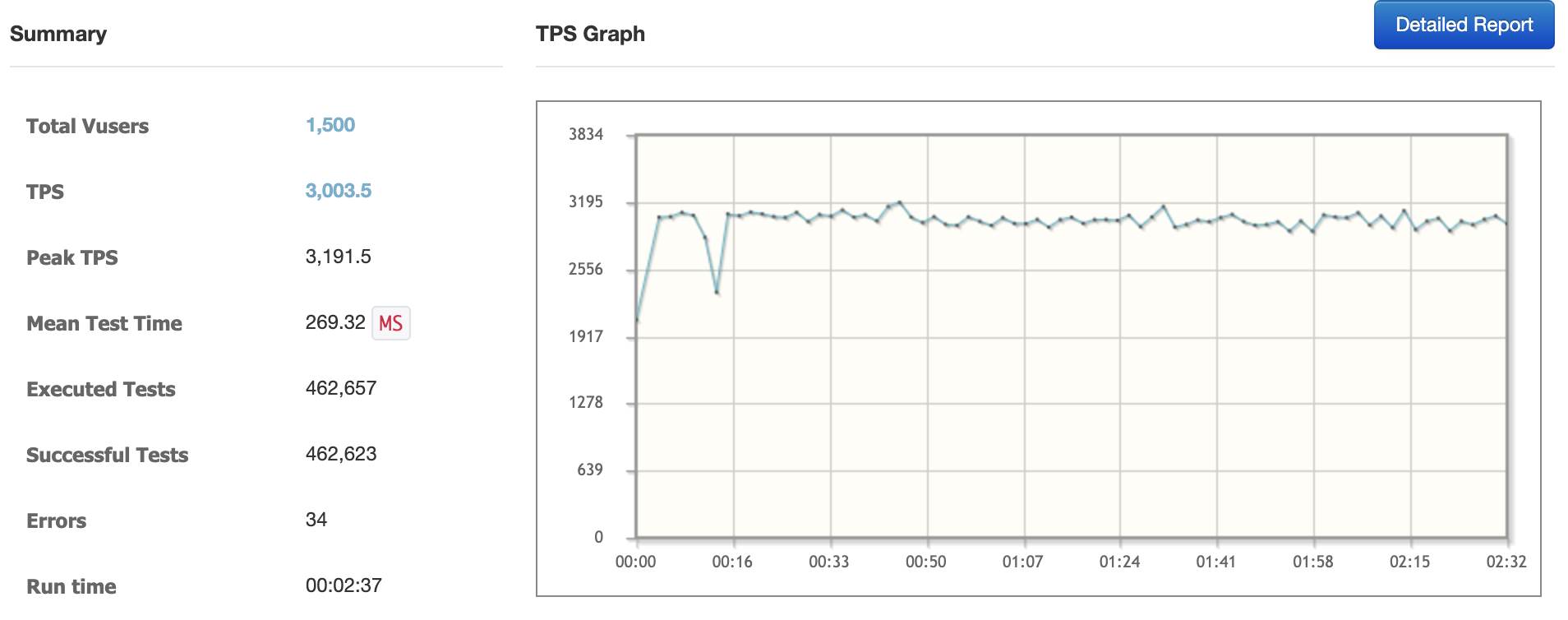
오히려 loop 문을 제외하고 긴 Strings 값을 데이터로 넣고 체크를 동시에 하였는데도,
처음 테스트만큼 CPU 사용률이 그렇게 많이 사용되지 않았습니다.
초반과 다르게 오히려 평균 TPS가 훨씬 높게 나오는 것을 확인할 수 있었습니다.
Part 1 결론
테스트 후에 개발자분들과 이야기를 해 보았습니다.
많은 클라이언트가 동시에 Web 호출 시에 특정 key 값에 대한 데이터에 대해 빈번하게 변경이 시도되는 경우 Redis 보다는 file Cache를 사용하거나 Collection을 잘 선택하여 데이터를 넣는 것이 중요하다는 이야기를 들을 수 있었습니다.
Redis 사용을 고려하게 된다면 데이터를 어떤 Collection으로 적재할지 고민하는 것이 가장 중요한 것으로 보입니다. 너무 많은 것을 한 번에 처리하려고 하거나 Redis가 정상적으로 동작하지 않았을 때의 이슈를 어떻게 처리해야 할지에 대해서도 대책을 준비해야 하는 것을 알게 되었습니다.
이번 테스트에서는 바로 Error를 뱉어내면서 TPS가 엄청나게 떨어지는 현상을 보였지만 실제 Look-Aside-Caching 방식을 사용하는 경우 Redis에서 응답이 없을 때 DB로 모든 부하가 집중되기 때문에 심각한 장애가 발생할 수 있을 것입니다.
이번 Part 1에서는 Redis에 대한 기초 학습 및 문제 시점을 비슷하게 상황 재현 테스트를 진행해 보았습니다.
Part 2에서는 Redis 사이징을 위한 테스트 및 효율적인 모니터링에 대해 정리해 볼 예정입니다.