지난 3월 1달 간, AI 토큰 사용 전사 1위가 되었습니다. 지난 53일 동안 AI와 148,000번 넘게 대화했습니다. 그 과정에서 하나 깨달은 게 있는데요. 생산성 차이는 AI를 ‘많이’ 쓰는 데서 오는 게 아니라, AI가 ‘어떻게’ 일하게 하느냐에서 온다는 것이었습니다. 이 글은 사내 발표를 기반으로, 발표에서 미처 못 다룬 배경과 상세내용을 담은 글입니다.
1편에서는 왜 개발자의 역할이 오케스트레이터로 옮겨가는지, 그리고 AI의 실패 패턴과 컨텍스트 품질에 대해 다룹니다. 구체적인 실행 방법(Task DAG, Branch Hunt, Ralph Loop)은 2편에서 소개합니다.
개발자에서 오케스트레이터로
어쩌다 보니 사내에서 AI 토큰을 제일 많이 사용해서, 저의 AI 사용 경험을 공유하는 발표 기회를 얻게되었습니다.
3월 한달 간 약 100억 토큰을 사용했습니다. 하지만 저는 AI를 많이 쓰는 것보다 잘 쓰는 것이 중요하다고 생각해요. 그래서 AI를 많이 쓴 것이 자랑은 아니지만, 그 과정에서 깨달은 것들을 업무 방식에 어떻게 잘 적용하고 있는지를 소개해드리려고 합니다.
발표에서 소개한 내용을 간략하게 설명하고, 실제로 제가 업무에 어떤 방식으로 AI를 적용했는지에 초점을 맞춰서 (왜 그렇게 토큰을 많이 썼는지?) 적어보고자 합니다.
53일 사용 기록
지난 53일 동안 사용한 AI 에이전트에 대해서 정량 지표를 추출해봤습니다.
| 지표 | 값 | 의미 |
|---|---|---|
| 직접 시작한 세션 | 940개 | 제가 의도한 작업 단위 |
| 파생된 서브에이전트 | 2,594개 | AI가 스스로 만든 실행 단위 |
| 직접 작성한 메시지 | 12,632개 | 제 실제 입력 |
| AI 생성 메시지 | 129,537개 | AI의 실행 결과 |
| 도구 호출 | 177,590회 | 코드 탐색, 브라우저 조작 등 |
| 제가 1번 입력하면 AI 행동 | ~10회 | 위임 효율 |
148,000번의 대화를 복기하면서 발견한 건 도구 사용법이 아니라 운영 원리였습니다.
근데 중요한 건 이 총량이 아니에요. 940개 세션에서 왜 2,594개의 서브에이전트가 파생됐을까? 하나의 작업이 여러 실행 단위로 쪼개졌다는 뜻입니다. 이 분해 구조가 오늘 이야기의 중심이에요.
제가 1번 입력하면 AI가 약 10번 행동합니다. 한 번의 지시가 탐색 → 분석 → 구현 → 검증으로 자동 전개되는 파이프라인이 깔려 있습니다.
AI 활용의 5단계
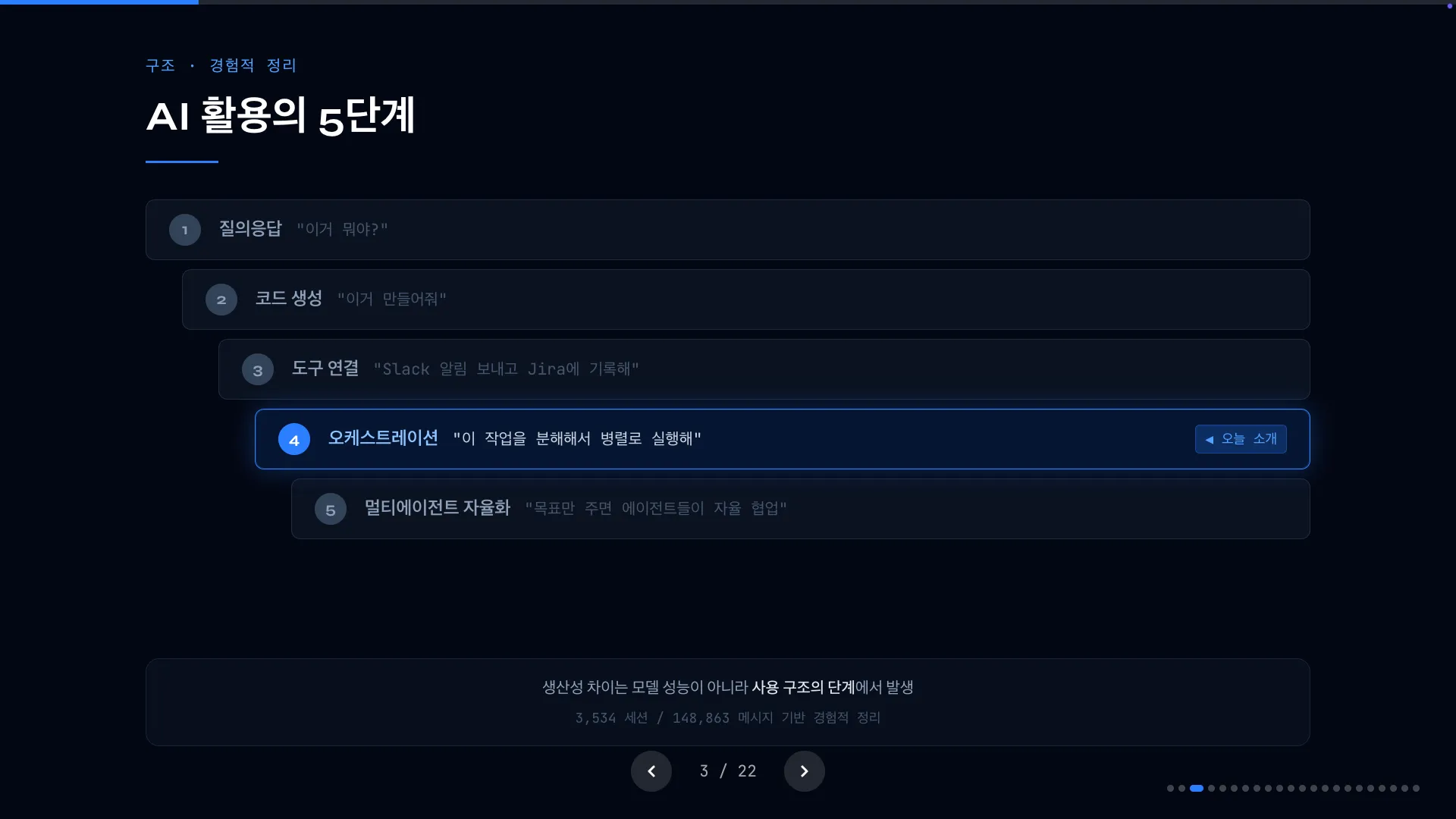
제가 생각하는 AI 활용 방법에 대해 단계를 나누어봤습니다.
- Level 1 — 질의응답: “이거 뭐야?” 가장 기본적인 질의 응답 방식의 사용입니다.
- Level 2 — 코드 생성: “이거 만들어줘.” 대부분의 AI 활용이 여기 머물러 있습니다.
- Level 3 — 도구 연결: “Slack 알림 보내고 Jira에 기록해.” AI한테 외부 시스템 조작을 시키기 시작하는 단계입니다.
- Level 4 — 오케스트레이션: “이 작업을 분해해서 병렬로 실행해.” 이 아티클에서 소개해드릴 내용입니다.
- Level 5 — 멀티에이전트 자율화: “목표만 주면 에이전트들이 알아서 협업.” 아직 연구 단계입니다.
생산성 차이는 모델 성능에서 오지 않아요. 이 단계 중 어디에 있느냐에서 온다고 생각해요.
같은 Claude, 같은 GPT를 쓰더라도 Level 2에 머무는 사람과 Level 4를 운용하는 사람의 결과물은 구조적으로 다르다는 것을 깨달았습니다.
역할의 변화
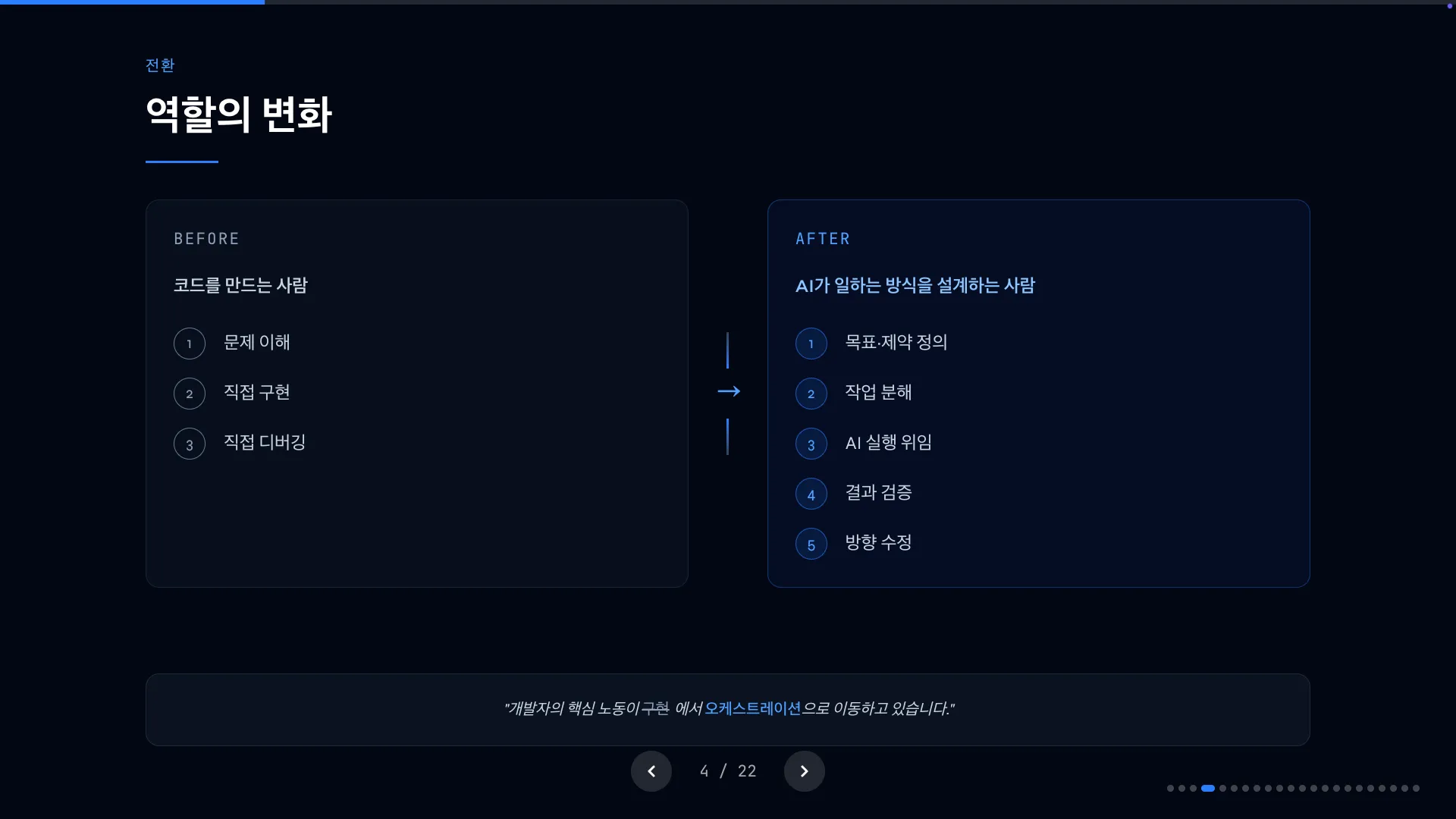
핵심 노동이 구현에서 분해·플래닝·검증으로 옮겨갔습니다.
53일 동안 제가 가장 많이 한 일은 코드를 쓰는 게아니라, 작업을 쪼개고, 계획을 세우고, 결과를 검증하는 일이었기 때문입니다.
처음부터 이렇게 써야겠다 의도한 건 아니었습니다. AI를 매일매일 다루다보니 자연스럽게 개발자로서의 역할이 옮겨갔어요.
처음에는 AI한테 코드를 생성시키고 직접 리뷰했는데, 어느 순간 뭘 어떤 순서로 만들 건지를 설계하는 데 대부분의 시간을 쓰고 있었습니다.
작업의 여섯 단계
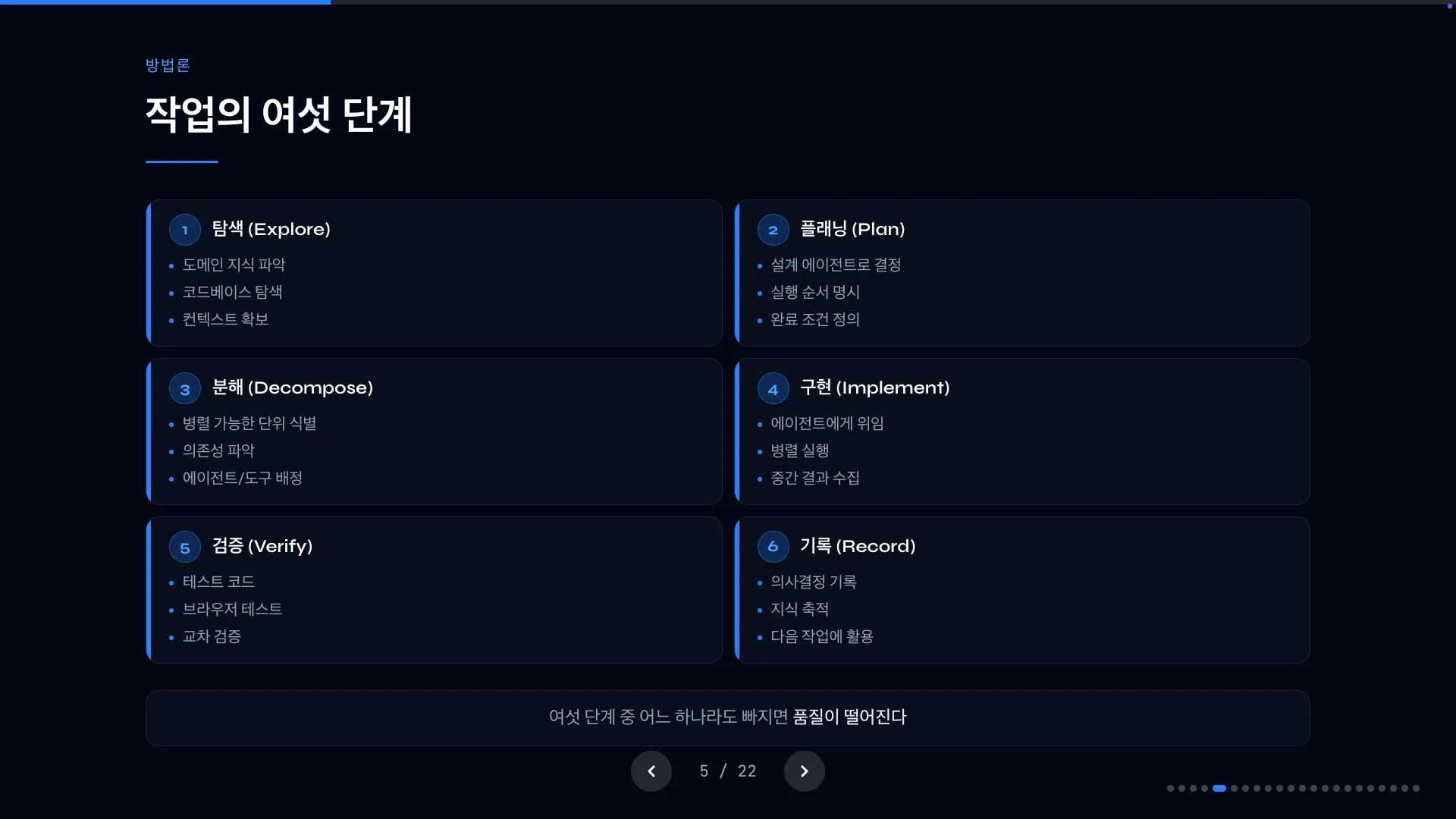
53일 간의 사용기록을 정리해보면서, 제가 AI와 함께 작업을 수행할 때의 단계를 나누어봤습니다. 정리해보고 나니, 거의 모든 작업에 대해서 하나도 빠짐없이 이 단계대로 수행하고 있다는 것을 알게 되었습니다.
저는 작업은 여섯 단계로 나눠서 진행합니다.
1. 탐색 (Explore)
6가지 단계 중에서 가장 중요한 단계입니다. 도메인 지식을 파악하고, 코드베이스를 탐색하고, 컨텍스트를 확보합니다. 이 단계가 전체 품질을 결정하는 출발점입니다.
2. 플래닝 (Plan)
설계 에이전트로 아키텍처를 결정하고, 실행 순서를 명시하고, 완료 조건을 정의합니다. 이 단계에서는 저의 노력이 가장 많이 들어가는 단계에요. 짧게는 30분에서 길게는 1-2시간동안 에이전트와 인터뷰를 진행하면서 심층 플래닝을 진행합니다.
심층 인터뷰 플래닝을 진행하면서, 미결정사항에 대해 파악하고, 자연스럽게 전체 아키텍처 구조를 머리 속에 넣고, 에이전트에게 상세한 지시를 담을 수 있습니다.
이 과정에서 얼마나 상세하게 플래닝을 진행했느냐가 작업 결과물 퀄리티에 큰 영향을 미칩니다.
3. 분해 (Decompose)
풍부한 컨텍스트와 상세한 플랜을 기반으로, 병렬 가능한 단위를 식별하고, 의존성을 파악하고, 각 단위에 맞는 에이전트와 도구를 배정합니다. 예를 들어 API 개발이라면: DB 스키마 → 공통 DTO → API 엔드포인트 → 프론트엔드 → 통합 테스트. 여기서 병렬 가능한 단위(스키마와 DTO)를 찾아내는 단계입니다.
4. 구현 (Implement)
에이전트에게 위임하고, 병렬로 실행하고, 중간 결과를 수집하면서 모니터링을 해줍니다.
5. 검증 (Verify)
테스트 코드를 돌리고, Playwright로 브라우저 자동 테스트, api call을 통한 E2E 테스트까지 수행해주는 단계입니다.
6. 기록 (Record)
의사결정을 기록하고, 지식을 축적하고, 다음 작업에 활용합니다. 이 단계가 있어서 세션이 일회성이 아니라 자산이 됩니다.
이 여섯 단계 중 어느 하나라도 빠지면 결과물의 품질이 떨어지는 것을 목격했습니다. 탐색 없이 바로 구현하면 기존 컨벤션을 무시하고, 플래닝 없이 시작하면 중간에 방향이 흔들리고, 검증 없이 넘어가면 타입 에러가 쌓이고, 기록 없이 끝내면 같은 실수를 반복합니다.
그리고 AI가 실수하고 실패하는 데에는 패턴이 있습니다.
실패 패턴 5가지
AI는 불규칙하게 실패하는 게 아니라, 반복적으로 같은 방식으로 실패합니다.
솔직히 처음에는 “AI가 틀릴 수 있다”는 막연한 불안이 있었습니다. 이 에이전트를 믿고 맡겨도되나.. 하는..
근데 수천 번 쓰다 보니 패턴이 보이기 시작했습니다. AI의 실패는 무작위가 아니에요. 같은 유형의 작업에서 같은 방식으로 실패하는 것을 발견했습니다.
이걸 알면 사전에 막을 수 있고, 실패가 터져도 빠르게 교정할 수 있습니다.
AI의 정답률을 100%로 올리는 건 불가능합니다. 대신, 실패했을 때 빠르게 방향을 바꿀 수 있는 구조를 만드는 게 현실적이고 효과적이었습니다.
그동안 반복적으로 관찰된 5가지 실패 패턴입니다.
| 패턴 | AI가 하는 실수 | 제 대응법 |
|---|---|---|
| 1. 원인 축소 | 증상만 보고 근본 원인을 놓쳐요 | ”끝까지 추적해” — 종료 지점을 명시 |
| 2. 가설 고착 | 첫 가설이 틀려도 같은 방향을 고집해요 | ”다른 방향으로” — 짧게 끊고 가설 리셋 |
| 3. 국소 최적화 | 한 곳 고쳤는데 다른 곳이 깨져요 | 수정 후 전체 영향도 확인 필수 |
| 4. 환경 맹점 | 문서만 보고 실행 환경을 무시해요 | 환경 지식을 Obsidian/PROJECT.md에 축적 |
| 5. 탐색 중단 | 중간까지만 보고 끝까지 안 가요 | Ralph 루프로 종료 조건까지 자동 반복 |
“XXX: 카드를 등록하지 않았는데 등록 알림톡이 발송되었어요”
알림톡 관련 voc가 인입되어 AI와 함께 root cause를 찾고자 했습니다. AI 최초 분석으로 코드 구조는 정확히 파악했지만, 문제는 “알림톡이 어디서 발송되는가”였습니다. 실제로는 디커플링을 위해 별도의 이벤트 리스너가 알림톡을 발행하는 구조였지만, 코드 내부에 카프카 발행 메서드가 있었고, AI는 이것이 원인이라고 진단했습니다.
이후에 AI는 카프카 -> admin 서버 컨슘 -> 알림톡 이라는 경로를 가설로 세우고, 이 방향으로 탐색을 진행하게 됩니다.
AI가 고착된 원인은 카프카였고, 실제 원인은 feign 동기호출 체인에 있었습니다. 이는 전형적인 원인 축소 및 가설 고착 패턴으로, 제가 모니터링을 하면서 중간에 끊고 탐색 종료지점과 가설을 새로 정해줌으로써 방향을 교정해줄 수 있었습니다.
이 외에도 OTEL 플러그인 작업을 한 경험이 있었습니다. 여기서는 버그 6개가 양파 껍질처럼 겹쳐 있었습니다. 하나 고치면 다음 게 드러나는 구조로 탐색 중단 없이 끝까지 원인을 추적하도록 하는 것이 중요합니다.
실패는 결국 하나의 문제로부터 출발
그런데 이 5가지 패턴은 결국 한가지 문제로부터 출발한다는 것을 알게되었습니다. 바로 컨텍스트 품질의 문제입니다. 좋은 품질의 컨텍스트가 충분히 쌓이지 않아서, 에이전트는 자신이 알고있는 좁은 컨텍스트 속에서 작업을 수행하느라 많은 실패를 마주하게 됩니다.
그래서 저는 좋은 품질의 컨텍스트를 확보해주기 위해, 탐색하는 과정을 늘렸습니다.
읽기:쓰기 = 10:1
앞서 말씀 드렸듯이 탐색을 통한 컨텍스트 확보가 매우 중요했기 때문에, 저는 토큰의 대부분을 읽기/탐색 과정에 사용합니다.
177,590건의 도구 호출을 분석해봤어요.
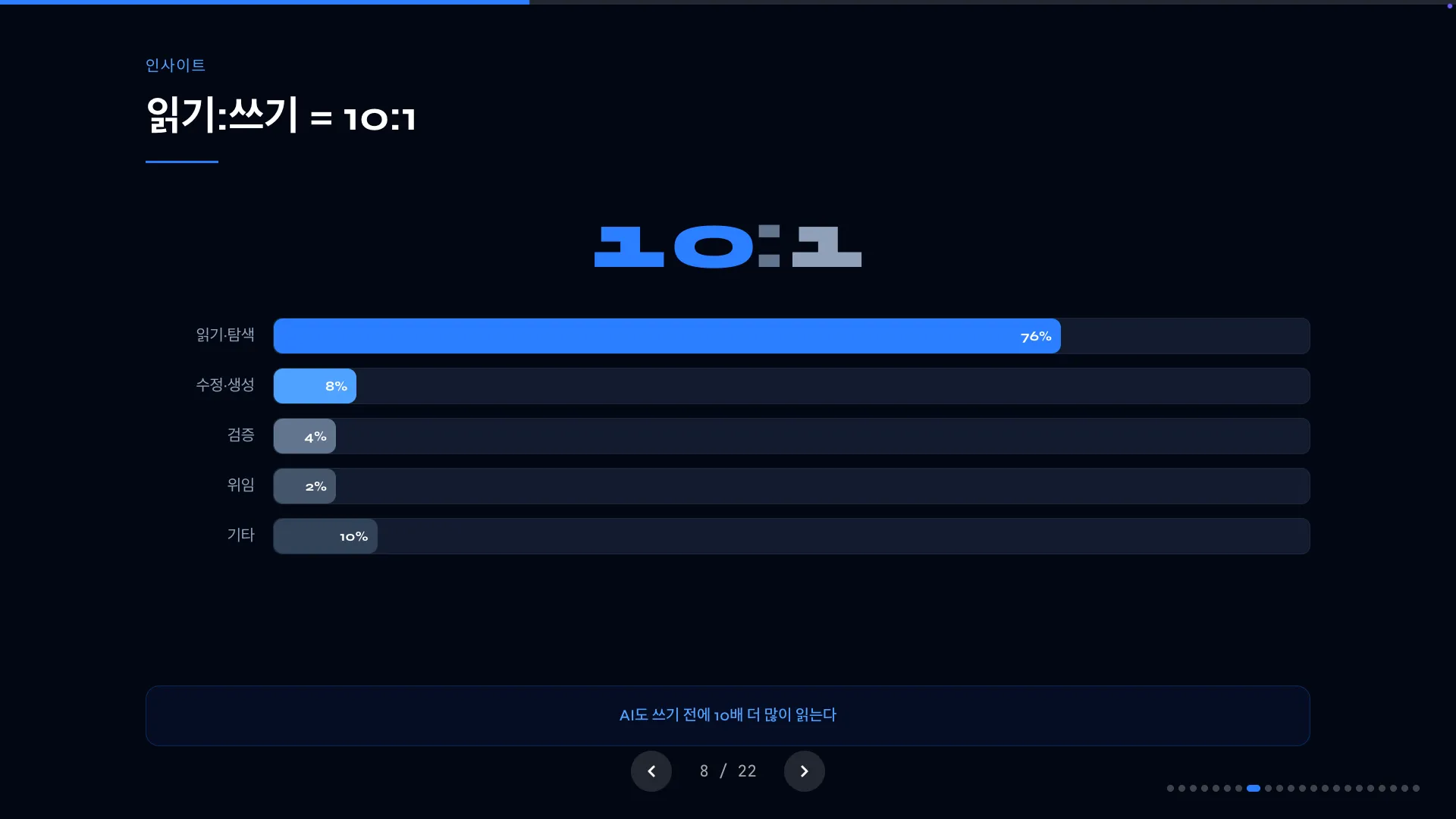
읽기:쓰기의 비율이 10:1 입니다.
Clean Code의 저자 Uncle Bob이 “코드를 읽는 시간이 쓰는 시간의 10배 이상”이라고 했습니다. 사람도 그렇다면, AI도 마찬가지라고 생각합니다. 제 데이터에서도 읽기:쓰기의 비율이 10배 차이가 났습니다.
처음부터 10:1은 아니었습니다. 초기에는 탐색 없이 바로 “해줘(딸깍)“를 던졌고, 재작업 비율이 높았습니다. 탐색 비중을 의도적으로 늘리면서 재작업이 줄어드는 것을 체감했고, 53일 치 도구 호출 로그를 분석해보니 자연스럽게 10:1로 수렴해 있었습니다.
좋은 코드의 출발점은 빠른 생성이 아니라 정확한 탐색입니다.
AI가 기존 코드베이스의 컨벤션을 모르고 코드를 짜면 스타일이 안 맞듯이, “바로 구현해”가 아니라 “먼저 기존 코드와 도메인 지식을 탐색하고, 패턴을 파악한 후 구현해”가 되어야합니다.
높은 품질의 컨텍스트 확보
| 소스 | 방법 | 목적 |
|---|---|---|
| 사용자 프롬프트 | 목적·제약·맥락을 명시 | 탐색 방향과 품질을 결정하는 출발점 |
| 코드베이스 | 탐색 에이전트 3~5개 병렬 | 기존 패턴, 컨벤션, 의존성 |
| 컨플루언스/위키/엑셀 | 문서 검색 에이전트, MCP | 설계 배경, 비즈니스 규칙, 기획 문서 |
| 웹 검색 | 라이브러리 문서, GitHub | Best practice, 최신 패턴 |
| 과거 세션 | 시맨틱 검색 (문서 로컬 임베딩) | 유사 작업의 이전 결정 |
여기서 중요한 건 병렬 탐색입니다.
하나의 탐색 에이전트가 코드베이스를 순차적으로 훑는 게 아니라, 3~5개의 에이전트가 각각 다른 관점으로 동시에 탐색합니다. 패턴 탐색, 의존성 분석, 유사 코드 검색 — 이걸 한번에 병렬처리 하는 것입니다.
컨텍스트 품질이 높을수록 AI의 구현 품질도 자연스럽게 올라갑니다. 같은 작업을 컨텍스트 없이 던졌을 때와, 기존 패턴 + 비즈니스 규칙 + 과거 의사결정을 함께 전달했을 때, 재작업 비율이 3~4배 차이 났습니다.
단 주의사항이 있습니다. 에이전트의 컨텍스트 윈도우의 크기는 한정적이므로, 무작정 컨텍스트를 많이 확보하는 것은 능사가 아니에요. 컨텍스트를 확보하되, 불필요한 정보까지 가져오는 것을 막으면서 컨텍스트의 품질을 유지해줘야 합니다.
1편을 마치며
1편에서는 53일 간의 AI 협업 경험에서 발견한 운영 원리를 다뤘습니다.
- 개발자의 핵심 노동이 구현에서 분해·플래닝·검증으로 옮겨가고 있다는 것
- AI는 예측 가능하게 실패하며, 그 5가지 패턴은 결국 컨텍스트 품질 문제로 수렴한다는 것
- 좋은 코드의 출발점은 빠른 생성이 아니라 정확한 탐색이라는 것 (읽기:쓰기 = 10:1)
2편에서는 이 원리를 실제 업무에 적용하는 구체적인 실행 프로세스를 소개합니다. AI의 기억 문제를 해결하는 로컬 RAG 시스템, 작업을 병렬화하는 Task DAG와 Branch Hunt 전략, 그리고 자동 구현·검증을 반복하는 Ralph Loop까지 — 148,000번의 대화를 가능하게 한 실행 인프라의 전체 그림을 다룹니다.