1. 들어가며
안녕하세요, 컬리에서 검색/추천 서비스를 개발하고 있는 서민우입니다. 최근 컬리에는 대규모 시스템 개편이 있었고, 이에 따라 저희는 검색 인덱싱 파이프라인 구조를 변경해야 했습니다. 이 기회에 카프카를 조금 더 깊게 들여다볼 기회가 있었는데요. 컬리 기술 블로그를 통해 그 경험을 공유드리고자 합니다.
포스팅은 2편에 걸쳐 공유할 계획이며 이번 포스팅은 몇 가지의 카프카 설정 튜닝을 통해 메시지 처리 스루풋을 높이고 불필요한 시스템 동작을 방지한 이야기입니다.
2. 검색시스템 변경 요구사항
AS-IS
 컬리 검색 시스템은 카프카를 통해 상품 정보를 전달받아 검색 엔진에 인덱싱하고 있었습니다.
단일 토픽으로 전달되는 메시지는 색인에 필요한 모든 정보를 갖고 있었고, 이에 대한 간단한 정제만으로 색인 구축이 가능했었습니다.
컬리 검색 시스템은 카프카를 통해 상품 정보를 전달받아 검색 엔진에 인덱싱하고 있었습니다.
단일 토픽으로 전달되는 메시지는 색인에 필요한 모든 정보를 갖고 있었고, 이에 대한 간단한 정제만으로 색인 구축이 가능했었습니다.
TO-BE
 검색 서비스 요구사항 고도화에 따라 부가적인 정보가 색인에 필요해졌습니다.
해당 정보는 기존의 상품 정보 토픽이 아닌 별도의 토픽으로 유통되었으므로, 저희에게는 검색 엔진 외부에서 복수의 메시지를 하나의 메시지로 조합하여 인덱싱하는 설계가 필요해졌습니다.
검색 서비스 요구사항 고도화에 따라 부가적인 정보가 색인에 필요해졌습니다.
해당 정보는 기존의 상품 정보 토픽이 아닌 별도의 토픽으로 유통되었으므로, 저희에게는 검색 엔진 외부에서 복수의 메시지를 하나의 메시지로 조합하여 인덱싱하는 설계가 필요해졌습니다.
1차 구현안
저희가 먼저 고안해낸 방법은 하나의 색인을 이루는 복수의 상품정보를 각각 레디스에 저장하는 것이었습니다.
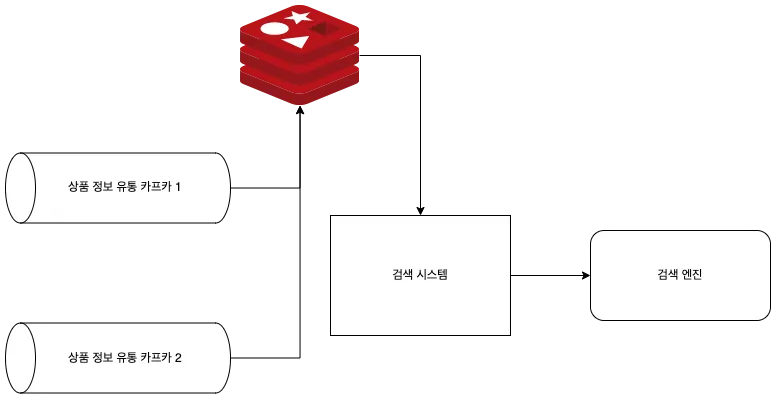 둘 중 어떤 토픽의 메시지가 먼저 저장되든지 간에, 메시지를 수신하면 색인에 필요한 나머지 데이터가 레디스에 있는지 확인하고,
있다면 데이터를 합쳐 검색 엔진에 색인을 요청했습니다.
둘 중 어떤 토픽의 메시지가 먼저 저장되든지 간에, 메시지를 수신하면 색인에 필요한 나머지 데이터가 레디스에 있는지 확인하고,
있다면 데이터를 합쳐 검색 엔진에 색인을 요청했습니다.
3. 문제 발생
새로운 아키텍처 상에서 색인 구축을 테스트하기 위해 상품 메시지를 일괄 발행해보았습니다. 컨슈머의 처리 속도가 충분히 받쳐주지 못해 메시지가 토픽에 쌓이기 시작했습니다. 엎친 데 덮친 격으로, 컨슈머 그룹에 의도하지 않은 리밸런싱이 계속 발생해 처리는 더 늦어졌습니다. 메시지 소비가 매우 지연됨에 따라, 상품 데이터가 제때 색인에 반영되지 않아 정상적인 검색 서비스가 불가했습니다.
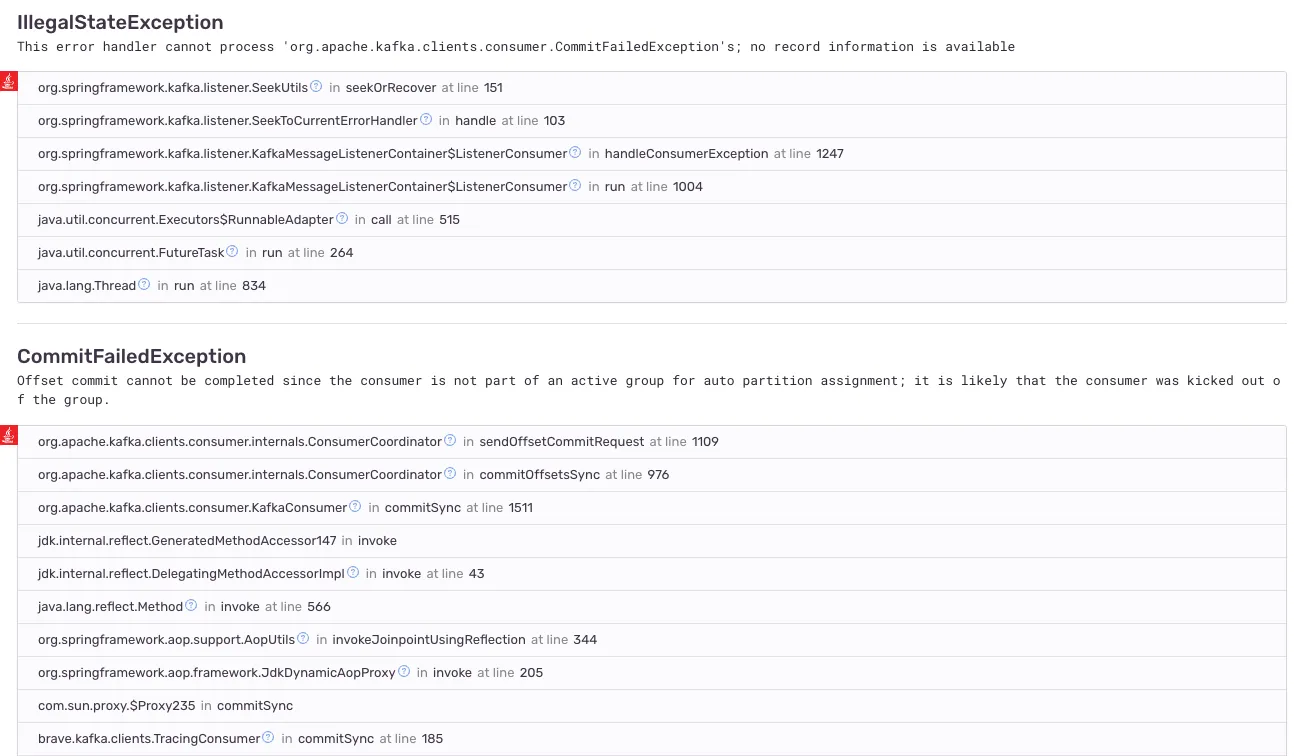
문제 상황을 다시 정리하자면 다음과 같습니다.
-
메세지 처리 속도가 발행 속도를 따라가지 못해 적체되어 제때 인덱싱이 되지 못한 문제
-
컨슈머 그룹 내 예기치 못한 리밸런싱이 일어나는 문제
이 두 가지 문제가 어떤 지점에서 발생하는지 파악하기 힘들었습니다. 그래서 색인 시스템 컴포넌트를 하나씩 점검해보았습니다.
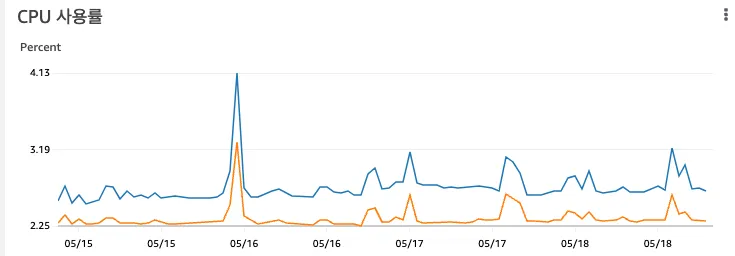
레디스 지표 확인
가장 먼저 확인한 부분은 레디스의 시스템 지표였습니다. 하지만 CPU 사용률을 비롯해 과부하가 의심되는 정황은 발견되지 않았습니다. 그렇다면 문제가 되는 부분은 카프카였습니다.
해결 1: max.poll 설정을 통한 리밸런싱 컨트롤
카프카의 기본 설정 중에 컨슈머가 메시지를 받아오는 poll() 메서드와 관련된 설정들을 들여다보았습니다.
이 설정을 통해 컨슈머 그룹에 속한 컨슈머들이 카프카 브로커에서 가져오는 레코드 수나 시간 간격을 조정할 수 있다는 것을 알 수 있었습니다.
현재 검색 컨슈머는 기본 설정대로 “500개의 레코드를 5분내에” 처리하도록 되어있는데, 계속 5분을 넘겨 컨슈머 그룹 내에서 리밸런싱하는 것으로 추측할 수 있었습니다.
관련 링크: Apache Kafka config
우선 불필요한 리밸런싱을 방지하기 위해 컨슈머가 한번에 가져오는 레코드 수를 하나로 줄여보았습니다.
spring:
kafka:
consumer:
max-poll-records: 1이렇게 설정을 극단적으로 변경하자 리밸런싱 발생 없이 색인을 구축할 수 있었습니다. 메시지 한 건에 대한 처리가 5분을 넘기지는 않기 때문입니다.
해결 2: Listener 설정 변경을 통한 스루풋 개선
하지만 근본적인 문제는 색인 구축 프로세스의 스루풋을 개선하는 것이었습니다. 애초에 500건의 메시지 처리가 5분을 넘지 않는다면, 리밸런싱도 일어나지 않았을 것이기 때문입니다.
이번에는 Spring Kafka의 설정을 찾아보았습니다. 우리가 Spring Kafka 를 사용할 때 사용하는 @KafkaListener 는 MessagingMessageListenerAdapter를 래핑한 스프링 빈을 기반으로 합니다.
카프카 리스너의 기본설정은 메시지를 1건씩 받아 처리하는 Record Listener 입니다.
Record Listener 의 구현체는 RecordMessagingMessageListenerAdapter 로 onMessage() 메서드를 살펴보면 1개의 레코드만 인자로 받는 것을 볼 수 있습니다.
public class RecordMessagingMessageListenerAdapter<K, V> extends MessagingMessageListenerAdapter<K, V>
implements AcknowledgingConsumerAwareMessageListener<K, V> {
@Override
public void onMessage(ConsumerRecord<K, V> record, Acknowledgment acknowledgment, Consumer<?, ?> consumer) {
Message<?> message;
if (isConversionNeeded()) {
message = toMessagingMessage(record, acknowledgment, consumer);
} else {
message = NULL_MESSAGE;
}
if (logger.isDebugEnabled()) {
logger.debug("Processing [" + message + "]");
}
try {
Object result = invokeHandler(record, acknowledgment, message, consumer);
if (result != null) {
handleResult(result, record, message);
}
} catch (ListenerExecutionFailedException e) { // NOSONAR ex flow control
if (this.errorHandler != null) {
try {
if (message.equals(NULL_MESSAGE)) {
message = new GenericMessage<>(record);
}
Object result = this.errorHandler.handleError(message, e, consumer);
if (result != null) {
handleResult(result, record, message);
}
} catch (Exception ex) {
throw new ListenerExecutionFailedException(createMessagingErrorMessage(// NOSONAR stack trace loss
"Listener error handler threw an exception for the incoming message",
message.getPayload()), ex);
}
} else {
throw e;
}
}
}
}컨슈머가 한번에 더 많은 메시지를 가져와 처리할 수 있도록 하기 위해, 리스너의 설정을 Batch Listener 으로 변경해보았습니다.
spring:
kafka:
listener:
type: batch스프링 카프카 배치 리스너 구현체인 BatchMessagingMessageListenerAdapter 를 살펴보면 메세지를 리스트로 받아 처리하는 것을 볼 수 있습니다.
이는 컨슈머가 poll() 메서드로 받은 전체 레코드를 불러오는 것입니다.
public class BatchMessagingMessageListenerAdapter<K, V> extends MessagingMessageListenerAdapter<K, V>
implements BatchAcknowledgingConsumerAwareMessageListener<K, V> {
@Override
public void onMessage(List<ConsumerRecord<K, V>> records, Acknowledgment acknowledgment, Consumer<?, ?> consumer) {
Message<?> message;
if (!isConsumerRecordList()) {
if (isMessageList() || this.batchToRecordAdapter != null) {
List<Message<?>> messages = new ArrayList<>(records.size());
for (ConsumerRecord<K, V> record : records) {
messages.add(toMessagingMessage(record, acknowledgment, consumer));
}
if (this.batchToRecordAdapter == null) {
message = MessageBuilder.withPayload(messages).build();
} else {
logger.debug(() -> "Processing " + messages);
this.batchToRecordAdapter.adapt(messages, records, acknowledgment, consumer, this::invoke);
return;
}
} else {
message = toMessagingMessage(records, acknowledgment, consumer);
}
} else {
message = NULL_MESSAGE; // optimization since we won't need any conversion to invoke
}
logger.debug(() -> "Processing [" + message + "]");
invoke(records, acknowledgment, consumer, message);
}
}Batch Listener 채택은 매우 성공적이었습니다. 현재 저희가 운영중인 검색엔진 역시 Batch 색인요청을 지원하므로, 기존에 Record Listener를 통해 건건이 요청하던 색인을 한번에 여러 건 모아 요청하도록 구현해 메시지 소비 및 색인 처리 속도를 비약적으로 증가시킬 수 있었습니다. 같은 수의 메시지를 처리하는 데 훨씬 적은 시간이 들기 때문에, 기존과 같은 레코드 수 및 시간 간격 설정에도 컨슈머 그룹 내 리밸런싱도 일어나지 않았습니다.
6. 마무리
여기까지 컬리에서 카프카 설정 튜닝만으로 불필요한 시스템 동작을 방지하고 메시지 처리 스루풋을 높인 경험을 공유해 드렸습니다.
특히 처음 리밸런싱이 계속 일어나는 것을 발견했을 때는 적잖이 당황했었었는데, 이를 해결하고 나니 굉장히 짜릿했습니다.
그런데 말입니다. 두 가지 상품 정보를 조합해 색인을 구축하는 이 시스템 구조를 좀 더 효과적으로 구성할 수는 없는 걸까요? 이 고민에 대한 내용은 2편에서 이어서 작성하도록 하겠습니다.
읽어주셔서 감사합니다.