VSMS: 가상 재고 관리 시스템
Virtual Stock Management System
마켓 컬리의 가상 재고 관리 시스템(이하 VSMS)은 기획팀, 개발팀, 데브옵스팀이 함께 약 8개월간 준비하여, 2020년 8월 30일에 최종적으로 라이브 배포되었습니다.
| 기획/PM 담당 | 최다은 | | 인프라 담당 | 이규원 | | 개발/운영 담당 | 김영근, 박제희, 이종립 (가나다순) |
VSMS의 기능은 크게 세 가지로 분류할 수 있습니다.
| 상품 코드 관리와 재고 수량 변경을 위한 관리자 API 제공 | | 컬리몰 고객님들을 위한 재고 수량 조회/증감 API 제공 | | 데이터 처리를 위한 배치 작업 실행 |
즉, 현실 속 상품들의 재고 수량을 컴퓨터 세상(가상)에 투영한 값을 관리하는 시스템이라 할 수 있습니다.

영화 매트릭스의 한 장면 (The Matrix. Lana Wachowski, Lilly Wachowski. Warner Bros. 1999.)
조회, 주문, 주문 취소 등 고객을 위한 중요 연산을 제공하므로 높은 성능이 필요하여,
개발 막바지에 다양한 성능 테스트를 수행했습니다.
덕분에 초기에 예상하지 못했던 다양한 문제를 발견하고 해결할 수 있었습니다.
이 글은 그렇게 해결한 여러 문제 중 3가지를 선정하여 소개합니다.
- 데드락 발견과 해결
- 리팩토링 결과 선택
- TPS 향상
이 외에 failover 처리 등 다른 중요한 문제들도 추후 기술 블로그를 통해 소개할 수 있기를 바랍니다.
두근두근 성능 테스트
목표 성능을 산정하자
마켓 컬리의 메인 페이지나 각종 카테고리에서는 재고가 0인 경우 노출 우선순위를 낮춥니다.
즉, 마켓 컬리에 접속하는 모든 사용자는 어느 페이지에 들어가도 VSMS의 재고 수량 조회 API를 호출하게 됩니다. 그러므로 VSMS의 성능 목표를 산정하려면 현재 운영되고 있으면서 가장 많이 호출되는 재고 조회 API의 성능을 참고해야 합니다. 저희는 이규원 님의 조언에 따라 성능테스트 전 약 2주간의 RPS를 참고하기로 결정하였습니다.1
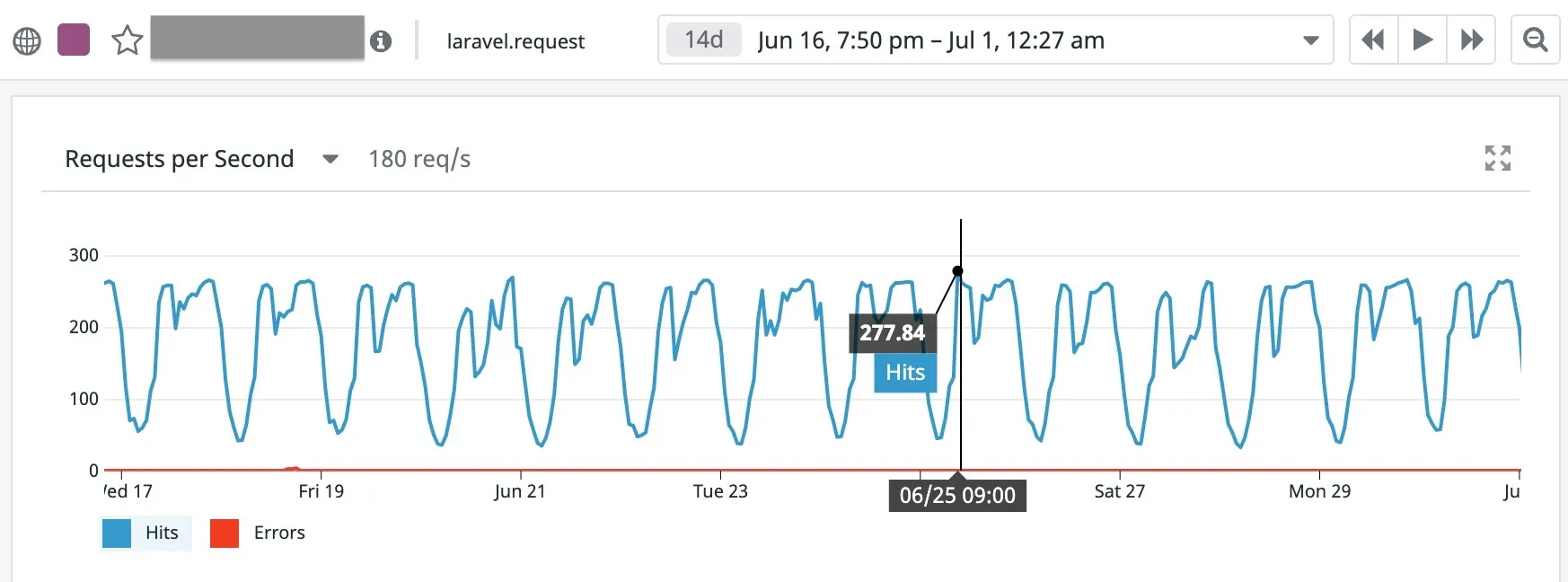
2020년 6월 16일부터 7월 1일까지 주요 API를 가동하는 수십 대의 인스턴스들 중 2대의 RPS를 보여주는 그래프.
기준 자료는 수십대의 운영 인스턴스 중 2 대의 로그를 샘플링하여 구성된 것이었습니다.
이를 통해 8월 무렵의 필요 Peak TPS로 소박하게 약 300 TPS를 예상한 다음, 4배를 곱한 수치인 1200 TPS를 목표로 결정했습니다.2
| × 2 | 김포 물류 센터가 추가될 예정이므로, 2배로 늘어날 물류에 대한 요청을 커버할 수 있어야 한다. | | × 2 | 마켓 컬리의 성장세를 커버할 수 있어야 한다. (2배 성장 자신감) |
즉, VSMS의 성능 목표는 다음과 같았습니다.
VSMS 인스턴스 2대가 운영 인스턴스 2대보다 4배의 부하를 견뎌낼 수 있어야 한다.
첫 성능 테스트에서 DB 데드락이 나왔다?
2020년 7월 2일, 이규원 님과 박제희 님의 주도로 공식적인 첫 성능 테스트를 실행했습니다.
머신 스펙은 다음과 같았습니다.
| 인스턴스 | c5.xlarge(4 core, 8GB) |
| RDS(aurora) | r5.large(2 core, 16GB) 2대 |
총 6개의 Agent 로 vuser를 300 만큼 생성하여 부하를 주도록 설정했습니다.
테스트 내용은 재고 차감, 재고 증가, 재고 조회, 재고 초기화였는데…
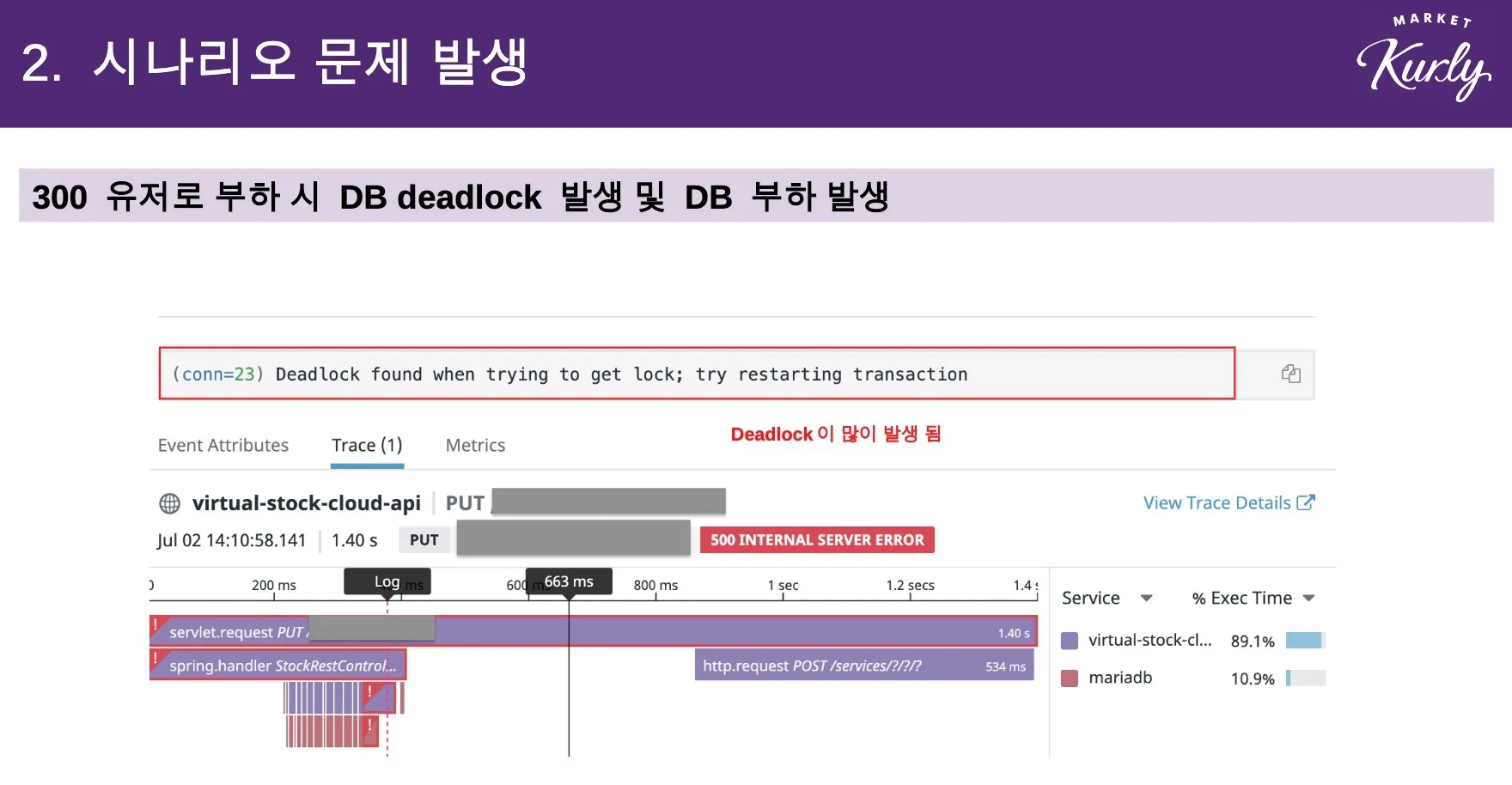
목표 TPS에 도달하기는커녕 DB에서 데드락이 발생하는 것을 확인하고 말았습니다. 😭
게다가 commit에서 DB IO가 많이 발생하여 120 TPS라는 처참한 결과가 나왔습니다.
성능 테스트 리허설에서는 1200 TPS를 거뜬히 넘겼었기 때문에 이 결과는 저희에게 큰 고민을 안겨 주게 됩니다.
데드락의 원인 ☠️
이후 며칠 간은 데드락을 해결하기 위한 몇 번의 논의와 실험이 있었습니다. 결론부터 이야기하자면 VSMS의 데드락은 논리 문제였으며, 단순한 자바 코드 한 줄로 해결되었습니다.
이를 이해하기 위해서는 먼저 재고 수량의 차감 과정을 설명해야 합니다.
재고 수량의 차감 과정
일반적으로 고객은 장바구니에 여러 상품을 담은 다음 구매하게 됩니다.
장바구니 => (A 상품 3개, B 상품 1개, C 상품 2개, ...)그리고 차감은 다음과 같이 하나의 트랜잭션 안에서 시퀀셜하게 발생합니다.
Tx1 => (A 상품 3 차감, B 상품 1 차감, C 상품 2 차감, ...)이렇게 순서대로 작업하다가 한 단계에서 문제가 생기면 트랜잭션을 롤백하여, 작업을 취소하고 응답하게 되어 있습니다.
데드락 발생 모델 💥
그런데 재고를 동시에 차감/증감시킬 때 교착 상태가 발생하는 문제가 성능 테스트를 통해 확인된 상태였죠.
문제가 발생하는 상황을 단순하게 모델링하면 다음과 같습니다.
Tx1 => (A 상품 차감, B 상품 차감)
Tx2 => (B 상품 차감, A 상품 차감)| 시퀀스 | Tx1 | Tx2 |
|---|---|---|
| 1 | A 잠금 | |
| 2 | B 잠금 | |
| 3 | B가 잠금에서 해제되길 기다림 | |
| 4 | A가 잠금에서 해제되길 기다림 | |
| 5 | B가 잠금에서 해제되길 기다림 | |
| 6 | A가 잠금에서 해제되길 기다림 | |
| … | …(무한반복) | …(무한반복) |
서로의 잠금이 풀리기를 기다리고 있으므로 교착 상태가 발생하게 되는 것이었습니다.
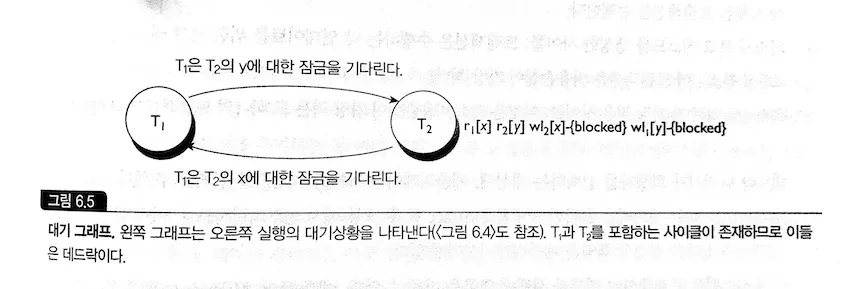
대기 상황 모델링 그래프(waits-for graph) 3
가장 간단한 해결 방법: 정렬
이 문제를 해결하는 방법은 다양합니다. 팀 동료들의 논의에서 제안된 대안만 해도 5가지 이상이었습니다.
- 트랜잭션 단위를 상품 하나로 제한하고 Queue 도입으로 순환 대기 방지
- 인 메모리 Queue 사용
- 외부 Queue 사용
- 안전 상태일 경우에만 차감(뱅커 알고리즘 응용)
- timeout을 줄여 빠르게 실패하게 하고, 클라이언트에서 재시도하도록 유도
- Redis 도입
- Java Phaser 사용
- …
그러나 남아있는 개발 일정과 코드의 복잡도 등을 고려한 결과 작은 실험을 한 가지 해보기로 했습니다.
실험: 각 트랜잭션의 차감 대상 상품을 정렬한다.
이종립 님은 작업 대상을 정렬하면 이론적으로 (A, B) (B, A)와 같은 순환 대기를 제거하고, 잠금 대상에 순서를 붙이므로 교착 상태를 방지할 수 있으리라 추측했습니다.
Tx1 => (A 상품 차감, B 상품 차감)
Tx2 => (A 상품 차감, B 상품 차감)| 시퀀스 | Tx1 | Tx2 |
|---|---|---|
| 1 | A 잠금 | |
| 2 | A가 잠금에서 해제되기를 기다림 | |
| 3 | B 잠금 | |
| 4 | A가 잠금에서 해제되기를 기다림 | |
| 5 | 작업 완료 A, B 잠금 해제 | |
| 6 | A 잠금 | |
| 7 | B 잠금 | |
| 8 | 작업 완료 A, B 잠금 해제 |
작업은 너무나도 단순해서 일정을 고려할 필요가 전혀 없었습니다. 그냥 정렬 코드를 한 줄씩만 추가하고 PR을 올렸습니다.
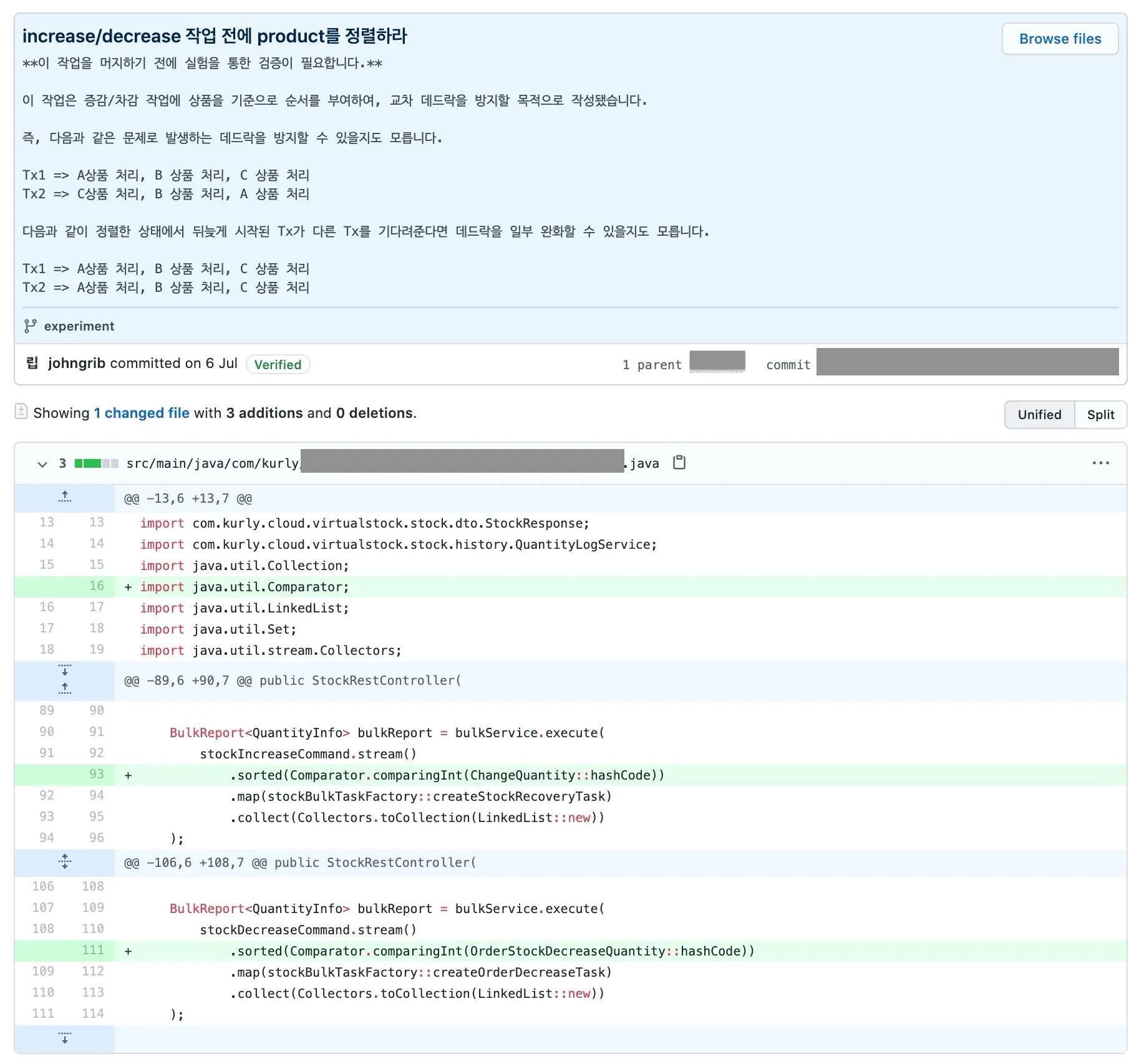
이 3줄짜리 변경사항이 있는 PR을 통해 우리는 데드락을 제거할 수 있었습니다. 이후의 성능 테스트에서는 DB 처리 지연에 의한 타임아웃은 발생했지만, 같은 원인에 의한 데드락은 발생하지 않았습니다.
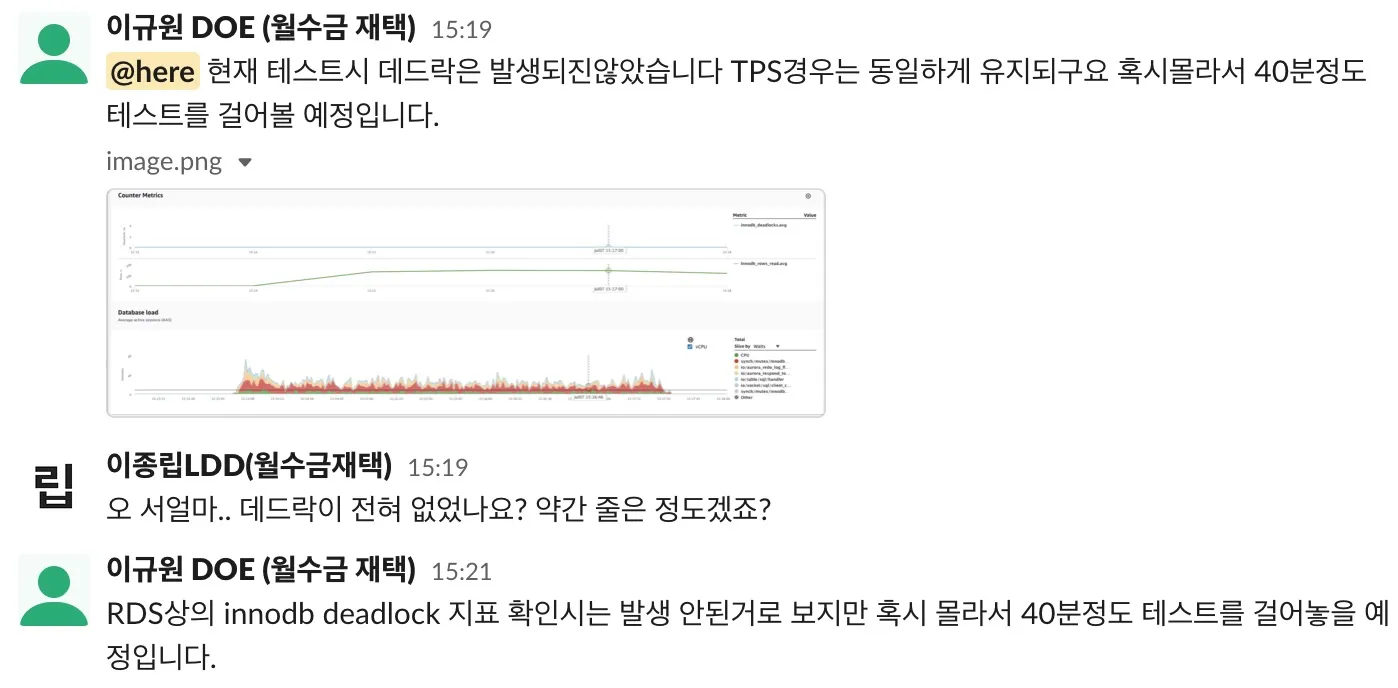
가장 큰 병목은 데이터베이스 IO
DB 입출력 최소화로 TPS를 대폭 향상시키자 💨
데드락 문제를 해결한 이후에도 성능 테스트는 꾸준히 반복됐습니다. 저희는 반복적인 성능 테스트를 통해 DB IO가 가장 큰 병목이라는 사실을 깨달을 수 있었습니다.
따라서 다음과 같은 과감한 실험을 할 필요가 있었습니다.
실험: DB 입출력을 할 수 있는 한 최소화한다.
리팩토링을 진행하기 전에 I/O 최소화 결과를 빠르게 확인하기 위해 임시 클래스를 작성하고, 모든 처리를 하나의 클래스에서 처리하는 프로시저 형태의 코드를 작성해 보았습니다. 여기저기에서 발생하고 있는 DB commit을 한 곳에 모아 한꺼번에 처리하려 한 것입니다.
다음은 이 실험에서 변경된 코드 중 하나인 차감 작업 큐 생성 메소드입니다. 삭제된 부분을 읽어보면 차감 요청 하나를 처리하고 있는 반면, 추가된 부분은 여러 차감 요청을 한꺼번에 처리하고 있음을 알 수 있습니다. 이후 몇 가지 과정을 거쳐 commit이 발생하게 되므로 이 작업은 commit 횟수 감소에 적절히 기여하게 됐습니다.
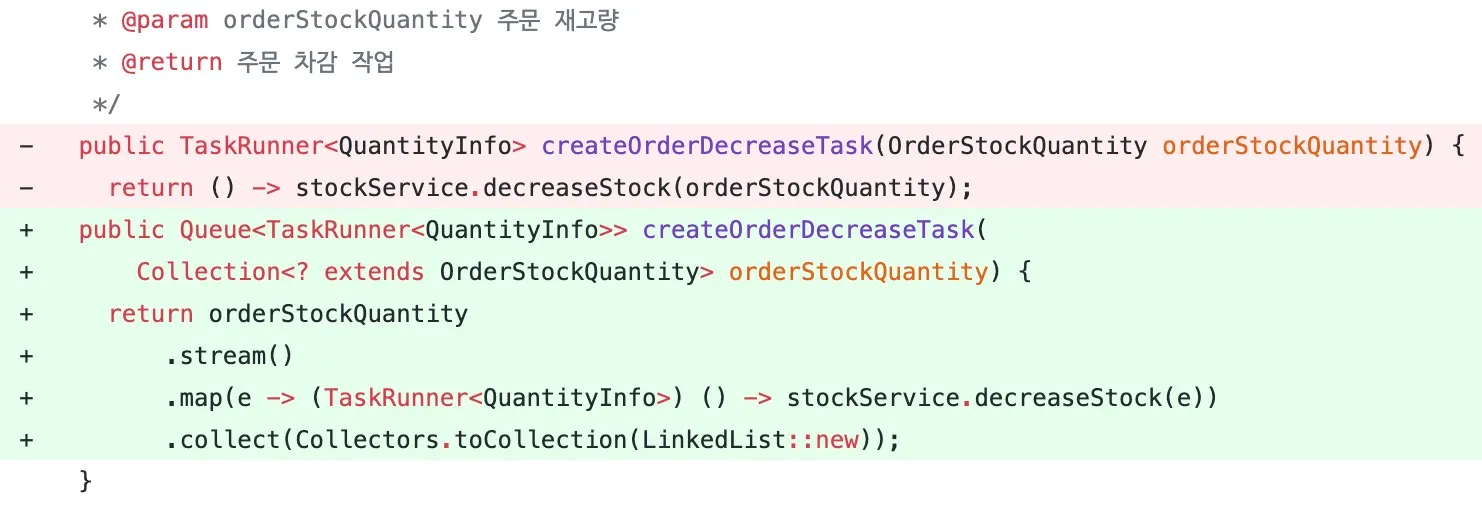
이 실험을 위해 변경된 코드의 겉모습은 아쉬운 점이 많았습니다. 코드의 모양이 마치 stored procedure 같았기 때문입니다. 만약 이 코드를 적용한다면 대규모의 리팩토링이 필요할 것이었습니다.

성능은 향상되었겠지만, 테스트와 유지보수가 곤란해진 코드.
하지만 성능 테스트 결과는 꽤 괜찮았습니다.
다음의 조건으로 nGrinder 기준 320 TPS, DataDog APM 기준 512 RPS가 나왔기 때문입니다.
| 인스턴스 | c5.xlarge(4 core, 8GB) 2대 |
| DB | 2 core, 2GB 2대 (커넥션: 인스턴스 당 20개) |
앞선 성능 테스트에서는 DB에 r5.large(2 core, 16GB)를 사용하고 있었으므로 320 TPS는 이전보다 대단히 개선된 것이라 할 수 있었습니다.
이후 다음과 같이 DB 스펙을 조정한 다음 테스트를 해보았더니 더 괜찮은 결과가 나왔습니다.
| 인스턴스 | c5.xlarge(4 core, 8GB) 2대 |
| DB | 8 core, 60GB 2대 (커넥션: 인스턴스 당 20개) |
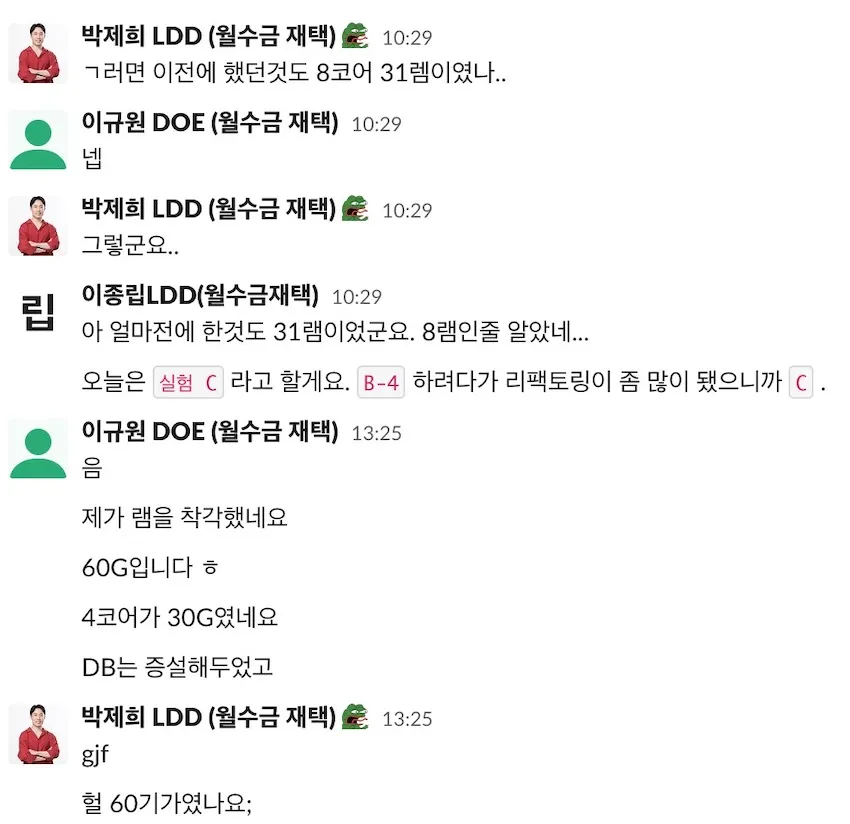
60GB 램을 쓰게 되다.
5분간 27만 건을 처리하고 nGrinder 기준 924 TPS, DataDog APM 기준 1600 RPS가 나왔습니다. 에러는 2건뿐이었습니다.
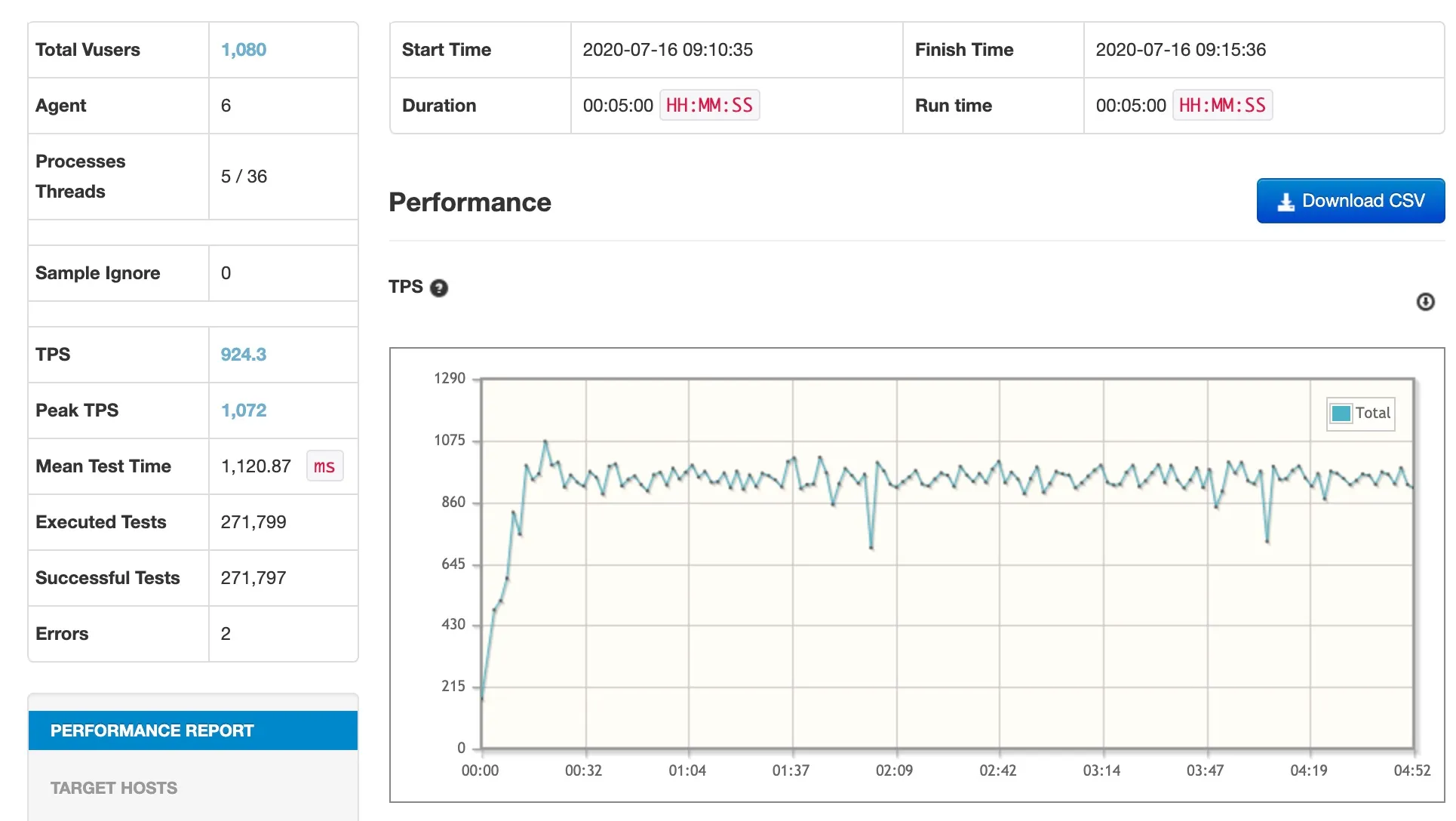
리팩토링한 결과를 채택해야 할까? 🤔
확실한 성능 향상을 확인하자, 이제 stored procedure처럼 바뀌어버린 코드를 리팩토링할 때가 됐습니다.
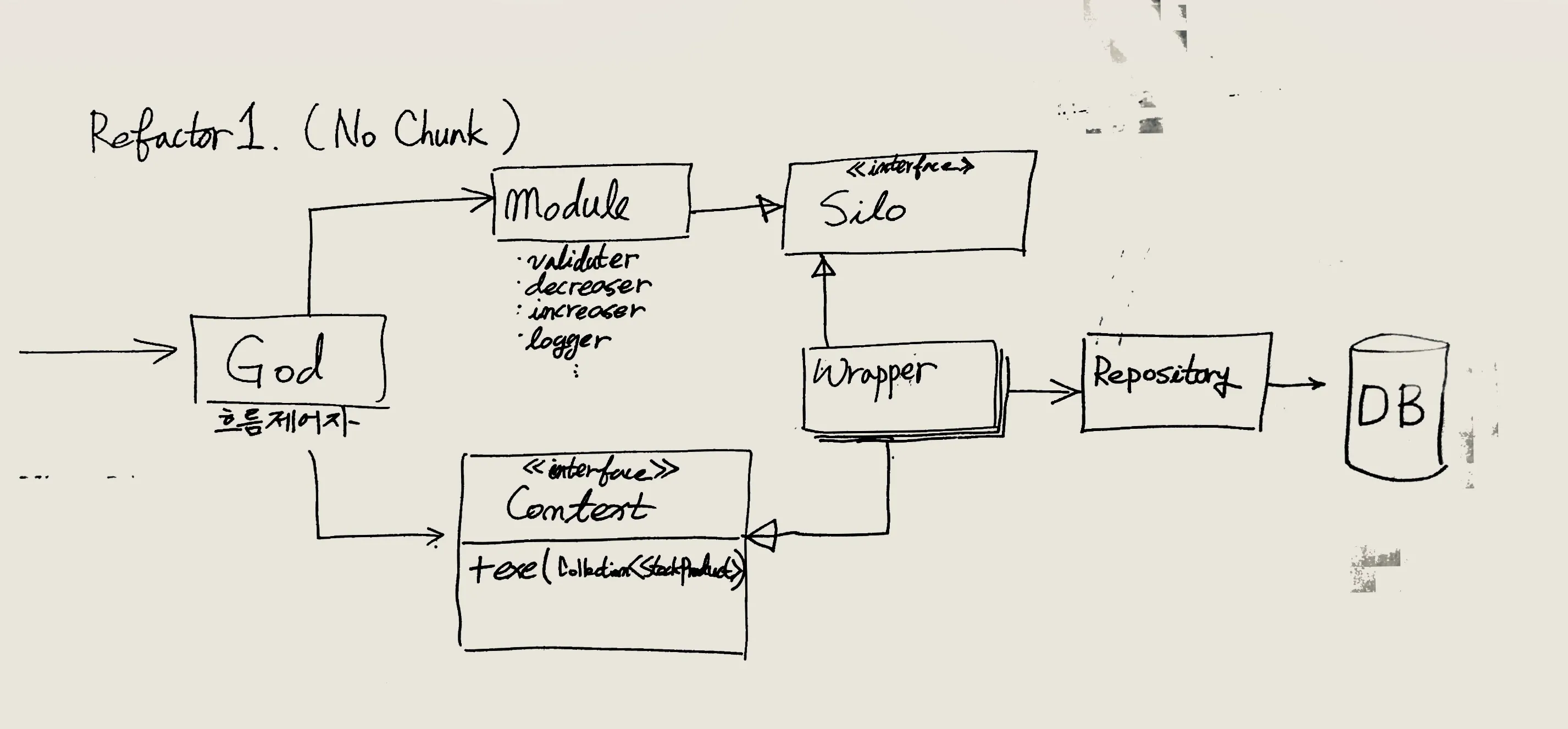
2020년 7월 15일. 박제희 님의 리팩토링 계획을 이종립 님이 토론을 위해 화이트보드에 옮겨 그린 모습.
그런데 다음과 같은 걱정이 생겼습니다.
실험을 위해 가독성을 포기한 현재의 코드보다, 리팩토링한 결과가 성능이 더 안 나오면 어떡하지?
그래서 우리는 리팩토링 전후를 비교하기 위해 두 버전을 기준으로 성능 테스트를 돌려보기로 했습니다. 하드웨어 스펙을 일치시킨 상태에서 두 버전을 테스트한 결과 TPS가 더 높게 나오는 것을 선택하면 된다고 단순하게 생각했던 것입니다.
그런데 이게 쉬운 일이 아니었습니다.
조건이 같아도 랜덤하게 어떨 때는 리팩토링한 쪽이 더 좋게 나오기도 하고, 어떨 때는 리팩토링을 하지 않은 쪽이 더 좋게 나왔기 때문입니다. 보통 이런 상황이라면 두 버전의 성능이 큰 차이가 없다고 판단하고 리팩토링한 결과를 고르는 것이 올바른 선택일 것입니다.
하지만 반복적으로 테스트를 하는 입장에서는 그 판단이 쉽지 않았습니다. 계속해서 자료를 보고 있자니 리팩토링을 하지 않은 쪽이 “미묘하게” 더 좋은 성능을 내는 것처럼 보였기 때문입니다.
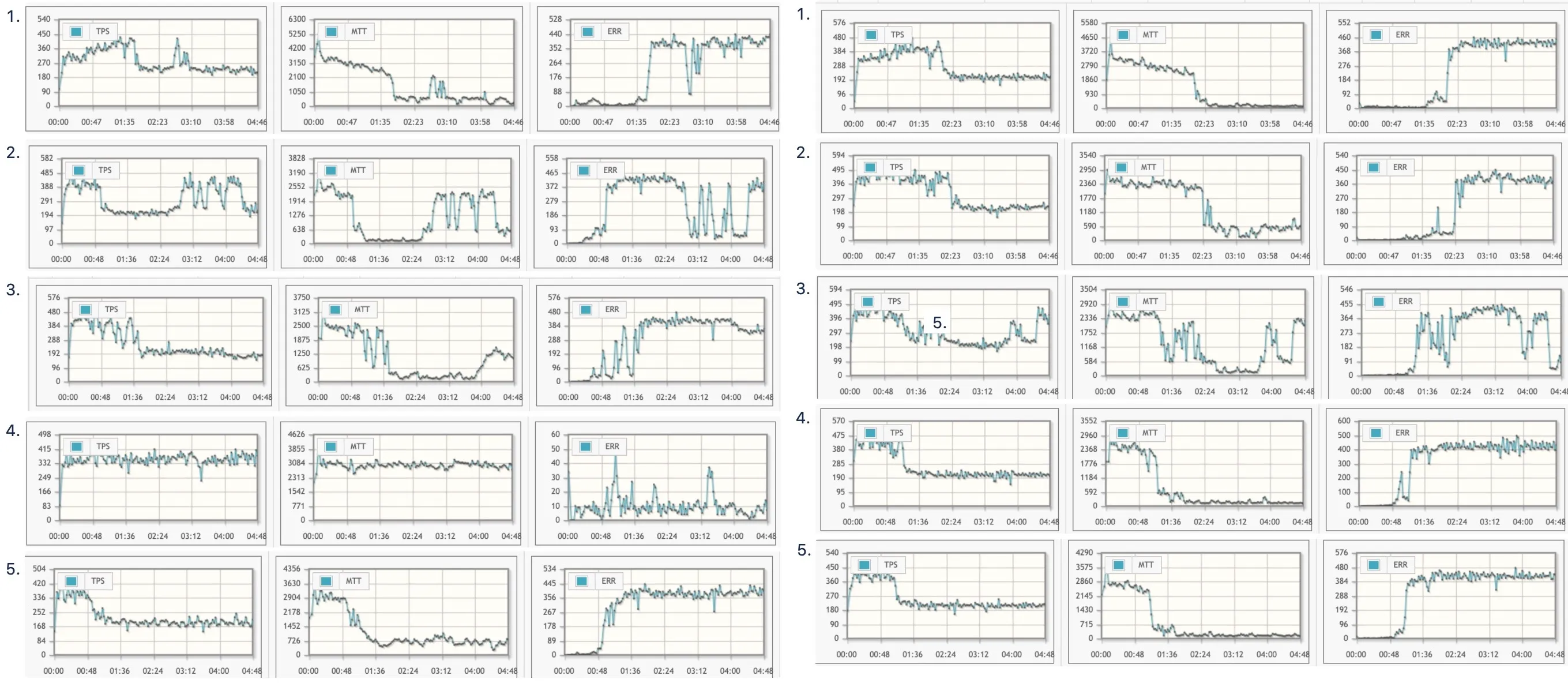
왼쪽이 성능을 위해 가독성을 포기한 버전. 오른쪽이 리팩토링을 마친 버전.
그래서 두 버전의 우위를 더 확실히 비교하기 위해 실험 조건을 더 통제하기로 했고, 하나의 API로 상품 하나만을 처리하는 성능 테스트를 다시 몇 차례 진행한 결과 두 버전 사이에 차이가 있다 해도 아주 근소한 정도만 있다고 결론을 내리게 됐습니다.
그리고 2020년 7월 23일, 박제희 님의 정성 어린 리팩토링 작업이 머지되었습니다.

DB 커넥션을 아껴서 성능을 더욱 끌어올려 보자
그렇다고 끝은 아니었습니다. 성능을 더 향상할 수 있는 포인트가 또 있었기 때문이었습니다.
DataDog의 APM 지표를 확인해보니, 수량변경 로그 적재에 이용되는 DB IO가 생각보다 큰 비중을 차지하고 있었습니다. 로그 때문에 커넥션 점유를 하는 지점이 생겨서 중요한 기능이 최상의 퍼포먼스를 내지 못하고 있는 상태였던 것입니다.
로그 데이터를 몽고DB로 분리하자
박제희 님이 대단히 좋은 아이디어를 제안하셨습니다.
“수량 변경 로그를 메인 DB에서 분리해 MongoDB로 옮기면 RDB 커넥션을 그만큼 덜 맺게 될 테니까 성능을 더 끌어올릴 수 있을 것 같아요.”
너무 좋은 생각이었기에 바로 찬성하고 작업에 들어가게 됐습니다.
여러 차례의 성능 테스트를 하면서 RDB 커넥션을 최소한으로 하는 것이 성능에 얼마나 큰 영향을 끼치는지 알게 됐기 때문입니다.
이 작업은 2020년 7월 22일부터 8월 4일까지 약 2주가 걸렸습니다.
성능 테스트 결과
성능 테스트 결과도 썩 괜찮았습니다.
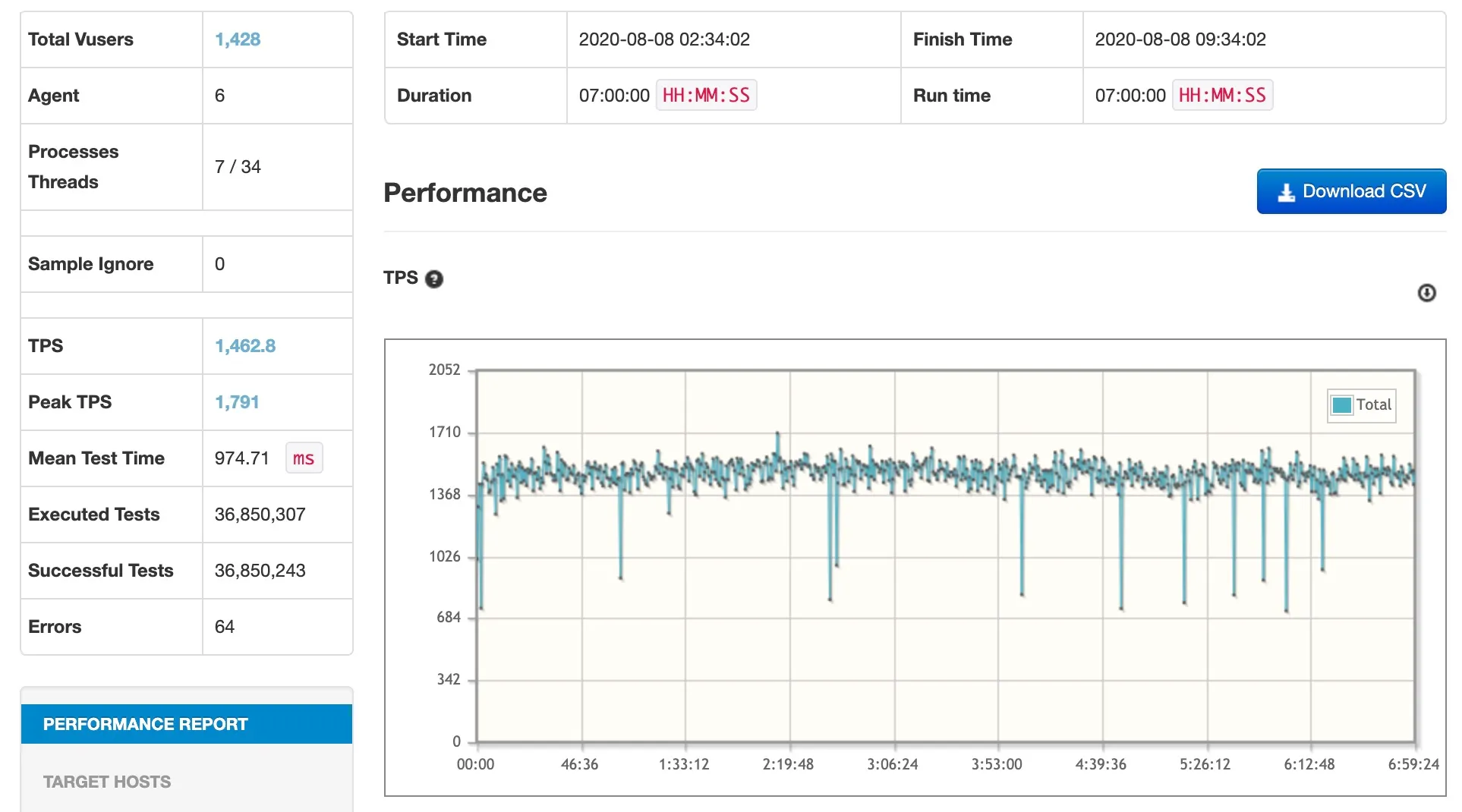
다음 테스트는 2020년 8월 8일 02시 34분부터 7시간 동안 돌면서 3,685만 건의 요청을 처리했고 1,462 TPS를 기록했습니다.
그리고 뒤이어 4시간 45분 동안 돌면서 2,476만 건의 요청을 처리했고 1445 TPS를 기록했습니다.
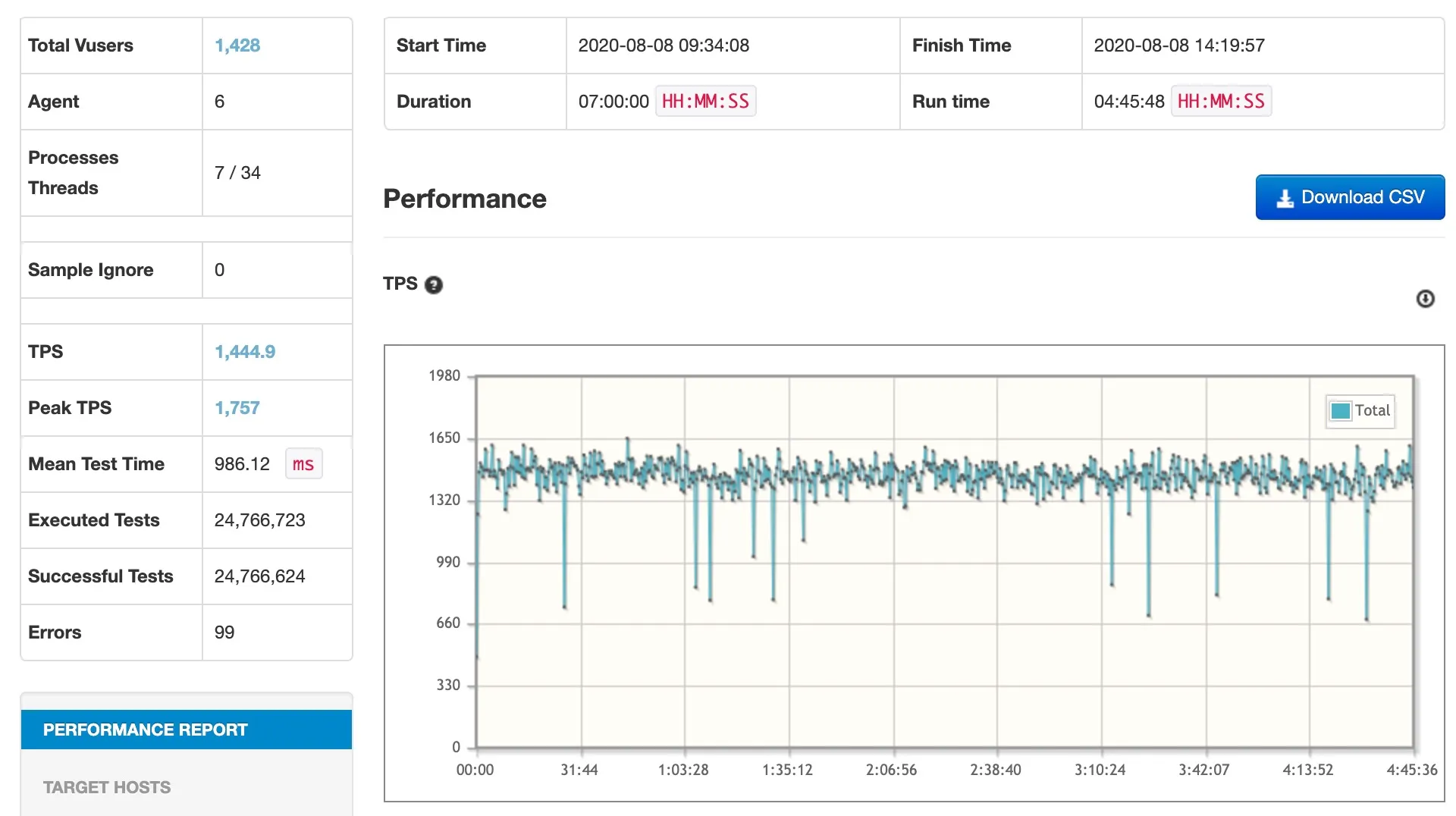
즉 11시간 45분 동안 약 6,161만 건을 처리한 것입니다.
그리고 몇 가지 작업을 거치자 VSMS는 이후의 성능 테스트에서 1500 TPS 이상을 유지했습니다. 목표 TPS를 충분히 넘겨 도달한 것입니다.
게다가 성능 테스트에 사용한 머신의 스펙은 운영 환경의 머신보다 떨어지므로 한동안 TPS 걱정은 없을 것 같습니다.
결론
성능 테스트를 수행하는 도중 처음에는 예상하지 못했던 다양한 문제를 마주할 수 있었습니다. 화려한 해결책보다 기본에 충실하며 단순한 코드가 얼마나 중요한지를 다시금 깨달을 수 있었습니다. 문제를 해결하기 위해서 동료들과 협력하며 적극적으로 나서는 태도의 소중함도 돌아보게 되었습니다.
VSMS는 2020년 8월 12일에 백그라운드 배포되었고, 2020년 8월 30일에 전면으로 나서게 되면서 마켓 컬리의 재고를 담당하는 서비스가 되었습니다.
개발은 끝났지만, 운영과 유지보수는 이제 시작된 셈입니다.
이후로도 VSMS에 대해 말씀드릴 화제가 생겨서 기술 블로그에 다시 공유할 수 있으면 좋겠습니다.
긴 글 읽어주셔서 감사합니다.
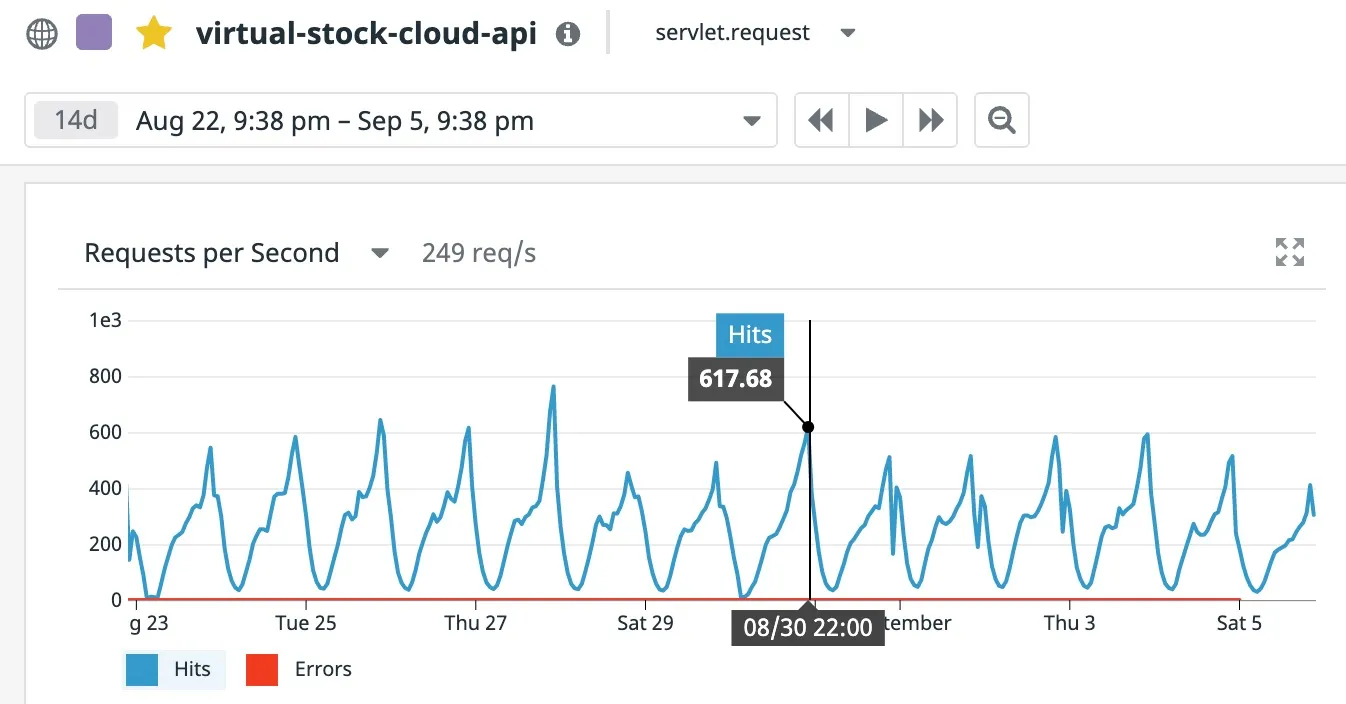
서비스 라이브 후 VSMS를 가동하는 수십 대의 인스턴스들 중 2대의 RPS를 보여주는 그래프.
참고문헌
- 트랜잭션 처리의 원리 / 필립 A. 번스타인, 에릭 뉴코머 공저 / 한창래 역 / KICC(한국정보통신) / 1판 1쇄 발행 2011년 12월 19일