도메인 지식을 LLM에게 어떻게 먹일 것인가. 이 질문에 대해 한 달간 세 가지 시도를 했고, 두 번 갈아엎었습니다.
이 글은 LLM Wiki를 RAG와 혼합해, 문서가 늘어도 적은 비용으로 질 좋은 컨텍스트를 제공하기까지 과정에서 겪은 시행착오들입니다.
들어가며
안녕하세요. 딜리버리프로덕트에서 컬리의 주문을 여러분의 집 앞까지 안전하게 배송하기 위해 불철주야 일하고 있는 김태훈입니다. 얼마 전까지만 해도 개발과 디버깅을 하며 삽질(?)의 나날을 보냈었는데요, 요즘은 그 주체가 AI로 바뀐 것 같네요. 오늘은 AI에게 질 좋은 먹이를 주기 위해 삽질한 내용을 공유하려 합니다.
배경 — 왜 시작했고, 왜 갈아엎었나
티켓을 만들거나 개발 설계를 할 때, 도메인을 잘 이해하고 있는 시니어 개발자·기획자와 같이 논의할 수 있으면 좋겠다는 생각이 자주 듭니다. AI가 이 자리를 채워주면 더할 나위 없을 텐데, 일반 LLM은 우리 회사 도메인을 모르니까요. 그래서 도메인에 특화된 시니어 AI를 직접 만들어보기로 했습니다.
처음 가져온 발상은 Andrej Karpathy의 LLM Wiki 패턴이었습니다. 마크다운 파일로 지식 베이스를 만들고, LLM이 그 wiki를 직접 읽으며 정리·유지하게 하는 패턴이죠. 매일 Confluence와 Slack에서 진행 중인 과제·도메인 관련 내용을 읽어 한 디렉토리(이하 knowledge/)에 마크다운으로 누적했습니다. 그러자 LLM이 도메인 맥락을 알고 답하기 시작했고, 처음엔 잘 동작하는 것 같았습니다.
그런데 문서가 쌓일수록 매 대화마다 LLM이 컨텍스트에 로딩하는 양도 같이 늘어났습니다. 30개가 50개, 100개가 되니 이대로 가면 토큰 비용은 폭증하고, 컨텍스트가 길어질수록 가운데에 위치한 정보를 LLM이 놓치는 lost in the middle 현상으로 응답 품질까지 떨어집니다. 그래서 발상을 바꿨습니다 — 전부 다 보내지 말고, LLM이 대화에 필요한 1~2개의 문서만 임팩트 있게 찾게 하자.
비교는 세 축으로 했습니다.
- 토큰 효율: 한 번의 질의에 LLM이 소비하는 토큰
- 컨텍스트 누락: 본문에 답이 있는데 못 찾는 경우 (recall)
- 잘못된 참조: 무관한 문서가 끼어드는 경우 (precision)
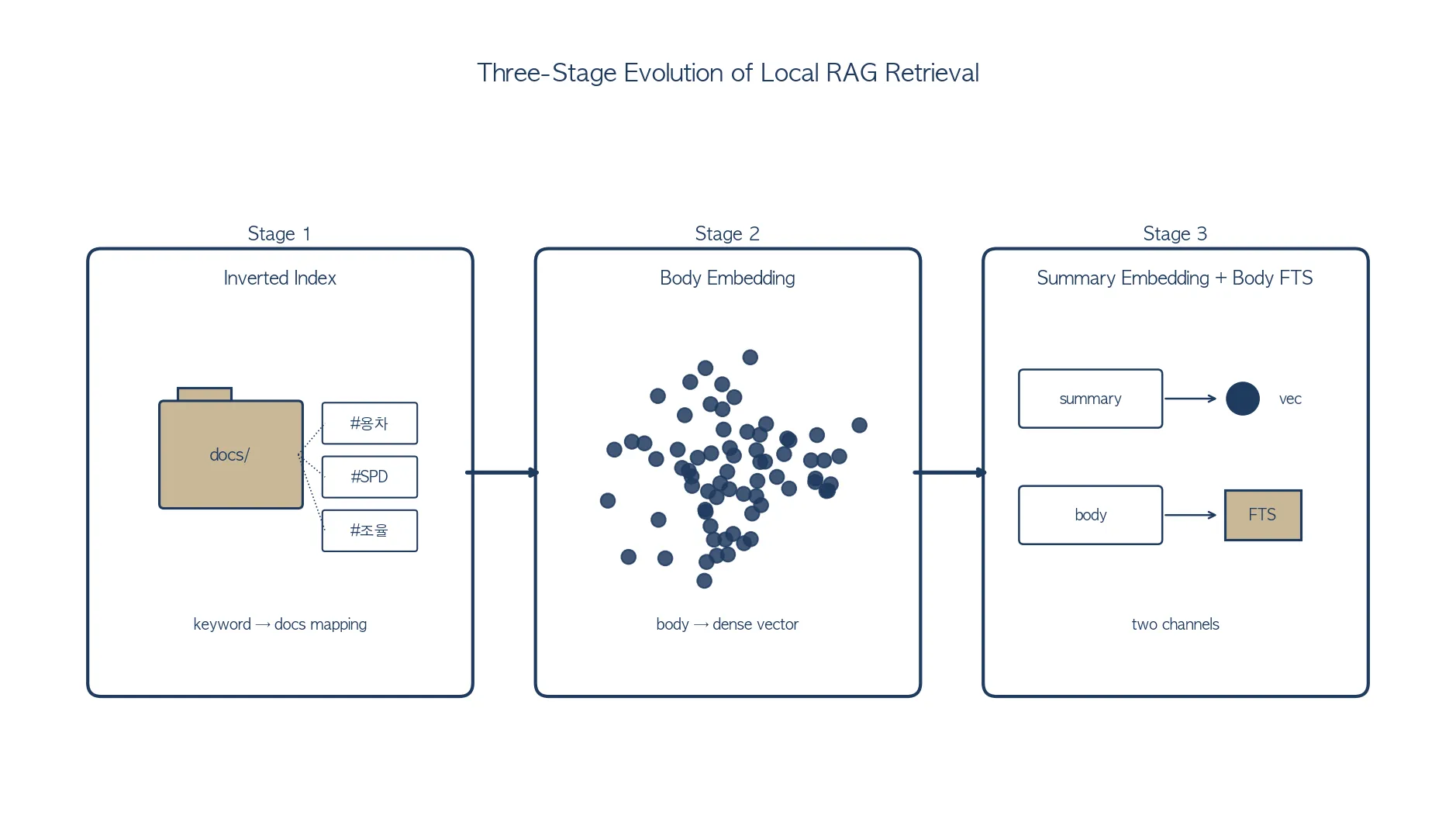
1단계: Inverted Index — 색인 유지가 룰인 구조
처음 만든 구조는 검색엔진 시뮬레이션에 가까웠습니다.
knowledge/
├── domains/{slug}.md # 운영 중 도메인 지식
├── tasks/{slug}.md # 진행 중 과제
└── indexes/
├── hot/{prefix}.md # 30일 내 3회 이상 참조
└── cold/{prefix}.md # 그 외indexes/hot/ㅅ-ㅊ.md 같은 prefix bucket(키워드 첫 글자별 분리 색인) 파일에 키워드 → 문서 매핑을 라인 단위로 두었습니다.
- **용차** 📖 → [domains/glossary.md#용차, domains/dispatch-policy.md]
- **샛별** → [domains/delivery-volume-pattern.md]문서마다 keywords: 메타데이터를 두고, 새 문서 생성 시 LLM이 해당 키워드를 어느 bucket에 끼울지 판단해 색인 라인을 직접 추가했습니다.
동작 흐름
"용차 비용 알려줘"
→ 키워드 "용차" 추출 → ㅅ-ㅊ.md grep
→ 매핑된 문서 2개 Read
→ 컨텍스트 반영실제 마주친 한계
며칠 운영해보니 누락·오참조 사례가 쌓이기 시작했습니다.
사례 1 — 동의어 누락: 사용자가 “새벽배송 지연”이라고 물어봤는데 결과 0건. 관련 문서들은 “샛별”로 색인되어 있었습니다. 색인을 LLM이 직접 작성하는데, 학습 데이터에 없는 도메인 동의어(“샛별 = 새벽배송 브랜드명”)를 LLM이 알 길이 없습니다. 그래서 새 문서를 만들 때 keywords: ["샛별"]만 적고 "새벽배송"은 빼먹습니다. 동의어 매핑은 결국 사용자가 색인 운영 룰을 따로 만들어 메우는 수밖에 없었습니다.
사례 2 — 키워드 매칭으로 인한 잘못된 참조: “용차(외부에서 임시로 임대하는 화물차) 비용 어떻게 산정해?”라고 물었을 때, “용차” 키워드를 가진 7개 문서가 한꺼번에 후보로 올라왔습니다. 답에 해당하는 비용 구조 문서는 그중 1개, 나머지 6개는 용차 운영 일정·계약 변경 이력·차량 등록 절차·신규 입사자 교육 자료·일자별 호출 통계·차종 정의 — 단어는 같지만 검색 의도와 전혀 무관했습니다. 키워드 정확 매칭은 의미 가중을 줄 수 없어서 단어가 같으면 다 끌고 옵니다. LLM은 7개를 모두 Read해 본문을 본 뒤 비용 구조 1개만 답에 반영하고 나머지는 버리는 과정을 거쳤습니다. 매 질의마다 의도와 무관한 6배의 토큰을 태우는 셈입니다.
세 축으로 정리하면:
- 토큰 효율 ❌: 매 질의마다 색인 파일 Read + 매핑된 문서 N개 Read. 색인 자체가 커질수록 비용 증가.
- 컨텍스트 누락 ❌: 사례 1처럼 LLM 색인이 동의어를 모름.
- 잘못된 참조 ❌: 사례 2처럼 키워드만 같으면 의미 무관해도 끌려옴.
운영을 해보니 결론이 명확해졌습니다. Inverted Index를 쓰는 한 색인 유지 자체가 부채이고, 키워드 정확 매칭은 의미 매칭과 다릅니다. 임베딩 쪽을 시도해보기로 했습니다.
2단계: 본문 임베딩 — 의미 매칭으로 전환
본문을 그대로 의미 벡터로 만들어 검색하는 단순한 구조로 갔습니다.
- 도구:
sqlite-vec(SQLite에서 벡터 검색을 가능하게 하는 확장) +multilingual-e5-small(다국어 의미 임베딩 모델, 384차원 벡터 생성) - 동작: 본문 + 키워드 + 별칭을 합쳐
"passage: "프리픽스와 함께 임베딩, 단일 SQLite 파일에 적재
왜 이 조합? sqlite-vec은 단일 SQLite 파일이라 PC를 바꾸거나 다른 환경으로 옮길 때 그대로 복사하면 끝입니다. multilingual-e5-small은 로컬에서 돌아 추가 비용이 들지 않고, 작은 모델치고 한국어 성능도 무리 없는 수준이었습니다.
def passage_text(doc):
return f"별칭: {doc['aliases']}\n키워드: {doc['keywords']}\n\n{doc['body']}"
vec = model.encode("passage: " + passage_text(doc), normalize_embeddings=True)검색은 의미 유사도 top 5만 반환.
결과
자연어 질의 “조율시에 어떤 지표 수집해야 해?”에 정답 문서가 1위로 잡혔습니다. Inverted Index 시절 “조율 + 지표”를 따로 grep해서 교집합을 구하던 것과 비교해 한 호출로 끝납니다. 동의어(“새벽배송”으로 검색해도 “샛별” 문서가 의미상 가까워 매칭됨)도 자연 해결.
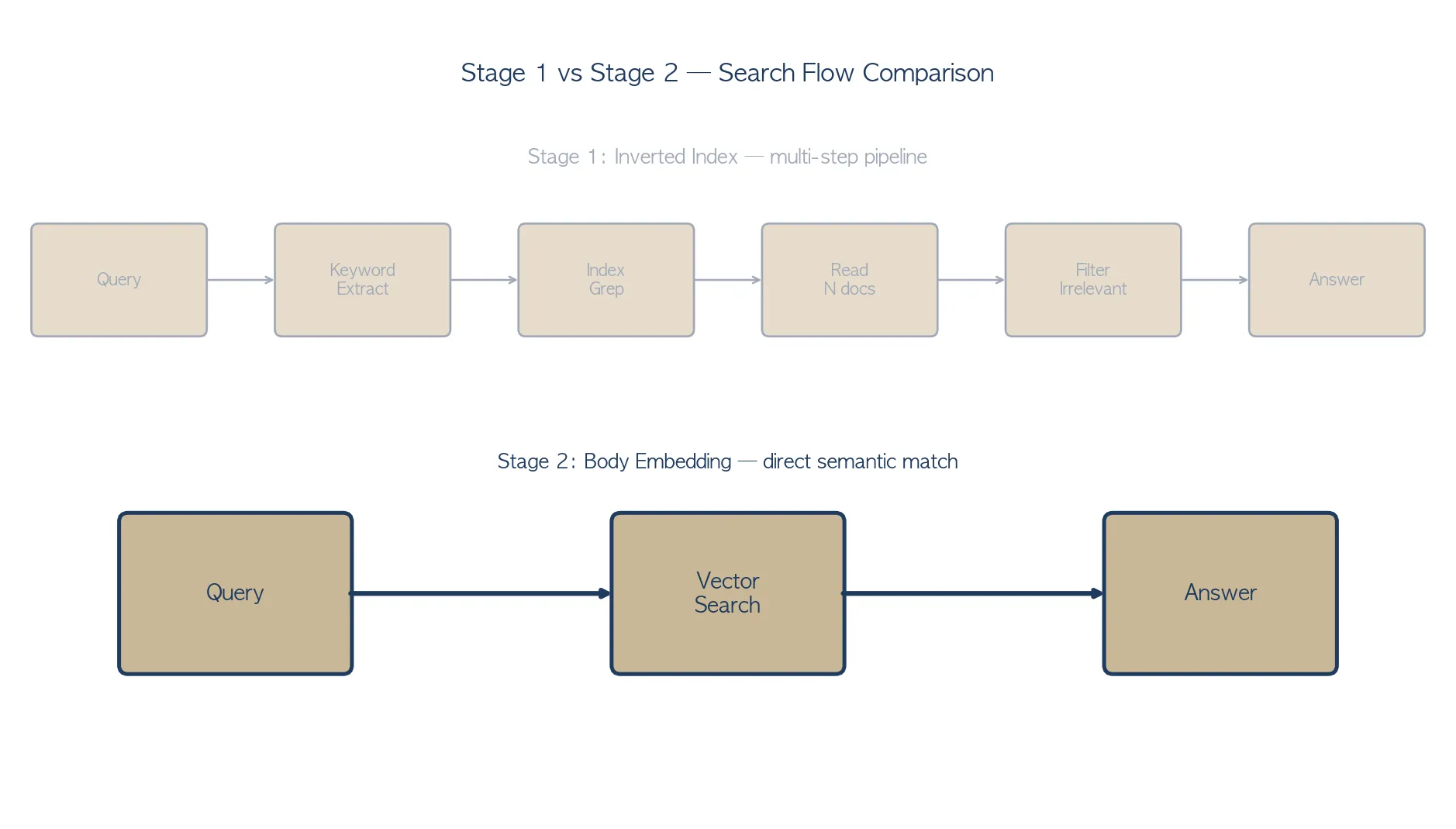
한계 — 측정 후 발견된 두 가지 문제
처음엔 잘 동작하는 줄 알았습니다. 그런데 100개 문서의 본문 토큰 수를 재보면서 두 가지 문제와, 하나의 의외의 발견이 나왔습니다. 문제부터 보겠습니다.
문제 ① — 의미 평균화 + 일반어 노이즈
한 문서에 여러 주제(정의 + 정책 + API 스펙)가 섞이면 벡터가 잡식성이 됩니다.
- “컨티 정책” 검색에 무관한
delivery-center-schedule.md(배송센터 예약 설정 정책)가 의미 매칭 3위에 떴습니다. “정책”이라는 일반어가 임베딩 의미를 끌어옵니다. - 다주제 문서는 특정 검색에 강하게 매칭되지 않고 어떤 검색에도 어중간하게 매칭됩니다.
문제 ② — 약어·식별자 검색에 약함
임베딩 모델은 학습 데이터에 거의 등장하지 않은 토큰(사내 약어·ID 등)에 대해 의미 시그널을 만들지 못합니다. 정확히는, 모델의 subword 토크나이저(단어를 더 작은 조각들로 쪼개는 방식)가 모르는 단어를 잘게 쪼개긴 하지만, 그 조각들의 의미가 주변 문맥에 평균화돼 묻혀버립니다. 결과적으로 사내 약어(DOS-bot, KLS)나 티켓 ID(TICKET-1234) 같은 식별자는 본문에 등장해도 의미 매칭 점수가 거의 올라가지 않습니다. 사실 식별자 매칭은 의미 매칭과는 본질이 다른 작업이라, 임베딩에 기대한 것 자체가 무리였습니다.
그리고 한 가지 발견 — 사실은 본문이 아니라 요약을 임베딩하고 있었다
같은 측정에서 부수적으로 따라온 발견인데, 이게 3단계 발상의 핵심 전제가 됩니다.
임베딩 모델 multilingual-e5-small은 한 번에 처리할 수 있는 입력이 512 토큰까지입니다. 이걸 넘으면 뒷부분이 잘려서 임베딩에 반영되지 않습니다(이걸 truncation이라 부릅니다). 우리 문서의 분포는 이랬습니다.
가장 긴 문서: 7,396 토큰 (multilingual-e5-small 토크나이저 기준)
→ 본문의 약 93%가 임베딩에 반영 안 됨
512 토큰 초과 문서: 약 85%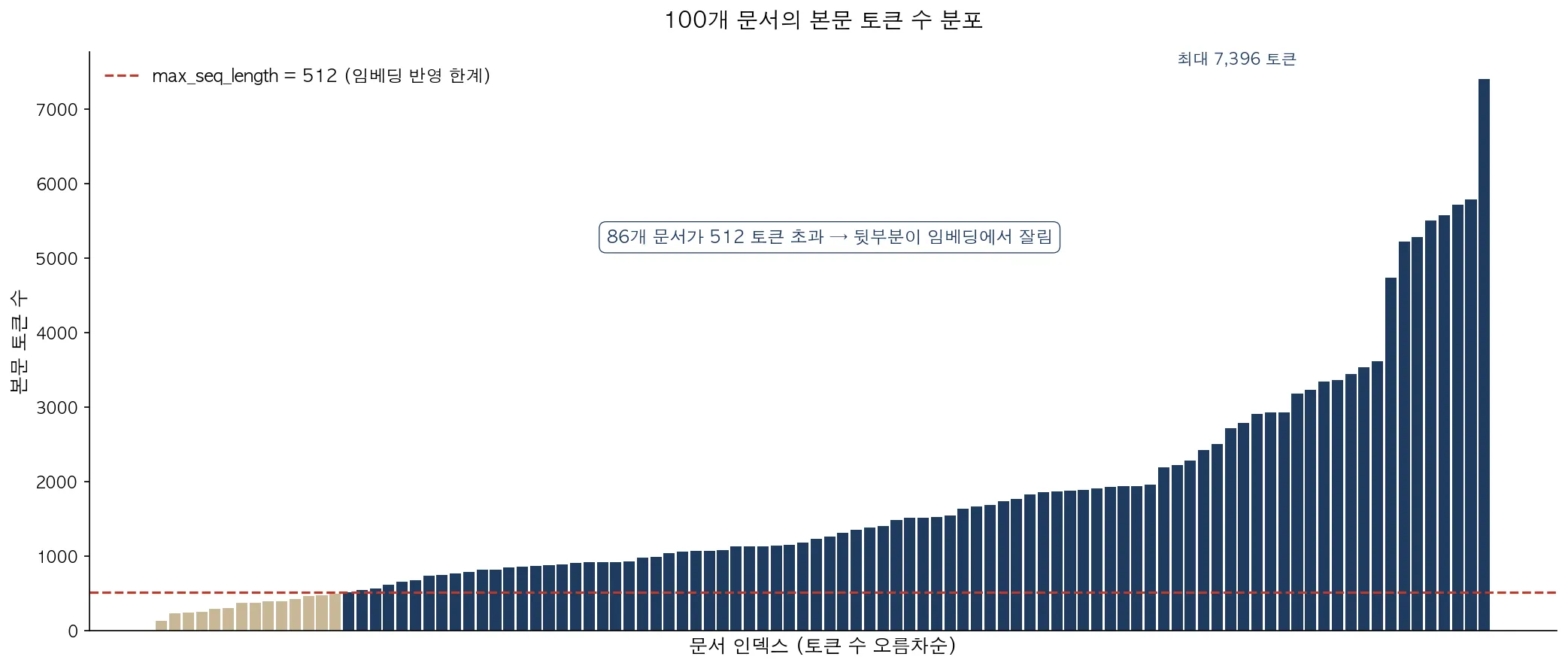
한국어는 토큰 효율이 영문보다 낮아서, 약 900자 이상의 문서는 모두 뒷부분이 잘립니다. 그런데도 검색이 잘 동작하고 있었습니다. 카파시 LLM Wiki 방식을 따라 모든 문서를 ## 요약 → ## 본문 구조로 정리한 덕분이었습니다. 잘리지 않는 앞 512 토큰 안에 요약이 들어가 있어, 의미 매칭은 사실상 그 요약을 보고 동작했던 셈이죠. “본문 임베딩”이라는 이름이 무색하게요.
이 발견과 두 문제를 종합하면 — 의미 매칭은 짧고 단일한 요약으로 충분하고, 본문은 키워드 검색용으로 따로 활용하는 쪽이 더 적절해 보였습니다.
3단계: 요약 임베딩 + 본문 키워드 검색 분업
위 두 문제를 풀기 위해 두 가지를 함께 적용했습니다.
- 다주제 문서는 주제별로 분리·재저장 — 한 문서 = 한 주제 원칙. 평균화의 근본 처방이 됩니다. (문제 ① 해결)
- 두 채널 분업 — 의미 매칭은 짧고 단일한 요약본 임베딩, 약어·식별자 같은 정확 매칭은 본문 전체에 대한 FTS5 키워드 검색. (문제 ② 해결, 의미 벡터는 별도 채널로 깔끔하게 분리)
도구도 두 개로 분리했습니다.
- 의미 매칭:
multilingual-e5-small+sqlite-vec(변경 없음) - 키워드 매칭: SQLite FTS5(SQLite 내장 풀텍스트 검색 모듈). 랭킹은 BM25(단어 빈도와 문서 길이를 함께 보는 키워드 가중 알고리즘). 본문을 잘림 없이 통째로 인덱싱
새 문서를 저장할 때 LLM이 본문을 보고 한 줄 요약을 만들어 메타데이터에 박고, 사용자가 한 번 검토하는 흐름으로 바꿨습니다.
summary: "용차 배차 운영 정책 — 권역별 우선 배정 기준과 조율 시점 정의. 권역 변경 시 SPD 영향 추적 절차 포함."
keywords: [용차, 권역, SPD, 조율, 배차]
aliases: [외주차량]
{본문 — 임베딩 대상 아님, FTS5와 미리보기에만 사용}임베딩 입력은 요약 + 별칭 + 키워드 약 100~200 토큰. truncation 영역 완전 탈출.
검색은 의미 매칭 top 3 + 키워드 매칭 top 2를 합치고 중복 제거, 의미 매칭 순위 우선으로 정렬. 결과 응답에 summary가 같이 나와서 LLM이 본문 Read 없이 1차 판단합니다.
{
"path": "tasks/dispatch-coordination-indicator.md",
"channels": {"vec_rank": 1},
"summary": "당일 배차 조율을 위한 물량·인원·SPD·용차 현황을 단일 화면에 통합.",
"snippet": "..."
}효과
- Truncation (잠재 위험): wiki 요약 덕에 우회하던 위험을, 이제는 요약본 자체를 임베딩 입력으로 명시해 구조적으로 차단했습니다. summary는 100~200 토큰뿐이라 임베딩에 100% 반영됩니다.
- 문제 ① (평균화): 한 문서 = 한 요약 = 한 의도 → 단일 주제 벡터. 다주제 문서를 쪼갰기 때문에 “정책” 같은 일반어 노이즈가 의미 매칭 1·2위에서 사라졌습니다.
- 문제 ② (약어 검색):
TICKET-1234,DOS-bot같은 식별자가 FTS5로 정확 매칭됩니다. 임베딩 모델로는 불가능하던 검색이 가능해진 것입니다.
세 단계 비교
| 축 | 1단계 (Inverted Index) | 2단계 (본문 임베딩) | 3단계 (요약 임베딩 + 본문 FTS) |
|---|---|---|---|
| 토큰 효율 | 2~4번 도구 호출 | 1~2번 호출 | 1~2번 + summary 메타로 Read 1회 절감 가능 |
| 컨텍스트 누락 | 동의어 색인 누락 (사례 1) | 평균화로 어중간 매칭 (truncation은 wiki 구조로 우회) | 평균화 해소 + truncation 구조적 차단 |
| 잘못된 참조 | 키워드 매칭 한계 (사례 2) | 일반어 노이즈 (문제 ①) | 약어 정확 매칭은 FTS5가, 일반어 노이즈만 일부 잔존 |
| 약어·식별자 검색 | 됨 (정확 매칭) | 거의 안 됨 (문제 ②) | 됨 (FTS5) |
| 운영 부담 | 색인 수동 갱신 | wiki 요약 헤딩 필수 | wiki 요약 + 다주제 분리 + 두 채널 |
회고
세 단계는 의미 추상화를 어디서 만들 것인가가 달랐습니다.
- 1단계: 별도 색인 파일에서 추상화. 본문과 색인이 분리되어 동기화 부채가 누적. 의미 가중도 없음.
- 2단계: 본문에서 모델이 직접 추상화. 동기화 부채는 없지만 모델 한계와 본문 다주제성에 부딪힘. 약어는 별도 도구 필요.
- 3단계: 다주제 문서를 분리하고, 메타데이터에 LLM이 한 줄 요약을 쓰고 사람이 검토 + 약어는 FTS5 별도 채널. 의미 매칭 입력은 좁고 명확하게, 본문은 키워드 검색용으로 따로 활용.
남은 한계와 다음 개선
여전히 풀지 못한 두 가지가 있습니다.
- 일반어 노이즈 일부 잔존 — “컨티 정책” 검색에 “예약 설정 정책”이 약하게 끼는 현상은 임베딩 본질의 한계라 완전히 사라지지 않습니다. 다만 1위 매칭은 또렷해서 실용상 영향은 크지 않습니다.
- summary 품질 편차 — LLM이 새 문서 저장 시 summary를 정성껏 작성하도록 스킬에 명시했고 사용자 검토 단계도 두었지만, 작성 LLM·세션에 따라 품질 편차가 남습니다.
다음 개선 후보는 ① 검색 빈도가 높은 문서의 헤딩 단위 청킹, ② 더 큰 max_seq_length를 가진 임베딩 모델로 업그레이드, ③ 약어·식별자 패턴이 들어간 질의의 가중치 동적 조정, ④ summary 품질 자동 평가 루프입니다.
돌이켜 보면 두 번의 갈아엎기는 시스템을 정교하게 만든 게 아니라, 무엇을 모델에 맡기고 무엇을 사람·다른 도구에 분담할지 선을 옮긴 작업이었습니다. 1단계는 색인 추상화를 사람이 다 했고, 2단계는 임베딩 모델에 떠넘겼고, 3단계는 한 줄 요약을 LLM이 쓰고 사람이 검토하며 약어 검색은 FTS5에 분리했습니다. 같은 분업 원칙은 100개가 1000개가 되어도, 도메인이 바뀌어도 유효할 거라 봅니다. 다음 100개가 쌓일 때 또 어디서 선을 옮기게 될지 — 솔직히 그게 가장 궁금한 지점입니다.
맺으며
“AI에게 도메인을 가르친다”는 표현으로 시작했지만, 결국 한 달간 한 일은 AI가 알아듣기 좋은 형태로 우리 지식을 다시 정리한 것에 가까웠습니다. 가르치는 쪽이 더 많이 배우는 작업이었던 셈이죠. 시니어 AI는 아직 멀었지만, 그 과정에서 우리 도메인이 어디서 모호한지 — 동의어가 어디 흩어져 있는지, 어떤 문서가 다주제로 비대해져 있는지 — 가 같이 드러났습니다. 어쩌면 이게 더 큰 수확일지도 모르겠습니다.
읽어주셔서 감사합니다.