소개
안녕하세요. 컬리 데이터서비스개발팀에서 일하고 있는 백엔드 개발자 최재형, 김수지, 데이터 엔지니어 이상협, ML 엔지니어 구국원입니다. 이전 글에서는 장바구니 추천 모델을 개발하는 과정에서 고민한 내용을 설명드렸습니다. 그리고 이러한 고민 끝에 만들어진 모델의 부가가치를 실제 컬리의 엔드 유저에게 전달하기 위해서 실시간 서빙 아키텍처를 구축할 필요가 있있었습니다. 그 과정에서 역시나 많은 고민과 시행착오가 있었고, 현재 구축한 아키텍처에 기반하여 성공적으로 실시간 서빙을 수행하고 있습니다. 따라서 본 글에서는 컬리가 어떻게 실시간 서빙 아키텍처를 구축하고 운영하고 있는지를 공유 드리고자합니다.
실시간 추천을 위한 아키텍처 소개
© 2024.Kurly.All right reserved
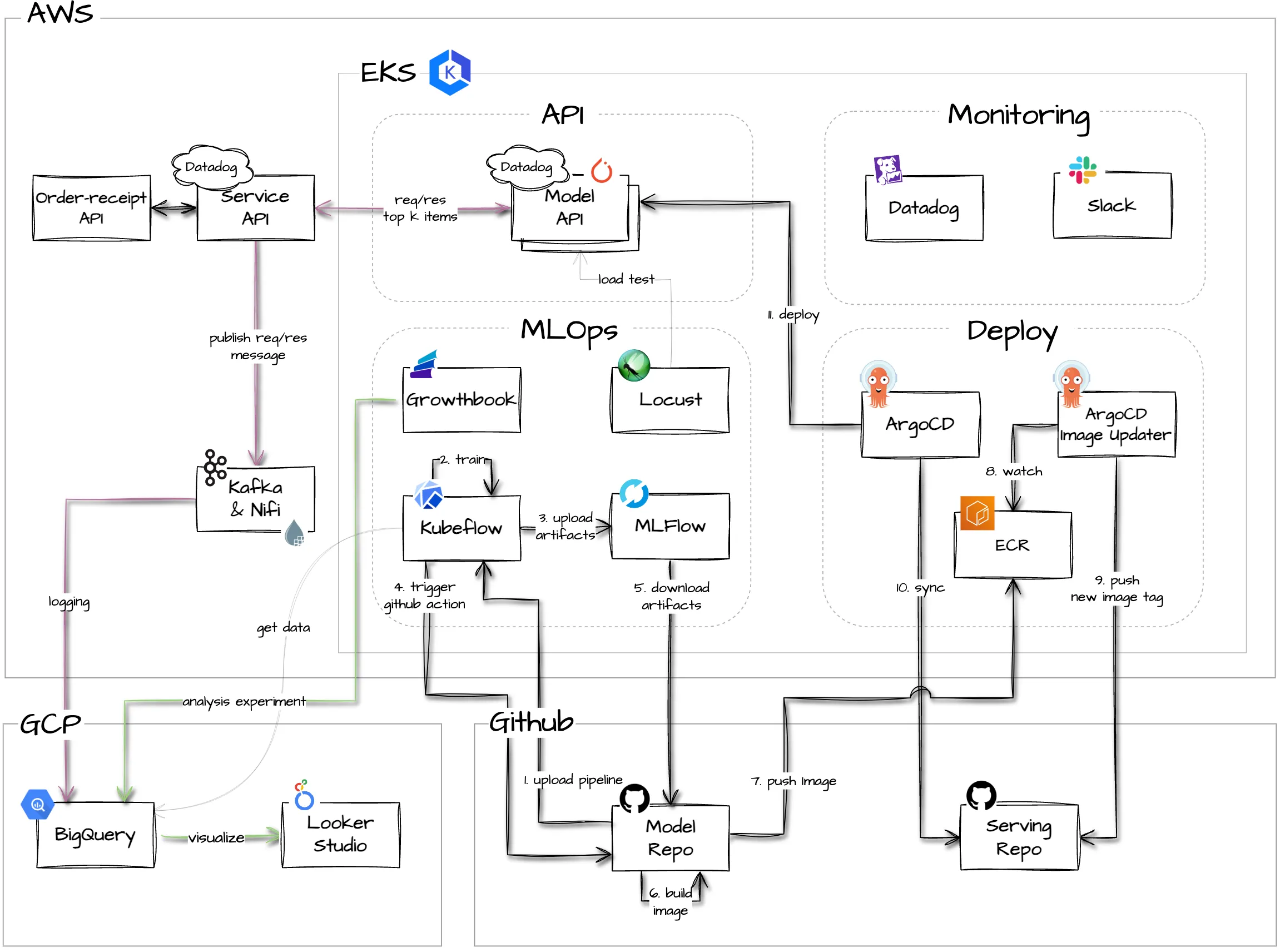
추천 모델을 실시간으로 서빙하기 위한 아키텍처를 나타내 보았습니다. 이 아키텍쳐에 대해서 간단하게 말씀드리면, 추천 모델 API는 AWS와 GCP의 시스템을 활용하였고 그 중 AWS의 EKS 클러스터에서 대부분의 추천 모델 관련 작업이 이루어졌습니다. 학습과 분석에 필요한 데이터는 BigQuery에 적재되어 있고, 운영시 중요하게 모니터링 해야할 부분들은 Datadog과 Slack을 활용해 감지하고 알럿을 보냅니다. 이 아키텍쳐를 서비스 API, 모델 API, MLOps, 모니터링, 배포 과정 파트로 나눠서 각각의 구성 요소들의 세부사항들을 설명드리겠습니다.
서비스 API
서비스 API는 모델 API 앞단에서 컬리 백엔드의 트래픽을 받아 냅니다. 서비스 API는 유저에게 더 좋은 추천 서비스를 제공하고, 추후 서비스의 확장성을 확보하기 위해 구축하였으며 다음과 같은 기능을 수행합니다.
- 모델 API 응답 실패시 fallback 추천 응답 제공
- A/B 테스트를 위해 여러 버전의 모델 API로 라우팅
- 필터링, 부스팅 등의 후처리 비즈니스 로직
- 모니터링과 사후 분석을 위한 추천 요청/응답 로깅
특히 모든 분석과 모니터링은 정확한 로깅에서 시작하기 때문에 로깅은 서비스 API의 가장 중요한 요소라고 할 수 있습니다. 서비스 API에는 팀내에서 자체 구축한 로깅 모듈을 활용하고 있는데, 이 모듈을 통해서 API에서 발생한 로그들을 파일 형태로 내립니다. 그 후 생성된 로그 파일을 기 구축된 로깅시스템을 통해 Kafka 토픽으로 전송하고 카프카 토픽에 쌓인 메시지는 Nifi를 활용해 실시간으로 빅쿼리로 적재됩니다. 위 과정을 수행하기 위해 필요한 Kafka나 Nifi와 같은 데이터 연동 인프라는 기존에 저희 팀에서 구축해서 운영 중인 상황이었기 때문에 이를 그대로 활용할 수 있었습니다. 그 결과, 현재 빅쿼리에서 거의 실시간에 가까운 로그를 확인할 수 있습니다.
모델 API
서빙 프레임워크 선정
모델 API를 구축하기 위해서는 먼저 서빙 프레임워크를 선정해야 했습니다. 서빙에 사용되는 오픈 소스들은 각자의 장단점이 명확하기 때문에 결국 저희 상황에 맞는 프레임워크를 선정하는 것이 중요했습니다. 여러 후보들을 비교 했는데, 최종적으로는 BentoML과 TorchServe를 후보로 두고 의사결정 하였습니다. 먼저, BentoML은 사용 편의성이 높아서 컬리의 다른 ML API를 서빙하는데 활용하고 있었고 운영 하면서 축적된 노하우가 있었기 때문에 후보로 선정하였습니다. 그리고 Torchserve는 Pytorch 모델을 서빙할 수 있는 프레임워크인데, 마침 개발된 모델이 Pytorch 기반이기도 하고 준수한 성능 보일 것으로 예상해서 후보로 선정하였습니다.
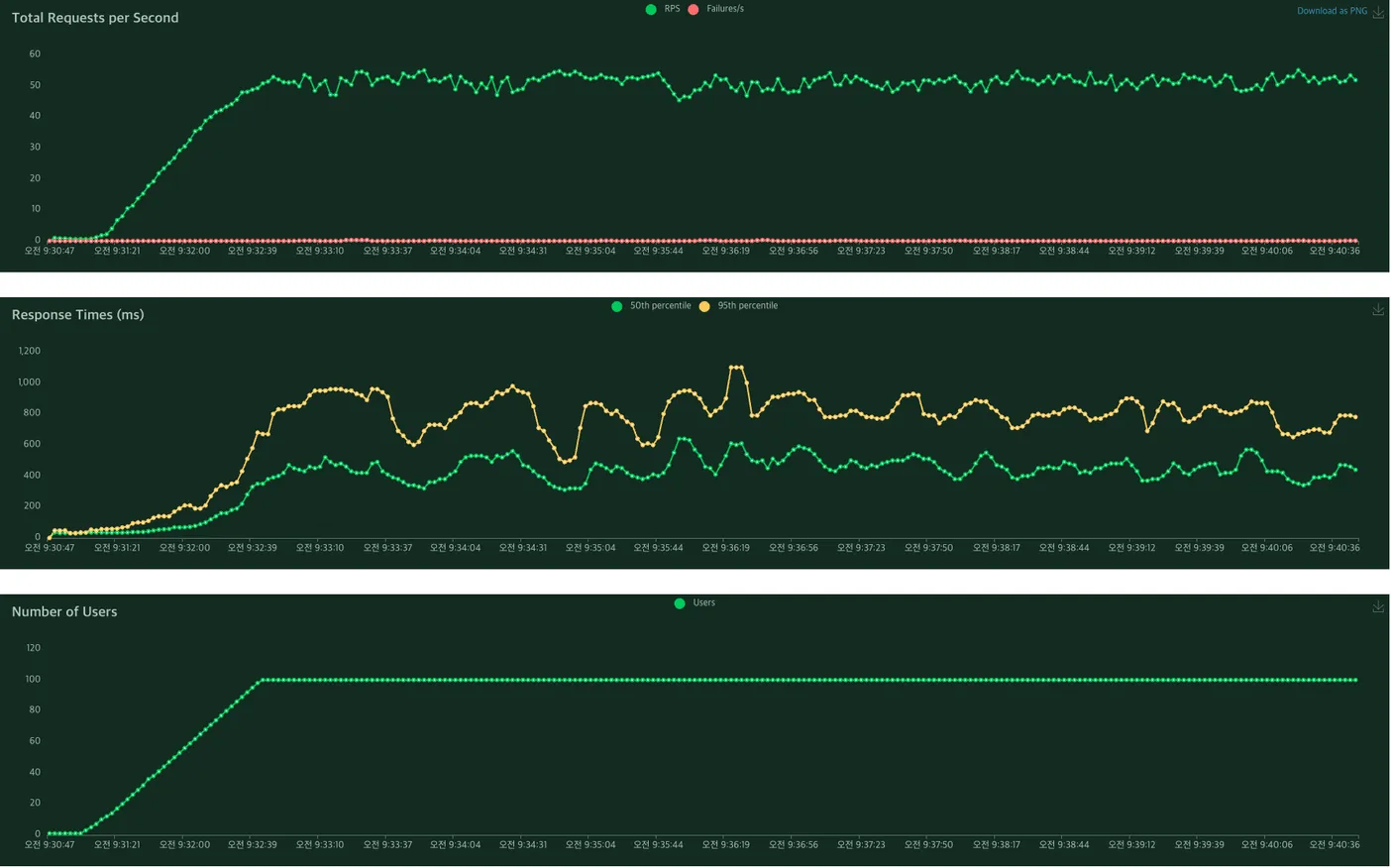
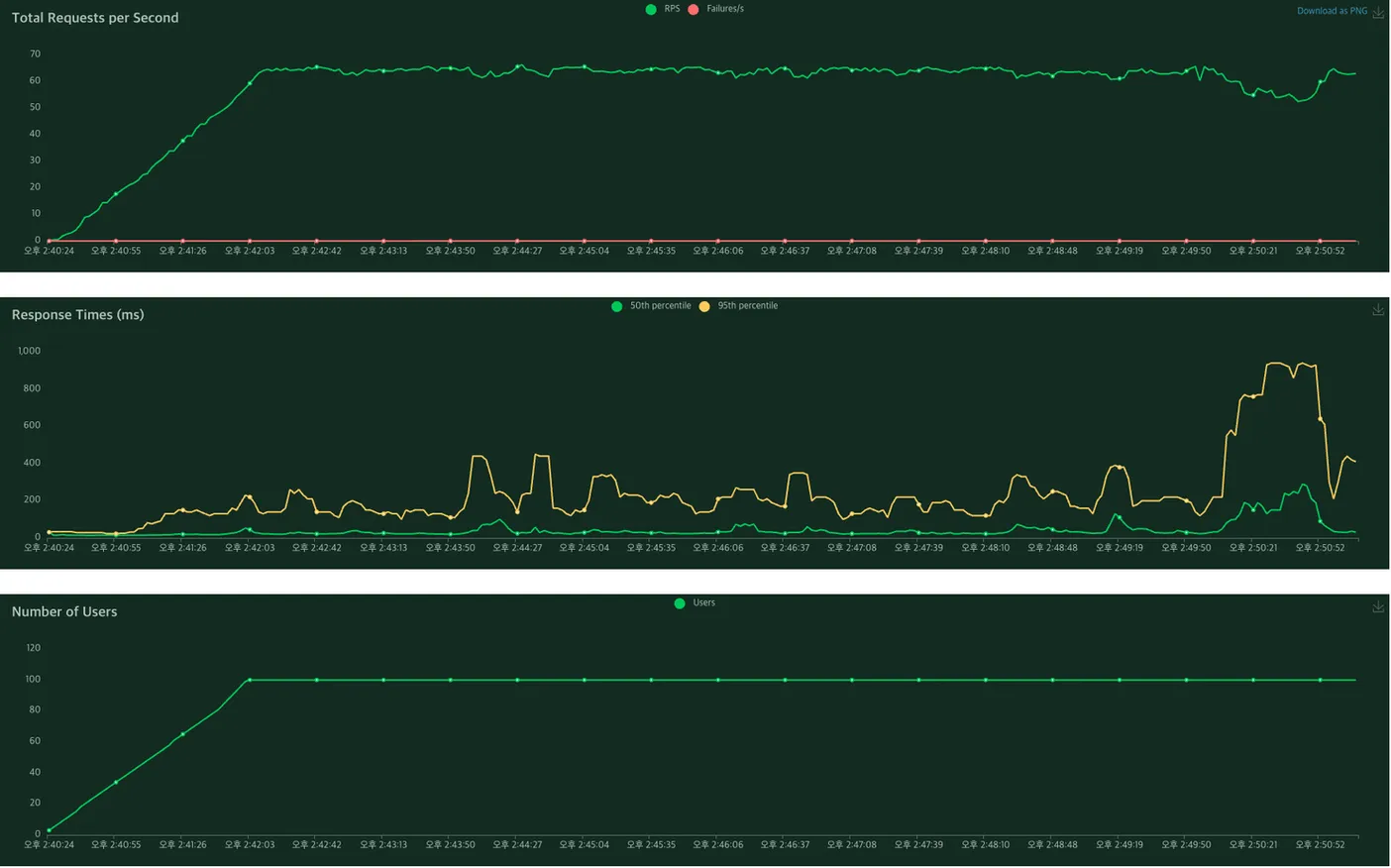
그리고 최종 선택을 위해 각 서빙 프레임워크로 랩핑한 API를 띄워보고 성능 테스트를 진행하였습니다. 성능 테스트는 Locust를 활용하였고, 아래와 같은 그래프를 확인 할 수 있었습니다.
© 2024.Kurly.All right reserved
© 2024.Kurly.All right reserved
대략적인 비교를 해보고자 세부적인 튜닝 없이 진행하였는데, 응답 시간 측면에서 torchserve가 더 좋은 지표를 보여주었습니다. 따라서 최종적으로 서빙 프레임워크로 Torchserve를 활용하기로 했고, 성능 최적화를 위한 세부적인 튜닝을 진행하였습니다.
Torchserve 튜닝
Torchserve를 튜닝하는 최종 목표는 낮은 응답시간(지연시간)을 달성하는 것이었습니다. 이를 위해 Torchserve 공식 문서나 관련 아티클을 참고하여 몇 가지의 속성들과 인프라적 튜닝 포인트를 확인 했습니다. 그 내용들은 다음과 같습니다.
CPU Clock Speed:
추론 요청시 연산 집약적이기 때문에 CPU Clock Speed가 더 높은 타입의 인스턴스로 교체하였을 때 속도가 월등히 늘어난 것을 확인할 수 있었습니다.
async_logging:
true로 설정시 로깅이 비동기로 동작합니다. async_logging을 활성화 해도 저희가 원하는 낮은 지연시간에는 영향을 주지 않았습니다.
disable_system_metrics:
시스템 관련 메트릭을 수집하지 않는 옵션입니다. 메트릭을 수집하지 않아도 낮은 지연시간에는 영향을 주지 않았습니다.
netty_client_threads:
추론 결과를 클라이언트에 제공하는 Worker 대수 관련 설정 옵션입니다. Worker를 늘려도 저희 환경에서는 응답시간이 줄지 않았기 때문에 쓰레드 갯수는 default 설정으로 유지하였습니다.
정리하면, 낮은 지연시간을 달성하기 위해선 부차적인 옵션 설정보다는 CPU Clock Speed가 중요한 특성이라는 것을 경험적으로 확인했습니다. 그 이유는 TorchServe는 요청을 들어온 순서대로 Queue에 넣고 FIFO 방식으로 처리하는 방식으로 구현되어 있으므로 선행하는 요청을 빠르게 처리하는 것이 전체 성능 향상에 가장 큰 영향을 미치기 때문입니다. 다시 말해, 높은 CPU Clock Speed를 확보하는 것이 결국 낮은 응답시간을 달성하는 핵심 요인이라는 것이므로 최종적으로는 CPU Clock에 특화된 인스턴스 중에서 더 우수한 성능을 보이는 인스턴스를 선정하여 API를 배포하였습니다.
안정적인 배포
무중단 배포의 필요성
ML 모델 API는 일반적인 애플리케이션과는 다르게 배포가 자주 일어날 수 있습니다. 왜냐하면 API가 운영되고 있는 중에 모델은 빈번하게 업데이트가 발생하기 마련이고, 이를 반영하여 새 모델로 API를 변경해줘야 하기 때문입니다. 이렇게 새 버전으로 배포하는 중에 다운타임이 발생하게 된다면 서비스 품질에 큰 영향을 줄 수 있기 때문에 무중단 배포가 필요합니다. 일반적으로 Kubernetes가 제공하는 Rolling Update, Blue/Green, Canary 등의 배포 전략을 활용하면 이론적으로는 무중단 배포가 되는게 맞지만, 실제로 배포 테스트를 해보았을 때 다운타임이 일부 발생하는 것을 확인되었습니다.
이런 중단이 발생하는 주된 이유는 EKS외에 AWS의 다른 서비스들을 활용하는 것, 그리고 Gracefulshutdown이 적용되지 않았기 때문입니다. AWS EKS에서 애플리케이션이 트래픽을 받기 위해서는 Ingress를 생성하면서 AWS의 Application Load Balancer(이하 ALB)를 활용하게 되는데 이 때 ALB Ingress의 TargetGroup의 연결이 끊어지고 새로 연결되는 과정에서 다운타임이 발생할 수 있습니다.
ALB가 생성된 후에 TargetGroup이 정상적으로 연결이 되면 그 시점부터 트래픽은 정상적으로 들어오게 됩니다. 하지만 모델의 업데이트로 새 버전의 pod가 생성되었고 이 pod로 트래픽을 보내려고 한다면, 기존의 구 버전의 pod는 ALB와 연결이 해제되어야 하며 이와 동시에 새 버전 pod가 ALB에 연결되어야 합니다. 바로 이 연결이 끊어지고 맺어지는 때에 다운타임이 발생하게 되는 것입니다. 다시 말해, 새 TargetGroup이 Initial 중이면서 기존 TargetGroup이 draining 될 때 발생하는 다운타임은 필연적입니다.
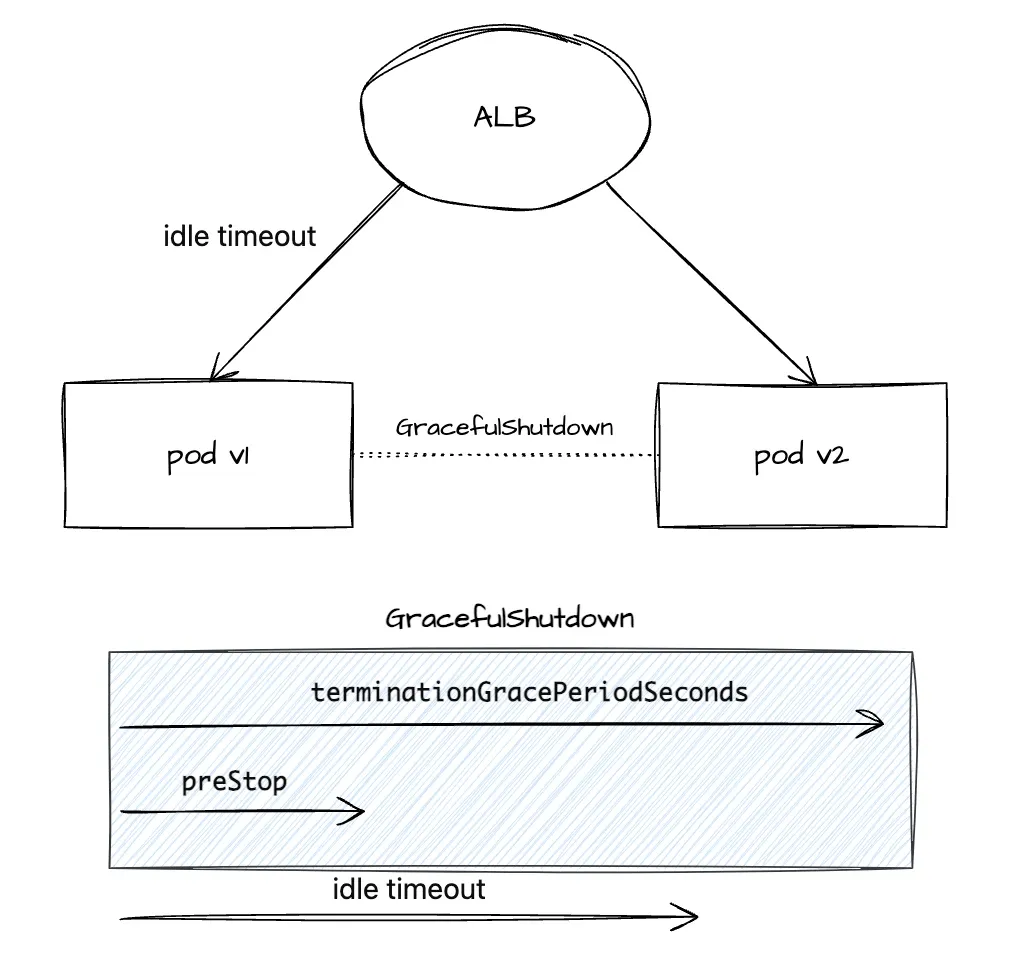
GracefulShutdown
© 2024.Kurly.All right reserved
그럼에도 불구하고 다운타임을 방지할 수는 없을까요? 이어서 설명드릴 GracefulShutdown을 적용하면 앱이 종료되는 과정 상의 타이밍을 조정하여 다운타임이 발생하는 것을 방지할 수 있습니다. 다시 TargetGroup이 새롭게 연결되는 과정으로 돌아가 봅시다. 기본적으로 애플리케이션은 종료 신호(SIGTERM)를 받게 되었을 때 그 즉시 바로 종료 됩니다. 그렇다면 pod가 완전히 종료되기 전에 종료를 준비할 시간을 주면 어떻게 될까요? GracefulShutdown을 설정하면 종료에 대한 준비를 할 수 있습니다. GracefulShutdown을 설정하기 위해서는 세 가지 개념을 알아야 합니다.
- PreStop Hook
- terminationGracePeriodSeconds
- ALB idle time
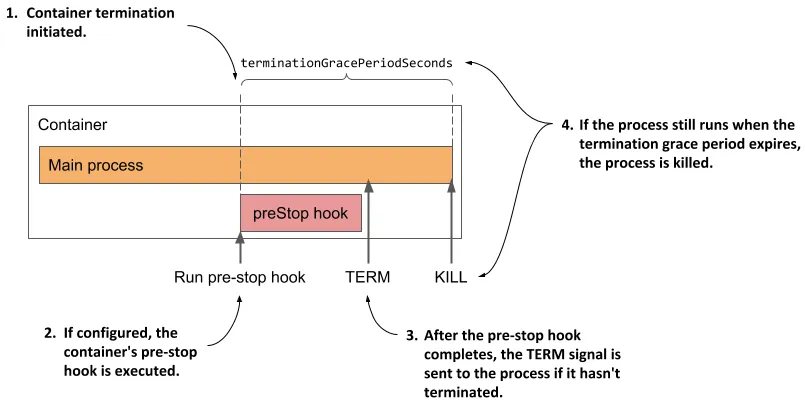
먼저 prestop Hook은 쿠버네티스에서 파드를 종료할 때 preStop 훅을 사용하여 파드가 종료되기 전에 일정 시간을 기다리도록 설정할 수 있습니다. 이는 애플리케이션이 GracefulShutdown을 할 시간을 벌어줍니다. prestop Hook은 컨테이너가 SIGTERM 신호를 받기 전에 실행됩니다. 이 훅을 통해 애플리케이션이 처리 중인 요청을 마칠 수 있는 시간을 확보할 수 있습니다. terminationGracePeriodSeconds는 쿠버네티스가 파드에 SIGTERM 신호를 보낸 후 파드를 강제로 종료하기 전에 기다리는 시간(초)을 지정합니다. 이 시간 동안 파드는 요청을 처리하고 종료 절차를 완료할 수 있습니다. 기본 값은 30초이며 이 시간이 지난 후에는 SIGTERM 신호가 전달됩니다. 기본적으로 이 두 개념을 사용하여 GracefulShutdown을 할 시간을 준비할 수 있습니다.
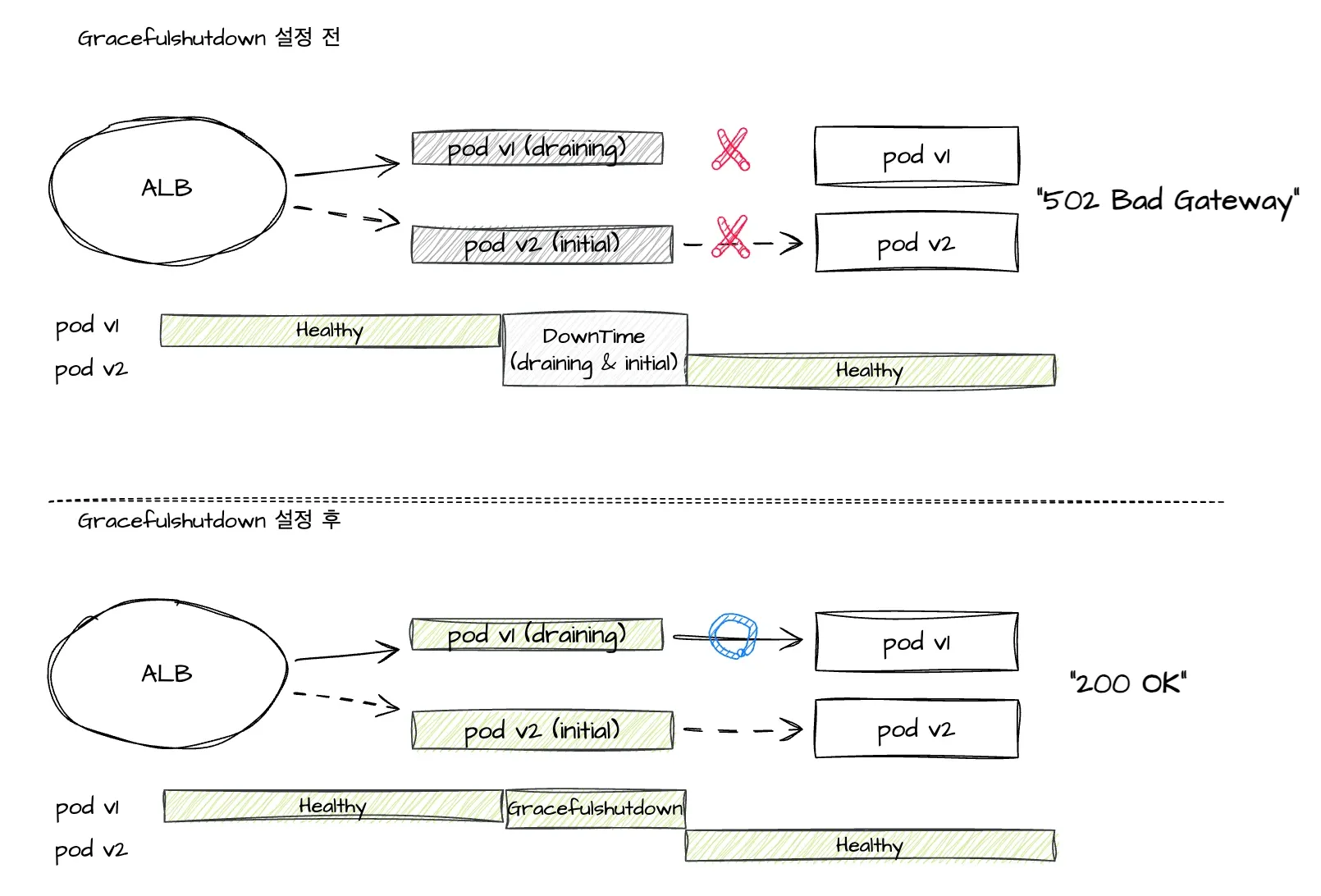
여기서 하나 더 필요한 것은 ALB idle timeout입니다. AWS ALB는 연결이 유휴 상태일 때 연결을 유지하는 최대 시간을 지정할 수 있는 값으로서 기본 값은 60초로 설정됩니다. 만약 ALB 시간이 60초이고 terminationGracePeriodSeconds가 50초라고 가정해보겠습니다. 50초 이후에는 ALB쪽 커넥션은 열려있지만 요청을 받는 쪽은 처리할 수 없는 상태가 되어 502 에러가 발생하기에 ALB쪽 커넥션이 먼저 닫히는 것을 보장할 수 있게 terminationGracePeriodSeconds를 ALB idle timeout 시간보다 조금 높게 잡아서 해당 커넥션으로 요청이 가지 않게 설정하는 것이 필요합니다. 아래 그림과 같이 Gracefulshutdown이 설정 되기 전에는 다운타임이 발생하여 502 error가 발생했던 것이 설정 이후에는 안정적으로 종료되면서 200 응답이 나오게 됩니다.
© 2024.Kurly.All right reserved
위에 설명한 내용들을 고려해서 샘플 yaml을 다음과 같이 작성할 수 있습니다. 각자의 애플리케이션 성격이나 환경에 맞게 설정하여 활용 하시면 됩니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
template:
metadata:
labels:
app: my-app
spec:
terminationGracePeriodSeconds: 70 # 종료 유예 시간 설정 (ALB idle timeout 60sec 보다 길게)
containers:
- name: my-app-container
image: my-app:latest
ports:
- containerPort: 80
readinessProbe:
httpGet:
path: /healthz
port: 80
initialDelaySeconds: 5
periodSeconds: 10
lifecycle:
preStop:
exec:
command: ['/bin/sh', '-c', 'sleep 10'] # 파드 종료 전 10초 대기참고로 Torchserve에는 별도로 GracefulShutdown이 이미 구현이 되어있기 하지만, 이는 네트워크 레벨에서의 요청의 유실을 보장하는 것은 아니기 때문에 무중단 배포를 위해서는 상기 언급한 설정은 반드시 필요합니다.
public void shutdown(boolean graceful) {
closeAllChannels(graceful);
List<EventLoopGroup> allEventLoopGroups = new ArrayList<>();
allEventLoopGroups.add(serverGroup);
allEventLoopGroups.add(childGroup);
if (configManager.isMetricApiEnable()) {
allEventLoopGroups.add(metricsGroup);
}
for (EventLoopGroup group : allEventLoopGroups) {
if (graceful) {
group.shutdownGracefully();
} else {
group.shutdownGracefully(0, 0, TimeUnit.SECONDS);
}
}
if (graceful) {
for (EventLoopGroup group : allEventLoopGroups) {
try {
group.awaitTermination(60, TimeUnit.SECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
}Warm up
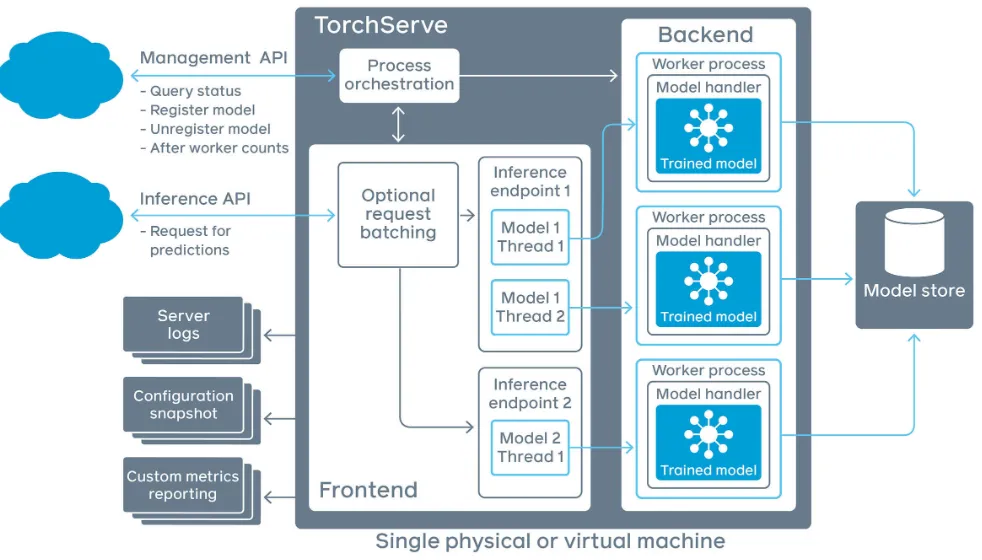
적절한 인스턴스 타입을 선정한 후 응답 시간을 테스트 했을 때, 배포가 정상적으로 완료된 뒤 첫 요청은 응답시간이 3초 이상 지연되는 문제가 발견되었습니다. 해당 현상의 원인은 파악하기 위해 Torchserve의 구조와 구현 코드를 살펴 보았습니다. TorchServe에서 요청을 받아내는 부분과 실제 추론 연산을 하는 요소는 각각 Frontend와 Backend입니다. Frontend는 Java 코드, Backend 부분은 Python 코드로 작성되어 있으며 Frontend와 Backend 사이에는 내부 통신이 이루어집니다. 문제는 Frontend 부분에서 요청 처리에 사용하는 클래스들을 로딩해주는 과정 및 모델 초기화 과정이 첫 번째 요청이 도달하는 시점에서 이루어지기 때문에 첫 요청의 응답이 상대적으로 매우 느리게 됩니다. 이외에도 JVM의 지연 로딩 등도 첫 요청시 느린 응답 시간의 원인일 수 있습니다.
따라서 저희는 첫 요청 부터 안정적인 응답 시간을 보장하기 위해 쿠버네티스의 StartupProbe를 활용한 warm up 과정을 추가하였습니다. 쿠버네티스 환경에서는 실제 트래픽을 받기 위해 라우팅 테이블에 등록하기 전에 Probe 과정을 거칩니다. Probe의 종류에는 다음과 같이 3가지 종류가 있습니다.
- StartupProbe: 컨테이너가 정상적으로 실행 됐는지 확인하는 용도. 처음에 한 번만 실행
- LivenessProbe: 컨테이너가 실행중인지 여부를 확인. 주기적 실행
- ReadinessProbe: 컨테이너가 요청을 받을 준비가 되었는지 확인. 주기적 실행
모델 API의 warm up 목적은 모델 초기화와 추론시 사용하는 클래스 로드이므로 최초 한번만 컨테이너의 정상 실행 여부를 확인하는 Startup Probe를 사용하여 warm up을 진행하였습니다. 해당 warm up 로직 추가 이후에는 잦은 배포에도 급하게 상승하는 지연시간 없이 안정적으로 서비스가 운영 되고 있습니다.
MLOps
MLOps에 관해서는 Kurly만의 MLOps 구축하기 - 초석 다지기, Kurly만의 MLOps 구축하기 - 쿠브플로우 도입기라는 두 편의 글을 작성했습니다. 본 글에서는 구체적인 활용 사례를 다루어 보겠습니다. 먼저, 추천 모델을 개발하기 위한 기본적인 데이터 분석 및 작업 환경은 Kubeflow Notebook을 통해서 이뤄졌습니다. 작업이 이루어진 후에는 Kubeflow Pipeline을 사용하여 ML 모델을 학습하는 파이프라인을 구성했고 주기적으로 데이터를 학습한 모델이 MLFlow에 업로드 됩니다.
© 2024.Kurly.All right reserved
학습에 GPU 자원이 필요한 경우엔 Karpenter를 활용해 GPU 노드 프로비저닝 활용할 수 있습니다. 또한 모델 학습을 자동으로 수행하기 위해서 Kubeflow Pipeline을 구성하는 yaml을 자동으로 생성하는 워크플로우를 작성했고 이를 쿠버네티스 클러스터 내에서 실행되도록 하는 Action Runner Controller를 클러스터 내에 설치해 파이프라인을 Kubeflow 환경에 자동으로 등록되도록 하여 작업 수행 시간을 줄일 수 있었습니다. 운영 환경에서 작업이 수행되는 내역들은 모니터링 설정을 통해 실패 시에 슬랙으로 알럿이 오도록 설정했고 배치에 이상이 있더라도 빠르게 대응이 가능했습니다.
그 외에 실험 분석을 위해서 Growthbook을 Helm Chart로 만들어 쿠버네티스에 배포해 사용하고 있습니다. 현재는 데이터 조직 외에도 개발/비개발 부서에서도 사용하면서 데이터 기반 의사 결정 문화를 형성하는데 큰 도움이 되고 있습니다. 모델 API의 요청 및 응답은 Bigquery에 적재되고 있는데 데이터 소스로 Bigquery를 연결하고 쿼리만 설정해주면 쉽게 A/B테스트 분석이 가능합니다. 이 결과 내용을 추천 모델의 의사결정자 분들께 공유하고 의견을 나누면서 추천 모델의 방향을 쉽게 잡을 수 있었습니다.
API 성능 테스트에는 Locust가 활용되었습니다. Locust는 오픈 소스 성능 테스트 도구로, 웹사이트 및 기타 시스템의 로드 테스트를 수행하는 데 사용할 수 있습니다. Python 코드를 사용하여 테스트 로직을 정의하고, 만들어진 스크립트를 통해 대규모 트래픽 시나리오를 시뮬레이션할 수 있습니다. Locust 역시 Helm Chart로 구성하여 쿠버네티스 클러스터에 배포되었습니다. Locust는 별도의 노드 구성을 하기 때문에 다른 노드에 있는 애플리케이션에 영향을 주지 않도록 설정되었고 따라서 API가 배포된 이후에 부담없이 부하테스트를 진행할 수 있었습니다.
이렇게 Kurly의 MLOps 시스템은 점진적으로 발전해왔으며, 작업자들이 통합된 환경에서 모델을 운영하고 배포할 수 있도록 지원하고 있습니다. ML 엔지니어나 MLOps 엔지니어가 아니더라도 누구나 자유롭게 MLOps 시스템에 대한 의견을 제시하고 원하는 기능을 제안할 수 있으며, 이를 바탕으로 MLOps 시스템은 점점 개선되고 있습니다.
모니터링
모델 API 모니터링은 Datadog을 활용하고 있습니다. API가 배포되어 있는 쿠버네티스 환경에 Datadog 클러스터 에이전트가 설치되어 있어 추가적인 설정 없이 CPU, Memory, RPS 등 각 노드의 메트릭 수집이 가능했습니다. 또한 주요 메트릭은 한번에 보기 편하게 대시보드를 생성하여 모니터링 하고 있습니다.
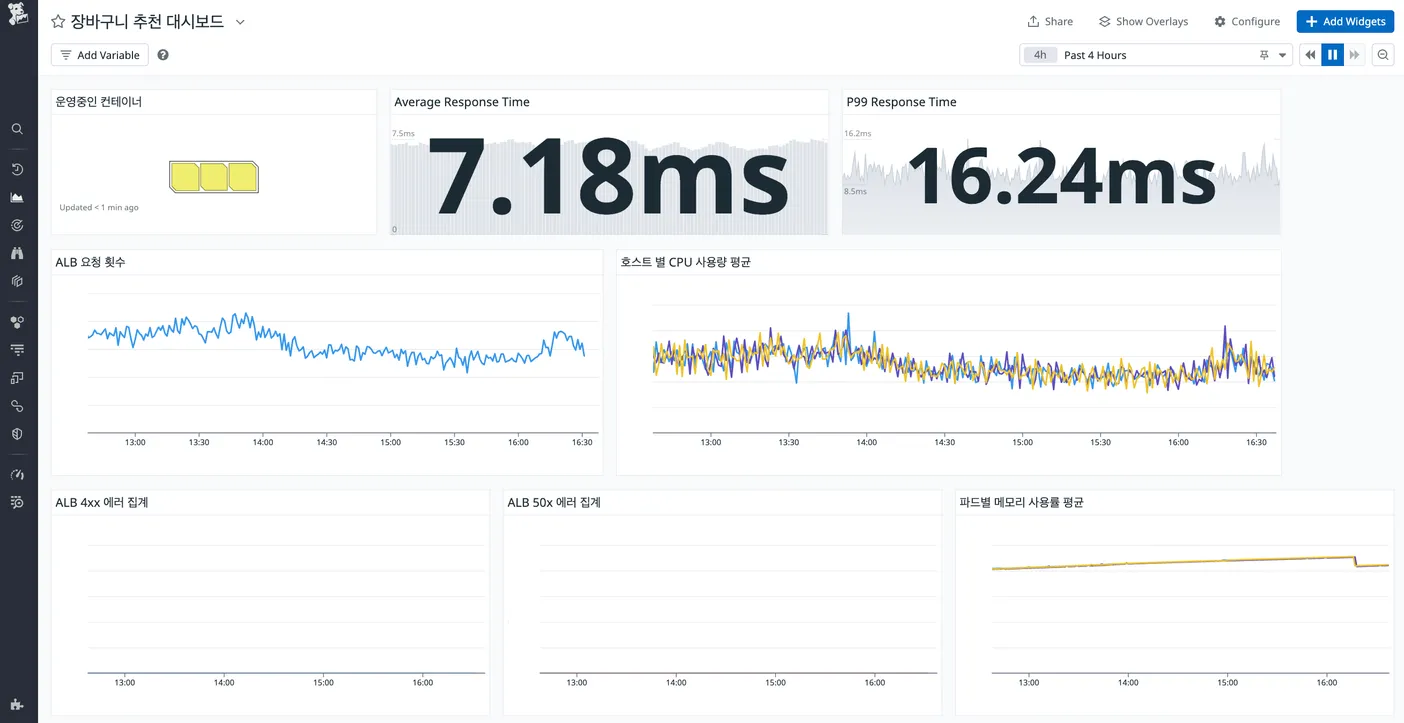
© 2024.Kurly.All right reserved
그러나 클러스터에 기존 서버들의 로그 수집이 불필요했기 때문에 에이전트의 로그 수집 기능은 비활성화된 상태였습니다. 이로 인해 서버의 로그를 확인하기 위해서는 각 노드에 직접 접속하여 원하는 로그를 찾아야 하는 번거로움이 있었습니다. 따라서 Datadog에서 로그 수집 기능을 사용하되, 다른 서버의 로그는 수집하지 않도록 에이전트에 다음과 같이 설정하였습니다.
datadog:
logs:
containerExcludeLogs: image:.*
containerIncludeLogs: image:\<IMAGE_NAME>\b또한 TorchServe는 기본적으로 Access logs와 TorchServes logs를 수집하는데, Access Logs는 TorchServes logs와 중복되는 로그를 포함하고 있고, 매 초마다 생성되는 health check 로그의 양이 많아 Datadog 로그에서는 Access Logs를 제외하여 필요한 로그만 효과적으로 확인할 수 있도록 쿠버네티스 yaml 에 다음과 같이 설정하였습니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: <APP-NAME>
namespace: kurly
labels:
app: <APP-NAME>
spec:
template:
metadata:
annotations:
ad.datadoghq.com/<CONTAINER_IDENTIFIER>.logs: |-
[{
"source": "<APP-NAME>",
"service": "<APP-NAME>",
"log_processing_rules": [{
"type": "exclude_at_match",
"name": "exclude_access_log",
"pattern" : "\\bACCESS_LOG\\b"
}]
}]
spec:
containers:
- name: <CONTAINER_IDENTIFIER>배포 과정
모델 API의 배포에는 ArgoCD와 ArgoCD Image Updater를 활용하고 있습니다. 모델 API의 배포 과정은 상기 아키텍처에 번호를 붙여서 명시해두었는데요. 이를 자세히 살펴보겠습니다.
먼저 저희는 레포지토리를 모델 레포, 서빙 레포 2가지로 분리하여 운영하고 있습니다. 먼저 모델 레포에는 모델 핵심 로직(예: train.py)과 API 빌드 관련 파일(예: Dockerfile)을 관리합니다. 그리고 서빙 레포에서는 API를 쿠버네티스에서 배포하기 위한 쿠버네티스 매니패스트(예: Deployment)를 관리합니다. 초기에는 모델 레포에서 모델 핵심 로직, API 빌드 파일, 쿠버네티스 매니패스트를 모두 한꺼번에 관리하였는데, 그 결과 배포가 불편해지고 여러 커밋이 혼재되는 문제가 발생했습니다. 따라서 레포를 위와 같이 2개로 분리하였고, 보다 효율적인 배포 구조를 마련할 수 있었습니다. 참고로 서빙 레포는 하나의 레포에 여러 개의 프로젝트를 관리하는 모노레포 방식으로 이루어져 있고, 각 프로젝트는 폴더 및 브랜치로 분리되어 관리됩니다. 또한 Kustomize를 활용하여 매니패스트를 환경별로 분리하여 관리하고 있습니다.
이제 API가 쿠버네티스에 배포되기까지의 과정을 살펴보겠습니다. 먼저, 모델 레포에서 수정이 일어나면 github action workflow가 쿠브플로우 파이프라인을 새로운 로직에 맞게 업데이트 합니다. 그 후 쿠브플로우 파이프라인이 동작하면 모델이 새롭게 학습되고, 최종적으로는 배포를 위한 github action workflow를 트리거합니다.
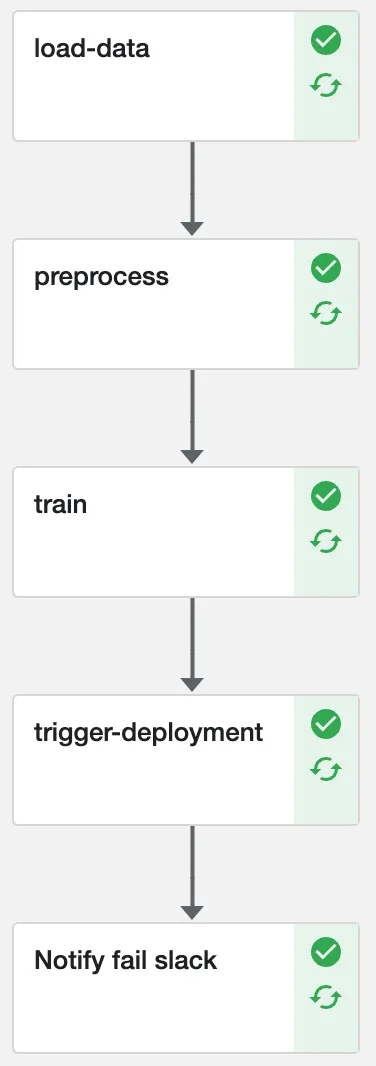
© 2024.Kurly.All right reserved
해당 workflow에서는 mlflow를 활용하여 production stage에 있는 아티팩트(모델 및 기타 파일) 다운로드 하고 이를 기반으로 토치 서브 컨테이너 이미지를 빌드한 뒤 특정 ECR에 해당 이미지를 푸시합니다.
ArgoCD Image Updater는 ECR의 특정 레포지토리를 특정 주기로 watch 하고 있습니다. 만일 새로운 이미지가 감지되면 해당 이미지 태그를 반영한 파일을 서빙 레포로 커밋 & 푸시합니다.
kustomize:
images:
- <ECR-REPOSITORY>:<IMAGE-TAG>마지막으로 ArgoCD는 서빙 레포의 특정 브랜치를 특정 주기로 watch 하고 있습니다. 만일 새로운 커밋이 감지되면 쿠버네티스에 배포된 리소스와 깃의 내용을 비교하여 차이가 발생할 경우 이를 sync 합니다. 즉, 새로운 이미지 태그를 가진 Deployment를 EKS에 배포 합니다.
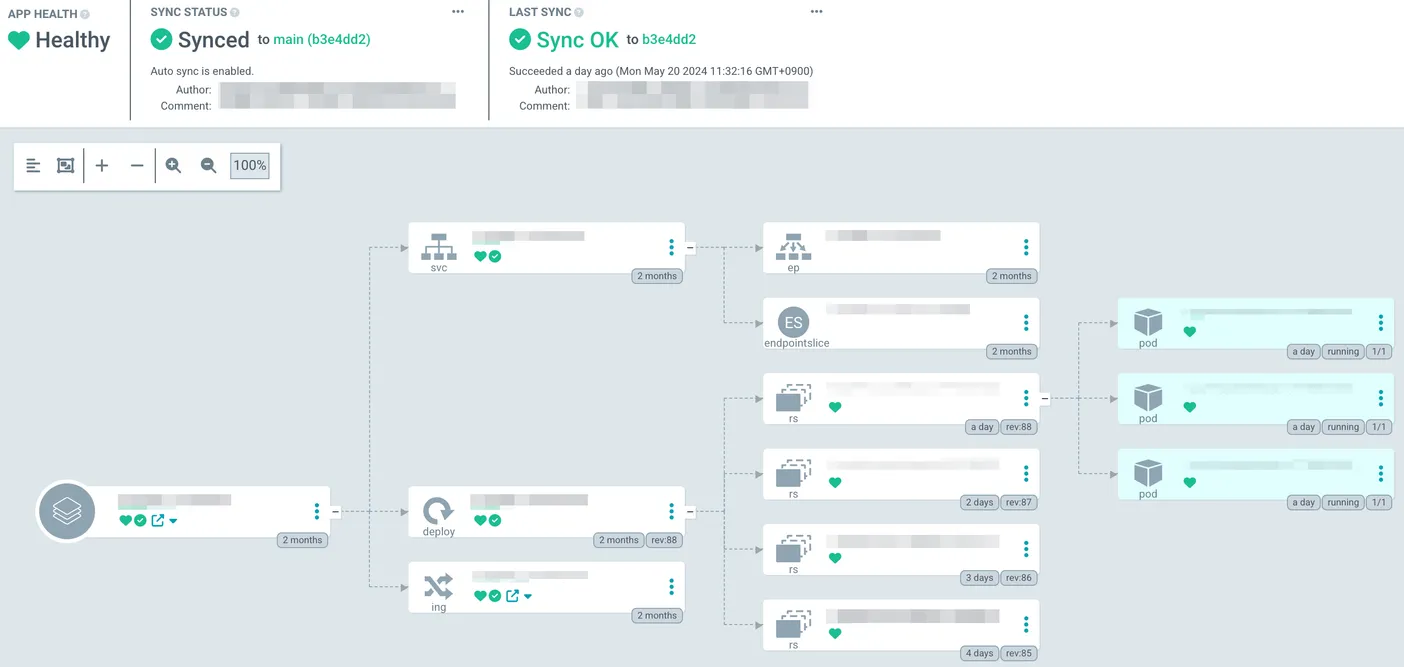
© 2024.Kurly.All right reserved
그리고 ArgoCD 배포 과정은 아래와 같이 슬랙으로 받아보고 있습니다.
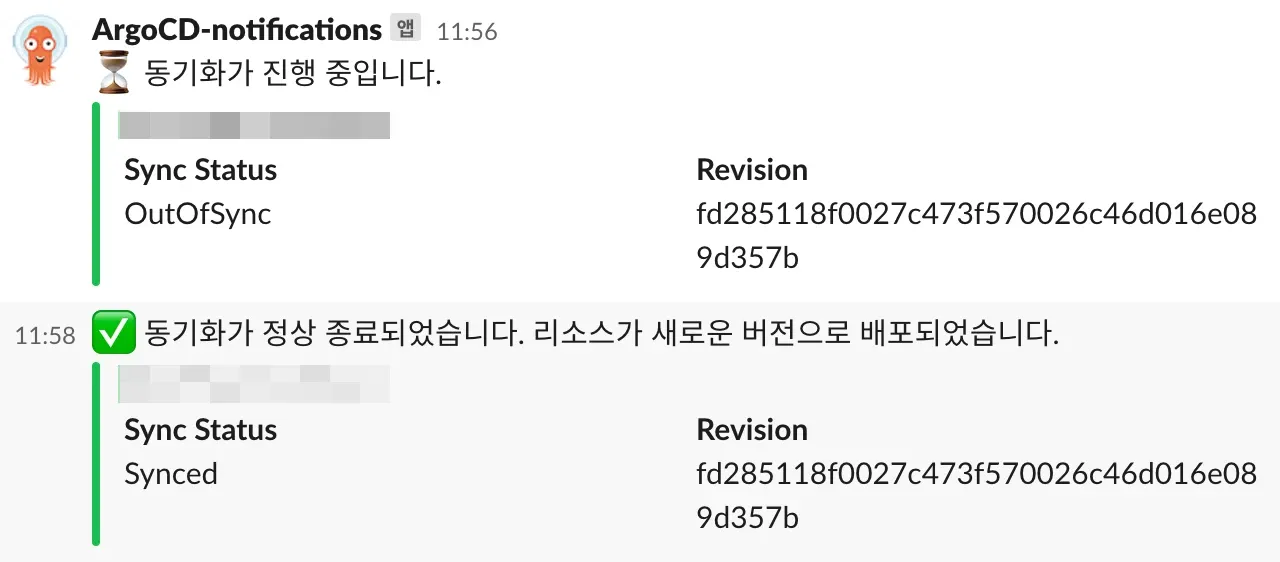
© 2024.Kurly.All right reserved
향후 과제
지금까지 장바구니 추천 서비스를 안정적으로 운영하기 위한 고민 과정과 현재 운영 중인 아키텍처를 설명드렸습니다. 하지만 앞으로 개선 해야할 점이 존재합니다. 아쉽게도 아직 아직 개인화 요소를 고려하여 추천 하는 서비스는 아닙니다. 따라서 향후에는 유저의 프로파일 정보나 상품의 추가적인 정보를 실시간으로 반영하여 보다 개인화된 추천 결과를 줄 수 있도록 서비스 개선을 준비하고 있습니다. 그러므로 이에 관련된 아키텍처도 많이 변경 및 개선 되어야 하며, 지금 보다 더 높은 수준의 실시간 처리 안정성이 요구될 것이므로 저희 팀은 이를 위한 아키텍처를 지속적으로 연구하고 구축해 나갈 것입니다. 컬리의 추천이 진화하는 모습을 앞으로도 기대해 주세요!
참고 자료
- https://docs.aws.amazon.com/ko_kr/elasticloadbalancing/latest/application/target-group-health-checks.html
- https://www.growthbook.io/
- https://locust.io/
- https://kubernetes.io/docs/concepts/containers/container-lifecycle-hooks/
- https://wangwei1237.github.io/Kubernetes-in-Action-Second-Edition/docs/Understanding_the_pod_lifecycle
- https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
- https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
- https://pytorch.org/serve/configuration.html
- https://docs.datadoghq.com/ko/containers/guide/autodiscovery-management/?tab=helm#포함-및-제외-작업
- https://docs.datadoghq.com/ko/agent/logs/advanced_log_collection/?tab=kubernetes#로그-필터링