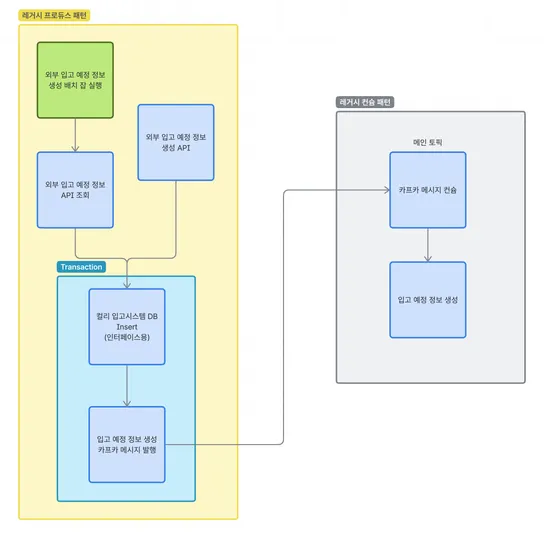
들어가기 전
- 주의 1. 해당 글에서 나오는 고민과 선택, 결과 및 실행 방법이 모두 옳거나 최선이 아닐 수 있습니다.
- 주의 2. 최대한 한글을 사용하였지만 의미 전달에 있어서 꼭 필요한 부분에는 영문 혹은 개발 용어를 그대로 사용하였습니다.
- 주의 3. 해당 글에는 오류와 수정사항이 존재할 수 있습니다. 알려주시면 검토 후 업데이트하겠습니다.
표준화
2022년 상장을 앞둔 컬리는 2015년 서비스를 개시한 이후 가파르게 성장하여 ‘새벽배송’이라는 시장을 개척해 냈습니다. 지금 이 순간에도 컬리는 빠르게 성장하는 중입니다. 컬리와 유사하게 급성장하는 곳이라면, 또 많은 서비스를 제공하는 곳이라면, 어느 순간 비슷한 고민거리와 마주하게 될 수 있습니다.
동시다발적으로 늘어나는 요구사항을 개발하며, 유사하거나 동일한 기능을 각 조직과 수행 프로젝트에서 별도로 개발, 관리하는 상황이 생기고 이를 운영하면서 비슷한 문제를 만날 때마다 제각각 다른 방법으로 대응해야 할 때가 있습니다.
수행 조직 관점에서는 잘 표시가 나지 않지만 그 범위를 확장해서 보면, 절약할 수 있는 인원과 시간을 확인할 수 있습니다. 그러한 고민의 해소를 위해 표준화를 생각하게 되었습니다.
well-known library vs in-house built
장기적으로는 우리가 해결할 문제들의 집합(도메인)을 전사적으로 설정하고 작은 단위의 문제부터 큰 범위의 문제까지 해결할 수 있는 하나의 구현체를 제공하는 것도 좋은 방법이겠지만 외부에서 제작하였지만 기능에 대해 어느 정도 검증이 된 라이브러리를 필요와 상황에 맞게 사용하기로 약속할 수도 있을 것입니다.
예를 들어, ‘물류 웹개발팀’에서는 A, B 애플리케이션을 동시에 개발하면서 Date 객체를 사용할 때 이와 관련한 기능은 Day.js를 사용하기로 약속했습니다. 이렇게 널리 알려져 많이 사용되는 라이브러리를 사용하게 되면,
- 해당 기능의 개발 시간을 단축할 수 있다
- 다수의 애플리케이션에 동시 적용이 가능하다
- 비슷한 고민과 문제의 해결책을 찾기 수월하다
등의 이점을 얻을 수 있습니다.
하지만,
- 기능과 목적에 비해 무거울 수 있다
- 해당 라이브러리를 직접 수정해야 할 수 있다
- 신뢰도가 떨어진다
- deprecated 될 수 있다
등의 위험요소가 있습니다. 동일한 규격의 기능을 각기 다른 프로젝트에 적용시킬 수 있다는 것은 생산성을 향상시키는 좋은 방법 중 하나입니다. 커뮤니티가 활발히 운영된다면 이미 겪었을 문제와 그 해결 방안에 대해 찾아보고 조금 더 빠르게 대응할 수 있습니다. 하지만 라이브러리에서 제공해 주지 않는 기능을 구현해야 할 때, 직접 라이브러리를 수정하거나 확장시켜야 하는 경우가 생길 수 있고, 불특정한 기여자나, 사용하는 라이브러리에서 의존하는 다른 라이브러리들 때문에 전적으로 신뢰할 수는 없습니다. 또 어느 순간 유료화가 되거나 버저닝 문제 혹은 치명적 오류가 발견되어 deprecated 될수도 있기에 중요한 서비스에 마음 놓고 외부의 라이브러리를 사용하기는 힘듭니다.
반대로 우리가 직접 만들면 이러한 문제가 모두 사라질까요?? 필요한 기능을 직접 작성하게 되면 우리가 가진 문제에만 집중할 수 있기 때문에,
- 가볍게 만들 수 있다
- 신뢰도를 높일 수 있다
- 내부 정책에 따라 (비교적 유연하게) 변경할 수 있다
등의 장점을 가질 수 있습니다. 물론 기능 개발을 어떻게 하느냐에 따라서 다르겠지만, 불특정 다수의 사용자들이 사용할 수도 있을 작은 가능성으로 여러 기능들을 포함시키거나, 작성한 코드베이스 전체를 리뷰하지 않아도 우리의 보안 및 내부 정책에 맞게 작성할 수 있고 또, 우리가 해결해야 할 문제가 변경될 경우나 제공자의 사정으로 사용하고 있는 라이브러리를 폐기할 가능성을 줄일 수 있습니다.
다만, 우리가 직접 작성하기 때문에,
- 별도의 개발 시간과 환경이 필요하다
- 코드베이스의 지속적 관리가 필요하다
- (작성자의) 즉각적 대응이 필요하다
등의 문제가 발생할 수 있습니다. 여러 프로젝트와 환경에 대응하기 위해서는 별도의 시간을 내어, 다수의 프로젝트 내에서 필요한 기능과 요구사항 등을 고려하여야 하며 요구사항이 급격하게 변경될 가능성이 있는 업무에서는 그에 맞춰 대응이 필요할 수 있습니다.
위에서 열거한 내용을 살펴보면 알겠지만 외부 라이브러리를 사용하느냐, 직접 만들어 관리하느냐는 선택일 뿐입니다. 어떠한 선택도 절대적으로 옳은 답(the correct one)은 될 수 없습니다.
공통 라이브러리의 시작
‘물류 웹개발팀’에서는 그 성격상, 하나의 프로덕트만을 관리하지 않습니다. 궁극적으로 지향하는 것은 물류 백오피스의 통합이고 해당 과제 안에서 각 도메인의 기능들을 하나씩 녹여 넣는 것이지만 지금 당장은 ‘파편화’ 되어있는 도메인과 ‘프런트엔드 기술 스택’을 ‘규격화’하는 것입니다. 그 일환의 첫번째로 우리는 react-boiler-plate(* boilerplate는 붙여 쓰는 게 맞지만 향후 외부 공개 시 검색에 우위를 두기 위하여 띄어쓰기로 명명하였습니다)를 제작하였고 신규 프로젝트 3개에 해당 템플릿을 이용하여 프런트엔드 개발을 진행하고 있습니다. 그와 함께 물류 조직에서 사용하고 있는 기능 중 공통으로 사용하는 것들을 찾아내고 우리가 해결해야 하는 주 문제 보다 시간과 인력이 많이 필요하다면 ‘외부 라이브러리’를, 그렇지 않다면 아주 작은 단위로 천천히 하나씩 ‘내부에서 제작하여 사용’하기로 결정하였습니다.
이렇게 하면, 각 도메인의 지식이 잘 공유된다는 전제하에, ‘컨텍스트 스위칭’ 비용이 줄어들 것이고 ‘확장’과 신속한 ‘대응’이 가능해질 수 있기 때문입니다. 아직 ‘물류 웹개발팀’은 팀을 만들어가는 과정 중에 있기 때문에 ‘버스 팩터’ 관리가 매우 중요합니다. 이를 높이기 위해서도 ‘기술 표준’은 필요했습니다.
코드베이스를 신뢰하는 방법
표준화를 하기 위해서, 우리에게는 기준이 필요했습니다. 아직 구체적인 안을 완성하지는 못했지만 1. 문서화 2. 코드 리뷰, 3. 테스트 스위트, 세 가지의 원칙을 세웠습니다. (* 외부 라이브러리 사용에 있어서도 동일한 기준을 가지고 있습니다)
문서를 통해서 해당 모듈이 어떠한 기능을 하는지, 어떻게 사용과 개발, 기여를 하는지 정보를 전달하고 코드베이스에 새로운 구문이 추가될 때마다 리뷰를 거치고 테스트를 통해 기능의 작동을 보증합니다. 이러한 행위들을 바탕으로, 우리는, 우리가 작성한 코드베이스에 용기를 불어넣고 그것을 다른 이들에게 공유하고 전파할 수 있도록 독려하기 위함입니다.
공통 라이브러리는 제공하는 쪽에도 부담이 될 수 있지만 사용하는 사람들도 신뢰할 수 있어야 합니다. 처음부터 완벽한 코드베이스를 제공하는 것을 지향하지만 그렇게 될 일은 없을 것입니다. 조금이라도 우리가 지향하는 바를 충족하기 위해 제공자는 위의 세 가지 원칙을 잘 준수하여야 하며, 이를 통해 사용자들이 신뢰할 수 있도록 약속을 만들고 이를 지켜나갈 예정입니다.
add-separator
우리가 가장 많이 사용하지만 구현이 제각각인 것이 무엇이 있을까 논의를 시작하였고 그를 통해서 몇 개의 안들이 추려졌습니다. 그중에서 숫자에 구분자를 추가하는 기능을 먼저 시작하기로 결정한 후 효율적으로 공통의 기능들을 관리할 방법을 모색하였습니다.
그리하여 lerna를 이용한 모노레포(mono-repo)를 구성하고 npm 패키지를 이용하는 방법을 선택하게 되었습니다. 모노레포를 이용하면 단일 저장소에서 여러 패키지를 관리하기 용이하다는 이점이 있으며 lerna를 이용하면 간단한(?) 설정을 통하여 공통의 설정을 공유하거나 패키지를 배포하는 과정과 버저닝을 조금 더 쉽게 할수있게 됩니다. 공유를 위해서 Nexus도 고려했었지만 현재로서는 폐쇄적으로 관리할 ‘중요한 기능’이 대상이 아니어서 접근과 설정이 친숙한 npm으로 하였습니다.
현재 저장소의 운영과 구성이 정리되지 않아서 비공개로 관리하고 있지만 22년도 상반기 내에 필요한 내용들을 업데이트하여 공유하도록 하겠습니다.
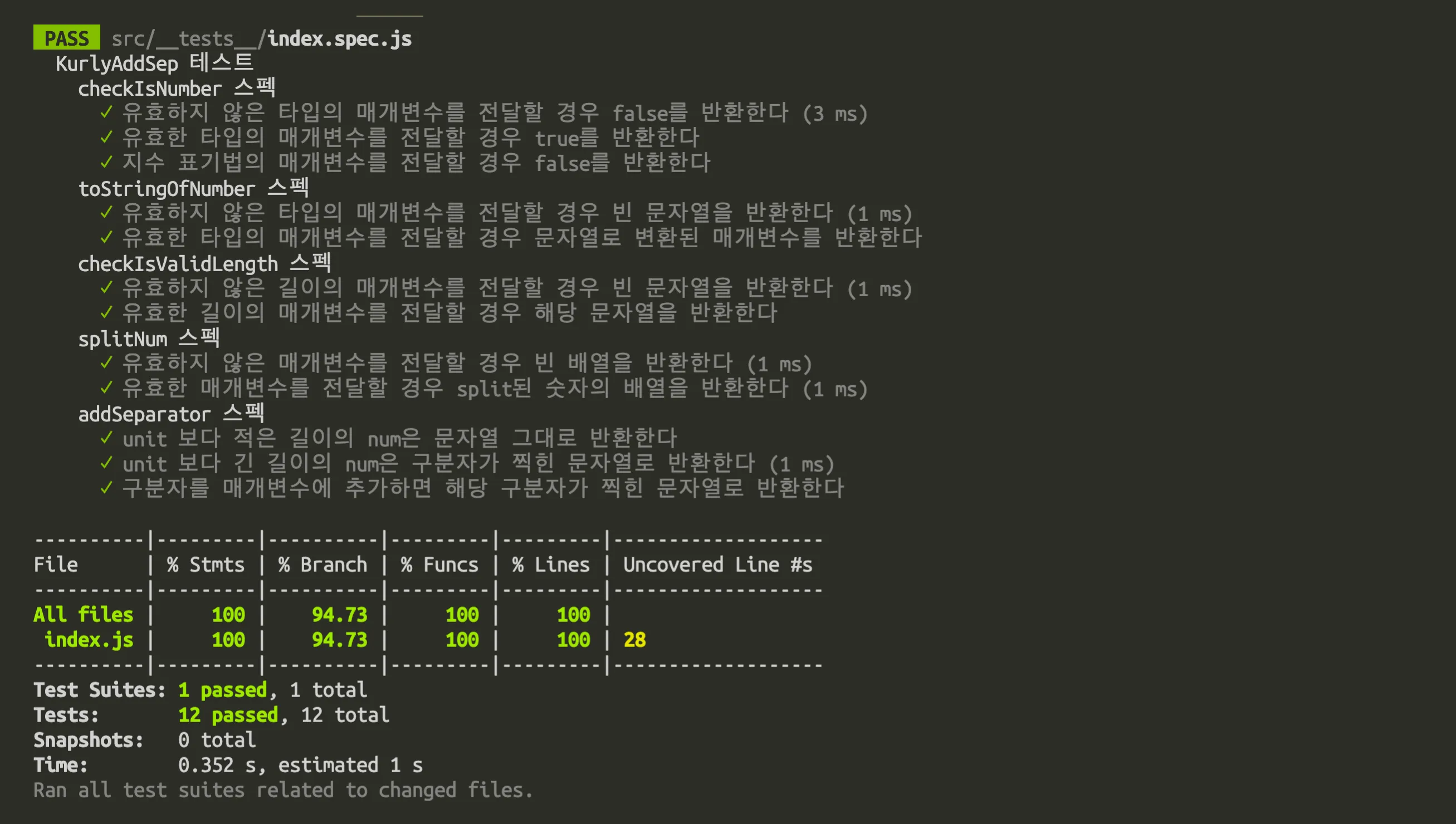 add-separator 테스트 실행결과
add-separator 테스트 실행결과
해당 기능의 개발은 TDD를 이용하였고 최대한 작은 기능들의 조합으로 제작하였습니다. 흔히 콤마 같은 구분자를 숫자에 추가할 때에는 ‘정규식’을 많이 사용하지만 기능의 확장 및 수정이 어려울 수 있으며 성능 저하의 원인이 될 수도 있습니다. 그래서 구분자를 추가하기 위해 필요한 것들을 나열하여 이를 통해 구현부의 인터페이스를 만들고 index.spec.js에 하나씩 필요한 기능들을 적어가며 기능을 완성해 나갔습니다.
export const RULES = {
MIN_LENGTH: 1,
MAX_LENGTH: 15,
};
export const checkIsNumber = (num) => {
if (num === '' || String(num).toLowerCase().indexOf('e') > -1 || isNaN(num)) return false;
return true;
};
export const toStringOfNumber = (num) => {
return checkIsNumber(num) ? `${num * 1}` : '';
};
export const checkIsValidLength = (num) => {
const strOfNum = toStringOfNumber(num);
const lengthIsGood = ((len) => {
return len >= RULES.MIN_LENGTH && len <= RULES.MAX_LENGTH;
})(strOfNum.length);
return lengthIsGood ? strOfNum : '';
};
export const splitNum = (num) => {
const validStr = checkIsValidLength(num);
return validStr.split('');
};
export const addSeparator = (num, unit = 3, sep = ',') => {
const validArr = splitNum(num);
if (unit >= validArr.length) {
return validArr.join('');
} else {
let AddedSepStr = ``;
validArr.reverse().forEach((v, i) => {
if (i > 0 && i % unit === 0) {
AddedSepStr = `${v}${sep}${AddedSepStr}`;
} else {
AddedSepStr = `${v}${AddedSepStr}`;
}
});
return AddedSepStr;
}
};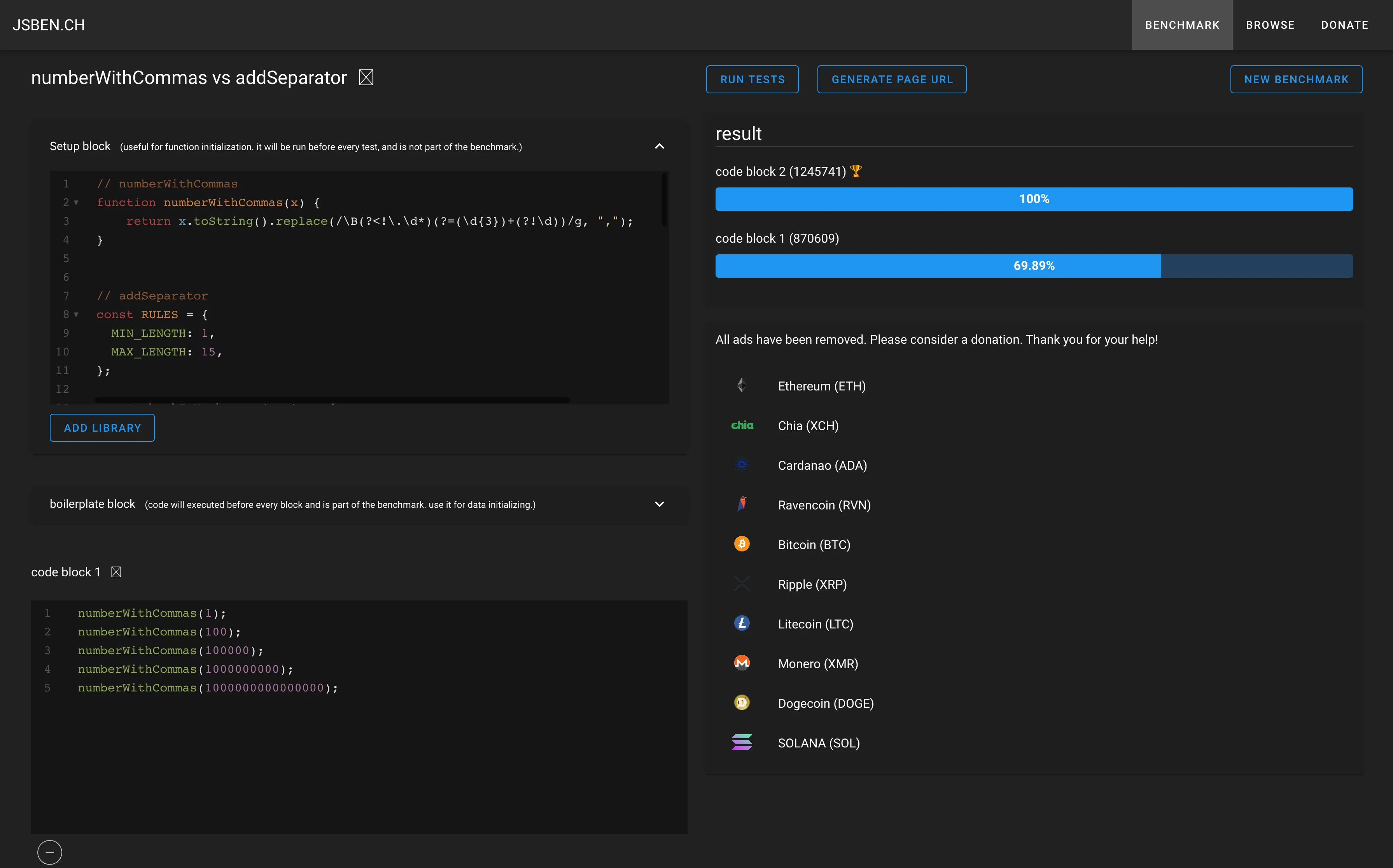 성능 테스트 결과 | 결과 페이지 / 모바일에서는 서비스 오류가 발생합니다
성능 테스트 결과 | 결과 페이지 / 모바일에서는 서비스 오류가 발생합니다
물론 성능 테스트의 결과는 측정 방법과 내용에 따라 다르고 절대적인 지표가 되기는 어렵지만 정규식을 사용한 함수 보다 조금 더 나은(평균적으로 20% 정도) 수치를 보여주고 있습니다.
* 해당 패키지는 npm에서 직접 확인 및 사용이 가능합니다. npm: @kurly-lfd/add-separator
마치며
아직은 작은 기능일 뿐이고 서툴거나 부족한 부분이 많이 있습니다. 이와 함께 기여를 받는 방법이나 대상, 또 저장소를 관리하며 생길 수 있는 이슈 등 생각해야 할 부분도 많이 존재합니다. 하지만 늘 그렇듯이 이렇게 작은 기능들을 꾸준히 작성하고 점진적으로 발전시킨다면 우리가 고민해야 할 부분 중 반복적으로 발생하는 ‘재발 비용’을 줄이고 그에 따른 생산성 향상을 기대할 수 있을 것입니다.
표준을 만들고 또 반복되는 업무를 줄여나가는 행위가 지금 당장 우리가 해결해야 할 일과는 무관하다 느껴질 수 있습니다. 하지만 소프트웨어 개발 조직이 커지면서 효율적인 의사결정과 소통의 비용을 줄이려면, 만드는 것에 그치지 않고 그것을 공유하고 재사용하는 문화가 필요하다 생각합니다. 이런 변화가 컬리의 개발 문화를 조금 더 성숙하게 발전시키는 데 도움 되리라 믿고 조금씩 조금씩 꾸준히 개발해 나가겠습니다.