Created by OpenAI DALL-E
안녕하세요. 컬리 데이터 플랫폼팀에서 머신러닝 엔지니어로 일하고 있는 구국원입니다. Kurly만의 MLOps 구축하기 - 초석 다지기에 이어서 또 다른 MLOps 구축기를 소개하고자 합니다. 제가 속한 데이터 플랫폼팀에는 모델을 연구하고 실험하는 데이터 사이언티스트 분들이 많이 계십니다. 그리고 최근 들어 여러가지 머신러닝 모델을 실험하고 서빙하고자 하는 수요가 증가하고 있는 상황입니다. 이런 상황 속에서 데이터 사이언티스트가 인프라는 최대한 신경쓰지 않고 오로지 데이터를 들여다보고 실험하고 모델링을 할 수 있는 추상화된 환경을 구성하는 일이 중요한 과제로 떠올랐습니다. 그 과정에서 어떤 도구를 활용하여 이러한 환경을 구축할지가 고민이었는데요, 컬리의 데이터 플랫폼팀은 어떤 선택을 했을까요? 지금부터 그 여정을 함께 살펴보시고 유용한 팁 몇 가지를 챙겨가시길 바랍니다. 🙏
어떤 툴/서비스를 선택할까?
컬리는 데이터를 기반으로 여러 모델을 실험하고 적용하려는 노력을 기울이고 있습니다. 그리고 이를 위한 인프라도 어느 정도 구축이 되어 있었습니다. 예를 들어서 Jupyterhub, MLFlow, Airflow 등의 오픈 소스 도구를 EKS 클러스터에 배포하여 활용하고 있었습니다. 그러나 이런 저런 툴을 하나둘씩 추가하면서 데이터 사이언티스트가 신경 써야 할 것들이 많아지고 있었고, 여러 툴들 간에 유기적인 연결성이 낮다보니 해당 툴들을 사용하는데에 따른 복잡성이 증가하고 있는 상황이었습니다. 컬리의 머신러닝 엔지니어와 데이터 엔지니어들은 이러한 현상을 개선하기 위해 추상화된 형태의 MLOps 플랫폼을 제공하고 싶었습니다. 직접 플랫폼을 만드는 것도 검토를 했었지만, 빠르게 성장하고 있는 컬리의 상황에서는 잘 패키징된 MLOps 서비스를 선택하여 신속하게 도입하는 것이 더 시의적절하다고 판단했습니다. 그리고 최종적으로 AWS 세이지 메이커와 쿠브플로우, 두 가지 중에서 하나를 채택하기로 했습니다.
쿠브플로우(Kubeflow)란?
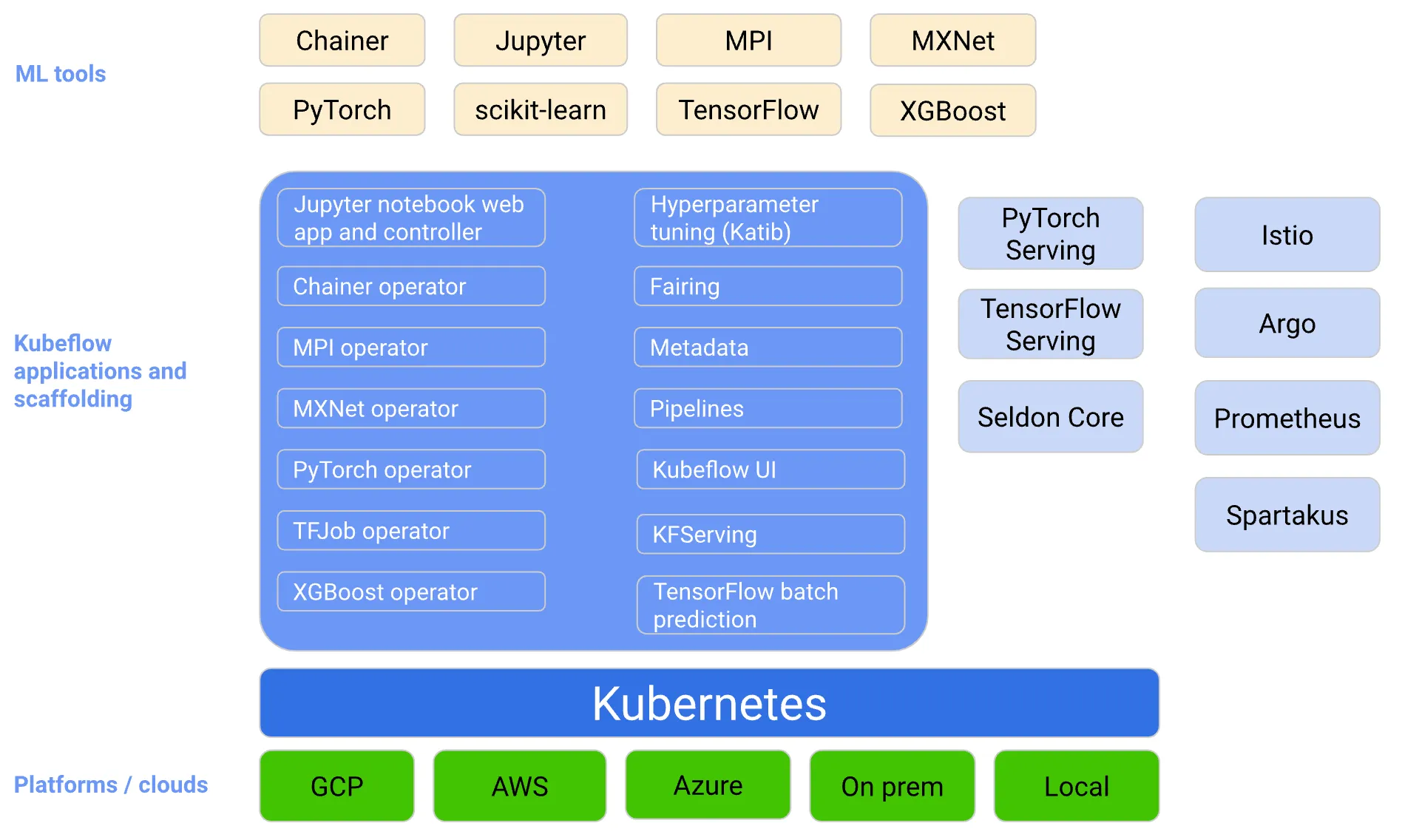 출처: Kubeflow Conceptual Overview
출처: Kubeflow Conceptual Overview
‘쿠브플로우(Kebeflow, https://www.kubeflow.org/)‘는 ‘쿠버네티스 위에서 머신러닝을 위한 다양한 오픈 소스들을 종합적으로 관리하고 운영을 하는데 도움을 주는 프로젝트’입니다(The Kubeflow project is dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable). 쿠브플로우는 다음의 3가지 원칙(principles)에 따라 설계되었습니다.
- composability: 머신러닝 워크플로우의 컴포넌트들을 프로젝트의 요구 조건(버전, 라이브러리 등)에 따라 구성할 수 있습니다.
- portability: 로컬, 온프레미스, 클라우드 등 다양한 환경에 배포할 수 있습니다.
- scalability: 쿠버네티스의 기능을 활용하여 CPU, GPU, TPU 등의 자원을 확장하거나 축소하여 사용할 수 있습니다.
쿠브플로우는 머신러닝 라이프사이클의 각 단계를 담당하는 컴포넌트들로 구성되어 있으며, 서드 파티 오픈 소스 툴과 자연스럽게 통합됩니다.
| Kubeflow Component | External Add-Ons | |
|---|---|---|
| 대시보드 | Central Dashboard | - |
| 실험 및 학습 | Kubeflow Noteoobk | - |
| 하이퍼파라미터 튜닝 | Katib | - |
| 워크플로우 | Kubeflow Pipelines | Elrya, Kale |
| 학습 모니터링 | Tensorboard | - |
| 서빙 | - | KServe, BentoML |
| 피쳐스토어 | - | Feast |
세이지 메이커(SageMaker)와의 비교
컬리는 ‘세이지 메이커(Amazon SageMaker, https://aws.amazon.com/ko/pm/sagemaker/)‘를 제한적으로 활용하고 있었습니다. 주로 노트북 인스턴스를 통해서 실험과 모델링을 진행하고 있었죠. 따라서 쿠브플로우가 세이지메이커를 대체할 수 있을지, 서로 어떤 장단점이 있는지를 조사해볼 필요성이 있었습니다. 먼저 두 가지 서비스는 모두 머신러닝 라이프 사이클을 통합하는 MLOps 플랫폼 서비스라는 점에서 공통점이 있습니다. 각 서비스에서 제공하는 머신러닝 라이프 사이클 컴포넌트들은 다음과 같습니다.
| 세이지 메이커(SageMaker) | 쿠브플로우(Kubeflow) | |
|---|---|---|
| 데이터 라벨링 | Ground Truth | - |
| 전처리 | Data Wrangler | - |
| 실험 및 학습 | Studio Notebooks & Notebook Instances | Kubeflow Noteoobk |
| 하이퍼파라미터 튜닝 | Automatic Model Tuning | Katib |
| 워크플로우 | SageMaker Pipelines | Kubeflow Pipelines |
| 학습 모니터링 | Model Monitor | Tensorboard |
| 서빙 | Endpoints | KServe, BentoML |
| 피쳐스토어 | Feature Store | Feast |
그리고 각 서비스들의 공식 문서나 사용 사례를 참고하여 쿠브플로우와 세이지메이커의 장단점을 정리해 보았습니다.
| 세이지 메이커 | 쿠브플로우 | |
|---|---|---|
| 장점 | - AWS 리소스들과 자연스럽게 통합되므로 관련 인프라 설정이 편리합니다. - 쿠브플로우에서 아직 지원하지 않는 컴포넌트들도 통합된 환경에서 제공하고 있습니다. | - 이식성(portabiltiy)이 높습니다. 쿠버네티스가 설치되어 있는 어느 환경이든지(AWS, GCP, on-prem 등) 배포가 가능합니다. - 컬리에서는 이미 쿠버네티스를 적극 활용하고 있기 때문에 쿠버네티스를 구성하기 위한 인프라 구성을 하지 않아도 됩니다. |
| 단점 | - AWS 리소스들과 연계되다보니 벤더 락인(vendor lock-in) 가능성이 높습니다. - 비용도 저렴한 편은 아닙니다. | - 환경 구성을 할 때 참고할만한 레퍼런스가 적습니다. 또한 쿠브플로우가 채택한 오픈 소스가 많다보니 디버깅시 어려움이 따를 가능성이 높습니다. |
최종 결정
세이지 메이커는 fully-managed 서비스답게 쿠브플로우에 비해 머신러닝 라이프 사이클의 더 큰 영역을 커버할 수 있었습니다. 그러나 비용 문제와 함께 기술 내재화 측면에서 그리 좋은 방안은 아니라는 판단을 하였습니다. 반면 컬리 데이터플랫폼팀에서는 쿠버네티스를 적극 활용하고 있는 상황이었고 쿠브플로우가 커버하지 못하는 머신러닝 라이프 사이클 영역은 직접 개발하거나 다른 오픈 소스 툴을 활용하여 충분히 극복 가능할 것이라고 판단 했습니다. 따라서 컬리 데이터플랫폼팀은 쿠브플로우를 활용하여 MLOps 플랫폼을 발전시켜나가기로 결정하였습니다.
쿠브플로우를 좀 더 세심하게 설정하기
쿠브플로우 깃헙에서 안내하는 방식으로 설치를 했을 경우에, 이를 곧바로 운영 환경에 사용하기에는 부족한 점들이 많이 있습니다. 그러나 쿠브플로우를 운영하기 편리한 형태로 커스텀하는 것과 관련된 레퍼런스는 많이 없는 것 같습니다. 따라서 컬리에서 쿠브플로우 초기 셋팅시 적용 했던 내용들을 간단하게 공유 드리고자 합니다. 먼저 설치 환경은 다음과 같습니다.
- Kubernetes version: 1.21
- Kubeflow version: 1.5.0
- Kustomize version: 3.2.0
Elyra와 Container Images
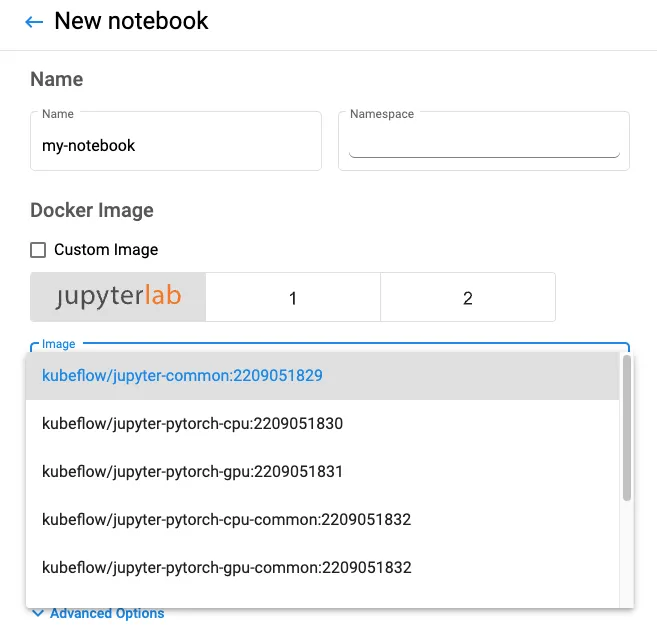
쿠브플로우에는 머신러닝 워크플로우를 생성하고 관리하는 ‘쿠브플로우 Pipeline(이하 KFP)‘이라는 컴포넌트가 있습니다. 그러나 KFP에서 DAG를 만들기 위해서는 문법을 새로 익혀야하는 불편함이 존재하였습니다. 따라서 데이터사이언티스트 분들이 신경 써야 하는 범위가 지나치게 늘어나는 것을 경계하고, 추상화된 형태로 DAG를 만들 수 있는 방안을 고민하다가 Elyra를 도입하게 되었습니다. Elyra는 주피터랩의 UI 상에서 작성한 파이썬 파일, 노트북 파일들의 dependency를 설정하고 이를 KFP DAG로 쉽게 변환 시켜주는 툴입니다. 참고로 Kale도 검토 해보았지만 아직 덜 성숙한 오픈 소스라고 판단했습니다.
쿠브플로우 설치시 기본적으로 제공하는 도커 이미지에는 Elyra가 설치되어 있지 않습니다. 따라서 저희는 쿠브플로우 공식 문서와 깃헙 레포지토리를 참고하여 Elyra 익스텐션이 설치된 주피터랩 이미지를 생성하고 이를 ECR에서 관리하고 있습니다. 그리고 쿠브플로우 노트북을 생성할 때 해당 이미지를 쉽게 사용할 수 있도록 드롭다운 메뉴로 만들어서 제공하고 있습니다. 드롭다운 메뉴는 쿠브플로우 매니패스트 레포지토리를 기준으로 apps/jupyter/jupyter-web-app/upstream/base/configs/spawner_ui_config.yaml 파일을 수정하고 주피터 노트북을 재배포 하면 됩니다.
kustomize build apps/jupyter/jupyter-web-app/upstream/overlays/istio | kubectl apply -f -
# serviceaccount/jupyter-web-app-service-account unchanged
# role.rbac.authorization.k8s.io/jupyter-web-app-jupyter-notebook-role unchanged
# clusterrole.rbac.authorization.k8s.io/jupyter-web-app-cluster-role unchanged
# clusterrole.rbac.authorization.k8s.io/jupyter-web-app-kubeflow-notebook-ui-admin configured
# clusterrole.rbac.authorization.k8s.io/jupyter-web-app-kubeflow-notebook-ui-edit unchanged
# clusterrole.rbac.authorization.k8s.io/jupyter-web-app-kubeflow-notebook-ui-view unchanged
# rolebinding.rbac.authorization.k8s.io/jupyter-web-app-jupyter-notebook-role-binding unchanged
# clusterrolebinding.rbac.authorization.k8s.io/jupyter-web-app-cluster-role-binding unchanged
# configmap/jupyter-web-app-config-df6d7fc46b created
# configmap/jupyter-web-app-logos unchanged
# configmap/jupyter-web-app-parameters-h7dbhff8cb unchanged
# service/jupyter-web-app-service unchanged
# deployment.apps/jupyter-web-app-deployment configured
# virtualservice.networking.istio.io/jupyter-web-app-jupyter-web-app unchangedKFP의 기본 저장소를 S3로 변경하고 IRSA 적용
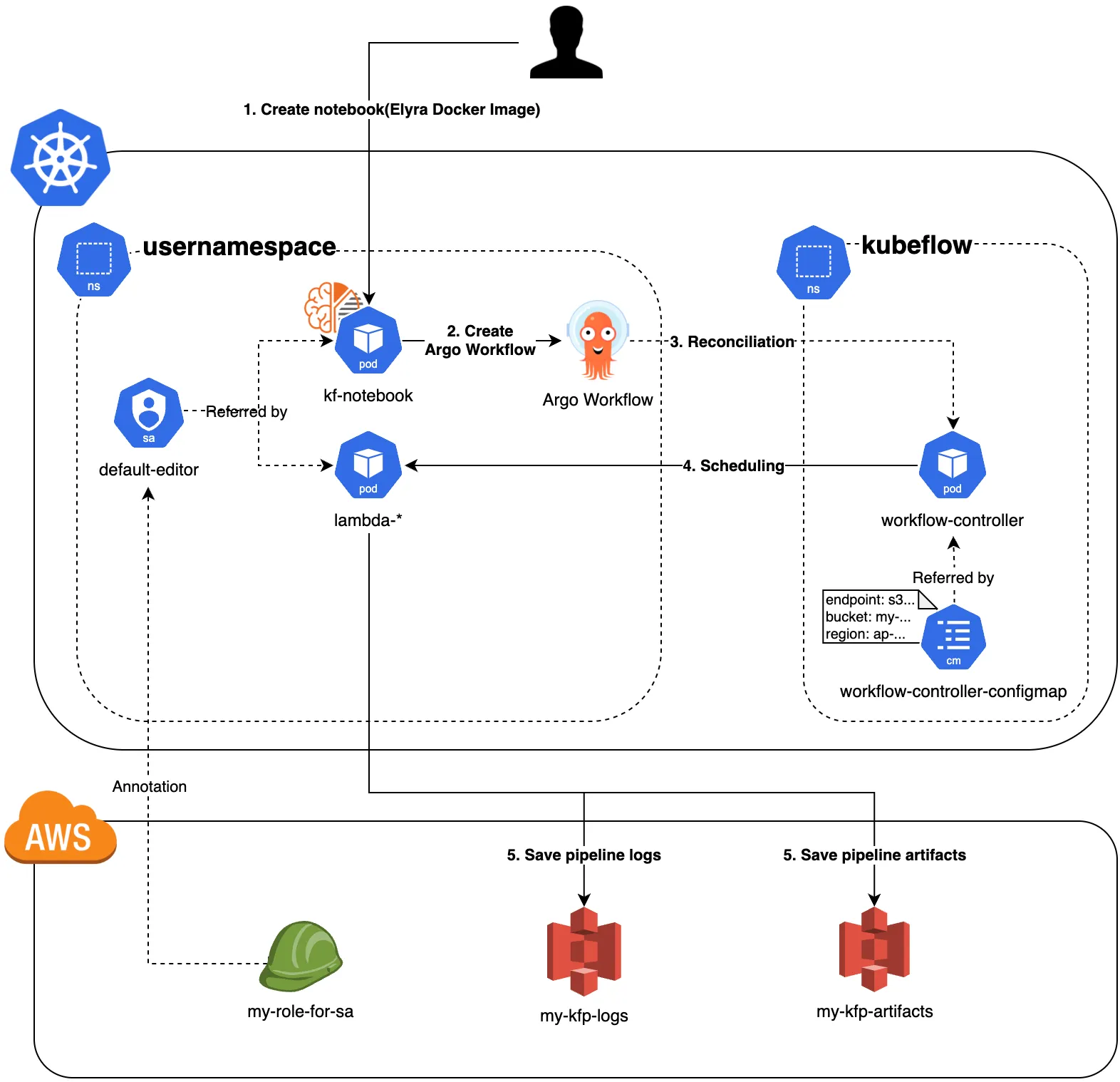
쿠브플로우는 기본적으로 artifact 저장소로 MinIO로 사용합니다. MinIO는 AWS S3 api와 호환되는 오브젝트 스토리지로서 PV(EBS 볼륨)로 생성됩니다. 그러나 머신러닝에 사용되는 raw 데이터는 대용량일 경우가 많으며, 가변적일 수도 있기 때문에 데이터에 대한 접근성이나 확장성 측면에서 EBS 볼륨보다는 S3를 기본 저장소로 활용하는 것이 낫겠다는 판단을 하였습니다.
KFP는 Argo Workflow로 동작하기 때문에 KFP의 기본 저장소를 변경하기 위해서는 Argo Workflow 관련 설정을 살펴 봐야합니다. 쿠브플로우를 배포하면 쿠버네티스 클러스터 내에 workflow-controller-configmap이 생성됩니다. 이 ConfigMap은 Argo Workflow의 전반적인 설정 정보가 담겨 있습니다. 각 필드의 자세한 설명은 여기의 주석들을 주의 깊게 보시면 됩니다. artifact 저장소 변경과 관련된 부분만 발췌하면 아래와 같은 형태입니다.
apiVersion: v1
data:
artifactRepository: |
archiveLogs: true
s3:
...
endpoint: "s3.amazonaws.com" # for S3
bucket: "my-bucket" # bucket name
region: "ap-northeast-2" # region
useSDKCreds: true # If you are using IRSA on AWS, and set this option to true그러나 이렇게만 설정한다고 해서 S3와 통신이 이루어지지는 않습니다. 파드가 S3와 통신하기 위해서는 aws credential 정보를 파드에 주입시키는 과정이 반드시 필요합니다. 가장 간단한 방법은 Secret에 aws access key id와 secret access key를 명시 해 놓고 파드가 해당 Secret을 마운트 하도록 설정하면됩니다. 그러나 컬리의 쿠브플로우는 multi-tenancy 방식으로 셋팅되어 있어서 namespaced resoucre인 Secret을 활용할 경우 유저의 네임스페이스마다 Secret을 만들어 주어야 하는 불편함이 존재합니다. 따라서 저희는 IRSA을 통해 임시 보안 자격 증명을 받아 S3와 통신하는 방식을 채택했습니다. 특별한 설정을 하지 않았다면 유저의 네임스페이스에 자동으로 생성되는 default-editor라는 서비스 어카운트에 IRSA 설정을 진행해주시면 됩니다. 필요한 부분만 발췌하면 서비스 어카운트는 다음과 같은 형태입니다.
apiVersion: v1
kind: ServiceAccount
metadata:
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::1234567890:role/example-role
name: default-editor
namespace: your-name-spaceSealedSecrets
쿠브플로우 매니패스트에는 다양한 credential 정보들이 있습니다. 예를 들어 컬리 쿠브플로우 대시보드는 컬리의 이메일로 접속이 가능하도록 설정되어 있습니다. 따라서 Dex의 매니패스트에 google client id와 client secret이 명시되어 있습니다. 한편 개발 환경에서는 로컬에서 매니패스트를 관리해도 되지만 운영 환경에서는 깃헙 레포지토리에서 매니패스트를 관리해야합니다. 만일 이러한 credential 정보를 그대로 레포지토리에 푸시한다면 해당 정보가 유출 되었을 때 심각한 보안 피해가 발생할 것입니다. 물론 일반적으로 회사에서는 private 레포지토리로 운영하지만 그럼에도 불구하고 credential 정보를 암호화 처리 없이 그대로 관리한다는 것은 그리 좋은 프랙티스가 아니라고 판단했습니다.
따라서 먼저 Dex의 ConfigMap을 Secret으로 변환하였고, 이 Secret을 안전하게 관리할 수 있는 방안을 리서치 해보았습니다. 여러 대안들(vault, external secret operator 등)이 있었지만 현재 상황하에서는 SealedSecrets가 가장 적절한 툴이라고 판단하고 이를 도입하게 되었습니다. SealedSecret는 쿠버네티스 클러스터에 배포되는 sealed-secrets-controller와 클라이언트 툴인 kubeseal로 이루어져있습니다. 사용자는 평상시와 같이 Secret을 생성한 후에 kubeseal을 이용하여 이를 SealedSecret이라는 CR(Custom Resource)로 변환합니다. SealedSecret은 암호화된 Secret 정보를 가지고 있습니다. 그리고 쿠버네티스 클러스터에 SealedSecret을 배포하면 sealed-secrets-controller가 이를 복호화하여 클러스터내에 Secret을 배포해줍니다. 따라서 사용자는 SealedSecret만 깃헙 레포지토리에 푸시하여 관리하면 됩니다. 암호화 되어 있기 때문에 유출되어도 문제가 발생할 여지가 적습니다.
# <꺽쇠>안의 값들은 적절하게 수정이 필요합니다.
kubeseal --controller-name=<your-controller-name> --controller-namespace=<your-namespace-of-controller> --format=yaml < <your-secret-file> > <your-sealedsecret-file>Secret 커밋 방지 팁!
마지막으로 생각해보야할 것은 실수로 SealedSecret과 함께 Secret을 깃헙 레포지토리에 푸시할 경우가 발생할 수도 있다는 것입니다. 따라서 git hook 중에서 pre-commit을 활용하여 실수로 Secret이 커밋되는 것을 방지하는 장치를 구성해 두었습니다. 아래는 pre-commit 깃훅의 예시입니다.
#!/bin/sh
DESTS="common/dex kurly"
PATTERN="kind:\s*Secret"
RESULT=0
for DEST in $DESTS; do
if git grep --untracked -E "kind:\s*Secret" $DEST; then
echo "There are secret in ${DEST}"
RESULT=$((RESULT || 1))
else
echo "There are not secret in ${DEST}"
RESULT=$((RESULT || 0))
fi
done
if [ "$RESULT" == 1 ]
then
echo "** commit is fail!! **"
echo "You should convert Secret to SealedSecret"
exit 1
else
echo "** commit is successful!! **"
exit 0
fi마치며
이번에 쿠브플로우를 도입하면서 새로운 개념과 기술을 많이 접하게 되었고, 어떻게 하면 데이터 사이언티스트가 쿠브플로우를 편하게 잘 사용할 수 있을지 사용자 입장에서 많이 고민했습니다. 그 과정에서 짧은 기간에 성장의 기쁨을 느낄 수 있는 소중한 경험을 했습니다. 아직 컬리의 쿠브플로우 기반의 MLOps 환경은 초기 단계입니다. GitOps를 통한 매니패스트 관리, katib을 활용한 하이퍼파라미터 튜닝, 서빙 아키텍처 정비 등 해볼만한 일은 끝이 없는 상황입니다. 차근차근 진행해서 데이터 사이언티스트가 마음껏 뛰놀수 있는 탄탄한 MLOps 환경을 구축하는 것이 최종 목표입니다. 긴 글 읽어주셔서 감사합니다.