DevOps팀의 Terraform 모험
사실은 낭만이 아닌 헬이었다
- Terraform 도입 계기
- Module Code와 Environment Code를 구성해보자
- 큰 착각으로 인하여 문제를 만나다
- 실제 Stage 및 Perf 환경에서의 Terraform 삽질
- 후기: 실제 사용 소감 과 앞으로 해야할 과제
안녕하세요. DevOps Engineering Team의 이규원입니다.
저희 팀은 항상 다양한 개발/운영 환경을 뿌시고 만들고 테스트하고 뿌시고 만들고 테스트하고 있습니다.
그런데 회사의 성장과 더불어 점차적으로 많은 서비스가 런칭되었고, 그에 따라 다양한 환경을 생성하거나 관리하는 일이 어려워지게 되었습니다.
따라서 성능 테스트나 실제 스테이지 환경 인프라도 함께 급증하면서 관리 복잡도가 나날이 증가하는 상황입니다.

그래서 저희 Kurly에서는 작년 8월부터 이러한 복잡도를 관리하기 위한 IaC(Infrastructure as code)로 Terraform을 사용하고 있습니다.
이 글을 통해 저희 팀이 Terraform을 사용하게 된 이유들과, 저희의 시행착오삽질 를 돌아보는 시간을 갖고자 합니다.
또한 실제 저희팀에서 관리하는 방식이나, 어떻게 활용하고 있는지 등을 공유하여 이 글이 저희와 비슷한 문제에 봉착한 다른 분들께 도움이 되거나 저희의 착오나 실수에 대한 조언을 받을 수 있는 기회가 될 수 있기를 바라고 있습니다.
해당 프로젝트시 아낌없이 지원을 해주시고 도움을 주신 유필성님께 감사드립니다.
Terraform 도입 계기
도입을 고려하게 된 계기는 단순했습니다. 컬리의 서비스가 꾸준히 증가하게 되면서 Stage 환경과 QA환경이 너무 비대해지고 단순한 반복 작업이 대폭 증가하게 되었습니다.
따라서 인프라 및 CI/CD를 구성할 때 복잡도가 증가하여 반복 작업을 하는 상황이 자주 발생 하였고 때때로 작은 실수를 하는 일도 있었습니다.
우리는 이러한 문제를 완화하기 위해 Stage 및 QA 환경에 먼저 Terraform 기술을 반영해 본 다음, 노하우가 쌓이면 운영 환경에도 반영하는 전략을 실행해보기로 하였습니다.
도입을 앞두고 고민한 것들
그러나 우리에게 있어 Terraform을 다뤄본 경험은 단순하게 사용한 것들 뿐이었습니다. 업무 환경에서 동료들과 함께 사용하기에는 부족함이 있었습니다.
그래서 Terraform을 기본부터 다시 공부하기로 하였습니다.
우리에게는 다행히 구글이 있었고 처음부터 어렵게 가지 않고 작은 목표를 잡으며 시작하려 했습니다.
첫 목표는 단순한 코드를 작성하고 구조를 잡는 것이었습니다.
Terraform 구조를 어떻게 구성할까?
먼저 Terraform Document와 Best practices를 정독하고 구조를 어떻게 가져갈지 논의하였습니다.
참고한 문서들은 다음과 같습니다.
- Terraform Standard Module Structure
- Terraform module structure를 어떻게 작성할지에 대한 문서입니다.
- Code structure examples
- Anton Babenko님이 작성 해주신 Terraform code structures.
저희 팀의 경우 여러 AWS accounts를 관리하고 있고, 추후에는 Terraform을 운영망에서도 사용하는 것을 계획 하고있어 Terraform best practices 중의 하나인 large 방식을 선택하여 저희 환경에 맞게 응용해 사용 하기로 했습니다.
다음 구조는 저희가 Terraform 사용을 시작했을 때의 구조입니다. large 방식을 거의 그대로 사용해 시작했다고 할 수 있습니다.
.
├── README.md
├── env // 실제 Provision될 Environment Code 위치
│ ├── dev
│ ├── qa
│ ├── stg
│ │ ├── main.tf
│ │ ├── terraform.tfvars
│ │ ├── variables.tf
│ │ └── version.tf
└── modules // AWS modules 코드
├── acm
├── compute
│ ├── alb
│ │ ├── main.tf
│ │ ├── output.tf
│ │ ├── variables.tf
│ │ └── versions.tf
│ ├── asg
│ ├── efs
│ ├── lb_listener
│ ├── lt
│ ├── nlb
│ ├── sg
├── database
│ ├── ec
│ ├── rds
│ └── rds-aurora
├── developer_tool
│ ├── codebuild
│ └── codedeploy
├── iam
├── mq
└── network
└── route53
Terraform 소스 코드를 어떻게 관리할까?
처음에는 정말 간단하게 생각했습니다.
Terraform 소스 코드는 당연히 Github private repository로 관리하고,
terraform.tfstate
(부끄럽게도 핵심 파일인 tfstate의 형상관리를 처음부터 고려하지 않고 파일을 저장하는 것만 고려 했었습니다)은 Infra 관련 서비스가 모여있는 Infra 계정의 S3 bucket에 저장하는 방식으로 관리하려 했습니다.
이때 AWS console에서의 S3 bucket 파일 수정을 막아놓고, 실제로 Terraform을 실행하는 Accesskey를 통해서만 파일을 수정하거나 업데이트할 수 있도록 bucket policy를 설정하여 팀원들이 주요 파일을 변경할 수 없도록 설정했습니다.
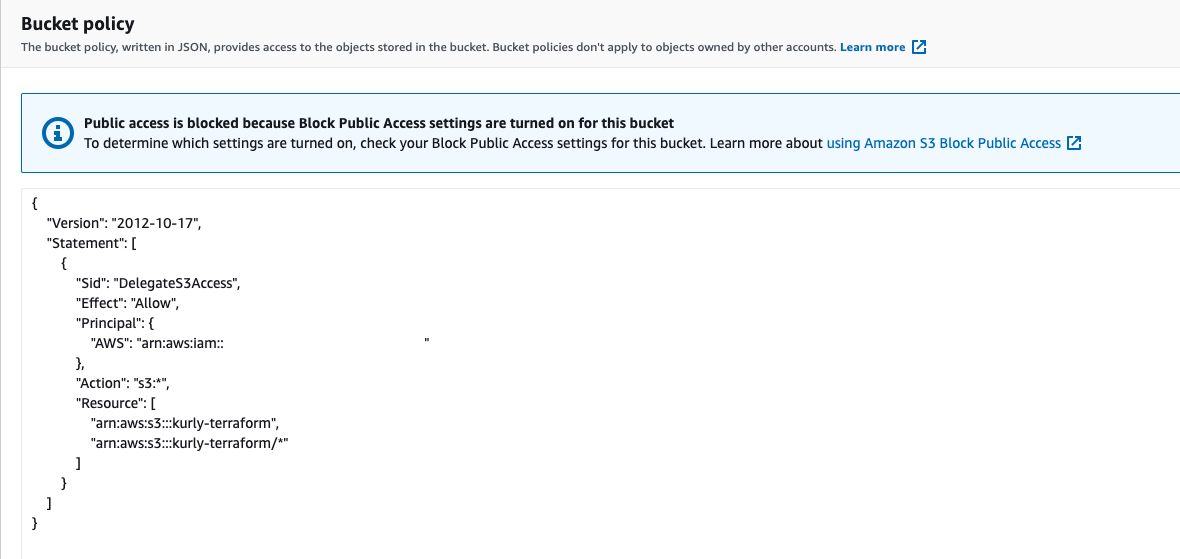
이때까지만 해도 시작이 좋다고 생각했습니다?!
뒤에서 언급하게 되겠지만 이후 저는 Terraform에 대한 낮은 이해도 때문에 큰 문제를 만나게 됩니다.
Module Code와 Environment Code를 구성해보자
요약해보자면 Module Code와 Environment Code는 다음과 같이 짧게 설명할 수 있습니다.
- Module code
- 각 Provioder(AWS, Google등)의 서비스(EC2, RDS, ALB등)에 대해 반복적으로 사용할 코드
- Environment Code
dev,stg,prod등의 환경에서 실제 Provision되고 관리해야 할 코드
저는 두 코드에 대해 다음과 같이 판단하였습니다.
- Module Code는 Environment Code의 변경에 가능한 한 영향을 받지 않고 무리 없이 환경을 생성할 수 있도록 하자.
- Envrionment Code는 Module Code를 사용해 자유롭게 환경을 생성할 수 있는 것이 가장 중요한 것 같다.
Module Code를 작성하자
먼저 간단하게 기본적인 Module Code를 작성하며 시작하였습니다.
Module Code는 실수를 최대한 방지하기 위해 Terraform registry 사이트에서 AWS provider를 참고하여 작성하였습니다.
아래는 저희의 기술 스택 중 하나인 Launch Template입니다. 초기에 작성된 코드중 하나입니다.
main.tf
resource "aws_launch_template" "launch_template" {
name = var.aws_lt_name
iam_instance_profile {
name = var.aws_lt_iam_profile_name
}
image_id = var.aws_lt_iam_profile_id
instance_type = var.aws_lt_instance_type
monitoring {
enabled = true
}
placement {
availability_zone = "ap-northeast-2"
}
vpc_security_group_ids = var.aws_security_group_id
tag_specifications {
resource_type = "instance"
tags = {
"Name" = var.tags_name
"Asset Number" = var.tags_assert_name
"Service" = var.tags_service
"Team" = var.tags_team
"Position" = var.tags_position
"OS" = var.tags_os
"Env" = var.tags_env
"filebeat" = var.tags_filebeat
"Datadog" = var.tags_datadog
"APPLang" = var.tags_applang
"AppName" = var.tags_appname
}
}
}
우선 aws_launch_template이라는 resource를 정의합니다(첫 번째 줄).
위에 링크된 문서를 보시면 아시겠지만 AWS Provider에서는 서비스별로 resource들이 정의되어 있으므로,
원하는 서비스를 구성하기 위해서 필요한 resource를 가져와 코드를 작성하면 됩니다.
Environment Code에서는 위의 코드에 지정된 변수들을 받아서 실제로 정의된 resource를 실행하여 환경을 provision 합니다.
아래의 파일에는 Environment Code에서 변수를 받아 올 수 있도록 변수 및 타입을 정의 하였습니다.
variables.tf
variable "aws_lt_name" {
type = string
}
variable "aws_lt_iam_profile_id" {
type = string
}
variable "aws_lt_instance_type" {
type = string
}
....
versions.tf 파일에는 provider와 Terraform의 버전을 명시했습니다.
versions.tf
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
}
}
required_version = ">= 0.12"
}
저희는 위의 예제에서 시작하여 다양한 수정과 리팩토링을 거쳤기 때문에, 현재 시점에서 저희가 사용하고 있는 코드는 위의 예제와는 다소 다른 모습을 갖고 있습니다.
그러나 코드를 작성하고 환경을 배포할때 저희가 어떠한 고민을 했고 어떻게 구성했는지에 대해 설명하기 위해 처음 시점의 기본 코드를 먼저 보여드리게 되었습니다.
Environment Code를 작성 해보자
Environment Code는 실제로 생성할 환경에 대한 다양한 설정값을 명시한 코드라 할 수 있습니다.
Environment Code에서는 local 변수를 선언하여 해당 Environment Code에서 사용할 변수들도 지정이 가능합니다.
이 외에도 다양한 기능이 많지만 전부 설명할 수 없기 때문에 이번에도 간단한 코드부터 작성하도록 하겠습니다.
module "test_launch_template" {
source = "../../../modules/compute/lt"
aws_lt_name = var.test_lt_app_name
aws_lt_iam_profile_id = var.launch_template_iam_id
aws_lt_instance_type = var.launch_template_instance_type
aws_lt_key_name = var.lt_key_name
aws_lt_iam_instance_profile = var.lt_iam_instance_profile
aws_security_group_id = var.test_sg_name
tags = {
Name = var.test_tags_app_name
Asset_name = var.test_tags_assert_name
Service = var.test_tags_service
Team = var.test_tags_team
Position = var.test_tags_position
OS = var.test_tags_os
Category = var.test_tags_category
Env = var.test_tags_env
APPLang = var.test_tags_applang
AppName = var.test_tags_appname
}
aws_asg_name = var.test_asg_name
aws_asg_max_size = var.asg_max_size
aws_asg_min_size = var.asg_min_size
aws_asg_health_check_type = var.asg_health_check_type
aws_target_group_arns = var.test_tg_arn
aws_asg_sch = {}
this_aws_lt_name = var.test_lt_app_name
aws_vpc_zone = var.vpc_zone
}
위의 예제를 보면 알 수 있듯, 반복적으로 변수를 엄청 생성하여 찍어내는 Environment Code 만 작성이 가능한 형태입니다. 당연히 단순한 반복 작업을 없애기 위해 초반에 어느 정도 리팩토링을 해 두었습니다.
Environment Code에 대응 할 수 있도록 간단히 양쪽 코드를 리팩토링을 해보자
위의 코드를 보고 눈치 채셨겠지만 기본 코드를 그대로 사용하게 되면 엄청나게 많은 변수 선언으로 인해 괴로움에 시달리게 됩니다.
저는 너무 게으른 사람이므로 이러한 부분을 용납할 수 없었습니다. Terraform을 시작하기도 전에 팀원들에게 마녀 사냥을 당하는 게임 오버는 피하고 싶어 고민을 하게 됩니다.
local 변수를 사용하여 반복적인 코드를 줄이자
Tags는 언제나 반복적으로 사용하며 절대 바뀌지 않는 목록이라 할 수 있습니다.
Tags의 이런 값들을 locals로 빼서 계속 사용할 수 있도록 변경하였습니다.
(말로 표현할 때에는 local변수라고 하는데, 실제 선언하는 키워드는 locals이기 때문에 헷갈리지 않도록 주의해야 합니다)
다음은 main.tf의 일부입니다.
locals {
tags_options = {
"php" = {
Team = "---"
Position = "---"
Team-position = "commerce"
OS = "linux"
Category = "stage"
Env = "stg"
Applang = "php"
Iac = "terraform"
Datadog = "apm"
},
"java" = {
Team = "---"
Position = "---"
Team-position = "commerce"
OS = "linux"
Category = "stage"
Env = "stg"
Applang = "java"
Iac = "terraform"
Datadog = "apm"
},
}
}
위의 코드에서 locals를 변경하고 해당 tags_option을 사용할 수 있도록 기존의 Environment Code를 변경해 봅시다.
위의 tags_options를 읽어보면 php와 java가 나뉘어 있습니다.
이것을 merge function을 사용해(아래 예제의 첫째 줄) 환경마다 다르게 사용할 tag와 재활용할 local tag를 하나로 합칠 수 있었습니다.
tags = merge(
local.tags_options[var.java_tags_options],
{
Name = var.test_tags_app_name
Asset_name = var.test_tags_assert_name
Service = var.test_tags_service
AppName = var.test_tags_appname
}
)
위의 예제를 통해 변수를 줄일 수 있었데요,
사실 저 위에서 등장한 Name, Asset_name, Service, AppName과 같은 Tag들은 저희 내부 정책에 정의된 서비스 네이밍을 따라가는 것들입니다.
이 부분도 줄일 수 있을 것 같습니다.
그래서 실제 var.test_app_name 변수를 하나만 받고 format, upper, lower function을 사용해 실제 Tag 값을 완성해 보았습니다.(아래 예제의 Name과 Asset_name)
tags = merge(
local.tags_options[var.java_tags_options],
{
Name = format("STG-%s-AS", upper(var.test_tags_app_name))
Asset_name = format("ASG-STG-%s", upper(var.test_tags_app_name))
Service = lower(var.test_tags_app_name)
AppName = lower(var.test_tags_app_name)
}
)
Environment Code는 변수가 많지 않고 사용하더라도 변수의 Default 값을 사용하여 코드를 작성하는 것이 가장 심플하고 안정적으로 Environment Code를 관리 할 수 있는 방법일거라 생각했습니다.
따라서 위와 같이 고민 하고 코딩하게 되었습니다.
실제로 신규 입사자 분께서 위와 같은 방식을 사용해 보았더니 Environment Code를 작성하더라도 크게 어렵지 않았다고 합니다.
Module Code에 Block device mapping 기능을 추가해보자
Launch Template에서 EBS volume을 추가하거나 지정할 때
Block device Mapping을 사용할 수 있도록 코드를 변경 해보았습니다.
간혹 서비스마다 마스터 이미지로 생성한 AMI가 아니라 다른 EBS volume을 추가로 마운트해서 사용해야 하는 경우가 있어서, 다음과 같이 해당 코드를 작성해 보았습니다.
block_device_mappings {
device_name = var.device_name
no_device = var.no_device
virtual_name = var.virtual_name
ebs {
volume_size = var.volume_size
delete_on_termination = var.delete_on_termination
encrypted = var.encrypted
iops = var.iops
kms_key_id = var.kms_key_id
snapshot_id = var.snapshot_id
volume_size = var.volume_size
volume_type = var.volume_type
}
}
기본적인 Module 코드에서 Block_device_mappings는 위와 같은 형태입니다.
다만 위와 같이 사용하는 경우에는 마스터 이미지로 생성한 AMI에서 사용하는 Volume과, 추가하는 EBS voulme 두 개를 동시에 맵핑할 수 없다고 판단했습니다.
그래서 아래와 같이 dynamic block 을 사용해 리팩토링해 보았습니다.
dynamic "block_device_mappings" {
for_each = var.block_device_mappings
content {
device_name = lookup(block_device_mappings.value, "device_name", null)
no_device = lookup(block_device_mappings.value, "no_device", null)
virtual_name = lookup(block_device_mappings.value, "virtual_name", null)
dynamic "ebs" {
for_each = lookup(block_device_mappings.value,"ebs",null) != null ? ["ebs"] : []
content {
delete_on_termination = lookup(block_device_mappings.value.ebs, "delete_on_termination", null)
encrypted = lookup(block_device_mappings.value.ebs, "encrypted", null)
iops = lookup(block_device_mappings.value.ebs, "iops", null)
kms_key_id = lookup(block_device_mappings.value.ebs, "kms_key_id", null)
snapshot_id = lookup(block_device_mappings.value.ebs, "snapshot_id", null)
volume_size = lookup(block_device_mappings.value.ebs, "volume_size", null)
volume_type = lookup(block_device_mappings.value.ebs, "volume_type", null)
}
}
}
}
참고로 Dynamic Block은 resource 생성시 내부의 configuration을 여러 개 설정할 수 있게 도와주는 Configuration Block 입니다.
여러 리소스를 생성할 때 반복적인 작업을 줄여주고 편리하게 컨트롤할 수 있기 때문에 자주 사용하는 패턴입니다. (해당 문법은 0.12 버전부터 사용할 수 있습니다.)
리팩토링이 완료된 위의 코드에서는 var.block_device_mappings 디폴트 변수(2번째 줄)에 List(object) 타입으로 각 변수에 Key-value 값으로 설정 하였습니다.
그리고 해당 값들은 lookup function을 사용하여 실제 값과 맵핑되고, 값이 없을 경우에는 null로 처리하는 방식입니다.
이런 방식은 hashicorp discuss와 GitHub Issue를 토대로 확인된 방법입니다.
저희는 시작했을 때부터 지금까지 dynamic block을 어떻게 사용할지에 대해 많은 고민을 해오고 있습니다. 시행 착오와 리팩토링을 거쳐서 위와 같은 형태를 갖추게 되었습니다.
많은 사용자분들이 남겨주신 자세한 Issue와 Discuss는 저에게 큰 도움이 된 너무 감사한 Reference라 할 수 있습니다.
variable "block_device_mappings" {
type = list(object({
device_name = string
no_device = bool
virtual_name = string
ebs = object({
delete_on_termination = bool
encrypted = bool
iops = number
kms_key_id = string
snapshot_id = string
volume_size = number
volume_type = string
})
}))
default = []
}
위와 같이 variable를 정의하고 Environment Code에는 위와 동일하게 작성하였습니다. 그리고 terraform.tfvars 파일에는 아래와 같이 지정했습니다.
test_block_device_mappings= [
{
device_name = "/dev/sda1"
no_device = null
virtual_name = null
ebs = {
delete_on_termination = true
encrypted = false
volume_size = 30
volume_type = "gp3"
iops = 3000
kms_key_id = null
snapshot_id = "snap-00000000000000"
}
},
{
device_name = "/dev/sdf"
no_device = null
virtual_name = null
ebs = {
delete_on_termination = true
encrypted = false
volume_size = 10
volume_type = "gp3"
iops 은 = null
kms_key_id = null
snapshot_id = "snap-00000000000000"
}
}
]
위와 같은 형태로 Configuration block 처리를 함으로써 좀 더 생산적이고 깔끔하게 리팩토링이 되었습니다.
여기까지의 작업으로 저는 혼자 성취감을 느끼며 뿌듯해 하였지만 실제로는 크나큰 착각을 하고 있었으며, 어떤 문제에 직면하게 될지 이때까지는 상상하지 못하고 있었습니다.
큰 착각으로 인하여 문제를 만나다
사실, 이때까지 tfstate 파일이 얼마나 중요한지 상상도 하지 못했습니다.
앞서 언급한 바와 같이 Terraform을 실제로 적용하고 고민 하는건 이번이 처음이었습니다.
최초의 목표는 다음과 같았습니다.
- STG/QA 환경을 Provision 할 때 다음 작업들이 반자동으로 실행된다.
- Github PR로 필요한 변수들과 파일들이 명시된
envfile를 업로드 Consul에 Key-value 방식으로 저장- Jenkins에서 환경별로 Provision (수동)
- Github PR로 필요한 변수들과 파일들이 명시된

이 구성도는 다음과 같이 요약할 수 있습니다.
terraform.tfvars를 완성할Envfile를 작성하여 PR로 올리고 코드 리뷰를 받습니다.- 개발자들이 필요할 때마다 Jenkins에서 필요한 환경을 찍어낼 수 있습니다.
…이렇게 설계를 하려 했지만 tfstate 파일 관리의 어려움과 이 파일이 얼마나 중요한지에 대해 잘못 이해하고 있었기 때문에 큰 실수를 저지르게 됩니다.
설계단계부터 잘못된 접근 방식이었다?!
위의 설계에 대해 저희팀 매니저님인 유필성님과 이야기하면서, 제가 착각했다는 것을 깨달았습니다.
Ansible를 사용하여 자동화한 경험을 가지고 있었던 저는, 환경 생성만을 고려하고 있었고, Terraform에서 가장 중요한 인프라 형상관리 부분은 고려하지 않았던 것입니다.
단순히 여러 개의 환경을 찍어낸 다음, 이후의 관리(삭제, 체크)를 하지 않는 방식만 생각했던 것이 문제였습니다.
요약하자면 tfstate 파일 자체를 작성하는 인프라 형상관리 코드에 대해서 고민이 부족했고, 단순히 환경 생성시 tfstate의 의미도 모른체 저장만 하려고 했던 것입니다.

나는 바보였다!
tfstate 파일이 무엇이길래 우리가 논의 하게 하는가?
이후 유필성님과 긴 회의를 하고 tfstate 파일의 목적을 다시 돌아보니 저는 멘붕 상태에 빠지고 말았습니다.
기술 습득시에는 기본기에 충실해야 하는데 겉핡기식으로 시작한 거였죠. 결과적으로는 반성하는 계기가 되어 좋았습니다.
실제 tfstate의 역할은 크게 4가지 였습니다.
- 실제 provider에서 제공 해주는 Resources와 Code의 맵핑 역할
- Resources의 Dependance 정보등이 저장 되어있는 Metadata 역할
- Cache 역할을 하여 리소스에 관련된 모든 값을 저장 하여 실제적으로 빠르게 plan 및 apply 할 수 있도록 함
- 가장 중요한 provision된 환경과 실제 코드의 Sync 역할
위의 내용을 읽고 tfstate 파일의 중요성을 인지 하게 되었고, Environment Code를 실제 환경과 잘 Sync하여 어떻게 관리할지 고민하게 되었습니다.
문제가 되었던 초기 컨셉은 파기하고 추후 따로 앱을 개발하여 개발자분들이 원하는 환경을 찍을 수 있도록 하는 방향으로 새로운 목표를 잡았습니다.
즉, 처음은 DevOps 팀에서 코드를 작성하고 tfstate를 관리하는 방향으로 선회 하였습니다.
그렇다면 핵심인 tfstate 파일을 어떻게 관리를 할 것인가?
이 시점에 Terraform Document 및 여러 Reference를 다시 리서치 하였습니다.
대부분의 글에서는 Consul이나 S3에서 tfstate 파일을 Environment Code별로 디렉토리로 관리하는 것으로 확인하였고
앞에서 언급한 바와 같이 tfstate 파일을 다른 계정 S3 bucket에서 소중히 관리하도록 정책을 결정했습니다.

실제 Stage 및 Perf 환경에서의 Terraform 삽질
실제 환경에 적용하기 전에 각종 모듈 코드를 작성하면서 개발 환경을 테스트했습니다. 그리고 이번에 Stage/Performance 환경을 개편하면서 Environment Code 및 Module Code를 추가로 리팩토링했습니다. 또한 CI/CD 환경 (이미 CI는 Codebuild를 사용하고 해당 코드는 이미 Terraform 전환이 완료된 상태) 및 실제 인프라 환경을 코드화 할 매니지드 서비스 분류도 시작하였습니다.
우리의 원칙1: 코드 관리와 수동 관리를 명백히 분리 하자
이 부분이 가장 중요한 파트 중 하나일 것 같습니다.
Security Group이나 IAM등 권한 문제 때문에 빠르게 수정하고 자주 변경되는 리소스들은 코드화를 해야 할지 수동적으로 관리할지에 대해 결정해야합니다.
이에 대해서는 유필성님과 논의한 후에 팀원들과 의견 공유하여 다음과 같이 결정했습니다.
- IAM 권한은 수동으로 관리하고,
- Security Group은 코드화를 하지만,
- Security Group을
EC2서비스나ALB서비스 만큼 너무 파편화를 하지 말고 Global 하게 사용 하자
제가 코드를 잘 분석하거나 코드 기여를 위하여 github repo에 PR을 자주 보내는 것은 아니지만(추후 기회가 되면 기여는 해보고싶은 큰 목적은 있지만..) 간혹 에러가 발생하면 Github Issue나 terraform-proiver-aws 소스를 보게 됩니다.
그 중에 resource_aws_default_security_group.go를 보니 Function들의 Error 메시지가 어떻게 처리되는지 확인할 수 있었습니다.
Terraform의 경우 tfstate와 sync가 되지 않으면 replaced하거나, 최악의 경우 destoryed 되어 재생성할 때 무척 조심해야 합니다.
그러나 Security Group의 경우 1차적으로 수동으로 수정하고 해당 Security Group Role을 코드에 작성하고 terraform apply 명령어를 실행해도 replaced 되지 않고 통과 되기 때문에 코드화를 하게 된 것입니다.
따라서 Security Group의 경우 1차적으로 수동으로 수정하지만 코드 반영만 정상적으로 된다면 문제 없다고 판단였고, 결국 코드화를 결정하였습니다.
우리의 원칙2: Terraform resouce간의 의존성을 확실히 이해 하자
Resouces 의존성을 확실히 이해해야 할 필요를 느끼게 된 이유가 있었습니다.
코드를 작성하다보면 module 코드에서 직접적으로 ARN 또는 ID 값을 가져오거나 아니면 data를 사용하여 연관되는 의존성 값을 가져오는 경우가 있습니다.
그런데 이런 작업이 순서대로 진행되지 않으면 Cycle Error(순환 참조 에러)가 발생하여 terraform apply가 되지 않습니다.
이와 같이 순환 참조와 관련된 에러가 발생하면 문제의 원인을 찾기가 쉽지 않습니다.
사실 terraform plan의 관점에서는 참조할 ARN 값을 직접 가져오기 보다는 known after apply로 표기 되면서 통과하기 때문입니다.
이 부분에 대해서는 troubleshooting-workflow 문서에 cycle error가 발생했을 때 어떻게 처리를 어떻게 하는지 잘 나와 있으므로, 참고하시기 바랍니다.
저의 경우 이 문제를 처리하는 과정에서 Terraform 코드를 서서히 이해하게 되었습니다. 만약 이해하지 못했다면 코드 작성시 순환 참조 에러를 처리하지 못했을 것입니다. 뿐만 아니라 수많은 삽질을 겪어야 했을 것이기 때문에 플로우 차트를 그리며 팀 동료들에게 상황을 공유하였습니다.
결국 코드 상의 Resource 사이의 의존성을 설명하고 적절히 정리를 해주신건 유필성 님이셨습니다. (감사합니다)
즉, 기본적인 Environment Code는 제가 설계했고 Commerce Stage Environment Code는 곽동우님이 코딩 및 리팩토링을 저와 같이 진행 해주셨습니다.

불타오르는 회의의 결과!
저희는 환경을 구성할 때 ECR, ALB, Launch Template, Autoscaling Group, Target Group, CodeDeploy, CodePipeline, Amazon MQ, Elastic Cache, ACM, Route 53등과 같이 여러 환경을 사용 합니다.
이러한 리소스를 생성할 때 순환 참조를 피하고 의존성을 확실하게 이해하기 위해, 저희는 먼저 생성 되어야할 리소스와 별개로 생성되는 리소스 분리가 필요했습니다. 그래서 컬리의 여러 개발팀에서는 저희가 사용하는 CI/CD 및 사용하고 있는 매니지드 서비스들 간의 연결 관계와 작업 순서도의 정리가 필요했습니다.
이를 요약하자면 다음과 같습니다.
- 기본적으로 MQ, Elastic Cache는 먼저 생성되어도 문제없음
- Route 53의 NameServer 및 도메인 설정 이후에는 ACM의 생성이 진행되어야 함
- ALB(기본 타겟 그룹 포함), Security Group이 생성되어야 함
- Launch Template 및 Target Grop을 먼저 생성하고 해당 값으로 ASG가 생성되어야 함
- 생성된 ASG 정보를 가지고 CodeDeploy 및 Codepipeline(ECR 트리거)이 생성 되어야 함
위와 같이 순환 참조를 예방할 수 있도록 정리하여 팀원들에게 공유했습니다.
만나게 되는 실체와 함정들
저희 DOE팀에서는 팀 단위 프로젝트로 업무로는 이번 Terraform 전환 작업이 처음이었습니다.
그러다 보니, 협업 하면서 다양한 함정을 만나게 되었습니다.
특히 코드를 작성하여 얻을 수 있는 자동화의 낭만보다는, 개인적인 협업과 관련된 경험 부족으로 인하여 여러 문제점을 만나게되었습니다.
잦은 코드 변경 및 기술 전파의 부족
만약 Terraform 구조에 대한 이해가 부족할 뿐만 아니라, 코드 작성에 대한 공부도 부족하면 어떻게 코드를 작성 해야할지 감을 잡기 어렵습니다.
이것은 일반적으로 Terraform에 입문하시는 분들이라면 모두가 고민하게 되는 부분일 것입니다.
저희 동료들의 경우 기본적으로 Terraform을 실제 서비스가 아닌, 테스트나 학습 목적으로 사용 해보신 경험은 있었지만 resource를 제외한 다른 부분에 대해서는 생소한 상황이었습니다.
때문에 이게 코드를 작성하는 건지 Copy and paste를 하는 건지 모르는 상황이 벌어졌습니다.
가령 variable 분리를 위해 왜 local 변수를 사용하는지라던가, 왜 코드를 단순화하는지라던가, 왜 data를 사용해서 ARN등의 정보를 가져와야하는지에 대한 내용 공유가 먼저여야 했습니다.
그러다보니 페어 프로그래밍이라는 좋은 협업 방법을 통해 공유하고 설명하였지만 결국 커뮤니케이션 부족이 발생하게 됐습니다.
결국엔 혼자서 코드를 수정하는 작업이 늘어나 많은 부분이 안타까웠습니다.
아쉬운 혼자만의 흔적(Q1과 kyuwon.lee는 동일인물)
코드 리뷰에서 발생한 문제점들
Terraform 코드에 대한 변경 사항을 리뷰할 때에도 문제점을 만나게 되었습니다.
인프라 Environment Code이다 보니 하나의 PR에서 무수히 많은 라인이 발생했습니다.
이 때에는 각 terraform plan이 실행됐다는 가정하에 신뢰의 도약을 하듯이 실제로 작성된 코드만 본 것이 큰 화근이였습니다.

신뢰하면 안되는데..
이런 화근을 알아차리기 전의 저희는, 코드 리뷰 시점으로 환경 리뷰까지 같이 진행하면서 서로 저희 내부적 환경을 리뷰하는 시간을 갖고 있었습니다.
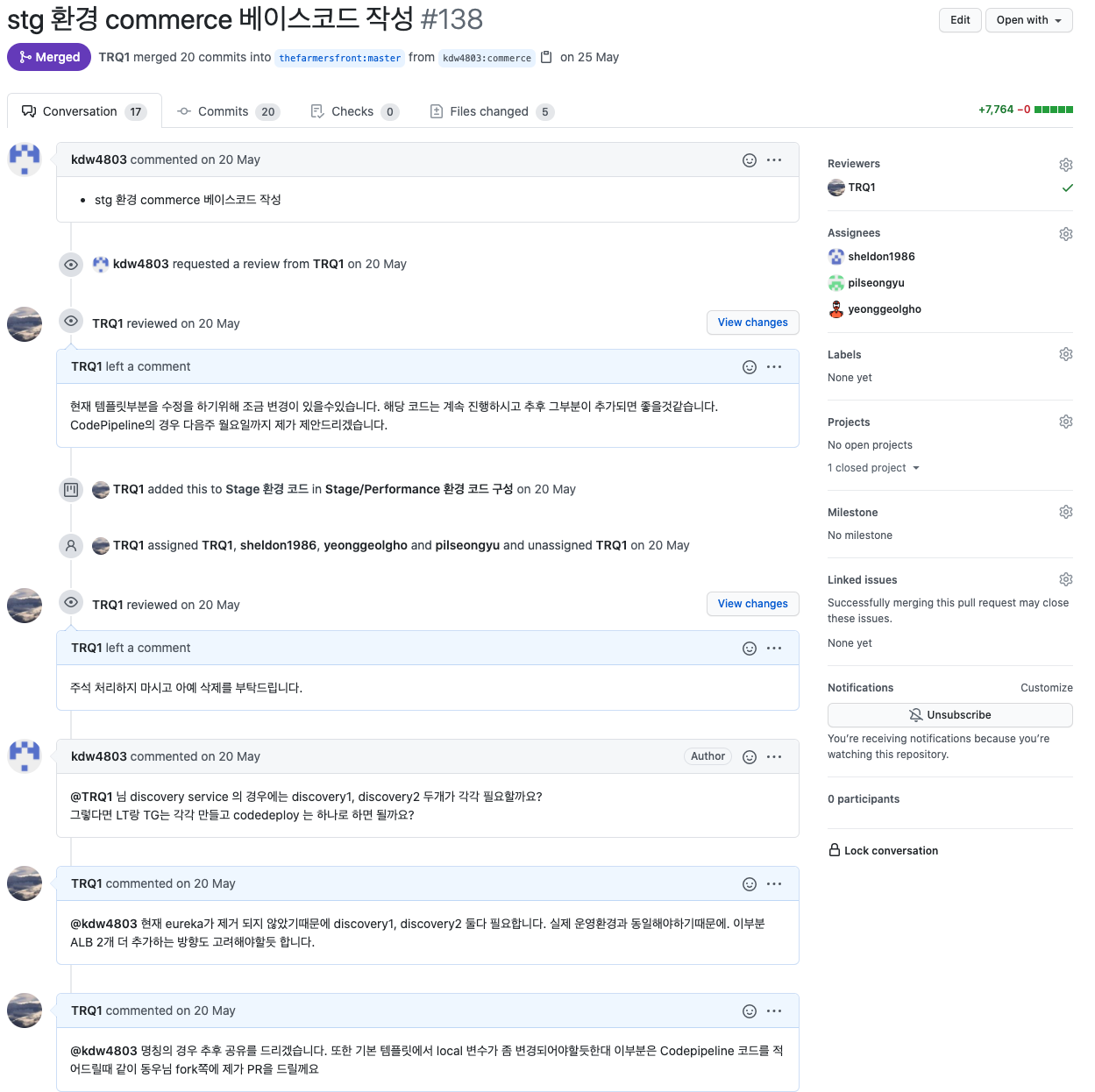
그런데 반복 코드가 많아짐으로써 조금이라도 최적화하기 위한 노력을 시작하게 되었습니다.
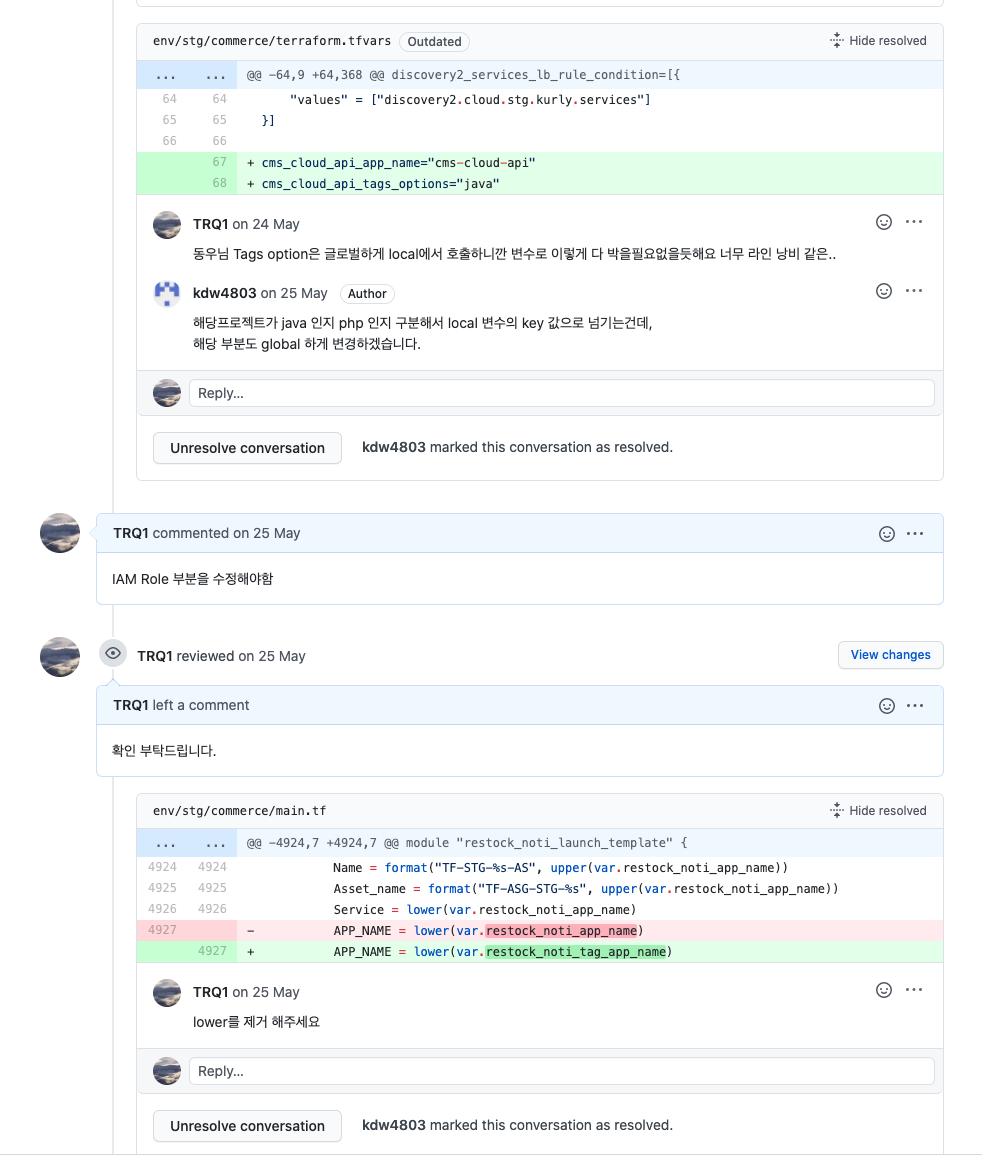
결국 실질적인 문제점은 해당 코드 리뷰 이후의 terraform apply 단계에서 발생하기 시작했습니다.
당연히 팀원분들이 각각 terraform plan을 실행하여 PR 시점에 진행을 완료하였지만,
여러 사람이 수정을 하고 테스트를 완료하지 않은 상황에서 점검과 서로를 믿고 머지하여,
terraform apply를 실행했을 때 무시무시한 must be replaced와 # forces replacement를 보게 되었습니다.
아래의 이미지는 예시로 들기위한 하나의 캡처 화면이지만, must be replaced 50개 이상이 뜨는 경우의 멘붕은 말로 표현하기 어려울 정도로 괴로웠습니다.
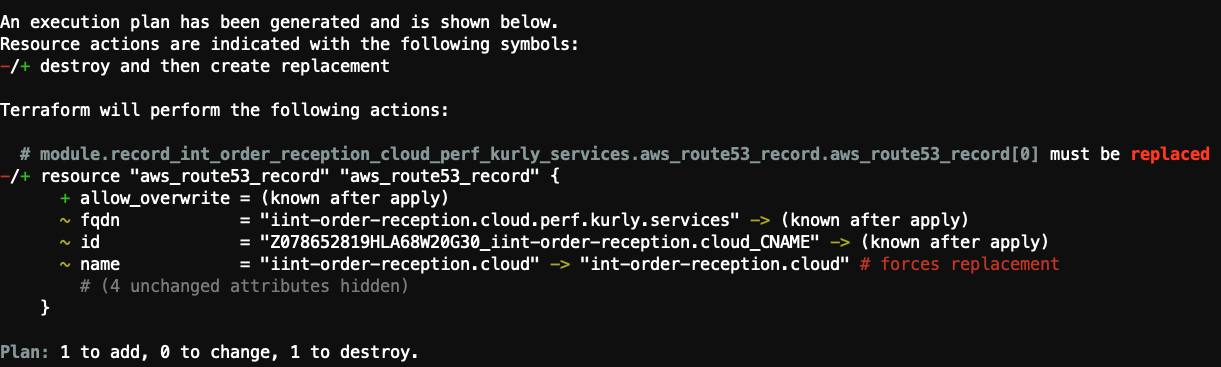
또한 수정 작업을 하다 보면 코드를 삭제하고 제 때 commit 하는 경우도 있지만, 코드의 양이 너무 많다 보니 이런 중요한 작업을 놓치는 경우가 발생하곤 합니다.
이후 이러한 문제점을 개선하기 위해 PR 시점에 terraform plan을 실행할 수 있는 환경을 구성하는 것이 추후의 과제로 잡히게 됩니다.
실시간 코드 및 환경 반영 or 수동 반영 후 코드 및 환경 sync
이 파트는 아마도 모든 Terraform 사용자의 딜레마일 것이라 생각합니다.
저희가 특정한 이유가 있어 수동으로 인프라를 수정하게 되면 그 이후에는 어떻게 해야 할까요?
..라는 질문과 논의는 저희가 경험한 다양한 이슈들 중 가장 큰 문제라 할 수 있었습니다.
저희가 Terraform을 사용해 반영한것은 stage/performance 환경이지만, 가끔은 스테이지에서도 (수동으로) 빠르게 값을 변경해야 하는 경우가 발생합니다.
이러한 경우는 PR을 보내서 리뷰를 받고 반영하는 것이 생산적일지 또는, 수동으로 처리한 이후 코드에 반영 하는 것이 현명한 일인지를 고민해 선택해야 합니다.
코드 관리와 수동 관리를 명백히 분리 하자 파트에서 언급했지만, 실제로 수동으로 작성하고 이후에 코드에 반영되어도 문제 없는 코드라던가, 아예 수동으로 리소스를 관리하는 자원을 열심히 분리하더라도…
결국 코드가 많아질수록 이런 고민을 해야 하는 상황이 늘어나는 것은 함정중의 함정인것 같습니다.
수동으로 코드를 수정하고 처리할 때 가장 에러들을 많이 보게 되는 것 같습니다.
그리고 이런 문제를 해결하거나 최적화 하기 위해서 모든 엔지니어들이 한결같이 Github Issue과 terraform-proiver-aws에 들어가 exception error나 Issue들을 찾아보게 되는 것 같습니다.
Route53의 예를 들어 봅시다.
실제 수동으로 코드를 작성하기 전에 도메인을 먼저 추가했다면, 해당 resource에 대한 실제 tfstate가 없기 때문에 but it already exists 에러 메시지가 발생합니다.
이렇게 되는 경우는 tfstate와 sync를 하기 위해 수동으로 해당 도메인을 직접 삭제하고 terraform apply를 하는 방법을 생각할 수 있습니다.
또는 각 resource 들마다 옵션이 다르겠지만 allow_overwrite 같은 옵션을 사용하여 이미 존재하는 리소스를 덮어씌워서 # forces replacement를 하는 방법도 있습니다.
하지만 담당 개발자나 엔지니어가 잘못된 코드를 수정 하였을때 반영이 되어버리면 대형 장애가 발생할 수 있기 때문에 저희는 이런 옵션들은 좀 더 연구를 하고 사용하기로 결정 하였습니다.
후기: 실제 사용 소감 과 앞으로 해야할 과제
Terraform은 진입 장벽이 높아 쉽게 익숙해질 수 있는 기술이 아니기 때문에, 동료들의 협력과 각오가 아니면 지옥문이 열릴 수도 있다고 생각합니다.
결국 자동화란 자신의 환경을 정말 정확하면서 속속들이 이해하고 있을 때 실천할 수 있는 일이고, 결국엔 AWS를 잘 알고 잘 사용해야 한다는 것이 아닐까 싶습니다.
그러나 만약 AWS Console 쓰기가 부담 스럽고, 형상관리가 필요하다면 Terraform을 사용하면 도움이 될 수 있습니다.
Terraform과 같은 도구를 사용하면 더 이상 트랙패드나 마우스 클릭으로 지루한 반복작업을 할 필요가 없고, 효율적으로 환경을 형상관리하여 문제가 발생해도 자동화된 코드로 모든 환경을 다시 복구할 수 있습니다.
그래서 새로운 요구 사항이 발생해도 기존 코드를 어떻게 리팩토링할까 어떤 방식으로 자동화를 할까 하고 고민하는 것이 즐거운 부분중 하나입니다.
하지만 아쉽게도 누군가가 편해지면 어느 누군가는 불편해질 수도 있습니다.
팀 내의 모든 사람들이 Terraform 익숙 하지 않고, 코드 작성보다 차라리 Console에서 수동으로 작업하는 것이 더 편한 분도 있을 수 있습니다. 어떤 경우에는 git 습득에 어려움을 느끼시는 분도 있을 수 있습니다.
그러므로 앞으로 해야할 과제는 다음과 같다고 생각합니다.
- 팀에 새롭게 조인하시는 분들이 Terraform에 쉽고 편안하게 익숙해지기 위한 교육 자료와 프로세스 정리
- 반복적인 환경의 경우 효율적인 Terraform 코드를 작성하기
- 수동 반영을 하더라도 사이드 이펙트가 잘 발생하지 않도록 꾸준한 디버깅과 리팩토링
- 내부 프로세스를 정비하여 지속적으로 코드 기여를 할 수 있도록 한다
- Environment Code가 길어질수록 효율적으로 관리할 수 있게 분리하는 작업을 한다
궁금하신 점이나 경험담을 공유하고 싶으시다면 언제든지 댓글로 남겨 주세요.
부족한 글을 읽어주셔서 감사드립니다!